django学习-15.ORM查询方法汇总
1.前言
django的ORM框架提供的查询数据库表数据的方法很多,不同的方法返回的结果也不太一样,不同方法都有各自对应的使用场景。
主要常用的查询方法个数是13个,按照特点分为这4类:
- 方法返回值是可迭代对象QuerySet:all(),filter(),exclude(),order_by(),reverse(),values(),values_list(),distinct();
- 方法返回值是单个对象:get(),first(),last();
- 方法返回值是布尔值:exists();
- 方法返回值是数字:count();
细节:
①.学习任何一个web开发框架比如django,框架都会提供满足90%的开发人员使用的封装的很健壮的很多方法,每个方法都能实现相应的功能,这样开发人员不用花大量时间去写这些类似的方法也就避免了重复造轮子而且开发人员自己造的轮子一般健壮性不高适用场景不多。所以对于使用框架的我们而言,知道框架提供了哪些方法并知道每个方法具体怎么用的例子,我们就能很轻松地进行业务开发!
2.数据准备
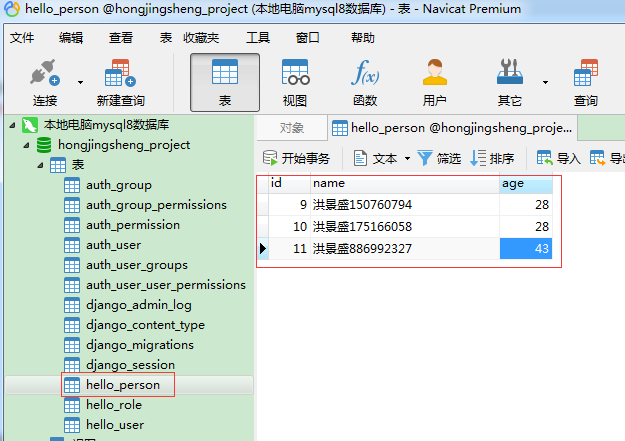
为了结合实际例子,来验证这13个查询方法怎么使用,需要提前在指定的数据表里造好数据。
所以,我选择用【hello_person】表的这三条数据当做测试数据。
3.方法返回值是可迭代对象QuerySet的每个查询方法的如何使用的完整记录
细节:
①.通过之前的接口调试,我们知道视图函数【search_person】已经能被正常调用并返回我们预期的结果值。所以我们每次验证一个查询方法,就可以通过改造这个视图函数【search_person】里的相关代码逻辑来进行验证。
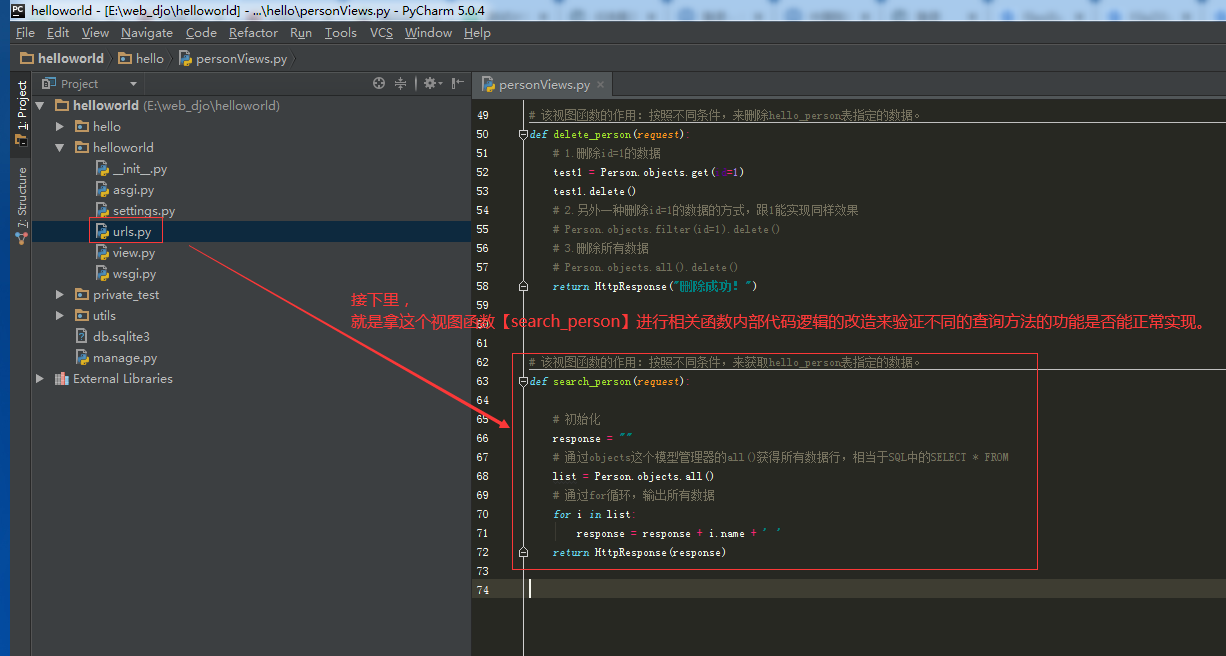
3.1.查询方法【all()】如何使用的完整记录
细节:
①.首先,我们知道查询一张数据表【hello_person】的所有数据的原生sql语句是:select * from hello_peroson。
②.但是,我们通过ORM框架提供的任何一个方法就都不需要写原生sql语句,比如执行这行代码【allData = 一张数据表对应的类名称.objects.all()】就能返回这张表的所有数据即所有数据都存储在这个变量【allData】里,变量【allData】是可迭代对象QuerySet,即我们要记住变量【allData】在此时是一个可迭代对象,并没有直接给我们返回全部数据而是间接返回全部数据。如果要取出可迭代对象【allData】里的具体的数据表数据,必须要用for循环进行读取,因为for循环就是专门用来处理列表和字典和元祖和可迭代对象的这些可被迭代的数据类型!
③.可迭代对象QuerySet的初步理解:可以把python语言里的可迭代对象QuerySet看成是java语言里的结果集,结果集可以看成是列表,结果集的作用是用于存储每个不同的对象/不同的元祖/不同的字典。而我们也知道每个对象都是唯一的因为每个对象内存地址都是唯一的,每个类被实例化一次后就会生成对应的一个对象,我们可以通过对象去调用类里面的相关类属性相关方法去获取我们想要的具体的数据表表数据。
④.通过ORM框架提供的【all() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
⑤.
问题:
结果集为什么基本用来存储从数据表获取的数据?
大概答案:
假如一张数据表有10万条数据,结果集里肯定有10万个不同的对象,通过每个对象可以方便后期获取对应的这条数据表数据的相关表字段数据。
django会对【all()】方法返回的这个可迭代对象QuerySet类型数据进行缓存,这是为了提高查询效率。也就是说,在我们创建一个迭代对象QuerySet的时候,django并不会立即向数据库发出查询命令而只是获取到对应数据里每条表数据对应的每个不同的模型类对象,只有在我们需要用到这个迭代对象QuerySet(通过for循环去调用模型类的对象)的时候才会触发调用模型类对象里的相关方法或者相关类属性去执行相关sql语句的查询命令。
⑥.
问题:如何用比较接地气的文案来描述用于存储对象的结果集的作用?
大概答案:
比如一张数据表A里有10条数据,把一张数据表A的每条数据看成一个结果,我们就需要用每个不同的对象去装载每个不同的结果。
就比如:一辆车装一个人,一个对象装一个结果。
然后现在有10个不同的人,就必须需要10辆不同的车。
可以把结果集理解为是一个很大的装车的集装箱,可以通过这个集装箱装这10辆车。
最终,我们拿到了这个集装箱,可以通过【for循环】这个开集装箱工具去获取到所有的车所有的人和每个人不同的具体数据。
⑦.
