Langchain-Chatchat项目:4.2-P-Tuning v2使用的数据集
本文主要介绍P-tuning-v2论文中的5种任务,分别为Glue任务、NER任务、QA任务、SRL任务、SuperGlue任务,重点介绍了下每种任务使用的数据集。
一.Glue任务
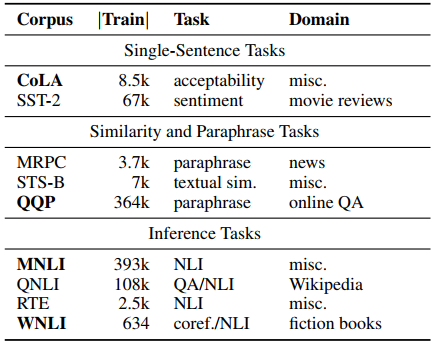
GLUE(General Language Understanding Evaluation)是纽约大学、华盛顿大学等机构创建了一个多任务的自然语言理解基准和分析平台。GLUE包含九项NLU任务,语言均为英语。GLUE九项任务涉及到自然语言推断、文本蕴含、情感分析、语义相似等多个任务。可分为三大类,分别是单句任务、相似性和释义任务、推理任务。所有任务都是2分类,除了STS-B是一个回归任务,MNLI有3个类别[1][2][3],如下所示:
P-tuning-v2/tasks/glue/dataset.py文件中的task_to_keys字典如下所示:
task_to_keys = {
"cola": ("sentence", None), # 这里的None表示没有第二个句子
"mnli": ("premise", "hypothesis"), # 这里的第一个句子是前提,第二个句子是假设
"mrpc": ("sentence1", "sentence2"), # 这里的第一个句子是句子1,第二个句子是句子2
"qnli": ("question", "sentence"), # 这里的第一个句子是问题,第二个句子是句子
"qqp": ("question1", "question2"), # 这里的第一个句子是问题1,第二个句子是问题2
"rte": ("sentence1", "sentence2"), # 这里的第一个句子是句子1,第二个句子是句子2
"sst2": ("sentence", None), # 这里的None表示没有第二个句子
"stsb": ("sentence1", "sentence2"), # 这里的第一个句子是句子1,第二个句子是句子2
"wnli": ("sentence1", "sentence2"), # 这里的第一个句子是句子1,第二个句子是句子2
}
1.CoLA(The Corpus of Linguistic Acceptability)
纽约大学发布的有关语法的数据集,该任务主要是对一个给定句子,判定其是否语法正确,因此CoLA属于单个句子的文本二分类任务。
2.SST(The Stanford Sentiment Treebank)
斯坦福大学发布的一个情感分析数据集,主要针对电影评论来做情感分类,因此SST属于单个句子的文本分类任务(其中SST-2是二分类,SST-5是五分类,SST-5的情感极性区分的更细致)。
3.MRPC(Microsoft Research Paraphrase Corpus)
由微软发布,判断两个给定句子,是否具有相同的语义,属于句子对的文本二分类任务。
