新手教程之:循环网络和LSTM指南 (A Beginner’s Guide to Recurrent Networks and LSTMs)
新手教程之:循环网络和LSTM指南 (A Beginner’s Guide to Recurrent Networks and LSTMs)
本文翻译自:http://deeplearning4j.org/lstm.html
其他相关教程:
1. 深度神经网络简介 http://deeplearning4j.org/zh-neuralnet-overview
2. 卷积网络 http://deeplearning4j.org/zh-convolutionalnets
目录:
1. 前向传播网络
2. 循环网络
3. 随着时间的后向传播
4. 梯度爆炸与消失
5. LSTMs
6. Capturing Diverse Time Scales
7. 示例代码与评论
8. 资源
1. 回顾:前向传播网络
在前向传播网络的示例中,输入的样本被传到网络中,然后将其转换为一个输出;在有监督的学习中,输出将会是一个标签。即,他们将原始数据映射成类别,识别模式信号,即一个图像应该被标记为猫或者大象。

一个前向传播网络在有标签图像上进行训练,直到他们不断的缩短误差,使得他们可以正确的猜到对应图像的类别。有了这些训练数据的参数或者权重,然后就可以识别从未见过的种类数据。一个训练的前向传播网络,对图像的识别和处理是无序的,即:看一个猫的图像不会使其感知大象。也就是说,他并没有时序的概念,不记得过去处理的事情,只记得当前的训练。
2. 循环网络
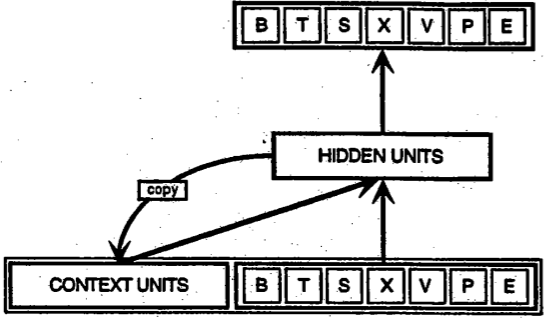
如上图所示,循环网络,其输入不仅仅是他们看到的当前的输入样本,他们也接收上一个时刻的输入。当前时刻的输入是:BTSXVPE,上一个时刻的信息存储在 CONTEXT UNIT中。
上一个时刻的决定会影响下一个时刻。所以RN 有两个输入来源,当前的和最近时刻的,共同来决定如何对付到来的新数据。与前向传播网络的不同之处在于,后向循环(feedback loop),即通常所说的RN具有记忆能力。任何东西的存在都是有道理的,同样,给神经网络添加记忆功能也是有收益的,即:可以捕获时序上的信息,RN经常可以执行前向传播网络所不能做的事情。
时序信息被保存在RN的隐层状态中,可以延伸很多时间步骤来级联前向传播来影响每一个新样本的处理。
