【关系抽取-R-BERT】定义训练和验证循环
【关系抽取-R-BERT】加载数据集
【关系抽取-R-BERT】模型结构
【关系抽取-R-BERT】定义训练和验证循环
相关代码
import logging
import os
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from tqdm import tqdm, trange
from transformers import AdamW, BertConfig, get_linear_schedule_with_warmup
from model import RBERT
from utils import compute_metrics, get_label, write_prediction
logger = logging.getLogger(__name__)
class Trainer(object):
def __init__(self, args, train_dataset=None, dev_dataset=None, test_dataset=None):
self.args = args
self.train_dataset = train_dataset
self.dev_dataset = dev_dataset
self.test_dataset = test_dataset
self.label_lst = get_label(args)
self.num_labels = len(self.label_lst)
self.config = BertConfig.from_pretrained(
args.model_name_or_path,
num_labels=self.num_labels,
finetuning_task=args.task,
id2label={str(i): label for i, label in enumerate(self.label_lst)},
label2id={label: i for i, label in enumerate(self.label_lst)},
)
self.model = RBERT.from_pretrained(args.model_name_or_path, config=self.config, args=args)
# GPU or CPU
self.device = "cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu"
self.model.to(self.device)
def train(self):
train_sampler = RandomSampler(self.train_dataset)
train_dataloader = DataLoader(
self.train_dataset,
sampler=train_sampler,
batch_size=self.args.train_batch_size,
)
if self.args.max_steps > 0:
t_total = self.args.max_steps
self.args.num_train_epochs = (
self.args.max_steps // (len(train_dataloader) // self.args.gradient_accumulation_steps) + 1
)
else:
t_total = len(train_dataloader) // self.args.gradient_accumulation_steps * self.args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.args.weight_decay,
},
{
"params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters,
lr=self.args.learning_rate,
eps=self.args.adam_epsilon,
)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=self.args.warmup_steps,
num_training_steps=t_total,
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(self.train_dataset))
logger.info(" Num Epochs = %d", self.args.num_train_epochs)
logger.info(" Total train batch size = %d", self.args.train_batch_size)
logger.info(" Gradient Accumulation steps = %d", self.args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
logger.info(" Logging steps = %d", self.args.logging_steps)
logger.info(" Save steps = %d", self.args.save_steps)
global_step = 0
tr_loss = 0.0
self.model.zero_grad()
train_iterator = trange(int(self.args.num_train_epochs), desc="Epoch")
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
self.model.train()
batch = tuple(t.to(self.device) for t in batch) # GPU or CPU
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"labels": batch[3],
"e1_mask": batch[4],
"e2_mask": batch[5],
}
outputs = self.model(**inputs)
loss = outputs[0]
if self.args.gradient_accumulation_steps > 1:
loss = loss / self.args.gradient_accumulation_steps
loss.backward()
tr_loss += loss.item()
if (step + 1) % self.args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
self.model.zero_grad()
global_step += 1
if self.args.logging_steps > 0 and global_step % self.args.logging_steps == 0:
self.evaluate("test") # There is no dev set for semeval task
if self.args.save_steps > 0 and global_step % self.args.save_steps == 0:
self.save_model()
if 0 < self.args.max_steps < global_step:
epoch_iterator.close()
break
if 0 < self.args.max_steps < global_step:
train_iterator.close()
break
return global_step, tr_loss / global_step
def evaluate(self, mode):
# We use test dataset because semeval doesn't have dev dataset
if mode == "test":
dataset = self.test_dataset
elif mode == "dev":
dataset = self.dev_dataset
else:
raise Exception("Only dev and test dataset available")
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=self.args.eval_batch_size)