4.STS-B(Semantic Textual Similarity Benchmark)
主要是来自于历年SemEval中的一个任务(同时该数据集也包含在了SentEval),具体来说是用1到5的分数来表征两个句子的语义相似性,本质上是一个回归问题,但依然可以用分类的方法做,因此可以归类为句子对的文本五分类任务。
5.QQP(Quora Question Pairs)
由Quora发布的两个句子是否语义一致的数据集,属于句子对的文本二分类任务。
6.MNLI(Multi-Genre Natural Language Inference)
同样由纽约大学发布,是一个文本蕴含的任务,在给定前提(Premise)下,需要判断假设(Hypothesis)是否成立,其中因为MNLI主打卖点是集合了许多不同领域风格的文本,因此又分为matched和mismatched两个版本的MNLI数据集,前者指训练集和测试集的数据来源一致,而后者指来源不一致。该任务属于句子对的文本三分类问题。
7.QNLI(Question Natural Language Inference)
其前身是SQuAD 1.0数据集,给定一个问句,需要判断给定文本中是否包含该问句的正确答案。属于句子对的文本二分类任务。
8.RTE(Recognizing Textual Entailment)
和MNLI类似,也是一个文本蕴含任务,不同的是MNLI是三分类,RTE只需要判断两个句子是否能够推断或对齐,属于句子对的文本二分类任务。
9.WNLI(Winograd Natural Language Inference)
一个文本蕴含任务,二分类任务,判断两个句子含义是否一样。
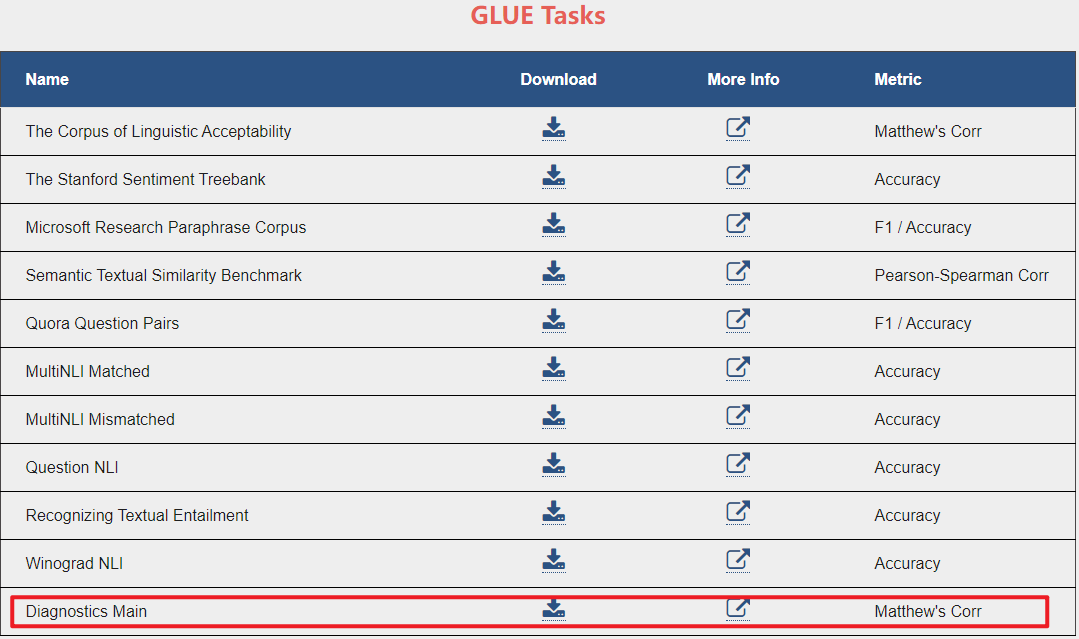
从官网GLUE Tasks来看,现在又多了一个Diagnostics Main分类任务,如下所示:
二.NER任务
主要是处理脚本P-tuning-v2/tasks/ner/dataset.py文件。
1.conll2003数据集
(1)简介
Conll-2003数据集是由欧洲计算语言学学会(CoNLL)于2003年发布的一个英语命名实体识别数据集。该数据集包含了英语新闻文本中的实体类别和实体位置信息。其中,实体类别包括人名、地名、组织名和其他实体。实体位置信息以标注的方式呈现,即以实体开始和结束的字符索引表示。Conll-2003数据集由训练集、开发集和测试集组成,用于训练和评估命名实体识别模型。
(2)下载地址
链接:https://www.cnts.ua.ac.be/conll2002/ner/
2.conll2004数据集
(1)简介
CoNLL04数据集由《华尔街日报》和美联社的新闻文章组成。CoNLL04定义了4种实体类型,包括位置(Loc)、组织(Org)、人(Peop)和其他(Other),以及5种关系类别,即坐落在(Locate_In)、基于组织的在(OrgBased_In)、住在(Live_In)、杀死(Kill)和工作在(Work_For)。
