rabbitmq+sleuth+zinkip 分布式链路追踪
我们都知道,微服务之间通过feign传递,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路,在每条链路中任何一个依赖服务出现延迟超时或者错误都有可能引起整个请求最后的失败。当业务流程足够复杂时,一个完整的HTTP请求调用链一般会经过多个微服务系统,要通过日志来跟踪一整个调用链变得不再那么简单。通过sleuth可以很方便的看出每个采集请求的耗时情况,分析出哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时,可以针对业务做一些优化措施。所以我们可以通过我们可以通过Spring Cloud Sleuth来解决这个问题。这里我们将演示如何通过Spring Cloud Sleuth来追踪这个过程,并借助Zipkin以图形化界面的方式展示。 展示之前,分别介绍一下rabbitmq、sleuth、zinkip。
rabbitmq
- RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而群集和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
sleuth和zinkip
- sleuth 是spring cloud的组成部分之一,为springcloud应用实现了一种分布式追踪解决方案,其兼容了zinkip,HTrace和log-based追踪
- Zipkin 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper 的论文设计而来,由 Twitter公司开发贡献。其主要功能是聚集来自各个异构系统的实时监控数据,用来追踪微服务架构下的系统延时问题。Zipkin 的用户界面可以呈现一幅关联图表,以显示有多少被追踪的请求通过了每一层应用。Zipkin 以 Trace 结构表示对一次请求的追踪,又把每个 Trace 拆分为若干个有依赖关系的 Span。在微服务架构中,一次用户请求可能会由后台若干个服务负责处理,那么每个处理请求的服务就可以理解为一个 Span(可以包括 API 服务,缓存服务,数据库服务以及报表服务等)。当然这个服务也可能继续请求其他的服务,因此 Span 是一个树形结构,以体现服务之间的调用关系。Zipkin 的用户界面除了可以查看 Span 的依赖关系之外,还以瀑布图的形式显示了每个 Span 的耗时情况,可以一目了然的看到各个服务的性能状况。
sleuth中的一些术语
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址) ,span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
- Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式工程,你可能需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
接下来就开始搭建
这里cloud版本用的Greenwich.SR1,boot使用的是2.1.6
1.在pom.xml中 引入sleuth依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2.模拟两个日志 这两个服务之间通过feign调用,由test调用system,这里本来有一个注册中心,这里就不在演示了
test模块
@Slf4j
@RestController
