Kaggle-pandas(1)
Creating-reading-and-writing
教程
1.创建与导入
DataFrame
import pandas as pd
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
生成的表如下:
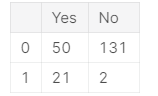
我们正在使用pd.DataFrame()构造函数来生成这些DataFrame对象。 声明新字典的语法是字典,其关键字是列名(在此示例中为Yes和No),其值是条目列表。 这是构造新DataFrame的标准方法,也是您最有可能遇到的一种方法。
字典列表构造函数将值分配给列标签,但仅对行标签使用从0(0、1、2、3,...)开始的递增计数。 有时这可以,但是通常我们会自己分配这些标签。
DataFrame中使用的行标签列表称为索引。 我们可以通过在构造函数中使用index参数来为其赋值:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])

Series
相比之下,系列是数据值的序列。 如果DataFrame是表,则Series是列表。 实际上,您可以创建一个只包含一个列表的列表:
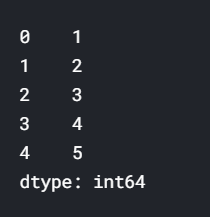
本质上,Series是DataFrame的单个列。 因此,您可以使用索引参数,以与以前相同的方式将列值分配给Series。 但是,系列没有列名,只有一个整体名:
Series和DataFrame密切相关。 认为DataFrame实际上只是一堆“胶合在一起”的Series很有帮助。 我们将在本教程的下一部分中看到更多信息。
2.读取数据文件
能够手动创建DataFrame或Series很方便。 但是,在大多数情况下,我们实际上不会手工创建自己的数据。 相反,我们将使用已经存在的数据。
数据可以多种不同形式和格式存储。 到目前为止,最基本的是不起眼的CSV文件。 当您打开CSV文件时,您将获得如下所示的内容:

因此,CSV文件是由逗号分隔的值表。 因此,名称为:“逗号分隔值(Comma-Separated Values")”或CSV。
现在让我们搁置玩具数据集,看看当我们将其读入DataFrame时真实数据集的外观。 我们将使用pd.read_csv()函数将数据读取到DataFrame中。
Kaggle-pandas(1)的更多相关文章
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- Kaggle入门教程
此为中文翻译版 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中最 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle之Grupo Bimbo Inventory Demand
Grupo Bimbo Inventory Demand kaggle比赛解决方案集合 Grupo Bimbo Inventory Demand 在这个比赛中,我们需要预测某个产品在某个销售点每周的需 ...
- kaggle之人脸特征识别
Facial_Keypoints_Detection github code facial-keypoints-detection, 这是一个人脸识别任务,任务是识别人脸图片中的眼睛.鼻子.嘴的位置. ...
随机推荐
- day05 垃圾回收机制(超小白讲解)
垃圾回收机制 在学习这个抽象概念前,老习惯,灵魂二问 什么是?为什么要有? 引言:在程序运行到变量定义时,会在内存空间中存放变量值,然而内存空间是有限的,变量是无限的. Q:如何在有限的内存里存里存放 ...
- 一道题理解setTimeout,Promise,async/await以及宏任务与微任务
今天看到这样一道面试题: //请写出输出内容 async function async1() { console.log('async1 start'); await async2(); consol ...
- python 设计模式专题(一):目录篇
一.创建型设计模式 1.工厂模式 2.建造者模式 3.原型模式 二.结构型设计模式(组合) 1.适配器模式 2.装饰器模式 3.外观模式 4.单例模式 5.mvc模式 6.代理模式 三.行为型设计模式 ...
- java 基本语法(一) 关键字与标识符
1.java关键字的使用定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)特点:关键字中所字母都为小写具体哪些关键字: 2.保留字:现Java版本尚未使用,但以后版本可能会作为关键字使用 ...
- python 面向对象专题(十):特殊方法 (三)__get__、__set__、__delete__ 描述符(三)方法是描述符
在类中定义的函数属于绑定方法(bound method),因为用户定义的函数都有 __get__ 方法,所以依附到类上时,就相当于描述符.示例 20-13 演示了从 面向对象专题(九)示例 20-8 ...
- 从JDK源码理解java引用
目录 java中的引用 引用队列 虚引用.弱引用.软引用的实现 ReferenceHandler线程 引用队列的实现 总结 参考资料 java中的引用 JDK 1.2之后,把对象的引用分为了四种类型, ...
- Burp Suite Scanner Module - 扫描模块
Burp Suite Professional 和Enterprise Version的Scaner功能较丰富. 以Professional版本为例,包含Issue activity, Scan qu ...
- Ethical Hacking - NETWORK PENETRATION TESTING(10)
WPA Craking WPA was designed to address the issues in WEP and provide better encryption. The main is ...
- 事件循环 event loop 究竟是什么
事件循环 event loop 究竟是什么 一些概念 浏览器运行时是多进程,从任务管理器或者活动监视器上可以验证. 打开新标签页和增加一个插件都会增加一个进程,如下图:  浏览器渲染进程是多线程,包 ...
- Oracle DataGuard主备切换(switchover)
Oracle DataGuard主备切换可以使用传统的手动命令切换,也可以使用dgmgr切换,本文记录手动切换. (一)将主库切换为物理备库 STEP1:查看主库状态 SQL> SELECT O ...