本文转之Pivotal的一个工程师的博客。觉得极好。
作者本人经常在StackOverflow上回答一个关系Spark架构的问题,发现整个互联网都没有一篇文章能对Spark总体架构进行很好的描述,作者可怜我们这些菜鸟,写了这篇文章,太感动了。本文读者需要一定的Spark的基础知识,至少了解Spark的RDD和DAG。
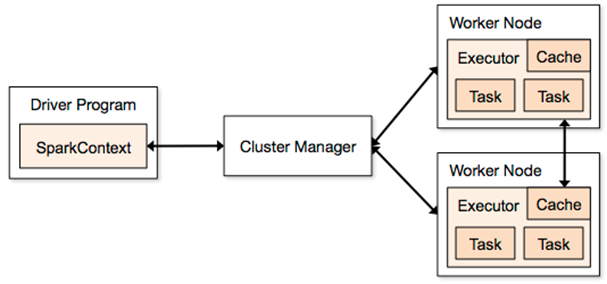
上图引入了很多术语:"Executor","Task","Cache","Worker Node"等等,当我开始学习Spark的时候,这几乎是整个互联网上唯一一张关于Spark架构的图了,我个人觉得该图缺失了一些很重要的概念或者是描述的
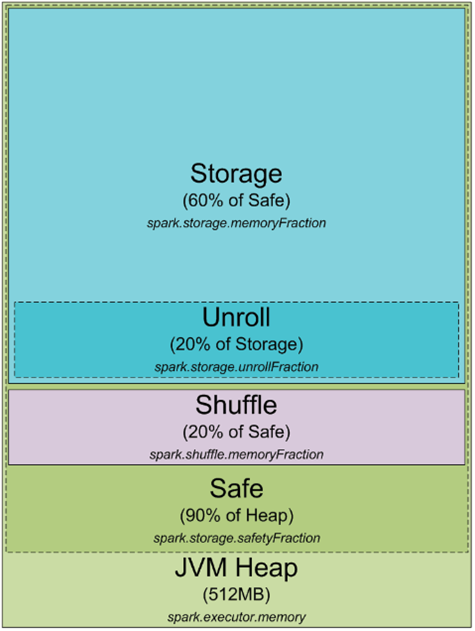
任何Spark的进程都是一个JVM进程,既然是一个JVM进程,那么就可以配置它的堆大小(-Xmx和-Xms),但是进程怎么使用堆内存和为什么需要它呢?下面是一个JVM堆空间下Spark的内存分配情况
默认情况下,Spark进程的堆空间是512mb,为了安全考虑同时避免OOM,Spark只允许利用90%的堆空间,spark中使用spark.storage.safetyFraction用来配置该值(默认是0.9). Spark作为一个内存计算工具,Spark可以在内存中存储数据,如果读过
http://0x0fff.com/spark-misconceptions/, 就会明白Spark不是一个真的内存工具,它只是把内存作为他的LRU缓存,这样大量的内存被用来缓存正在计算的数据,该部分占safe堆的60%,Spark使用spark.storage.memoryFraction控制该值,如果想知道Spark中能缓存了多少数据,可以统计所有Executor的堆大小,乘上safeFraction和memoryFraction,默认是54%,这就是Spark可用缓存数据使用的堆大小,
最后要讲到的一块内存是"unroll",该快内存用于unroll计算如下:spark.storage.unrollFraction * spark.storage.memoryFraction * spark.storage.safetyFraction 。当我们需要在内存展开数据块的时候使用,那么为什么需要展开呢?因为spark允许以序列化和非序列化两种方式存储数据,序列化后的数据无法直接使用,所以使用时必须要展开。该部分内存占用缓存的内存,所以如果需要内存用于展开数据时,如果这个时候内存不够,那么Spark LRU缓存中的数据会删除一些快。