public class TestController {
@Autowired
private IHelloService helloService;
@GetMapping("hello")
public String hello(String name) {
log.info("Feign调用system的/hello服务");
return this.helloService.hello(name);
}
}
在test模块的service包下创建IHelloService
@FeignClient(value = "system",contextId = "helloServiceClient")
public interface IHelloService {
@GetMapping("hello")
String hello(@RequestParam("name") String name);
}
system 模块
@Slf4j
@RestController
public class TestController {
@GetMapping("hello")
public String hello(String name) {
log.info("/hello服务被调用");
return "hello" + name;
}
}
3.访问接口 localhost:8202/test/hello?name=sleuth:会出现两个我们自定义的日志
启动的时候查看test模块产生的
2019-08-23 14:22:51.774 INFO [test,72bb0469bee07104,72bb0469bee07104,false] 22728 --- [nio-8202-exec-1] c.m.f.s.test.controller.TestController : Feign调用system的/hello服务
启动的时候查看system模块产生的
2019-08-23 14:22:52.469 INFO [system,72bb0469bee07104,43597a6edded6f2e,false] 812 --- [nio-8201-exec-2] c.m.f.s.s.controller.TestController : /hello服务被调用
可以看到,日志里出现了[Test,72bb0469bee07104,72bb0469bee07104,false]信息,这些信息由Spring Cloud Sleuth生成,用于跟踪微服务请求链路。这些信息包含了4个部分的值,它们的含义如下:
- system微服务的名称,与spring.application.name对应;
- 72bb0469bee07104称为Trace ID,在一条完整的请求链路中,这个值是固定的。观察上面的日志即可证实这一点;
- 43597a6edded6f2e称为Span ID,它表示一个基本的工作单元;
- false表示是否要将该信息输出到Zipkin等服务中来收集和展示,这里我们还没有集成Zipkin,所以为false。
下面我们来整合Zipkin
在整合Zipkin之前,我们需要先搭建RabbitMQ。RabbitMQ用于收集Sleuth提供的追踪信息,然后Zipkin Server从RabbitMQ里获取,这样可以提升性能。
在安装RabbitMQ之前,需要先安装Erlang/OTP,下载地址为:http://www.erlang.org/downloads/,下载exe文件安装即可。
安装完毕后,下载RabbitMQ,下载地址为 :
http://www.rabbitmq.com/install-windows.html,下载exe文件安装即可。