就像人类的记忆力一样,其在身体内部循环,影响我们的行为,但是我们看不到其完全的形状,信息也在RN的隐层状态中循环。我们公式化的执行记忆前向的过程:
$h_t = \phi(Wx_t + Uh_{t-1})$,
时刻t的隐层状态是$h_t$。$x_t$是当前的输入,$W$是权重矩阵,上一个时刻的隐层状态$h_{t-1}$,以及其 hidden-state-to-hidden-state matrix $U$。权重矩阵$W$ 是一种filter,来根据当前输入和过去的 hidden state 来决定重要性。他们产生的误差会经过后向传播回传,用来调整他们的权重最终使得误差不再下降。
权重输入和hidden state的总和经函数$\phi$变换---要么是 逻辑sigmoid函数,要么是 tanh --- 是一个标准的工具来压缩过大或者过小的值,也会将梯度变换的适合后向传播。
这个反馈后向回传每次都会发生,每个 hidden state 不仅包含之前hidden state的轨迹,也涉及所有处理$h_{t-1}$的hidden state的轨迹,只要有足够的记忆空间。
给定一个字符序列,recurrent 将会使用第一个字符来协助帮助识别第二个字符。例如:一个初始的q可能意味着下一个字母是u,当是t时,下一个可能是h。由于RN随着时间展开,这个动画很好的解释了这个过程:http://imgur.com/6Uak4vF
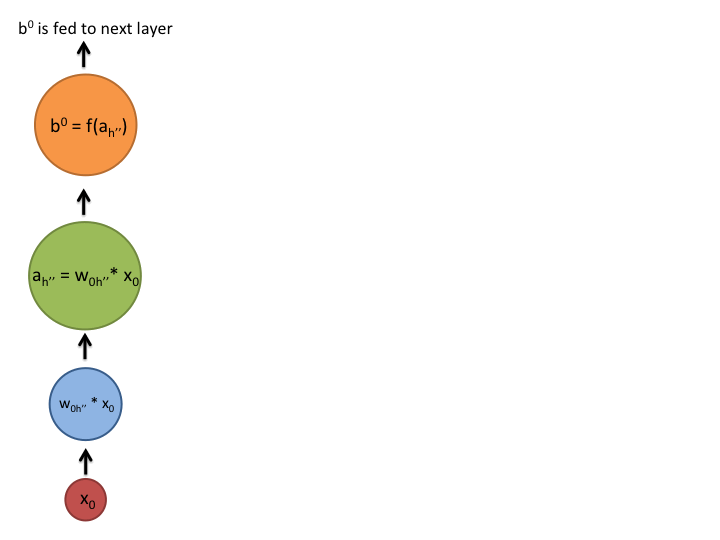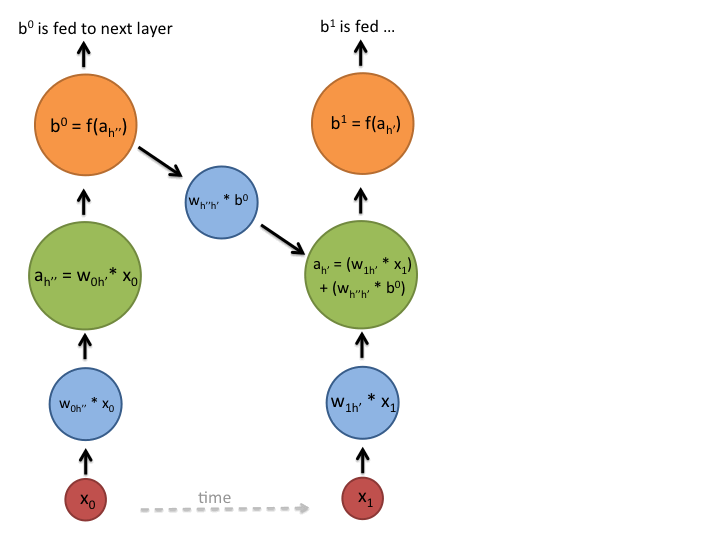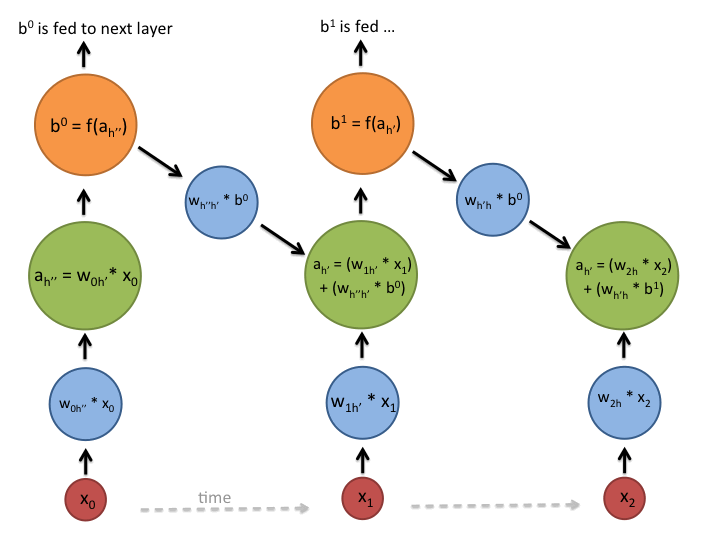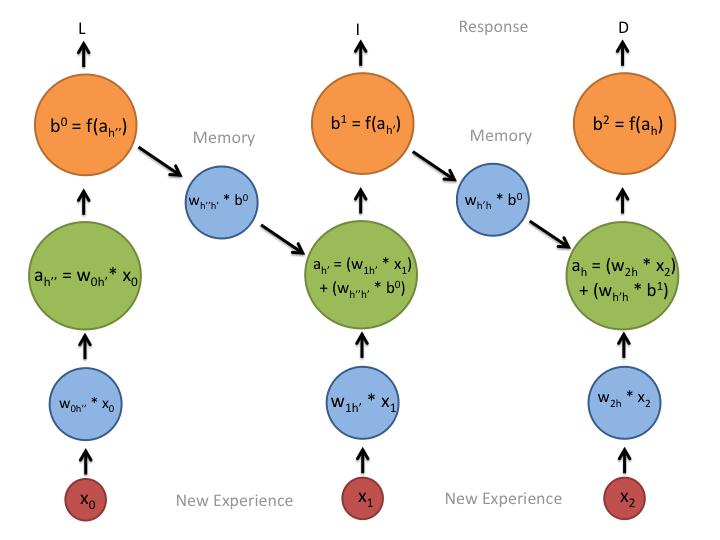
在上述流程图中,每个x是一个输入样本,w是权重,a是隐层的激活(权重输入和之前hidden state的组合),b是利用rectified linear or sigmoid unit转换后的隐层输出。
3. 随时间后向传播(Backpropagation Through Time ( BPTT ))
RN 的目标是准确的分类出序列输入,我们依赖误差的后向传播和梯度下降来完成该目标。