(2)下载地址
链接:https://www.clips.uantwerpen.be/conll2003/ner/
3.ontonotes数据集
(1)简介
OntoNotes 5.0是OntoNotes项目的最后一个版本,是BBN Technologies、科罗拉多大学、宾夕法尼亚大学和南加州大学信息科学研究所之间的合作项目。该项目的目标是对一个大型语料库进行注释,该语料库由三种语言(英语、汉语和阿拉伯语)的各种类型的文本(新闻、电话对话、网络日志、usenet新闻组、广播、脱口秀)组成,包含结构信息(语法和谓词论证结构)和浅层语义(与本体和核心参考相关联的词义)。
(2)下载地址
链接:OntoNotes Release 4.0:https://catalog.ldc.upenn.edu/LDC2011T03;OntoNotes Release 5.0:https://catalog.ldc.upenn.edu/LDC2013T19
三.QA任务
主要是处理脚本P-tuning-v2/tasks/qa/dataset.py文件。
1.SQuAD 1.1数据集
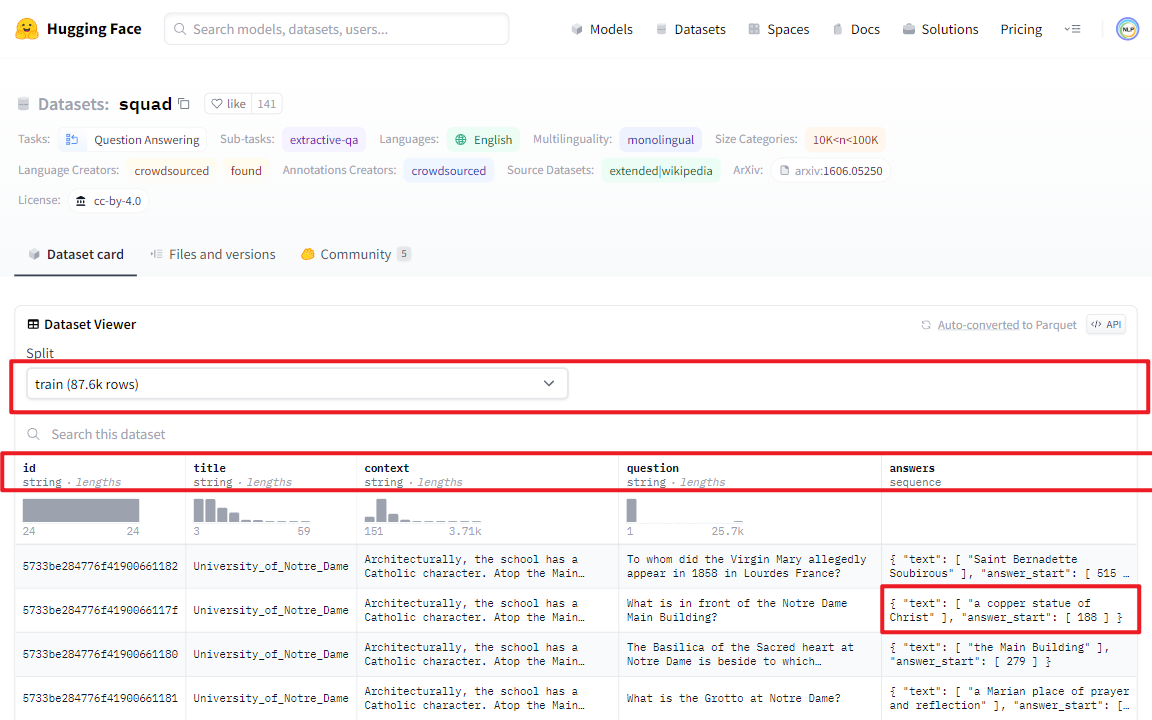
SQuAD是由Rajpurkar等人提出的一个抽取式QA数据集。该数据集包含10万个(问题,原文,答案)三元组,原文来自于536篇维基百科文章。对于每个文章的问题(<=5),有很多标注人员标注答案,且答案出现在原文中。https://huggingface.co/datasets/squad
训练集数据如下所示:
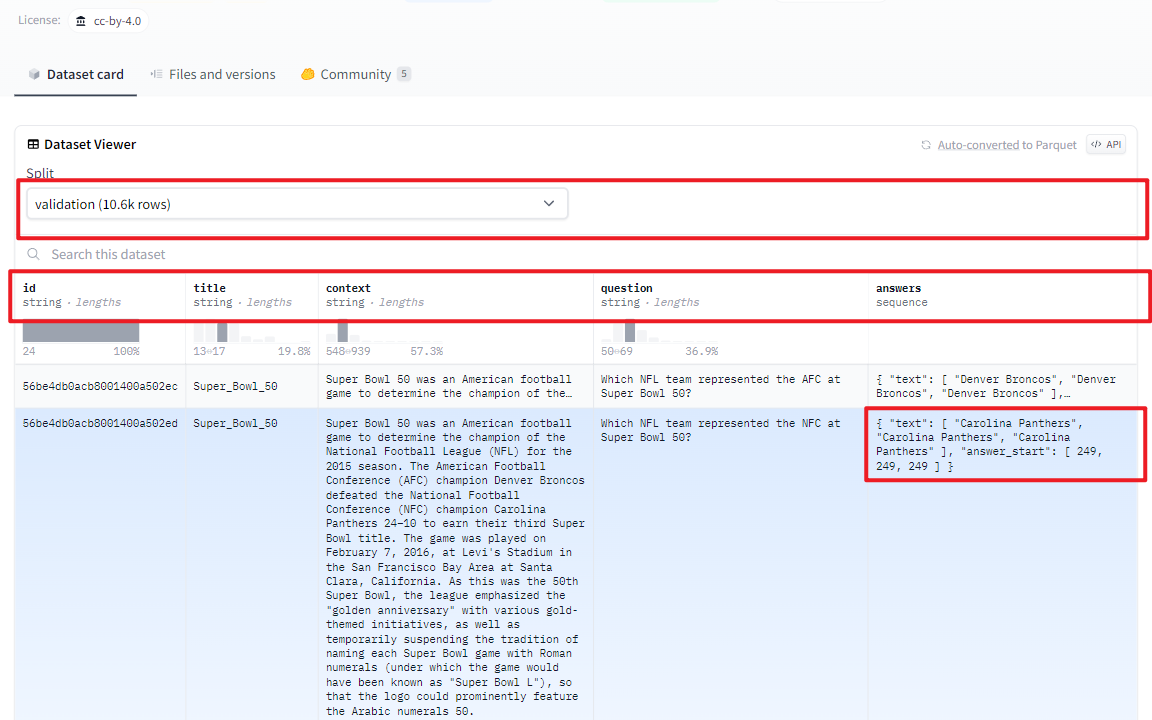
验证集数据如下所示:
2.SQuAD 2.0数据集
相较SQuAD 1.1中的10万问答,SQuAD 2.0又新增了5万个人类撰写的问题——而且问题不一定有对应答案。https://huggingface.co/datasets/squad_v2
训练集数据如下所示:
验证集数据如下所示:
四.SRL任务
主要是处理脚本P-tuning-v2/tasks/srl/dataset.py文件。语义角色标注(Semantic Role Labeling)的目标主要是识别出句子中Who did What to Whom, When and Where。英文数据集主要有CoNLL-2005和CoNLL-2012提供的标注数据集,其中CoNLL-2005的数据集来源于Penn Tree Bank,CoNLL-2012的数据集来源于OntoNotes v5.0。
1.conll2005数据集
链接:https://github.com/strubell/preprocess-conll05
2.conll2012数据集
链接:https://cemantix.org/conll/2012/data.html
五.SuperGlue任务