安装完RabbitMQ之后,我们到RabbitMQ安装目录的sbin下执行如下命令
rabbitmq-plugins enable rabbitmq_management
然后在浏览器中输入http://localhost:15672,默认用户名和密码都是guest,登录后可看到:
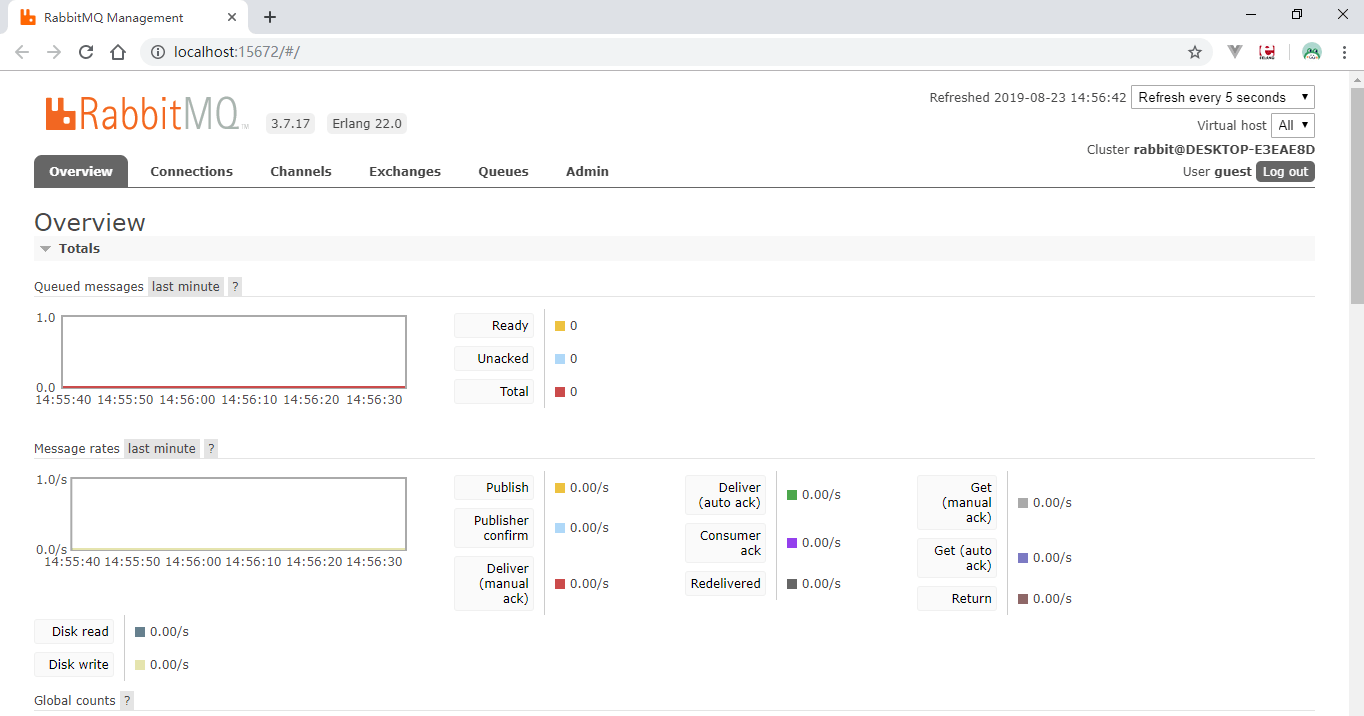
点击Admin Tab页面,新增一个用户:
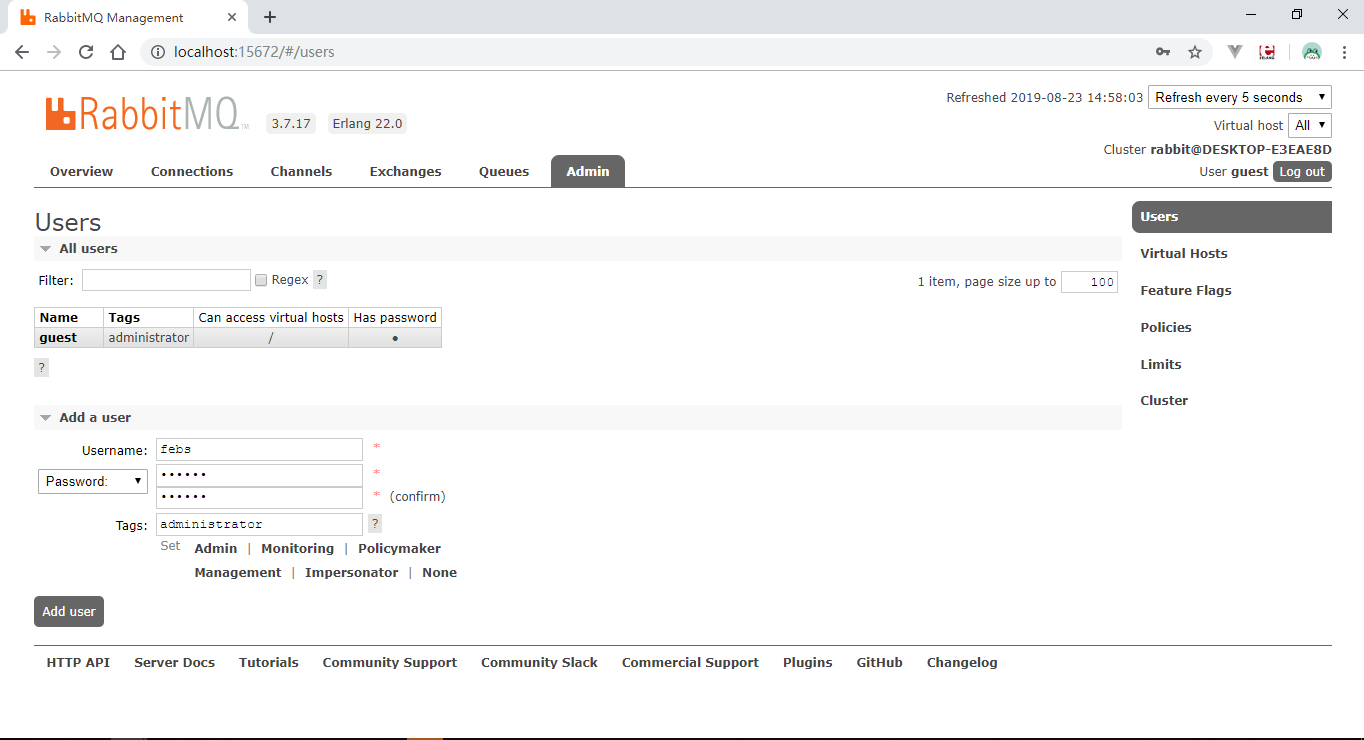
用户名为febs,密码为123456,角色为管理员。新添加的用户还是No access状态,需要进一步对该用户进行授权后,方可以远程通过该用户名访问。点击该新增用户名。进入授权页面,点击Set permission按钮,进行用户授权操作。
安装好RabbitMQ后,我们开始整合Zipkin。在较低版本的Spring Cloud中,我们可以自己搭建Zipkin Server,现在我们只能使用官方搭建好的Zipkin Server,地址为:https://github.com/openzipkin/zipkin
在cmd窗口下运行下面这条命令(windows下没有curl环境的话,可以在git bash中运行这条命令),下载zipkin.jar:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
如果下载速度极慢,可以复制链接到迅雷下载中下载,下载后重命名为zipkin.jar即可。
zipkin支持将追踪信息保存到MySQL数据库,所以在运行zipkin.jar之前,我们先准备好相关库表,SQL脚本地址为:
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql。
