scrapy 基础组件专题(一):scrapy框架中各组件的工作流程
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):
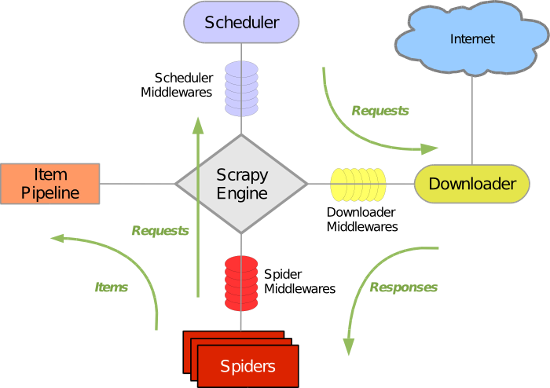
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 1.引擎:Hi!Spider, 你要处理哪一个网站?
- 2.Spider:老大要我处理xxxx.com(初始URL)。
- 3.引擎:你把第一个需要处理的URL给我吧。
- 4.Spider:给你,第一个URL是xxxxxxx.com。
- 5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
- 6.调度器:好的,正在处理你等一下。
- 7.引擎:Hi!调度器,把你处理好的request请求给我。
- 8.调度器:给你,这是我处理好的request
- 9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
- 10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
- 11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
- 12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- 13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 14.管道、调度器:好的,现在就做!
scrapy 基础组件专题(一):scrapy框架中各组件的工作流程的更多相关文章
- drf框架中分页组件
drf框架中分页组件 普通分页(最常用) 自定制分页类 pagination.py from rest_framework.pagination import PageNumberPagination ...
- drf框架中认证与权限工作原理及设置
0909自我总结 drf框架中认证与权限工作原理及设置 一.概述 1.认证 工作原理 返回None => 游客 返回user,auth => 登录用户 抛出异常 => 非法用户 前台 ...
- nodejs的Express框架源码分析、工作流程分析
nodejs的Express框架源码分析.工作流程分析 1.Express的编写流程 2.Express关键api的使用及其作用分析 app.use(middleware); connect pack ...
- django框架中form组件的简单使用示例:注册验证
Django中form组件的三大特点: 1. 生成页面可使用的HTML标签 2. 对用户提交的数据进行初步校验 3. 保留上次输入内容 废话不多说,直接进入正题. 这是注册界面截图: 与上一篇a ...
- Scrapy基础(十)———同步机制将Item中的数据写在Mysql
前面讲解到将Item中的所有字段都已经填写完成,那么接下来就是将他们存储到mysql数据库中,那就用到了pipeline项目管道了: 对项目管道的理解:做一个比喻,爬取好比是开采石油,Item装 ...
- Scrapy基础(二)————Scrapy的安装和目录结构
Scrapy安装: 1,首先进入虚拟环境 2,使用国内豆瓣源进行安装,快! pip install -i https://pypi.douban.com/simple/ scrapy 3,特殊情 ...
- scrapy基础知识之制作 Scrapy 爬虫 一共需要4步:
1.新建项目 (scrapy startproject xxx):新建一个新的爬虫项目 2.明确目标 (编写items.py):明确你想要抓取的目标 3.制作爬虫 (spiders/xxspider. ...
- Primeng UI框架中 分页组件用法
1.在当前模块或当前页面的对应的module.ts文件中引入相应组件模块,如:core.module.ts模块. import { PaginatorModule } from 'primeng/pr ...
- 使用spring框架中的组件发送邮件
首先进入自己的QQ邮箱,在设置中修改账户信息 然后来至底部 点击开启,再用手机发送对应信息到指定号码,然后点击我已发送 获取授权码 注意提示: 到这里,相信你已经开通了SMTP服务,这样就可以在 ...
随机推荐
- 如何设置body内容不能复制?
通过在body标签上设置相关的属性: <body oncontextmenu="return false" ondragstart="return false&qu ...
- UI 小白设计常用的Website
网址 设计师导航网址(其实这个用好了,enough) 设计导航1 设计导航2 icon 阿里巴巴Iconfont flaticons icomoon Noun Project 图片(有时候就是灵魂) ...
- 阿里巴巴二面凉经 flatten扁平化对象与数组
2020-04-13 阿里巴巴二面凉经 flatten扁平化对象与数组 在线笔试的时候写错了一点点 太可惜了哎 还是基础不够扎实... const input = { a: 1, b: [ 1, 2, ...
- 【经验心得】谈一谈我IT行业未来的方向
随着科技的发展,越来越多的入门行业将被淘汰,其实淘汰的不仅仅是工厂.环卫工人.普工这些无技术含量的工作,有一些运维.编辑等低门槛的行业也将被淘汰,这也是我这两年看互联网发展趋势得出来的结论,人类要想发 ...
- Java——八种基本数据类型(常用类)
装箱和拆箱 装箱:基本数据类型转为包装类 拆箱:包装类转为基本数据类型 jdk1.5(即jdk5.0)之后的版本都提供了自动装箱和自动拆箱功能 基本数据类型的包装类 举两个例子,看一下 public ...
- Shell编译安装nginx
环境及规划 [root@nginx-node01 ~]# cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) ID 主机名 ip ...
- ComplexHeatmap|根据excel表绘制突变景观图(oncoplot)
本文首发于“生信补给站”:https://mp.weixin.qq.com/s/8kz2oKvUQrCR2_HWYXQT4g 如果有maf格式的文件,可以直接oncoplot包绘制瀑布图,有多种展示和 ...
- Mac 电脑查看 pkg包的安装路径
pkgutil --pkgspkgutil --infopkgutil --files
- android自定义控件onMeasure方法
1.自定义控件首先定义一个类继承View 有时,Android系统控件无法满足我们的需求,因此有必要自定义View.具体方法参见官方开发文档:http://developer.android.com/ ...
- MapReduce 论文阅读笔记
Abstract MapReduce : programming model 编程模型 an associated implementation for processing and generati ...