问题:
3.1.1.第一步:我们可以打印出可迭代对象的值是什么。

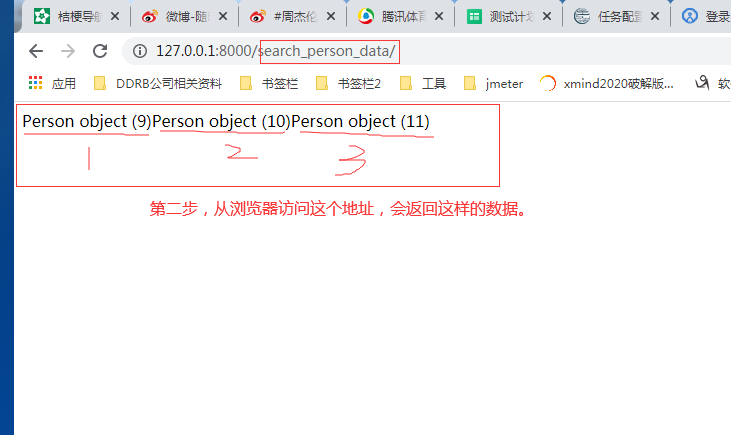
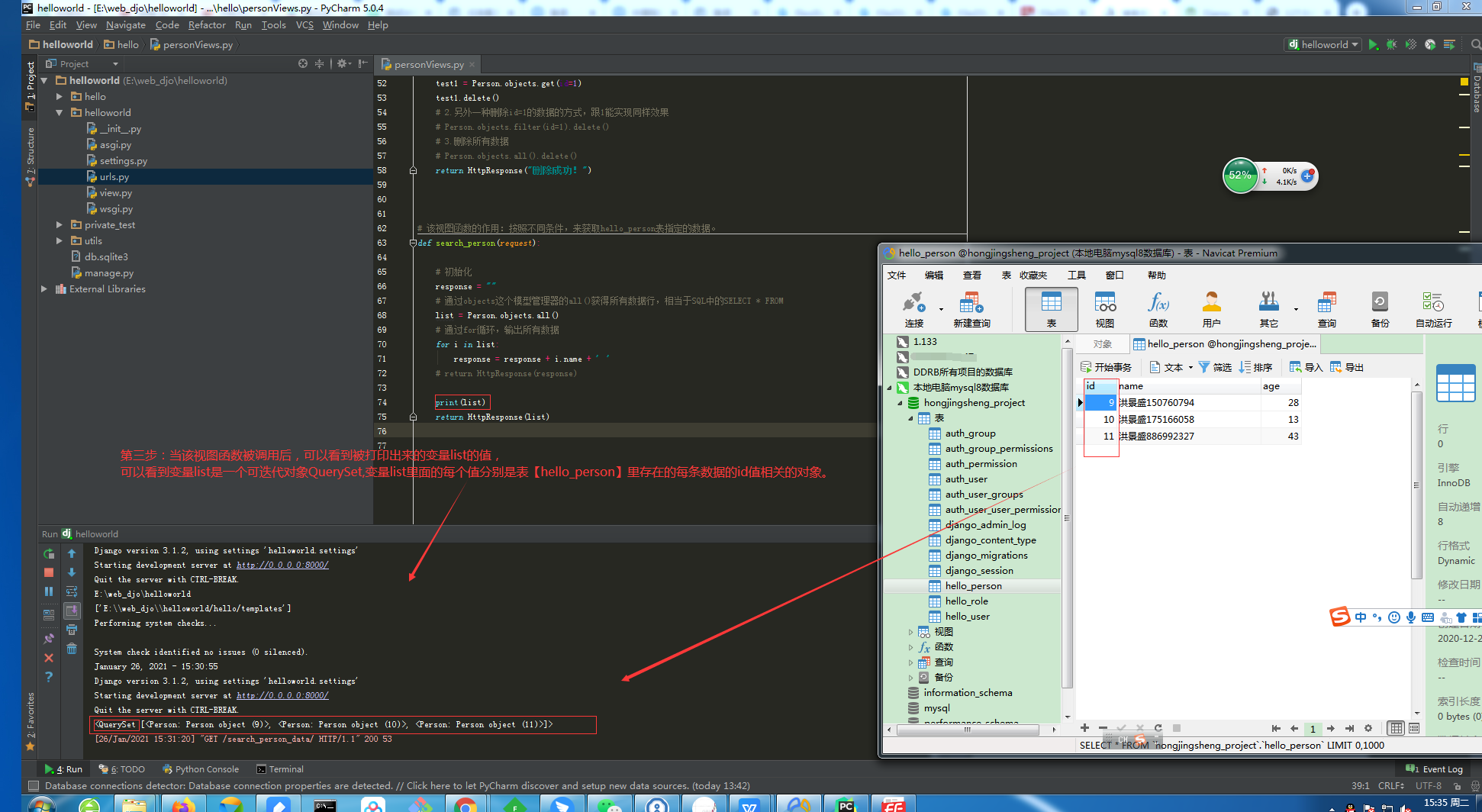
3.1.2.第二步:查询方法【all()】的具体使用。

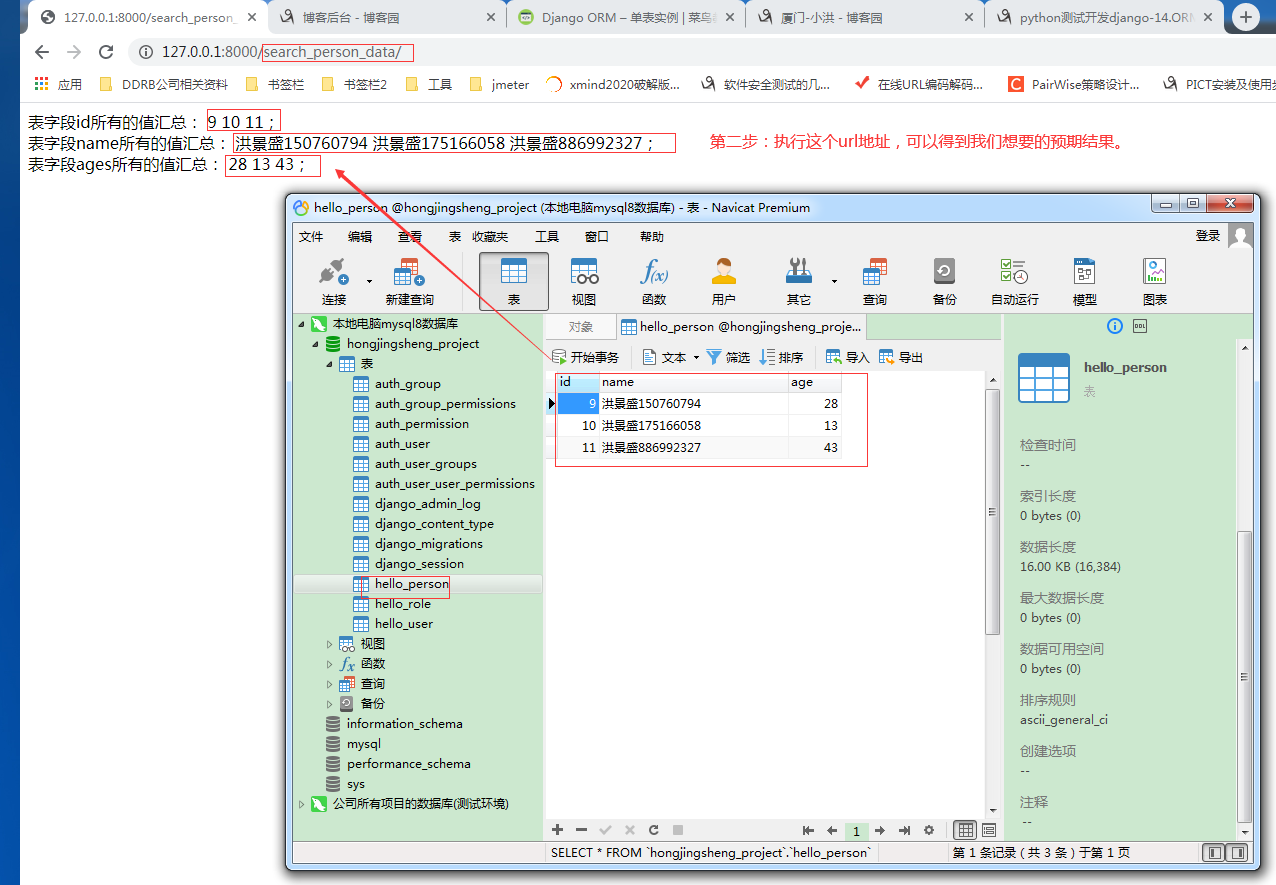
细节:
①.相关源码如下:
def search_person(request):
'''1.通过方法all()间接获取到hello_person表里的三个表字段id,name,age的所有数据'''
# 第一步:新增三个数据类型为str的变量,初始值都设置为空,用于后续存储数据;
ids = ''
names = ''
ages = ''
# 第二步:通过调用方法all(),返回一个数据类型为可迭代对象QuerySet的变量res;
res = Person.objects.all()
# 第三步:通过for循环,获取我们想要的数据;
for i in res:
ids = ids + " " + str(i.id) # 我们把表字段id的值都存储在变量ids;
names = names + " " + i.name # 我们把表字段name的值都存储在变量names;
ages = ages + " " + str(i.age) # 我们把表字段age的值都存储在变量ages; # 第四步:把数据返回给前端页面;
return HttpResponse('''
表字段id所有的值汇总:%s;<br/>
表字段name所有的值汇总:%s;<br/>
表字段ages所有的值汇总:%s;<br/>
'''%(ids,names,ages))
3.2.查询方法【filter()】如何使用的完整记录
细节:
①.首先,我们知道查询一张数据表【hello_person】里的符合条件的数据的原生sql语句一般比如是:select * from hello_peroson where id = 9。
②.我们通过ORM框架提供的【filter()】方法也可以快速实现①的功能。