前向网络中的后向传播通过结果输出,权重和每一个隐层的输入来回传误差,通过计算他们偏导数 $\{alpha}E/\{alpha}w$,后者他们比率的变换关系。这些导数然后用来作为学习的规则,梯度下降,来调整权重,不管哪个方向,来减小误差。
RN依赖于后向传播的拓展,称为:Backpropagation through time, or called BPTT。时间,在这种情况下,就被简单的表达成一个定义好的,有序列的计算将一个time step和下一个time step联系起来,这些都需要BP来完成。神经网络,不管是否是循环的,都可以简单的表述成符合的函数:$f(g(h(x)))$。增加时间元素,仅仅是拓展该函数序列,我们可以通过链式法则来计算偏导数。
Truncated BPTT(截断的BPTT)
截断的BPTT是full BPTT的一种估计,更适合长序列,因为full BPTT的每个参数更新的前向和后向代价随着时间的进行,变得越来越大。不好的地方在于:梯度可以回传那么远,所以网络无法像full BPTT那样可以学到很长的依赖。
4. 梯度爆炸和梯度消失
像大部分的神经网络一样,RN 也是很老的东西了,在1990年早期,梯度消失是抑制RN 性能的主要原因。
就像$y = f(x)$中那样,随着x的变换,y也随之改变,梯度表示了所有权重的改变,对应着误差的改变。如果我们无法知道梯度,就无法调整权重使得误差朝着减少的方向进行,故网络就停止学习了。
RN寻找建立最终输出和许多时间步骤的事件之间的联系,因为依据非常遥远的输入很难知道其重要性,这里作者给出了一个很有意思的比喻,即:你祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父的祖父,他们在数量上增加到很快,但是他们的遗产就变得越来越模糊了。
这个部分原因是因为信息在神经网络中传递经过很多相乘的阶段。因为深度神经网路的各个层和时间序列都是根据相乘关系而关联在一起的,梯度是非常敏感,从而会消失或者爆炸。梯度爆炸将相当于是“蝴蝶效应”,一个很小的改变,会导致出现很大的反应,即:蝴蝶煽动一下翅膀,会引起一场飓风,卷起一头牛,那么疯狂!但是梯度爆炸相对来讲是比较容易解决的,因为他们可以被截断或者压缩。梯度消失,就有点头疼了,他使得计算机因为太小而无法计算,网络也无法进行学习,这真是一个很棘手的事情!
下面给出来一幅图,来表示一遍又一遍的利用sigmoid 函数带来的影响。随着使用梯度的增加,曲线几乎变的平坦了,即:梯度也变得非常小!!!