库表准备好后,运行下面这条命令启动zipkin.jar:
java -jar zipkin.jar --server.port=8402 --zipkin.storage.type=mysql --zipkin.storage.mysql.db=febs_cloud_base --zipkin.storage.mysql.username=root --zipkin.storage.mysql.password=123456 --zipkin.storage.mysql.host=localhost --zipkin.storage.mysql.port=3306 --zipkin.collector.rabbitmq.addresses=localhost:5672 --zipkin.collector.rabbitmq.username=febs --zipkin.collector.rabbitmq.password=123456
上面命令指定了数据库链接和RabbitMQ链接信息。更多可选配置可以解压zipkin.jar,查看zipkin\BOOT-INF\classes路径下的zipkin-server-shared.yml配置类源码。
启动好zipkin.jar后,在对应模块的pom里引入如下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
修改对应模块的application.yml
spring:
zipkin:
sender:
type: rabbit
sleuth:
sampler:
probability: 1
rabbitmq:
host: localhost
port: 5672
username: febs
password: 123456
spring.zipkin.sender.type指定了使用RabbitMQ收集追踪信息;
spring.sleuth.sampler.probability默认值为0.1,即采样率才1/10,发送10笔请求只有一笔会被采集。为了测试方便,我们可以将它设置为1,即100%采样;
spring.rabbitmq用于配置RabbitMQ连接信息,你可能会问,为什么刚刚RabbitMQ端口是15672,这里却配置为5672,是不是写错了呢?其实不是,15672是RabbitMQ的管理页面端口,5672是AMPQ端口。
添加好配置后,启动system和test模块,发送一笔localhost:8202/test/hello?name=夏天请求后,使用浏览器访问http://localhost:8402/zipkin/链接,然后点击图中所示
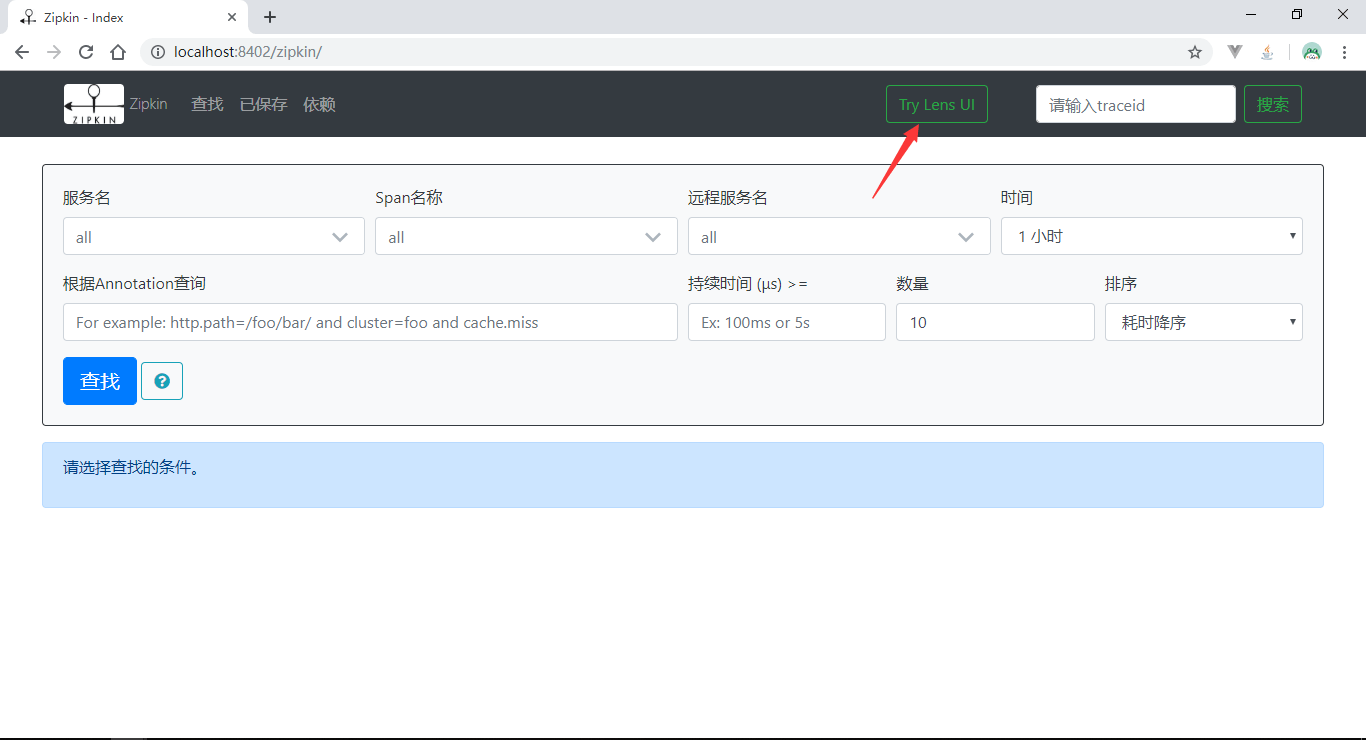
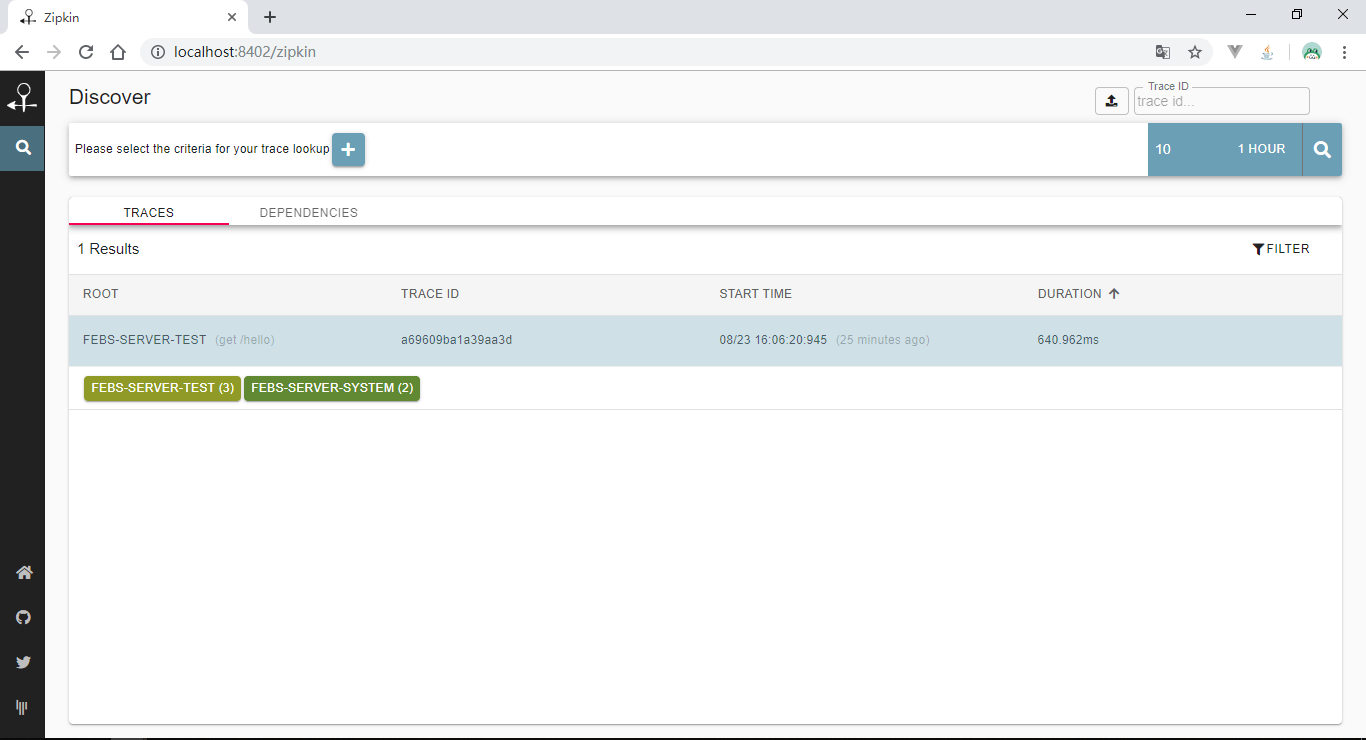
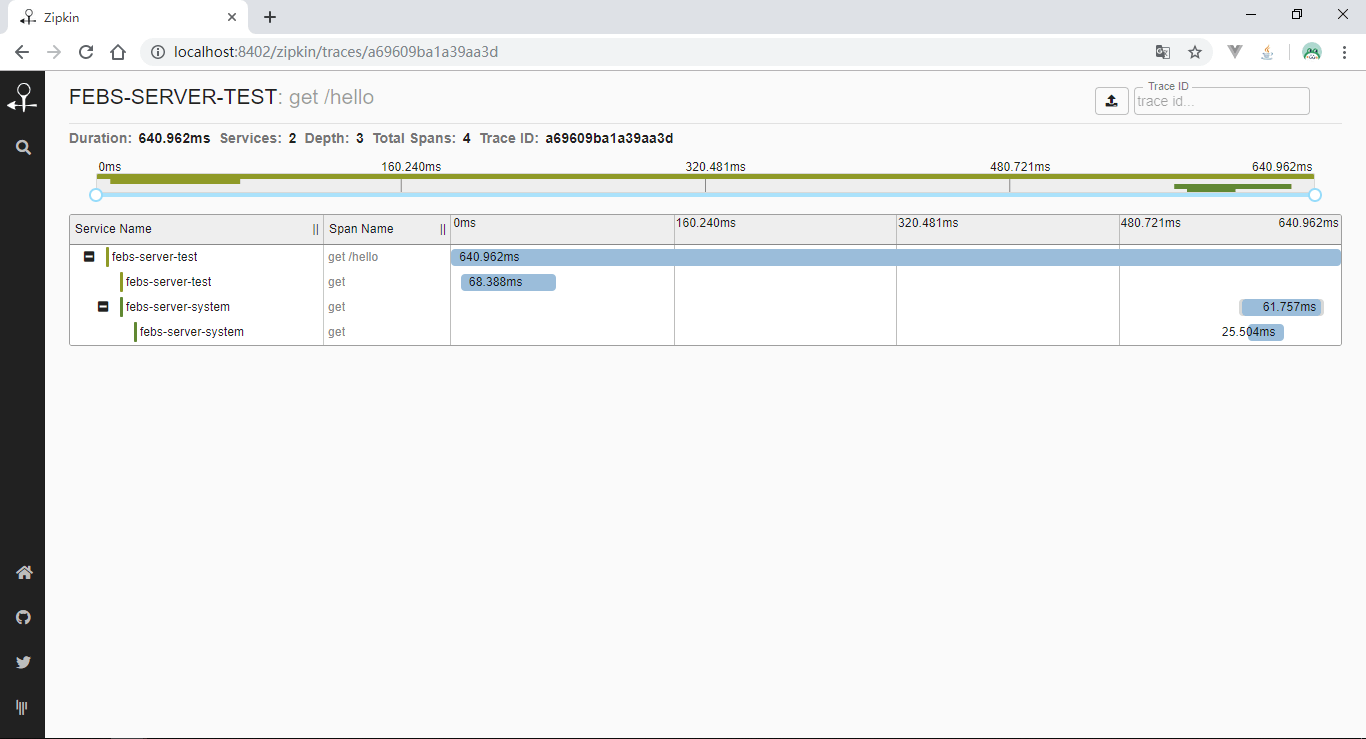
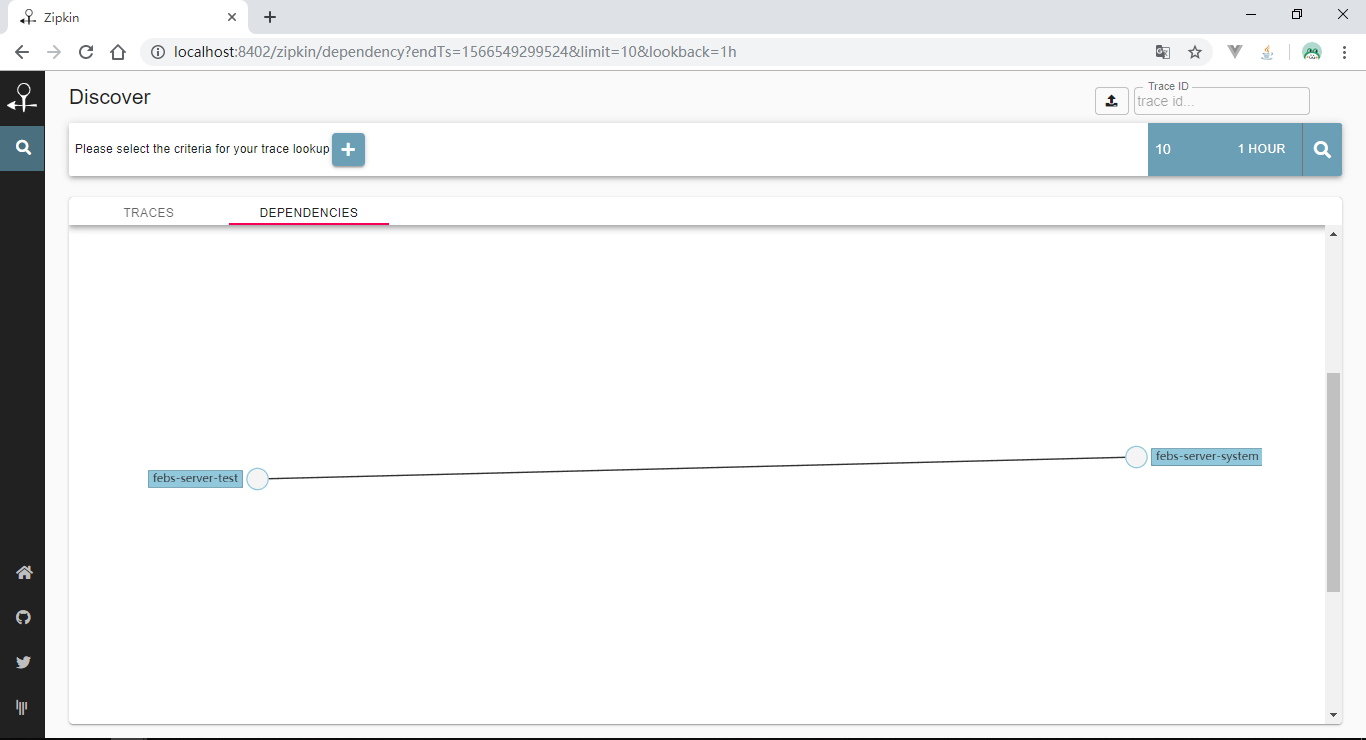
查看依赖关系:
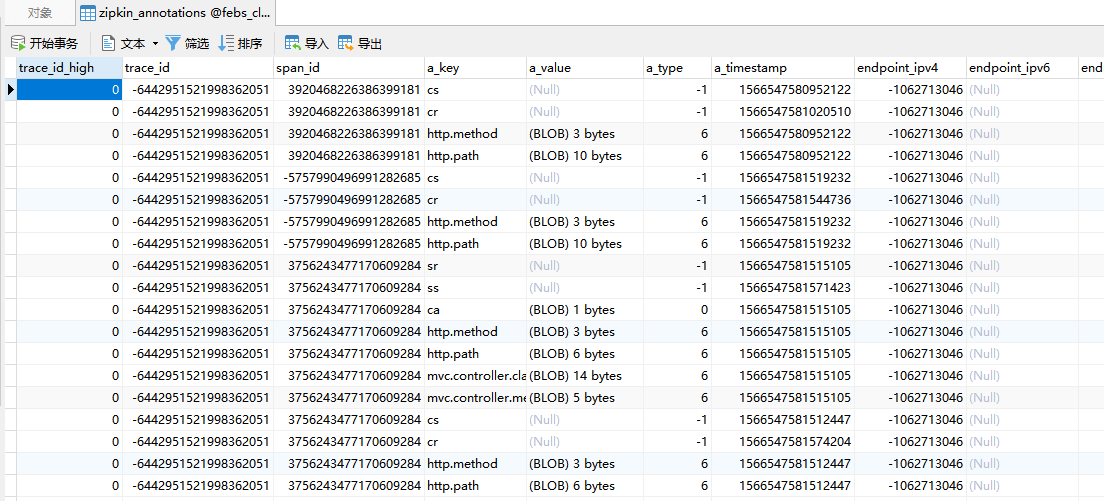
查看数据表,看是否存储了信息:
公众号:良许Linux

有收获?希望老铁们来个三连击,给更多的人看到这篇文章
rabbitmq+sleuth+zinkip 分布式链路追踪的更多相关文章
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- 分布式链路追踪之Spring Cloud Sleuth+Zipkin最全教程!