③.【filter() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
3.2.1.第一步:查询方法【fliter()】的具体使用。
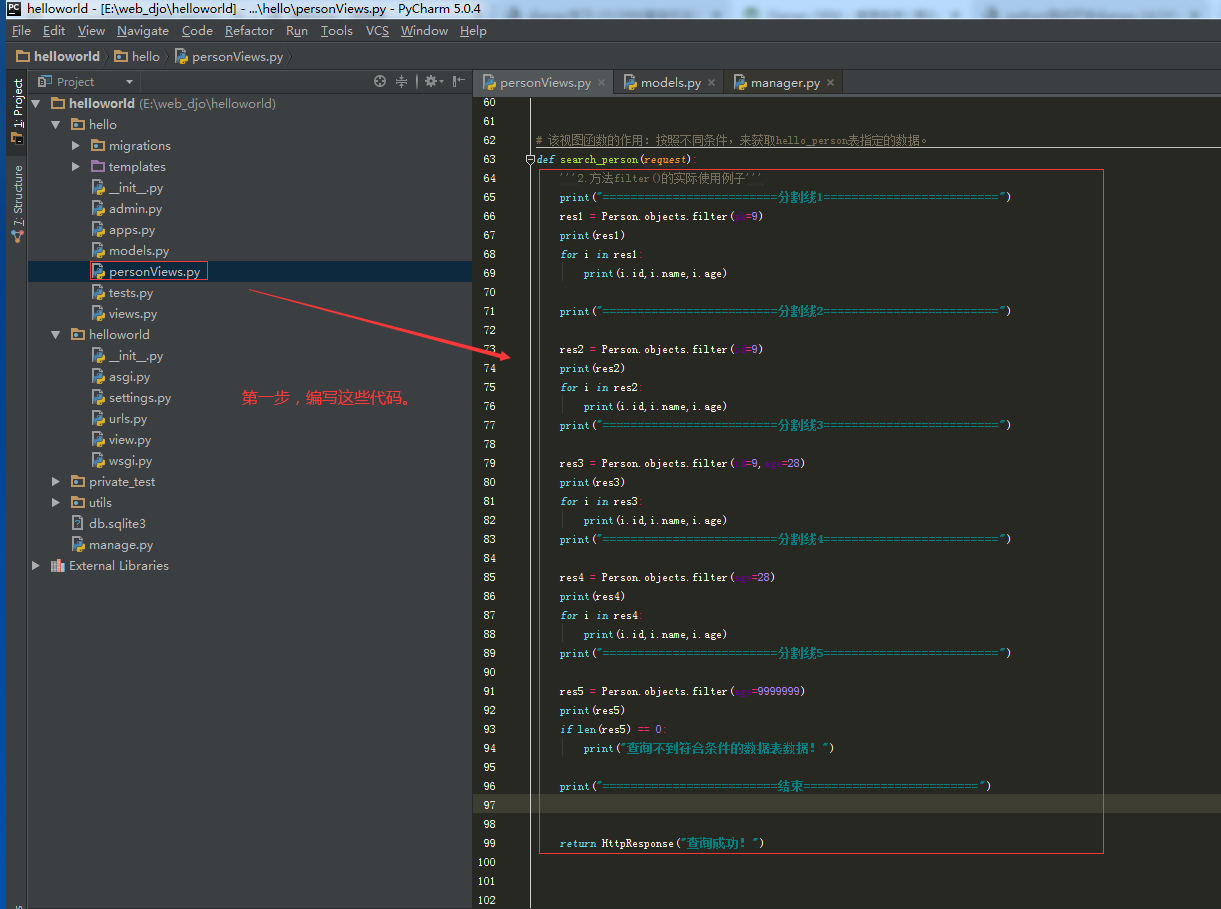
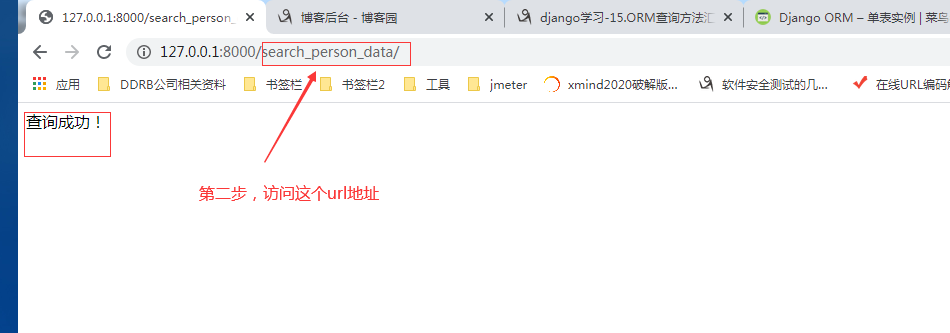
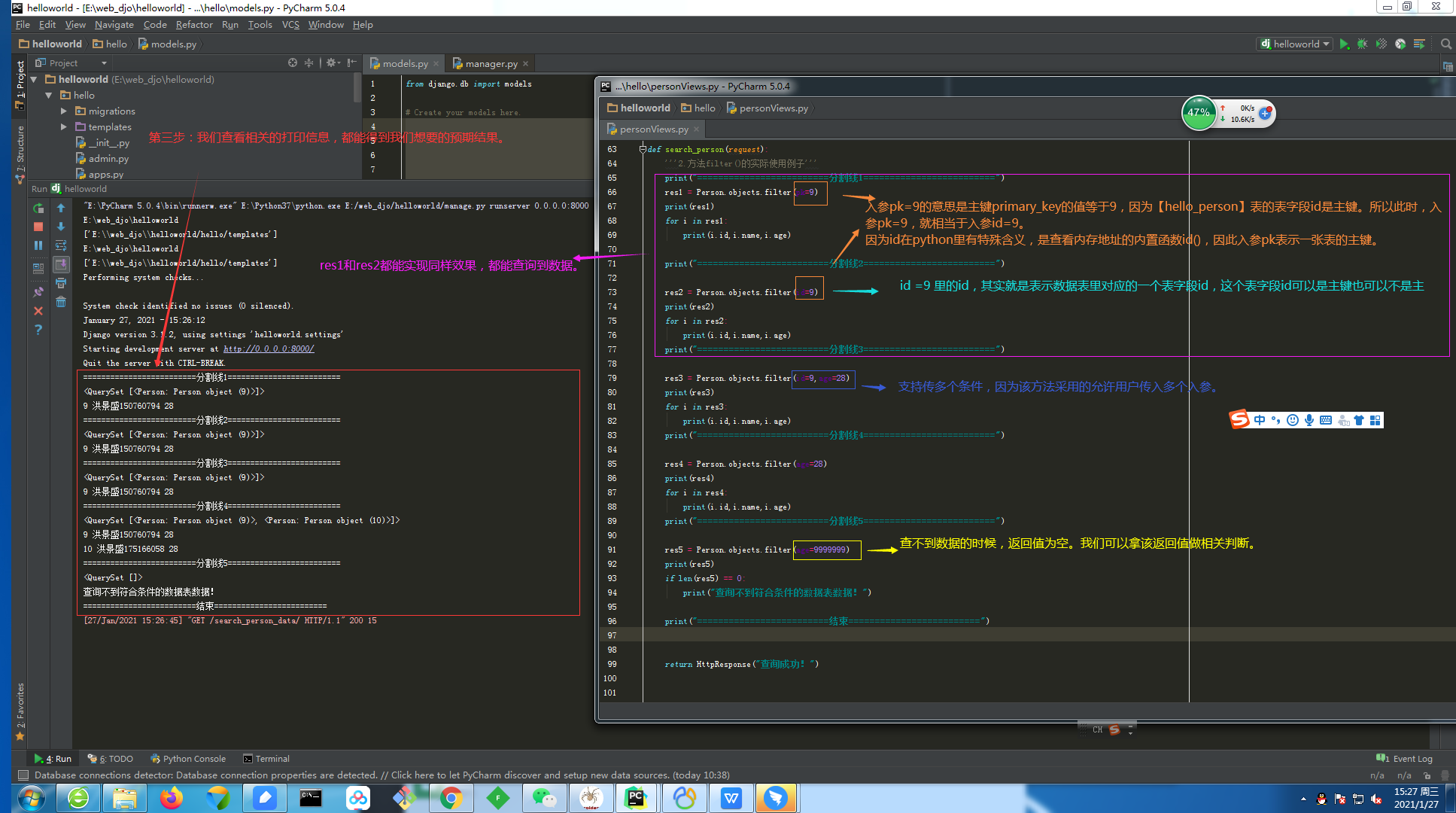
细节:
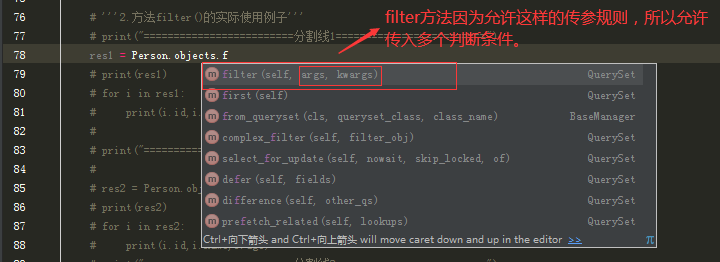
①.方法fiter()的传参规则。
3.3.查询方法【exclude()】如何使用的完整记录
细节:
①.【exclude() 】方法的返回值也是一个可迭代对象QuerySet,返回值都是不符合查询条件的数据。
②.【exclude() 】方法在实际开发中基本少用,基本都采用【filter()】方法。
②.【exclude() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
3.3.1.第一步:查询方法【exclude()】的具体使用。
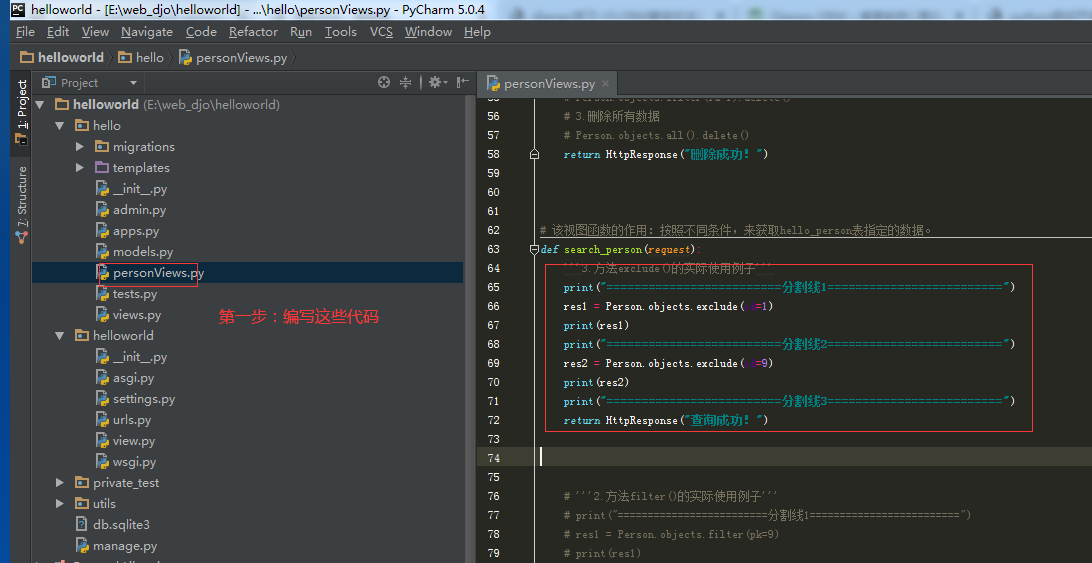
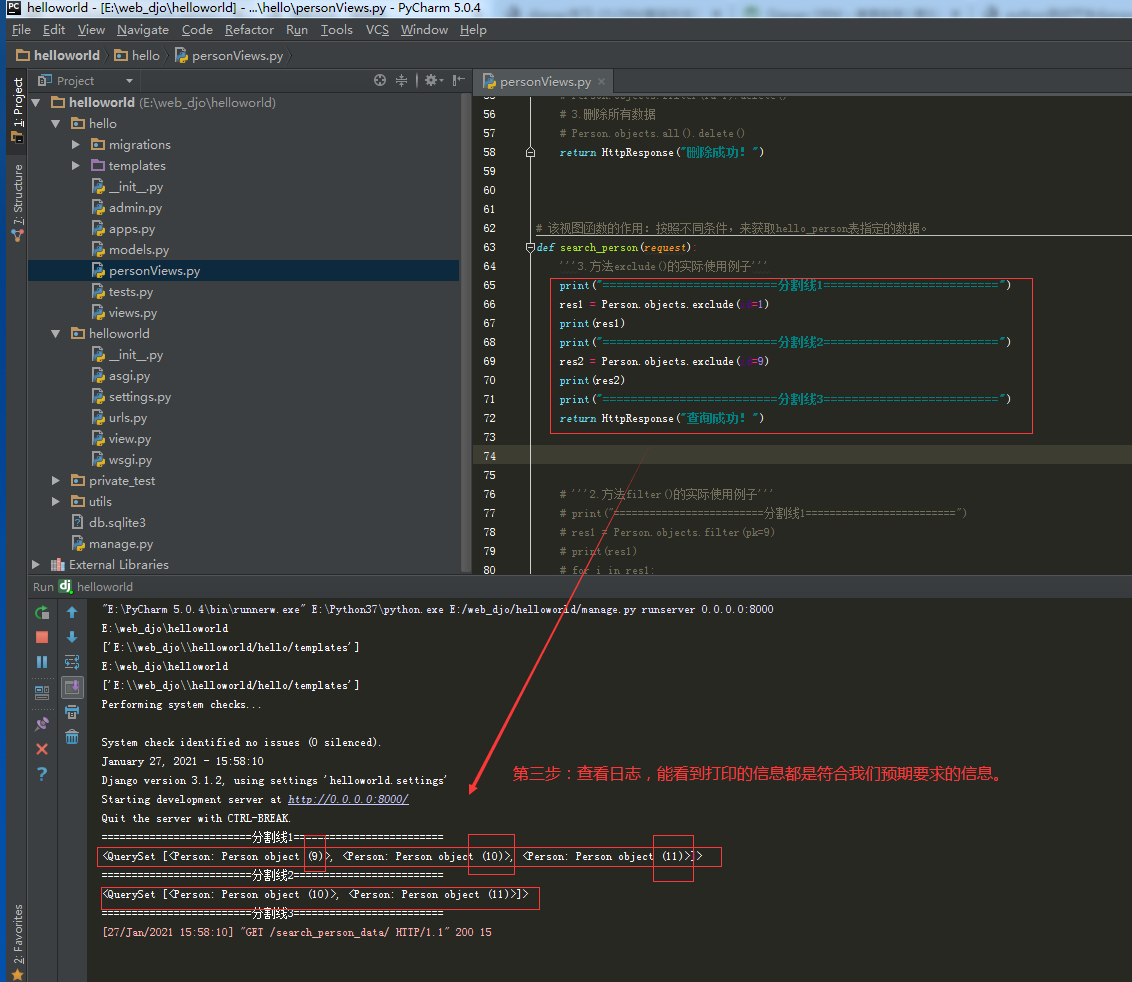
3.4.查询方法【order_by()】如何使用的完整记录
细节:
①.【order_by() 】方法的返回值也是一个可迭代对象QuerySet,返回值都是符合排序条件的数据。
②.【order_by() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
③.入参的相关注意点:
- 参数的字段名要加引号。
- 如果要实现降序功能,要在字段名前面加个负号【-】。
3.4.1.第一步:查询方法【order_by()】的具体使用。

3.5.查询方法【reverse()】如何使用的完整记录
细节:
①.【reverse() 】方法的返回值也是一个可迭代对象QuerySet,【reverse() 】方法用于对查询结果进行反转。