5. Long Short-Term Memory Units (LSTMs)
在90年代中期,RN的一个变体,LSTMs 被德国的研究者作为解决梯度消失问题的方案被提出。LSTMs 可以帮助用来存贮经过时间和各个层的误差,通过保持一个更加稳定的误差,他们允许RN来继续更多次的时间步骤,从而实现了原因和影响的远程操控。
LSTMs 将神经网络中正常流动的信息存储在一个门细胞中(gated cell)。信息可以存储,写入,后者从这里读取,就像数据存在计算机的存储单元中一样。该Cell经过门的打开和关闭,可以决定存储什么,什么时候允许读取,写入或者擦除。不像计算机中那种数字存储,然而,这些门都是类似的,通过sigmoid执行元素级相乘,都是在0-1的范围内。
这些门主要作用于他们接收的信号,类似于神经网络的结点。他们利用自己设置的权重来过滤,基于其力量和重要性来决定阻止或者允许通过信息。这些权重,像给输入和hidden state建模的权重一样,是随着RN学习过程不断调整的。即,Cells 学习何时允许数据通过,留下或者删除,通过迭代过程做出预测,后向传播误差,以及通过梯度下降来调整权重。
下面的图标表明了数据在记忆单元中的数据流向以及如何被各种门控制:
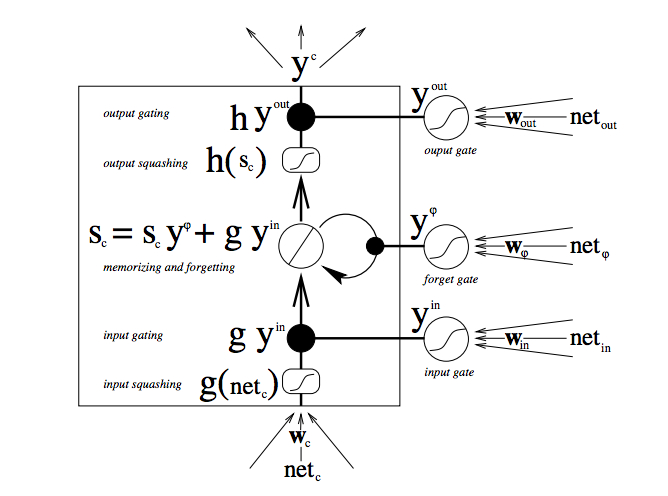
There are a lot of moving parts here, so if you are new to LSTMs, don’t rush this diagram---contemplate it. After a few minutes, it will begin to reveal its secrets.
从底部看起,三个箭头表明从多个点开始流向Cell,当前的输入和过去的Cell state的组合既传给Cell本身,还传给他的三个门,来决定如何处理该输入。黑点就是“门”,分别来决定是否让当前新的输入进入,擦除当前的Cell state,或者是否让那个状态影响当前网络的输出。$S_c$ 是记忆单元的当前状态,$g_y_in$是当前的输入。每一个门都可以关闭或者开启,在每一步,他们都会重组他们的开启或者关闭状态。
大的加粗的字母给出了每次操作的结果。
下图给出了简单的RN 和 LSTM单元的对比:
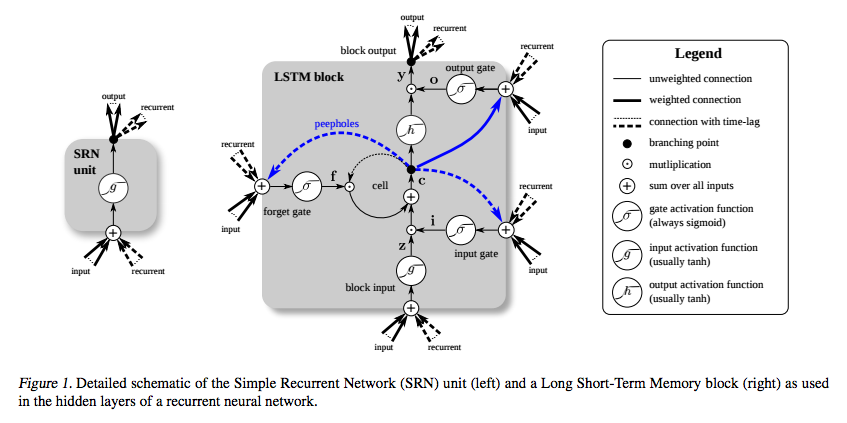
必须要注意到的是:LSTM的记忆单元给出了不同的角色来进行输入的相加和相乘。在两个流程图中,中心的加法符号,是LSTM的秘密。像他看起来那样的傻逼,这个基础的改变,在必须往深处回传时,能帮助他们保存固定的误差。并非通过将其当前状态与新的输入相乘来决定随后的Cell state,他们将其相加,而不是相乘,这两者是有很大区别的。(“遗忘门”依然采用相乘的方式。)