主要是处理脚本P-tuning-v2/tasks/superglue/dataset.py文件。SuperGLUE(General Language Understanding Evaluation)是一个广泛用于测试自然语言理解模型性能的基准测试集合,由斯坦福大学等机构联合开发。它是自然语言理解领域最具挑战性的测试集之一,旨在推动自然语言处理技术的发展。SuperGLUE中包含BoolQ、CB、COPA、MultiRC、ReCoRD、RTE、WiC、WSC 8个子数据集。详情可参考论文:https://w4ngatang.github.io/static/papers/superglue.pdf。
task_to_keys = {
"boolq": ("question", "passage"), # boolq数据集:包含问题和段落,预测段落是否包含答案
"cb": ("premise", "hypothesis"), # cb数据集:包含前提和假设,预测假设是否为前提的蕴含
"rte": ("premise", "hypothesis"), # rte数据集:包含前提和假设,预测假设是否为前提的蕴含
"wic": ("processed_sentence1", None), # wic数据集:包含2个句子和1个多义词,预测2个句子中的单词含义是否相同
"wsc": ("span2_word_text", "span1_text"), # wsc数据集:包含1个句子和2个名词短语,预测哪个名词短语更符合句子中的指代关系
"copa": (None, None), # copa数据:包含1个问题和2个候选答案,预测哪个答案更符合问题的语境
"record": (None, None), # record数据集:包含1篇新闻文章和1个关于文章的完形填空式问题,预测问题的被屏蔽的实体
"multirc": ("paragraph", "question_answer") # multirc数据集:示例由上下文段落、问题和可能答案列表组成,预测答案是否正确
}
1.BoolQ数据集
BoolQ(Boolean Questions)是一项QA任务,预测段落是否包含答案。
2.CB数据集
CB(CommitmentBank)是一个短文本语料库,根据给定的前提和假设,判断假设是否为前提的蕴含。
3.RTE数据集
RTE(Recognizing Textual Entailment)数据集来自一系列关于文本蕴涵的年度竞赛,判断给定的两个句子是否具有蕴含关系。
4.WiC数据集
WiC(Word-in-Context)是一个词义消歧任务,作为句子对的二元分类。给定两个文本片段和一个出现在两个句子中的多义词,任务是确定该词在两个句子中是否以相同的含义使用。
5.WSC数据集
WSC(Winograd Schema Challenge)在GLUE中以NLI任务出现,给定一个句子和两个名词短语,判断哪个名词短语更符合句子中的指代关系。
6.COPA数据集
COPA(Choice of Plausible Alternatives)是一项因果推理任务,给定一个问题和两个候选答案,判断哪个答案更符合问题的语境。
