Java 集合系列 15 Map总结
java 集合系列目录:
Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例
Java 集合系列 04 LinkedList详细介绍(源码解析)和使用示例
Java 集合系列 05 Vector详细介绍(源码解析)和使用示例
Java 集合系列 06 Stack详细介绍(源码解析)和使用示例
Java 集合系列 07 List总结(LinkedList, ArrayList等使用场景和性能分析)
Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
Java 集合系列 11 hashmap 和 hashtable 的区别
概述
第1 部分 Map 概述
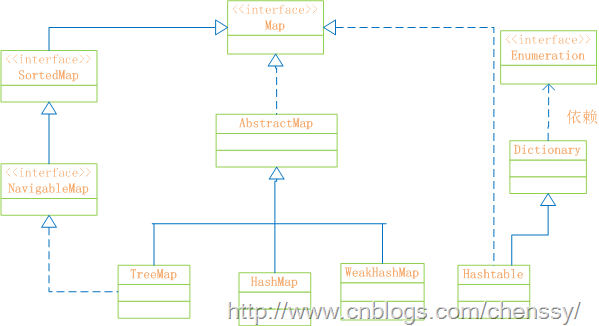
Map:“键值”对映射的抽象接口。该映射不包括重复的键,一个键对应一个值。
SortedMap:有序的键值对接口,继承Map接口。
NavigableMap:继承SortedMap,具有了针对给定搜索目标返回最接近匹配项的导航方法的接口。
AbstractMap:实现了Map中的绝大部分函数接口。它减少了“Map的实现类”的重复编码。
Dictionary:任何可将键映射到相应值的类的抽象父类。目前被Map接口取代。
TreeMap:有序散列表,实现SortedMap 接口,底层通过红黑树实现。
HashMap:是基于“拉链法”实现的散列表。底层采用“数组+链表”实现。
WeakHashMap:基于“拉链法”实现的散列表。
HashTable:基于“拉链法”实现的散列表。
总结如下:

第2 部分 内部哈希: 哈希映射技术
哈希映射技术是一种就元素映射到数组的非常简单的技术。由于哈希映射采用的是数组结果,那么必然存在一中用于确定任意键访问数组的索引机制,该机制能够提供一个小于数组大小的整数,我们将该机制称之为哈希函数。在Java中我们不必为寻找这样的整数而大伤脑筋,因为每个对象都必定存在一个返回整数值的hashCode方法,而我们需要做的就是将其转换为整数,然后再将该值除以数组大小取余即可。如下
int hashValue = Maths.abs(obj.hashCode()) % size;
下面是HashMap、HashTable的:
----------HashMap------------
//计算hash值
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//计算key的索引位置
static int indexFor(int h, int length) {
return h & (length-1);
}
-----HashTable--------------
int index = (hash & 0x7FFFFFFF) % tab.length; //确认该key的索引位置
在众多肯能存在多个元素他们的hash值是一样的,这样就会得到相同的索引位置,也就说多个元素会映射到相同的位置,这个过程我们称之为“冲突”。解决冲突的办法就是在索引位置处插入一个链接列表,并简单地将元素添加到此链接列表。当然也不是简单的插入,在HashMap中的处理过程如下:获取索引位置的链表,如果该链表为null,则将该元素直接插入,否则通过比较是否存在与该key相同的key,若存在则覆盖原来key的value并返回旧值,否则将该元素保存在链头(最先保存的元素放在链尾)。下面是HashMap的put方法,该方法详细展示了计算索引位置,将元素插入到适当的位置的全部过程:
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} // 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
} // putForNullKey()的作用是将“key为null”键值对添加到table[0]位置
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
// recordAccess()函数什么也没有做
e.recordAccess(this);
return oldValue;
}
}
// 添加第1个“key为null”的元素都table中的时候,会执行到这里。
// 它的作用是将“设置table[0]的key为null,值为value”。
modCount++;
addEntry(0, null, value, 0);
return null;
}
HashMap的put方法展示了哈希映射的基本思想,其实如果我们查看其它的Map,发现其原理都差不多!
第3 部分 Map 优化
首先这样假设,假设哈希映射的内部数组的大小只有1,所有的元素都将映射该位置(0),从而构成一条较长的链表。由于我们更新、访问都要对这条链表进行线性搜索,这样势必会降低效率。我们假设,如果存在一个非常大数组,每个位置链表处都只有一个元素,在进行访问时计算其 index 值就会获得该对象,这样做虽然会提高我们搜索的效率,但是它浪费了控件。这两种方式都是极端的,但是它给我们提供了一种优化思路:使用一个较大的数组让元素能够均匀分布。在Map有两个会影响到其效率,一是容器的初始化大小、二是负载因子。
3.1 调整实际大小
在哈希映射表中,内部数组中的每个位置称作“存储桶”(bucket),而可用的存储桶数(即内部数组的大小)称作容量 (capacity),我们为了使Map对象能够有效地处理任意数的元素,将Map设计成可以调整自身的大小。我们知道当Map中的元素达到一定量的时候就会调整容器自身的大小,但是这个调整大小的过程其开销是非常大的。调整大小需要将原来所有的元素插入到新数组中。我们知道index = hash(key) % length。这样可能会导致原先冲突的键不在冲突,不冲突的键现在冲突的,重新计算、调整、插入的过程开销是非常大的,效率也比较低下。所以,如果我们开始知道Map的预期大小值,将Map调整的足够大,则可以大大减少甚至不需要重新调整大小,这很有可能会提高速度。下面是HashMap调整容器大小的过程,通过下面的代码可以看到其扩容过程的复杂性:
void resize(int newCapacity) {
Entry[] oldTable = table; //原始容器
int oldCapacity = oldTable.length; //原始容器大小
if (oldCapacity == MAXIMUM_CAPACITY) { //是否超过最大值:1073741824
threshold = Integer.MAX_VALUE;
return;
}
//新的数组:大小为 oldCapacity * 2
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
/*
* 重新计算阀值 = newCapacity * loadFactor > MAXIMUM_CAPACITY + 1 ?