权重的不同集合为了输入 输出 和遗忘过滤输入。遗忘门 表示为线性特征函数,因为如果这个门打开,那么记忆Cell的当前状态就简单的乘以1,来以此向前传播多个时间步骤。
此外,给每一个LSTM引入1的偏差可以改善性能(Sutskever 推荐将bias设为5)。
你可能比较疑惑,LSTM是为了联系远距离出现的最终的输出,那么为何要引入“遗忘门”?是啊,记得多了,容易累啊,当然要选择性的遗忘一些东西来摆脱痛苦。哈哈,扯淡呢!但是,有时候,是的确需要遗忘的。例如:当你一个处理一个文本时,并且接近尾声了,那么你可能没有任何理由相信下一个文档与当前的文档有什么联系?对吧?所以,当网络开始输入下一个文档的相关内容时,应该将记忆单元置0,相当于暂时清除缓存,以准备下一个工作。
下面的流程图是一个正在工作的门:
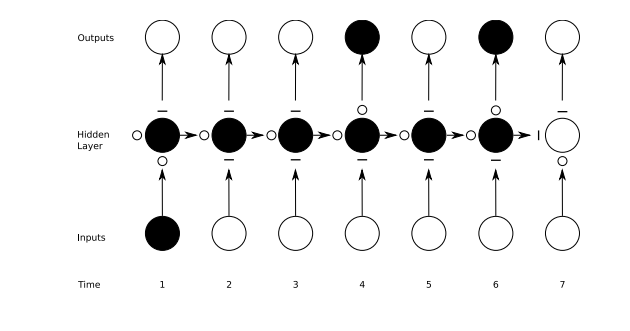
小段的直线代表 关闭的门,空白的小圆圈代表开着的门。在hidden layer下面的水平向下的线和圈是遗忘门。
前向网络只能是将一个输入映射到一个输出,但是RN 可以将一个输入映射到多个输出,像上图所示的那样,也可以从多个到多个,或者从多个到一个。
Capturing Diverse Time Scales and Remote Dependencies
...
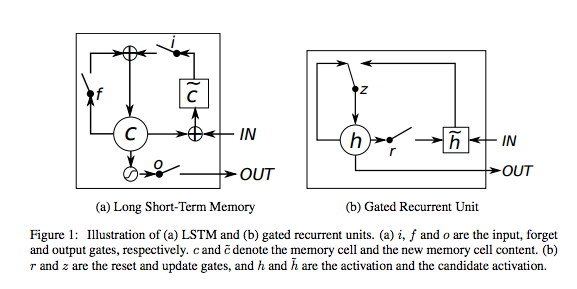
Gated Recurrent Units(GRUs)
一个GRU是一个基础的无输出gate的LSTM,所以每次时间步骤,完全从其记忆Cell中将内容写入更大的网络。
Code Sample:
只是提供一个代码链接:https://github.com/deeplearning4j/dl4j-0.4-examples/blob/master/src/main/java/org/deeplearning4j/examples/recurrent/character/GravesLSTMCharModellingExample.java

新手教程之:循环网络和LSTM指南 (A Beginner’s Guide to Recurrent Networks and LSTMs)的更多相关文章
- 循环神经网络与LSTM网络
循环神经网络与LSTM网络 循环神经网络RNN 循环神经网络广泛地应用在序列数据上面,如自然语言,语音和其他的序列数据上.序列数据是有很强的次序关系,比如自然语言.通过深度学习关于序列数据的算法要比两 ...
- Python编程之美:最佳实践指南PDF高清完整版免费下载|百度云盘|Python新手到进阶
百度云盘:Python编程之美:最佳实践指南PDF高清完整版免费下载 提取码:1py6 内容简介 <Python编程之美:最佳实践指南>是Python用户的一本百科式学习指南,由Pytho ...