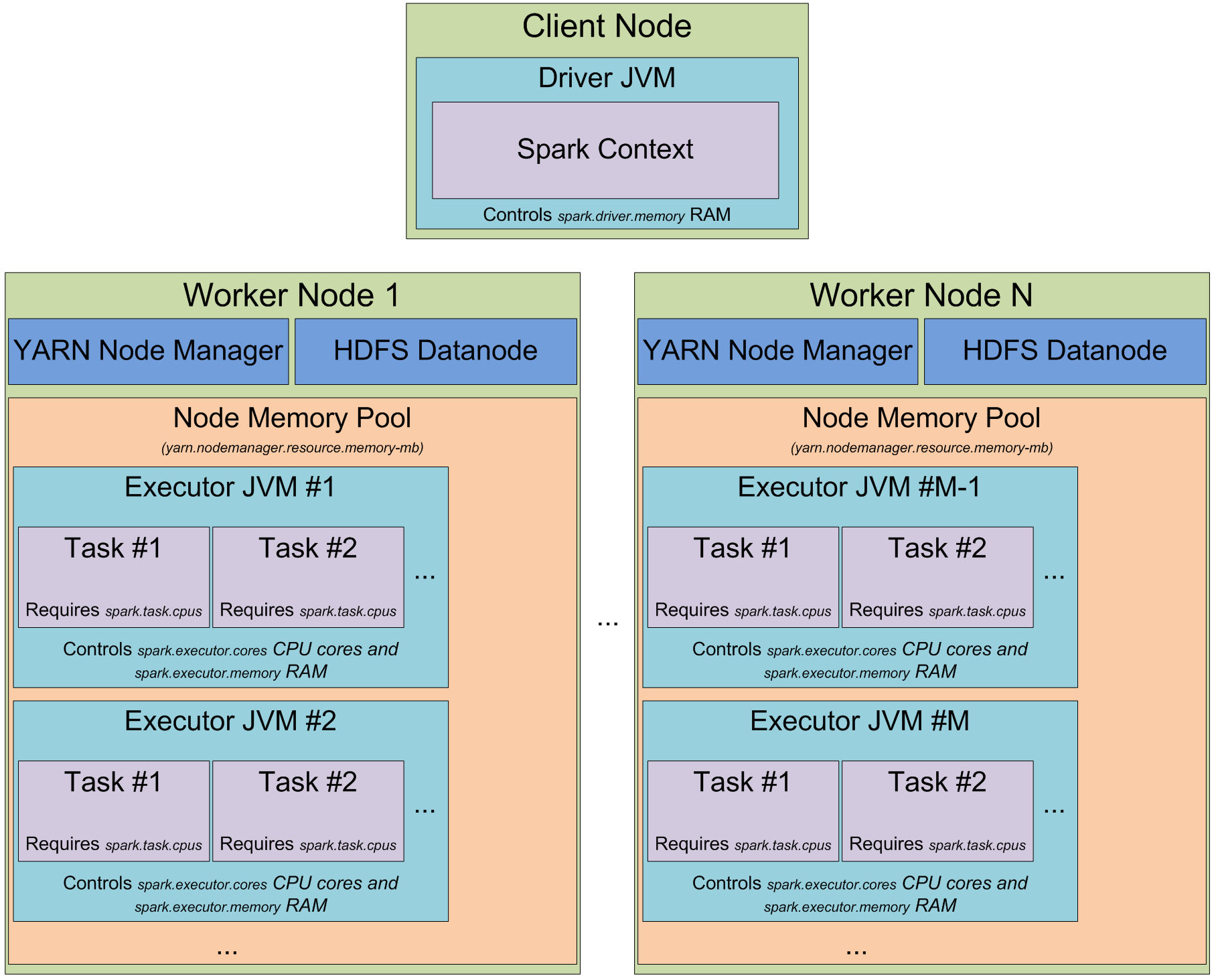
此时应该清楚知道spark怎么使用JVM中堆内存了,现在切换到集群模式,当你启动一个spark集群,如何看待它,下图是YARN模式下的
当运行在yarn集群上时,Yarn的ResourceMananger用来管理集群资源,集群上每个节点上的NodeManager用来管控所在节点的资源,从yarn的角度来看,每个节点看做可分配的资源池,当向ResourceManager请求资源时,它返回一些NodeManager信息,这些NodeManager将会提供execution container给你,每个execution container就是满足请求的堆大小的JVM进程,JVM进程的位置是由ResourceMananger管理的,不能自己控制,如果一个节点有64GB的内存被yarn管理(通过yarn.nodemanager.resource.memory-mb配置),当请求10个4G内存的executors时,这些executors可能运行在同一个节点上。
当在yarn上启动spark集群上,可以指定executors的数量(-num-executors或者spark.executor.instances),可以指定每个executor使用的内存(-executor-memory或者spark.executor.memory),可以指定每个executor使用的cpu核数(-executor-cores或者spark.executor.cores),指定每个task执行使用的core数(spark.task.cpus),也可以指定driver应用使用的内存(-driver-memory和spark.driver.memory)
当在集群上执行应用时,job会被切分成stages,每个stage切分成task,每个task单独调度,可以把executor的jvm进程看做task执行池,每个executor有 spark.executor.cores / spark.task.cpus execution 个执行槽,这里有个例子:集群有12个节点运行Yarn的NodeManager,每个节点有64G内存和32的cpu核,每个节点可以启动2个executor,每个executor的使用26G内存,剩下的内用系统和别的服务使用,每个executor有12个cpu核用于执行task,这样整个集群有12 machines * 2 executors per machine * 12 cores per executor / 1 core = 288 个task执行槽,这意味着spark集群可以同时跑288个task,整个集群用户缓存数据的内存有0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB.