7.ReCoRD数据集
ReCoRD(Reading Comprehension with Commonsense Reasoning Dataset)是一项多项选择的QA任务,每个示例都包含一篇新闻文章和一个关于文章的完形填空式问题,文章中的一个实体被屏蔽掉了,模型需要从提供的段落中给定的可能实体列表中预测被屏蔽的实体。
8.MultiRC数据集
MultiRC(Multi-Sentence Reading Comprehension)是一项QA任务,其中每个示例由上下文段落、关于该段落的问题和可能答案列表组成,由模型预测哪些答案是正确的,哪些是错误的。
参考文献:
[1]GLUE的论文:GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding(https://aclanthology.org/W18-5446/)
[2]GLUE的官网:https://gluebenchmark.com/
[3]NLP常见任务介绍:https://www.cnblogs.com/guozw/p/13369757.html
[4]NER常用数据集汇总:https://zhuanlan.zhihu.com/p/606788093
[5]SUPER_GLUE数据集:https://www.modelscope.cn/datasets/modelscope/super_glue/summary
Langchain-Chatchat项目:4.2-P-Tuning v2使用的数据集的更多相关文章
- 已使用.netframework,version=v4.6.1 而不是目标框架netcoreapp,version=v2.1 还原包,此包可能与项目不完全兼容
已使用.netframework,version=v4.6.1 而不是目标框架netcoreapp,version=v2.1 还原包,此包可能与项目不完全兼容 NU1202: 包 System.Run ...
- Restful.Data v2.0发布,谢谢你们的支持和鼓励
v1.0发布后,承蒙各位博友们的热心关注,也给我不少意见和建议,在此我真诚的感谢 @冰麟轻武 等朋友,你们的支持和鼓励,是这个开源项目最大的推动力. v2.0在除了细枝末节外,在功能上主要做了一下更新 ...
- 【多端应用开发系列1.1.1 —— Android:使用新浪API V2】服务器Json数据处理——Json数据概述
[前白] 一些基础的东西本系列中就不再详述了,争取尽量写些必不可少的技术要点. 由于本系列把Web Service 构建放到了第二部分,Android项目就采用新浪微博API v2作为服务器端. [原 ...
- Ionic项目中如何使用Native Camera
本文介绍如何在ionic项目中使用设备的camera. Ionic版本:v3.2.0 / 2017-05-10 / MIT Licensed / Release Notes ============= ...