②.【reverse() 】方法在实际开发中基本少用,基本都采用【order_by()】方法。
③.【reverse() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都是模型类的对象。
3.5.1.第一步:查询方法【reverse()】的具体使用。
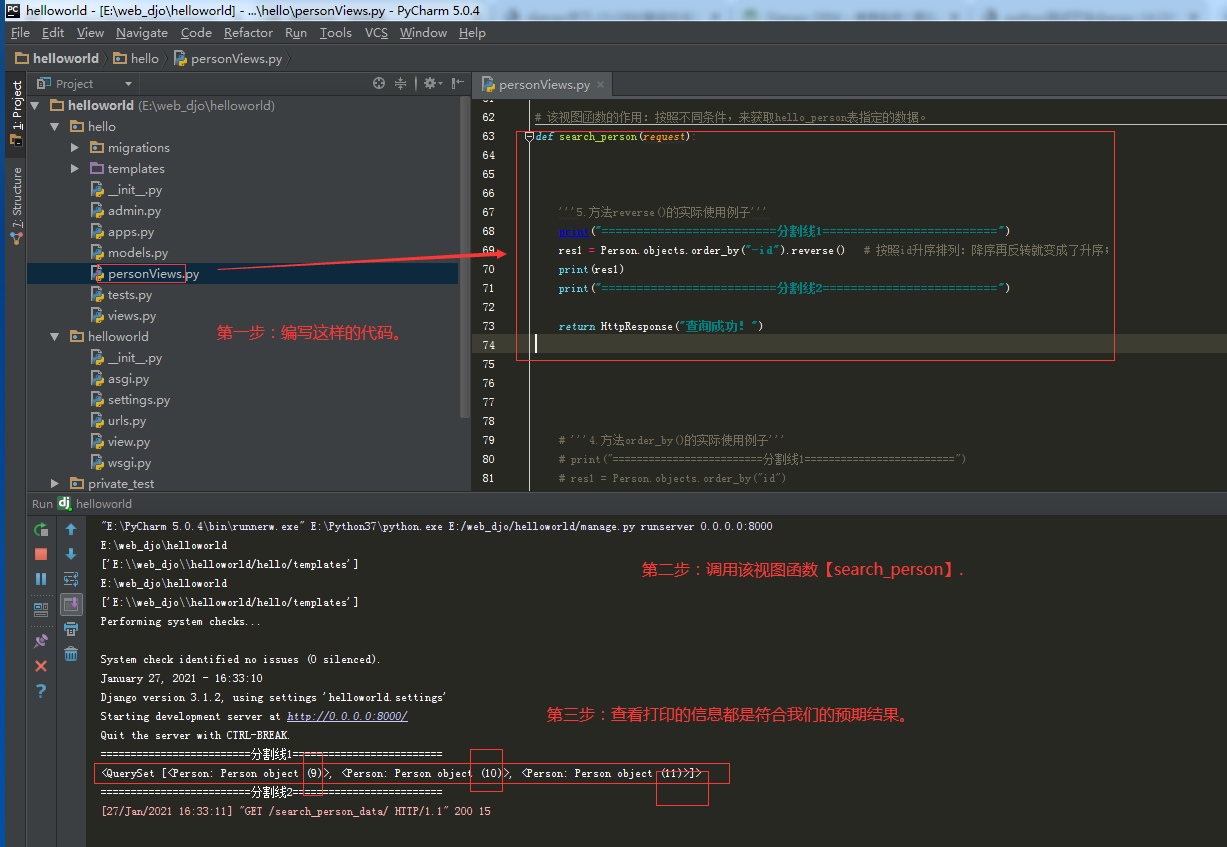
3.6.查询方法【values()】如何使用的完整记录
细节:
①.【values() 】方法的返回值也是一个可迭代对象QuerySet,【values() 】方法用于查询部分字段或者全部字段的数据。
②.如果要查询全部字段的数据,【values() 】方法的入参字段数要为0;
③.【values() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都不是模型类的对象而是可迭代的字典噢,字典里的键是表字段,值是表字段对应的数据。
3.6.1.第一步:查询方法【values()】的具体使用。
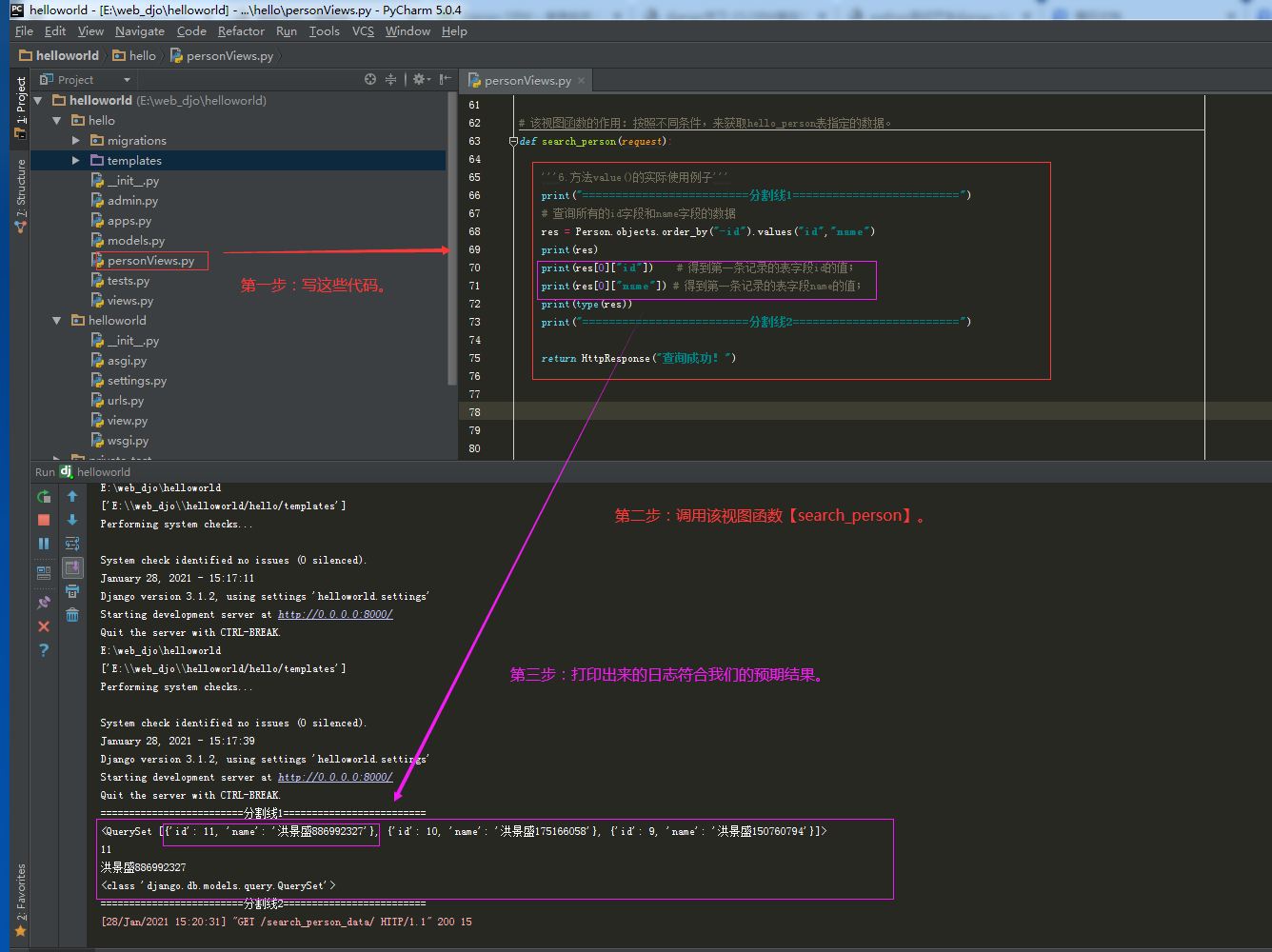
3.7.查询方法【values_list()】如何使用的完整记录
细节:
①.【values_list() 】方法的返回值也是一个可迭代对象QuerySet,但【values_list() 】方法用于查询部分字段或者全部字段的数据。
②.如果要查询全部字段的数据,【values_list() 】方法的入参字段数要为0;
③.【values_list() 】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都不是模型类的对象而是元祖哦,元组里放的是查询表字段对应的数据。
3.7.1.第一步:查询方法【values_list()】的具体使用。
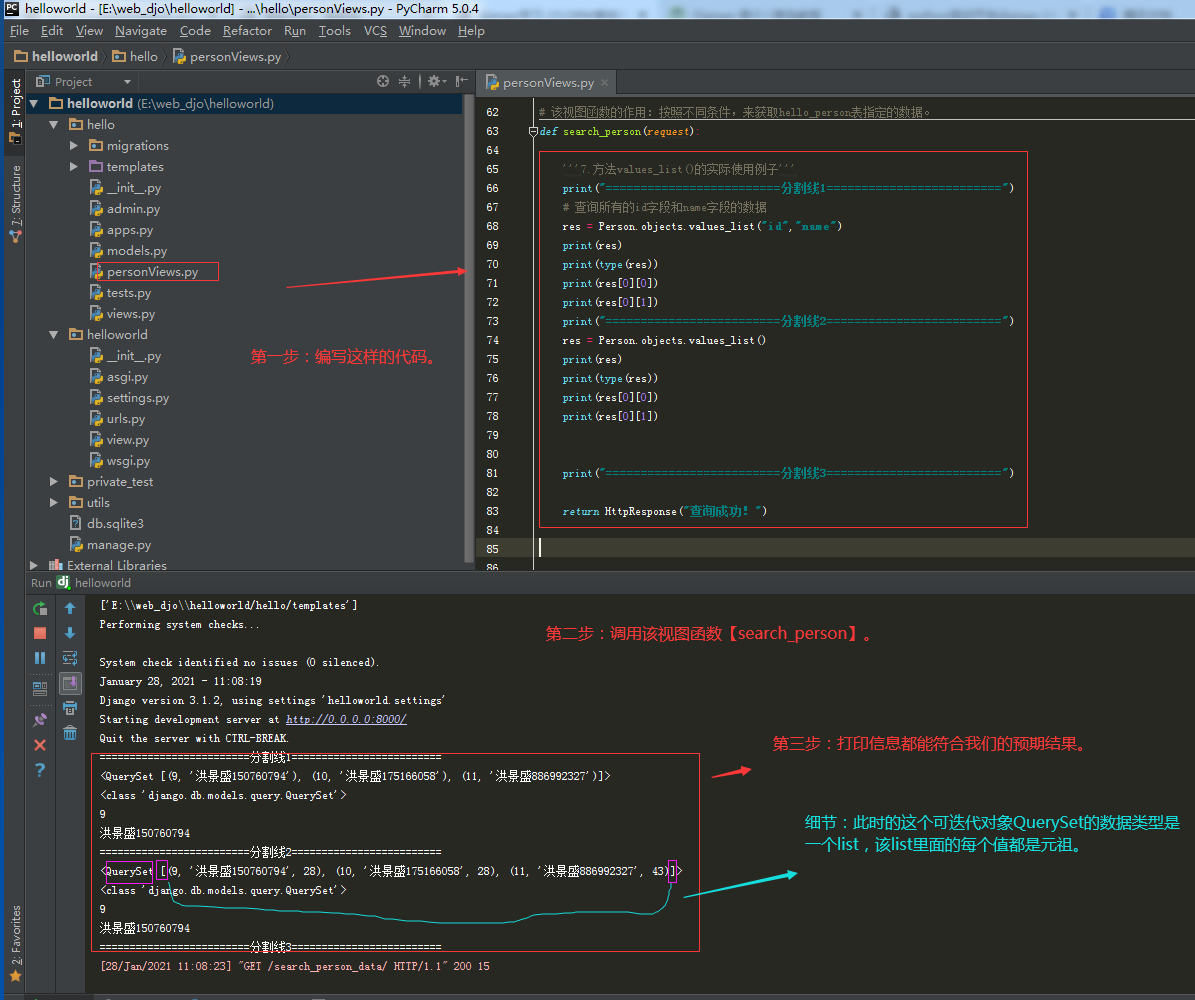
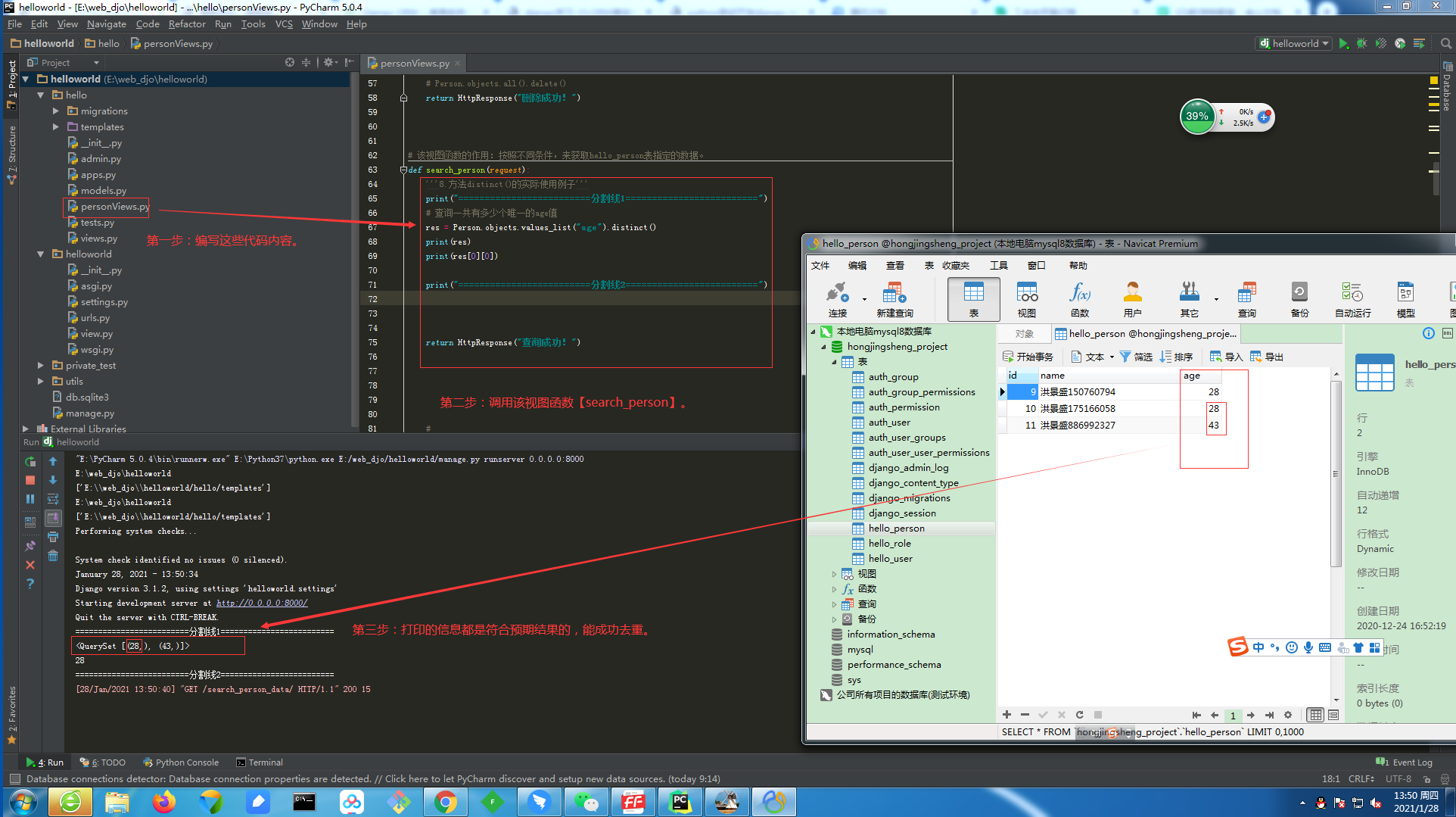
3.8.查询方法【distinct()】如何使用的完整记录
细节:
①.【distinct()】方法的返回值也是一个可迭代对象QuerySet。
②.【distinct()】方法的返回值是一个可迭代对象QuerySet类型数据,该类型数据类似于list。这个可迭代对象QuerySet类型数据里面每个数据都不是模型类的对象,而是每个元祖,元组里放的是查询字段对应的数据。
③.【distinct()】方法对模型类的对象去重没有意义,因为每个对象都是一个不一样的存在。所以【distinct()】方法一般是跟 【values】方法 或者 【values_list】方法 一起使用,但如果跟【all()】方法一起使用是产生不了去重的效果。
④.【distinct()】方法的作用:用于对数据进行去重。
3.8.1.第一步:查询方法【distinct()】的具体使用。
4.方法返回值是单个对象的每个查询方法的如何使用的完整记录
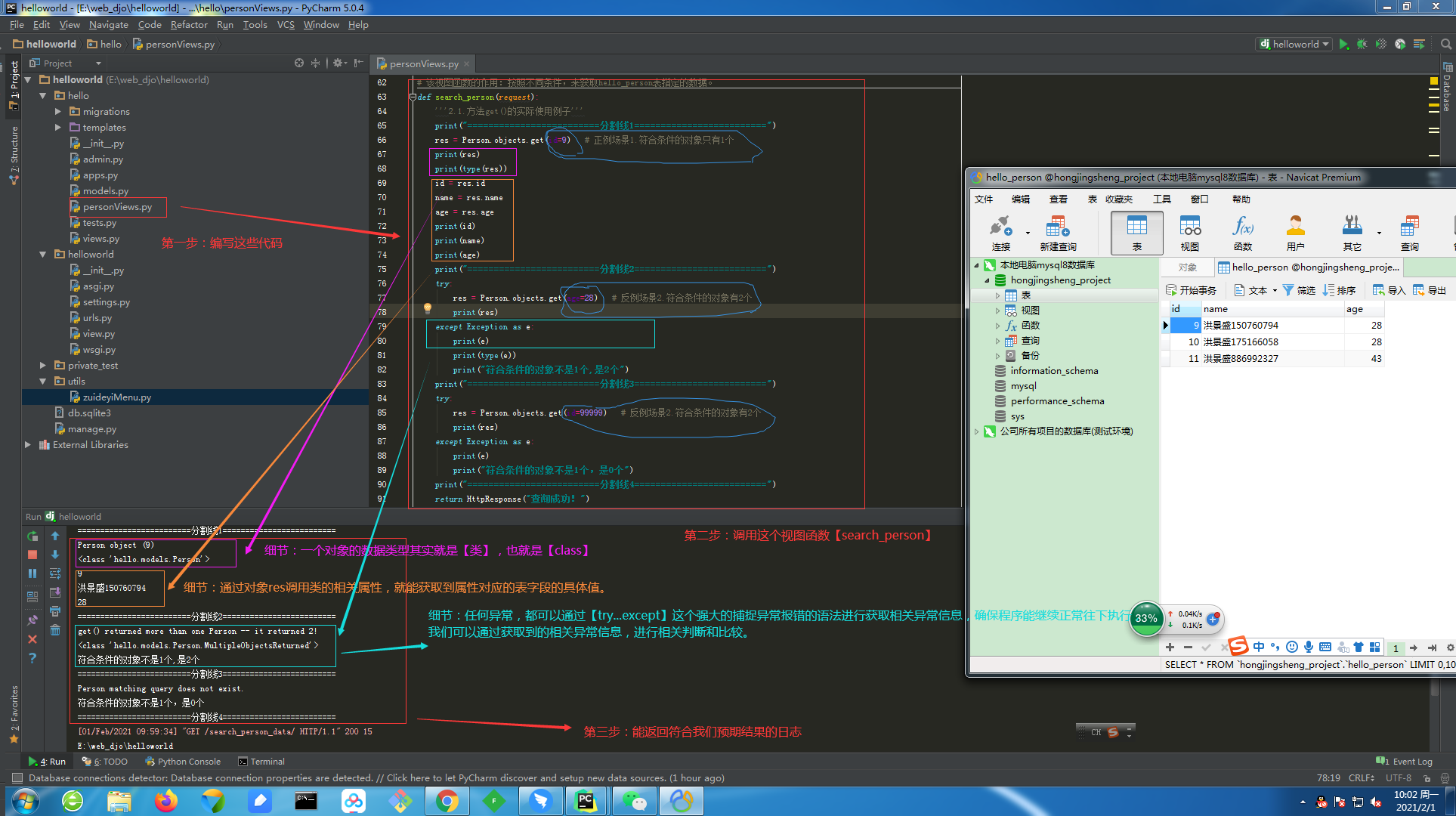
4.1.查询方法【get()】如何使用的完整记录
细节:
①.【get()】方法的返回值是一个模型类的对象。
②.【get()】方法用于查询符合条件的返回模型类的对象且符合条件的对象只能为一个,如果符合筛选条件的对象超过了一个或者没有一个都会抛出错误。
4.1.1.第一步:查询方法【get()】的具体使用。
4.2.查询方法【first()】如何使用的完整记录
细节:
①.【first()】方法返回符合查询条件的结果里的第一条数据且返回的数据是模型类的对象。
4.2.1.第一步:查询方法【first()】的具体使用。

4.3.查询方法【last()】如何使用的完整记录
细节:
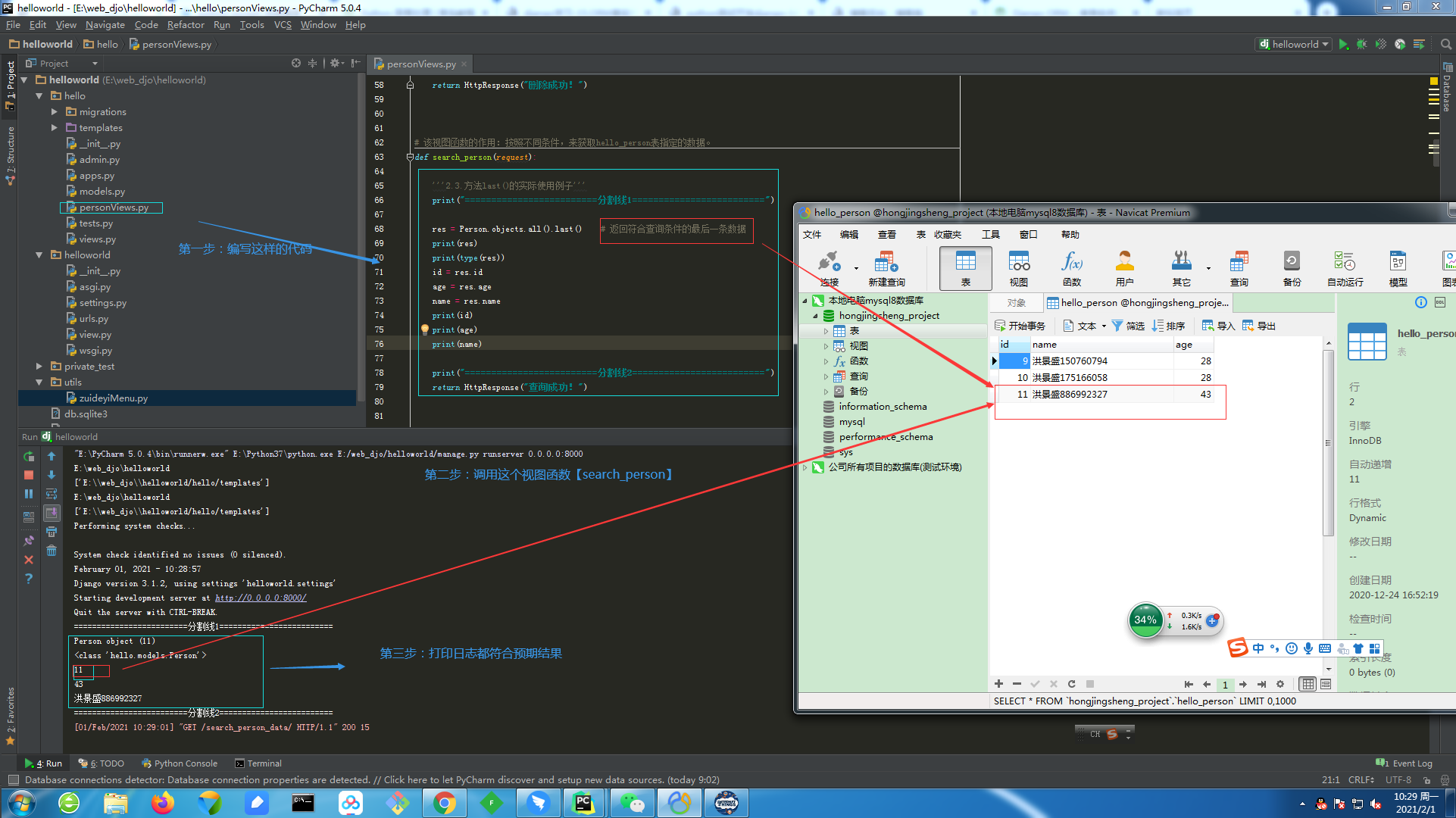
①.【last()】方法返回符合查询条件的结果里的最后一条数据且返回的数据是模型类的对象。
4.3.1.第一步:查询方法【last()】的具体使用。
5.方法返回值是布尔值的每个查询方法的如何使用的完整记录
5.1.查询方法【exists()】如何使用的完整记录
细节:
①.【exists()】方法用于判断查询的结果 QuerySet 列表里是否有数据。