到目前为止,我们已经了解了spark怎么使用JVM的内存以及集群上执行槽是什么,目前为止还没有谈到task的一些细节,这将在另一个文章中提高,基本上就是spark的一个工作单元,作为exector的jvm进程中的一个线程执行,这也是为什么spark的job启动时间快的原因,在jvm中启动一个线程比启动一个单独的jvm进程块(在hadoop中执行mapreduce应用会启动多个jvm进程)
下面将关注spark的另一个抽象:partition, spark处理的所有数据都会切分成partion,一个parition是什么以及怎么确定,partition的大小完全依赖数据源,spark中大部分用于读取数据的方法都可以指定生成的RDD中partition的个数,当从hdfs上读取一个文件时,会使用Hadoop的InputFormat来处理,默认情况下InputFormat返回每个InputSplit都会映射RDD中的一个Partition,大部分存储在HDFS上的文件每个数据块会生成一个InputSplit,每个数据块大小为64mb和128mb,因为HDFS上面的数据的块边界是按字节来算的(64mb一个块),但是当数据被处理是,它又要按记录进行切分,对于文本文件来说切分的字符就是换行符,对于sequence文件来说,他是块结束,如果是压缩文件,整个文件都被压缩了,它不能按行进行切分了,整个文件只有一个inputsplit,这样spark中也会只有一个parition,在处理的时候需要手动的repatition。
- 把传统的基于sql的企业信息中心迁移到spark 架构应该考虑的几点思考...[修改中]
把传统的基于sql的企业信息中心迁移到spark 架构应该考虑的几点 * 理由: 赶时髦, 这还不够大条么? > 数据都设计为NO-SQL模式, 只有需要search的才建立2级索引. 就可以 ...
- 从spark架构中透视job
本博文的主要内容如下: 1.通过案例观察Spark架构 2.手动绘制Spark内部架构 3.Spark Job的逻辑视图解析 4.Spark Job的物理视图解析 1.通过案例观察Spark架构 sp ...
- 大数据 Spark 架构
一.Spark的产生背景起源 1.spark特点 1.1轻量级快速处理 Saprk允许传统的hadoop集群中的应用程序在内存中已100倍的速度运行即使在磁盘上也比传统的hadoop快10倍,Spar ...