* newCapacity * loadFactor :MAXIMUM_CAPACITY + 1
*/
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//将元素插入到新数组中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
3.2 负载因子
为了确认何时需要调整Map容器,Map使用了一个额外的参数并且粗略计算存储容器的密度。在Map调整大小之前,使用”负载因子”来指示Map将会承担的“负载量”,也就是它的负载程度,当容器中元素的数量达到了这个“负载量”,则Map将会进行扩容操作。
负载因子、容量、Map大小之间的关系如下:
负载因子 * 容量 > map大小 ----->调整Map大小。
例如:如果负载因子大小为0.75(HashMap的默认值),默认容量为11,则 11 * 0.75 = 8.25 = 8,所以当我们容器中插入第八个元素的时候,Map就会调整大小。
负载因子本身就是在控件和时间之间的折衷。当我使用较小的负载因子时,虽然降低了冲突的可能性,使得单个链表的长度减小了,加快了访问和更新的速度,但是它占用了更多的控件,使得数组中的大部分控件没有得到利用,元素分布比较稀疏,同时由于Map频繁的调整大小,可能会降低性能。但是如果负载因子过大,会使得元素分布比较紧凑,导致产生冲突的可能性加大,从而访问、更新速度较慢。所以一般推荐不更改负载因子的值,采用默认值0.75.
参考
1.Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
Java 集合系列 15 Map总结的更多相关文章
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列15之 Set架构
前面,我们已经系统的对List和Map进行了学习.接下来,我们开始可以学习Set.相信经过Map的了解之后,学习Set会容易很多.毕竟,Set的实现类都是基于Map来实现的(HashSet是通过Has ...
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 17 TreeSet
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 16 HashSet
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 14 hashCode
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 13 WeakHashMap
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 12 TreeMap
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- 如何选择正确的DevOps工具
坦白的讲:世界上没有哪种工具能够像DevOps这么神奇(或敏捷,或精益).DevOps在开发和运营团队之间建立了完美的合作与沟通,因此与其说这是一种神奇的工具,不如说是一种文化的转变. 然而,团队之间 ...
- 【转】基于APD的光电探测器电路研究与设计
光电探测器电路用于对光电转换器件输出的微弱电压或电流信号进行放大.处理和整形输出.对于不同探测用途而采用的光电转换器件不同,与之配合使用的光电探测器电路性能也因此而不同.如果用来进行光电转换,则重点考 ...
- Beaglebone Black 和树莓派
我不是创客.我买了个 Beaglebone Black 来玩,主要是拿来学习. 入手前,看过好几个树莓派 (Raspi - 2 Model B)和 Beaglebone Black (BBB) 比较, ...
- [Effective Java]第六章 枚举和注解
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- day20 FORM补充(随时更新),F/Q操作,model之多对多,django中间件,缓存,信号
python-day20 1.FROM生成select标签的数据应该来源于数据库. 2.model 操作 F/Q (组合查询) 3.model 多对多操作. 4.中间件 :在请求到达url前先会经过 ...
- Typescript的面向对象
封装: var Greeter = (function () { function Greeter(message) { this.greeting = message; } Greeter.prot ...
- equals()和hashcode()
默认调用的情况: 1.集合在存放对象时,首先判断hashcode(),再判断equals如果都是true,认为是相同的两个元素不进行存储. 删除对象时,将从hashcode指定位置查找再删除 2.在h ...
- random使用
package com.cz.test; import java.util.Random; public class RandomTest { public static void main(Stri ...
- org.apache.jasper.JasperException: Expecting "jsp:param" standard action with "name" and "value" attributes
jasper 英 ['dʒæspə] 美 ['dʒæspɚ] 跟读 口语练习 n. 碧玉:墨绿色 n. (Jasper)人名:(德)雅斯佩尔:(西)哈斯佩尔 JasperException 异 ...
- C语言语法之占用字节
指针占用字节 指针即为地址,存的是变量的地址,在同一架构下地址长度都是相同的(cpu的最大寻址内存空间),所以不同类型的指针长度都一样. 指针占用几个字节跟语言无关,而是跟系统的寻址能力有关,16为地 ...