②.【exists()】方法返回值的数据类型是布尔值,有数据则返回值为true,没有数据则返回值为false。
5.1.1.第一步:查询方法【get()】的具体使用。

6.方法返回值是数字的每个查询方法的如何使用的完整记录
6.1.查询方法【count()】如何使用的完整记录
细节:
①.【count()】方法用于查询数据的数量且返回的数据是整数。
6.1.1.第一步:查询方法【count()】的具体使用。

7.相关的学习资料地址
①.django的ORM框架提供的查询数据库表数据的所有方法具体使用,可以查看该菜鸟教程地址:https://www.runoob.com/django/django-orm-1.html
django学习-15.ORM查询方法汇总的更多相关文章
- Django 学习 之ORM聚合查询分组查询与F查询与Q查询
一.聚合查询和分组查询 1.聚合查询aggregate 关于数据表的数据请见上一篇:Django 学习 之ORM多表操作(点我) aggregate(*args, **kwargs),只对一个组进行聚 ...
- Django框架 之 ORM查询操作详解
Django框架 之 ORM查询操作详解 浏览目录 一般操作 ForeignKey操作 ManyToManyField 聚合查询 分组查询 F查询和Q查询 事务 Django终端打印SQL语句 在Py ...
- DRF框架中链表数据通过ModelSerializer深度查询方法汇总
DRF框架中链表数据通过ModelSerializer深度查询方法汇总 一.准备测试和理解准备 创建类 class Test1(models.Model): id = models.IntegerFi ...
- Django学习手册 - ORM 数据创建/表操作 汇总
ORM 查询的数据类型: QuerySet与惰性机制(可以看作是一个列表) 所谓惰性机制:表名.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它 ...
- Django学习之ORM操作