- Spark架构
Spark架构 为了更好地理解调度,我们先来鸟瞰一下集群模式下的Spark程序运行架构图. 1. Driver Program 用户编写的Spark程序称为Driver Progr ...
- [Spark]Spark章1 Spark架构浅析
Spark架构 Spark架构采用了分布式计算中的Master-Slave模型.集群中运行Master进程的节点称为Master,同样,集群中含有Worker进程的节点为Slave.Master负责控 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- Spark 概念学习系列之从spark架构中透视job(十六)
本博文的主要内容如下: 1.通过案例观察Spark架构 2.手动绘制Spark内部架构 3.Spark Job的逻辑视图解析 4.Spark Job的物理视图解析 1.通过案例观察Spark架构 s ...
- Spark架构解析(转)
Application: Application是创建了SparkContext实例对象的Spark用户,包含了Driver程序, Spark-shell是一个应用程序,因为spark-shell在启 ...
- Spark- Spark内核架构原理和Spark架构深度剖析
Spark内核架构原理 1.Driver 选spark节点之一,提交我们编写的spark程序,开启一个Driver进程,执行我们的Application应用程序,也就是我们自己编写的代码.Driver ...
随机推荐
- web在线打印,打印阅览,打印维护,打印设计
winform打印的方案比较多,实现也比较容易,而且效果也非常炫:但现在越来越多的系统是web系统,甚至是移动端.网上也有非常的web打印方案,但各式各样的问题非常多,比如js兼容性,稳定性等一直缠绕 ...
- [译]Testing Node.js With Mocha and Chai
原文: http://mherman.org/blog/2015/09/10/testing-node-js-with-mocha-and-chai/#.ViO8oBArIlJ 为什么要测试? 在此之 ...
- func_get_arg、func_get_args、func_num_args实现PHP伪重载
今天在看书的时候,发现书上有这么一条:函数重载的替代方法——伪重载 确实,在PHP中没有函数重载这个概念,让很多时候我们无法进行一些处理,甚至有时候不得不在函数后面定义好N个参数在看到了func_ge ...
- PHP中常见的五种设计模式
设计模式只是为 Java架构师准备的 — 至少您可能一直这样认为.实际上,设计模式对于每个人都非常有用.如果这些工具不是 “架构太空人” 的专利,那么它们又是什么?为什么说它们在 PHP 应用程序中非 ...
- 【Alpha】Daily Scrum Meeting第十次
一.本次Daily Scrum Meeting主要内容 每个人学习情况 测试的任务的安排 Alpha版本展示的具体内容 二.任务安排 学号尾数 昨天做的任务 今天做的任务 任务用时 612 完成将计时 ...
- MyEclispe发布web项目-遁地龙卷风
(-1)写在前面 我用的是MyEclipse8.5. 还记得以前帮助一个女同学解决问题的时候,特意情调了要先启动服务在发布项目,其实单独的时候都是知道的,总和起来后就容易片面的给出结论.因为不会发生问 ...
- Jenkins的使用
参考: http://www.cnblogs.com/sunzhenchao/archive/2013/01/30/2883289.html
- [BZOJ1146][CTSC2008]网络管理Network
[BZOJ1146][CTSC2008]网络管理Network 试题描述 M公司是一个非常庞大的跨国公司,在许多国家都设有它的下属分支机构或部门.为了让分布在世界各地的N个 部门之间协同工作,公司搭建 ...
- ubuntu下MySQL中文乱码(新版本Mysql修改方法)
前几天在开发的时候出现了中文查询阿里云服务器上的mysql的时候,查询出来的值为空,找了好久终于发现原因是ubuntu下的mysql无法识别中文,这就涉及到要调整编码格式啦!!!! 然后就在网上查了许 ...
- mysql 优化实例之索引创建
mysql 优化实例之索引创建 优化前: pt-query-degist分析结果: # Query 23: 0.00 QPS, 0.00x concurrency, ID 0x78761E301CC7 ...