- ionic2项目创建回顾 及 react-native 报错处理
ionic2: 1.创建项目: ionic start MyIonic2Project tutorial --v2 (下载 tutorial 模板来初始化项目) ionic start MyIonic ...
- 一起了解 .Net Foundation 项目 No.4
.Net 基金会中包含有很多优秀的项目,今天就和笔者一起了解一下其中的一些优秀作品吧. 中文介绍 中文介绍内容翻译自英文介绍,主要采用意译.如与原文存在出入,请以原文为准. BenchmarkDotN ...
- .NET 6 中外部引用项目NU1105异常问题解决
.NET 6 Project中,添加了其他解决方案的工程后,本地能编译通过,代码签入后,其他同事下载代码,编译报错: 错误 NU1105 找不到"E:\Teld\01Code\TTP_CTP ...
- 找了几个 Solon 的商业落地项目案例!
Solon 是啥?是一个高效的 Java 应用开发框架:更快.更小.更简单.(代码仓库:https://gitee.com/noear/solon) 提倡: 克制.简洁.开放.生态 启动快 5 - 1 ...
- 顶级项目孵化的故事系列——Kylin的心路历程【转】
现在已经名满天下的 Apache Kylin,是 Hadoop 大数据生态系统不可或缺的一部分,要知道在 Kylin 项目早期,可是以华人为主的开源团队,一路披荆斩棘经过几年的奋斗,才在 Apache ...
- Expression Blend实例中文教程(6) - 项目控件和用户交互控件快速入门
前文我们曾经描述过,微软把Silverlight控件大致分为三类: 第一类: Layout Controls(布局控件) 第二类: Item Controls (项目控件) 第三类: User Int ...
随机推荐
- .NET for Apache Spark 入门演练
.NET for Apache Spark 入门演练 微软官方文档: .NET for Apache Spark 入门 | Microsoft Learn 注意:由于本次在windows平台下进行演练 ...
- MAUI Blazor项目中如何添加一个返回服务,并支持安卓返回键
前言 MAUI Blazor中,安卓项目的返回键体验很不好,只能如同浏览器一样返回上一页.但很多时候,我们想让他返回的上一页,不一定就是实际上的上一页.而且也想让返回键去支持一些事件,按下返回键触发, ...
- CPU摸鱼被抓,上了一个新技术!
我叫阿Q,是CPU一号车间里的员工,我所在的这个CPU足足有8个核,就有8个车间,干起活来杠杠滴. 我们CPU的任务就是执行程序员编写的程序,只不过程序员编写的是高级语言代码,而我们执行的是这些代码被 ...
- 2021-6-17 plc连接
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- python-stack
implements list deque LifoQueue 原文地址:https://realpython.com/how-to-implement-python-stack/ Argue lis ...
- js实现继承的五种方法及原型的继承关系
继承是javascript中实现代码复用的一种方式,也能绑定对象或者函数之间的关系 为什么要继承 比如以下代码,Person.Student和Teacher构造函数,可以发现他们有一些特征 Perso ...
- [prometheus]基于influxdb2实现远端存储
前言 Prometheus自带的时序数据库胜在使用方便,缺点在于难以维护,如果数据有问题,可能需要删除存储目录.重建目录再重启Prometheus,才能恢复正常.而且Prometheus自带的时序数据 ...
- 我是如何使用Spring Retry减少1000 行代码
本文翻译自国外论坛 medium,原文地址:https://levelup.gitconnected.com/how-i-deleted-more-than-1000-lines-of-code-us ...
- ETL之apache hop系列2-hop web安装和入门
前言 在Docker安装apache hop 首先确保Docker已经安装和运行Java 11 JDK 安装文档参考:https://blog.csdn.net/Chia_Hung_Yeh/artic ...
- AI绘画工具MJ新功能有点东西,小白也能轻松一键换装
先看最终做出来的效果 直接来干货吧.Midjourney,下面简称MJ 1.局部重绘功能来袭 就在前两天,MJ悄咪咪上线了这个被众人期待的新功能:局部重绘. 对于那些追求创新和个性化的设计师来说,局部 ...