- PyTorch教程之Training a classifier
我们已经了解了如何定义神经网络,计算损失并对网络的权重进行更新. 接下来的问题就是: 一.What about data? 通常处理图像.文本.音频或视频数据时,可以使用标准的python包将数据加载 ...
- [转]搬瓦工教程之九:通过Net-Speeder为搬瓦工提升网速
搬瓦工教程之九:通过Net-Speeder为搬瓦工提升网速 有的同学反映自己的搬瓦工速度慢,丢包率高.这其实和你的网络服务提供商有关.据我所知一部分上海电信的同学就有这种问题.那么碰到了坑爹的网络服务 ...
- jQuery EasyUI教程之datagrid应用(三)
今天继续之前的整理,上篇整理了datagrid的数据显示及其分页功能 获取数据库数据显示在datagrid中:jQuery EasyUI教程之datagrid应用(一) datagrid实现分页功能: ...
- Kali Linux系列教程之OpenVas安装
Kali Linux系列教程之OpenVas安装 文 /玄魂 目录 Kali Linux系列教程之OpenVas安装 前言 1. 服务器层组件 2.客户层组件 安装过程 Initial setup ...
- qq红心头像[中国心]制作教程之Photoshop教程
QQ红心头像[中国心]制作教程之Photoshop教程 中国最大的WEB开发资源网站及技术社区,阿里西西WEB开发 最近网络流传着很多qq红心头像,msn红心头像,中国心图标等等,最有些搞笑的是还有正 ...
- OpenVAS漏洞扫描基础教程之OpenVAS概述及安装及配置OpenVAS服务
OpenVAS漏洞扫描基础教程之OpenVAS概述及安装及配置OpenVAS服务 1. OpenVAS基础知识 OpenVAS(Open Vulnerability Assessment Sys ...
- Tkinter教程之Button篇(1)
本文转载自:http://blog.csdn.net/jcodeer/article/details/1811298 #Tkinter教程之Button篇(1)#Button功能触发事件'''1.一个 ...
随机推荐
- JVM-运行时数据区
运行时数据区示意图 ...
- PHP ceil() 函数
定义和用法 ceil() 函数向上舍入为最接近的整数. 语法 ceil(x) 参数 描述 x 必需.一个数. 说明 返回不小于 x 的下一个整数,x 如果有小数部分则进一位.ceil() 返回的类型仍 ...
- oracle 10gwindow7安装添加内容
F:\软件\database\stage\prereq\db\refhost.xml <!--Microsoft Windows 7 .Windows 8--> <OPERATING ...
- Motorola C118修改滤波器组件
所需工具: 热风枪.恒温焊台.镊子.助焊膏.锡丝.滤波器组件 关于怎么使用热风枪拆屏蔽盖将在后期更新视频,以下为修改滤波器流程.以下热风枪设置温度只针对快克957DW(不同品牌风枪和型号可能会有温差) ...
- 【LeetCode OJ】Word Break
Problem link: http://oj.leetcode.com/problems/word-break/ We solve this problem using Dynamic Progra ...
- Oracle PL/SQL高级应用 游标
游标可以处理SQL语句查询出来的结果集,进行逐条控制,其实游标在内存中申请空间,将自己指向SQL语句查询出来的结果集,有点像指针的感觉,游标使SQL更加的灵活. DECLARE CURSOR mycu ...
- Day04_JAVA语言基础第四天
1.循环(掌握) 1.什么时候使用(理解) 如果我们发现有很多重复内容的时候就要使用循环 2.好处(理解) 让我们的代码看起来更精炼了 3.循环的组成(理解) 1 初始化条件:一般定义的是一个初始变量 ...
- dedecms list 实现noflag
转自:http://blog.sina.com.cn/s/blog_7e53dd2b0101l3kq.html 替换include下arc.listview.class.php即可 经测试可行 但在更 ...
- angularjs 不同的controller之间值的传递
Sharing data between controllers in AngularJS I wrote this article to show how it can possible to pa ...
- GO简易聊天系统后台源码分享
本人是搞移动客户端开发的,业余时间接触到golang这么个可爱的囊地鼠,于是就写了这么个测试项目:简易版的聊天系统,功能包括注册,登陆,群聊和单聊,无需使用mysql,数据都存在了文本里.本人纯粹兴趣 ...