一.一般操作 二.必知必会13条 返回QuerySet对象的方法有 特殊的QuerySet 返回具体对象的 返回布尔值的方法有 返回数字的方法 三.单表查询之神奇的双下划线 四.ForeignKey操 ...
- Python - Django - ORM 查询方法
models.py: from django.db import models class Human(models.Model): id = models.AutoField(primary_key ...
- Python Django中一些少用却很实用的orm查询方法
一.使用Q对象进行限制条件之间 "或" 连接查询 from django.db.models import Q from django.contrib.auth.models im ...
- Django 一些少用却很实用的orm查询方法
一.使用Q对象进行限制条件之间 "或" 连接查询 from django.db.models import Q from django.contrib.auth.models im ...
- Django学习手册 - ORM 多对多表
定义表结构: class Host(models.Model): hostname = models.CharField(max_length=32) port = models.IntegerFie ...
随机推荐
- XCTF-easyjni
前期工作 查壳无壳 逆向分析 文件结构 MainActivity代码 public class MainActivity extends c { static { System.loadLibrary ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- Linux数据库的导入导出
Linux数据库的导入导出 1.导入数据库 mysql -u username -p test < /home/data/test.sql 说明:username是数据库用户名,test为目标数 ...
- 快速导出jekyll博客文件进行上传部署