# Eval!
logger.info("***** Running evaluation on %s dataset *****", mode)
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", self.args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
self.model.eval()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
batch = tuple(t.to(self.device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"labels": batch[3],
"e1_mask": batch[4],
"e2_mask": batch[5],
}
outputs = self.model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs["labels"].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs["labels"].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
results = {"loss": eval_loss}
preds = np.argmax(preds, axis=1)
write_prediction(self.args, os.path.join(self.args.eval_dir, "proposed_answers.txt"), preds)
result = compute_metrics(preds, out_label_ids)
results.update(result)
logger.info("***** Eval results *****")
for key in sorted(results.keys()):
logger.info(" {} = {:.4f}".format(key, results[key]))
return results
def save_model(self):
# Save model checkpoint (Overwrite)
if not os.path.exists(self.args.model_dir):
os.makedirs(self.args.model_dir)
model_to_save = self.model.module if hasattr(self.model, "module") else self.model
model_to_save.save_pretrained(self.args.model_dir)
# Save training arguments together with the trained model
torch.save(self.args, os.path.join(self.args.model_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", self.args.model_dir)
def load_model(self):
# Check whether model exists
if not os.path.exists(self.args.model_dir):
raise Exception("Model doesn't exists! Train first!")
self.args = torch.load(os.path.join(self.args.model_dir, "training_args.bin"))
self.model = RBERT.from_pretrained(self.args.model_dir, args=self.args)
self.model.to(self.device)
logger.info("***** Model Loaded *****")
说明
整个代码的流程就是:
- 定义训练数据;
- 定义模型;
- 定义优化器;
- 如果是训练,将模型切换到训练状态;model.train(),读取数据进行损失计算,反向传播更新参数;
- 如果是验证或者测试,将模型切换到验证状态:model.eval(),相关计算要用with torch.no_grad()进行包裹,并在里面进行损失的计算、相关评价指标的计算或者预测;
使用到的一些技巧
采样器的使用
在训练的时候,我们使用的是RandomSampler采样器,在验证或者测试的时候,我们使用的是SequentialSampler采样器,关于这些采样器的区别,可以去这里看一下:
https://chenllliang.github.io/2020/02/04/dataloader/
这里简要提一下这两种的区别,训练的时候是打乱数据再进行读取,验证的时候顺序读取数据。
使用梯度累加
核心代码:
if (step + 1) % self.args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
self.model.zero_grad()
global_step += 1
梯度累加的作用是当显存不足的时候可以变相的增加batchsize,具体就不作展开了。
不同参数设置权重衰减
核心代码:
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.args.weight_decay,
},
{
"params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters,
lr=self.args.learning_rate,
eps=self.args.adam_epsilon,
)
有的参数是不需要进行权重衰减的,我们可以分别设置。
warmup的使用
核心代码:
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=self.args.warmup_steps,
num_training_steps=t_total,
)
看一张图:
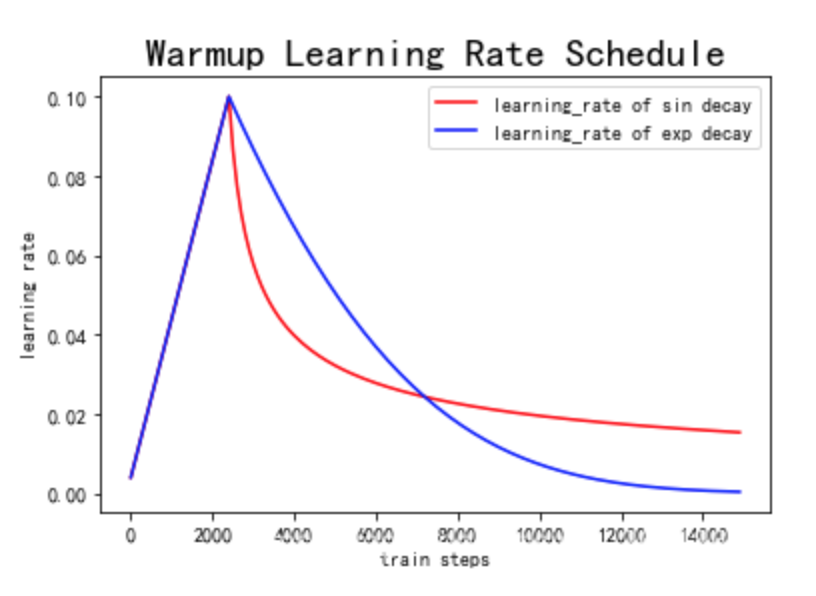
warmup就是在初始阶段逐渐增大学习率到指定的数值,这么做是为了避免在模型训练的初期的不稳定问题。
【关系抽取-R-BERT】定义训练和验证循环的更多相关文章
- 9. 获得图片路径,构造出训练集和验证集,同时构造出相同人脸和不同人脸的测试集,将结果存储为.csv格式 1.random.shuffle(数据清洗) 2.random.sample(从数据集中随机选取2个数据) 3. random.choice(从数据集中抽取一个数据) 4.pickle.dump(将数据集写成.pkl数据)
1. random.shuffle(dataset) 对数据进行清洗操作 参数说明:dataset表示输入的数据 2.random.sample(dataset, 2) 从dataset数据集中选取2 ...