大家好,我是不才陈某~ 这是<Spring Cloud 进阶>第九篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得 ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- 分布式链路追踪自从用了SkyWalking,睡得真香!
本篇文章介绍链路追踪的另外一种解决方案Skywalking,文章目录如下: 什么是Skywalking? 上一篇文章介绍了分布式链路追踪的一种方式:Spring Cloud Sleuth+ZipKin ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- NET Core微服务之路:SkyWalking+SkyApm-dotnet分布式链路追踪系统的分享
对于普通系统或者服务来说,一般通过打日志来进行埋点,然后再通过elk或splunk进行定位及分析问题,更有甚者直接远程服务器,直接操作查看日志,那么,随着业务越来越复杂,企业应用也进入了分布式服务化的 ...
- SkyWalking+SkyApm-dotnet分布式链路追踪系统
SkyWalking+SkyApm-dotnet分布式链路追踪系统 对于普通系统或者服务来说,一般通过打日志来进行埋点,然后再通过elk或splunk进行定位及分析问题,更有甚者直接远程服务器,直接操 ...
随机推荐
- 无法解析的外部符号 "public: virtual struct CRuntimeClass * _
SetupPropertyPage.obj : error LNK2001: 无法解析的外部符号 "public: virtual struct CRuntimeClass * __this ...
- 全网最全fiddler使用教程和fiddler如何抓包(fiddler手机抓包)-笔者亲测
一.前言 抓包工具有很多,比如常用的抓包工具Httpwatch,通用的强大的抓包工具Wireshark.为什么使用fiddler?原因如下:1.Wireshark是通用的抓包工具,但是比较庞大,对于只 ...
- 工业4.0:换热站最酷设计—— Web SCADA 工业组态软件界面
前言 随着工业4.0的不断普及与发展,以及国民经济的飞速前进,我国的城市集中供热规模也不断扩大,科学的管理热力管网具有非常重大的经济和社会效益.目前热力系统,如换热站大都采用人工监控,人工监控不仅浪费 ...
- Java WebService _CXF、Xfire、AXIS2、AXIS1_四种发布方式(优缺点对比)
xis,axis2,Xfire以及cxf对比 http://ws.apache.org/axis/ http://axis.apache.org/axis2/java/core/ http://xfi ...
- java SSM框架单元测试最佳实战代码
具体的代码参考链接:https://pan.baidu.com/s/1e9UTyidi4OMBwYydhwH-0g 密码:rmvs 本教程采用的是对单元测试的dao层.service层.control ...
- 都在讲DevOps,但你知道它的发展趋势吗?
根据最近的一项集体研究,DevOps的市场在2017年创造了约29亿美元的产值,预计到2022年,这个数字将达到约66亿美元.人工智能的融入和安全性的融入,加上向自动化的巨大转变,可合理预测,在202 ...
- 一种基于LQR使输出更加稳定的算法(超级实用)
已知: 令: 则: 以上三式成立 具体步骤: 状态量最后一行加入“上一时刻的控制量”: A,B根据上述方法变形: Q,R增加维度(控制量一般都为一个,此时R维度不变): 最关键的是——输出量已经变为“ ...
- Java基础之Synchronized原理
思维导图svg: https://note.youdao.com/ynoteshare1/index.html?id=eb05fdceddd07759b8b82c5b9094021a&type ...
- CSS粘性定位
粘性定位(position:sticky) 1.定义 粘性定位可以被认为是相对定位和固定定位的混合.元素在跨越特定阈值前为相对定位,之后为固定定位.(MDN传送门) 这个特定阈值指的是 top, ri ...
- Appium移动端自动化测试--搭建模拟器和真机测试环境
详细介绍安装Android Studio及Android SDK.安装Appium Server. 文章目录如下 目录 文章目录如下 模拟器--安装Android Studio及Android SDK ...