快速导出jekyll博客文件进行上传部署 在使用markdown书写jekyll博客时,经常需要写一个头部信息用以让jekyll读取博文信息,这是一件比较麻烦的事,因此我使用HTML实现了一个快速导出 ...
- Codeforces Round #677 (Div. 3) G. Reducing Delivery Cost(dijkstra算法)
题目链接:https://codeforces.com/contest/1433/problem/G 题解 跑 \(n\) 遍 \(dijkstra\) 得到任意两点间的距离,然后枚举哪一条边权为 \ ...
- 放苹果 POJ - 1664 递推
把M个同样的苹果放在N个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法?(用K表示)5,1,1和1,5,1 是同一种分法. Input 第一行是测试数据的数目t(0 <= t < ...
- AtCoder Beginner Contest 173 C - H and V (二进制枚举)
题意:有一张图,.表示白色,#表示黑色,每次可以将多行和多列涂成红色(也可不涂),问有多少种方案,使得剩下黑点的个数为\(k\). 题解:又学到了新的算法qwq,因为这题的数据范围很小,所以可以用二进 ...
- MySQL5.6 与 MySQL5.7 的区别
目录 编译安装区别 初始化的区别 其他区别 编译安装区别 # 5.7在编译安装的时候多了一个 boost 库 [root@db02 mysql-5.7.20]# yum install -y gcc ...
- 2.使用jenkins自动构建并发布应用到k8s集群
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-06-21 14:39:01 星期五 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- Eclipce怎么恢复误删类
选择误删除文件在eclipse所在包(文件夹) 在包上单击右键. 选择restore from local history... 在弹出的对话框中选择需要恢复的文件