- NLP(二十一)人物关系抽取的一次实战
去年,笔者写过一篇文章利用关系抽取构建知识图谱的一次尝试,试图用现在的深度学习办法去做开放领域的关系抽取,但是遗憾的是,目前在开放领域的关系抽取,还没有成熟的解决方案和模型.当时的文章仅作为笔者的 ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- 一次关于关系抽取(RE)综述调研的交流心得
本文来自于一次交流的的记录,{}内的为个人体会. 基本概念 实事知识:实体-关系-实体的三元组.比如, 知识图谱:大量实时知识组织在一起,可以构建成知识图谱. 关系抽取:由于文本中蕴含大量事实知识,需 ...
- 谷歌BERT预训练源码解析(三):训练过程
目录前言源码解析主函数自定义模型遮蔽词预测下一句预测规范化数据集前言本部分介绍BERT训练过程,BERT模型训练过程是在自己的TPU上进行的,这部分我没做过研究所以不做深入探讨.BERT针对两个任务同 ...
- 【例3】设有关系模式R(A, B, C, D, E)与它的函数依赖集F={A→BC, CD→E, B→D, E→A},求R的所有候选键。 解题思路:
通过分析F发现,其所有的属性A.B.C.D.E都是LR类属性,没有L类.R类.N类属性. 因此,先从这些属性中依次取出一个属性,分别求它们的闭包:=ABCDE,=BD,=C,=D, =ABCDE.由于 ...
- 基于BERT预训练的中文命名实体识别TensorFlow实现
BERT-BiLSMT-CRF-NERTensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuni ...
- 【python实现卷积神经网络】定义训练和测试过程
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 用NVIDIA-NGC对BERT进行训练和微调
用NVIDIA-NGC对BERT进行训练和微调 Training and Fine-tuning BERT Using NVIDIA NGC 想象一下一个比人类更能理解语言的人工智能程序.想象一下为定 ...
随机推荐
- 开源软件ffmpeg使用中的问题
error while decoding MB 20 10, bytestream -13 经过调试,发现这部是 int ret = avcodec_decode_video2(pCodecConte ...
- JVM进阶篇
class Person { private String name = "Jack"; private int age; private final double salar ...
- Vue3(四)从jQuery 转到 Vue工程化 的捷径
不会 webpack 还想学 vue 工程化开发 的福音 熟悉jQuery开发的,学习vue的简单使用是没用啥问题的,但是学习vue的工程化开发方式,往往会遇到各种问题,比如: webpack.nod ...
- Windows 10 & git & bash
Windows 10 & git & bash If you are on Windows, we recommend downloading Git for Windows and ...
- Chinese Parents Game
Chinese Parents Game <中国式家长>是一款模拟养成游戏. 玩家在游戏中扮演一位出生在普通的中式家庭的孩子. https://en.wikipedia.org/wiki/ ...
- 使用 js 实现一个简易版的动画库
使用 js 实现一个简易版的动画库 具有挑战性的前端面试题 animation css refs https://www.infoq.cn/article/0NUjpxGrqRX6Ss01BLLE x ...
- color recognition by image
color recognition by image 通过图像进行颜色识别 https://imagecolorpicker.com/ unknown color origin pic grey bl ...
- free Google translator for the personal website
free Google translator for the personal website https://html5.xgqfrms.xyz/
- HTML Imports & deprecated
HTML Imports & deprecated https://caniuse.com/#search=html imports https://www.chromestatus.com/ ...
- NGK公链:在规则明确的环境下运行超级节点机制
首先要跟大家明确的一点是,21个超级节点是投票选举出来的,并不是系统在创立之初就已经确定好了的.那么相信大家也一定很好奇,这21个超级节点是通过什么方式产生? NGK.IO对分布式超级节点使用了一个自 ...