动手实践丨基于ModelAtrs使用A2C算法制作登月器着陆小游戏
摘要:在本案例中,我们将展示如何基于A2C算法,训练一个LunarLander小游戏。
本文分享自华为云社区《使用A2C算法控制登月器着陆》,作者:HWCloudAI 。
LunarLander是一款控制类的小游戏,也是强化学习中常用的例子。游戏任务为控制登月器着陆,玩家通过操作登月器的主引擎和副引擎,控制登月器降落。登月器平稳着陆会得到相应的奖励积分,如果精准降落在着陆平台上会有额外的奖励积分;相反地如果登月器坠毁会扣除积分。
A2C全称为Advantage Actor-Critic,在本案例中,我们将展示如何基于A2C算法,训练一个LunarLander小游戏。
整体流程:基于gym创建LunarLander环境->构建A2C算法->训练->推理->可视化效果
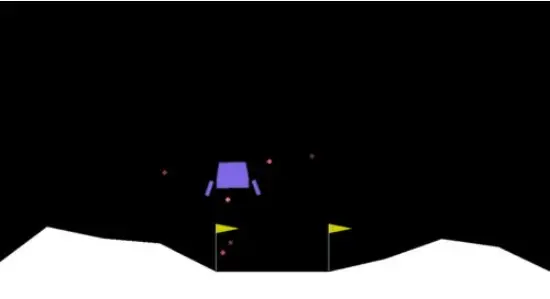
A2C算法的基本结构
A2C是openAI在实现baseline过程中提出的,是一种结合了Value-based (比如 Q learning) 和 Policy-based (比如 Policy Gradients) 的强化学习算法。
Actor目的是学习策略函数π(θ)以得到尽量高的回报。 Critic目的是对当前策略的值函数进行估计,来评价。
- Policy Gradients
Policy Gradient算法的整个过程可以看作先通过策略π(θ)让agent与环境进行互动,计算每一步所能得到的奖励,并以此得到一局游戏的奖励作为累积奖励G,然后通过调整策略π,使得G最大化。所以使用了梯度提升的方法来更新网络参数θ,利用更新后的策略再采集数据,再更新,如此循环,达到优化策略的目的。
- Actor Critic
agent在于环境互动过程中产生的G值本身是一个随机变量,可以通过Q函数去估计G的期望值,来增加稳定性。即Actor-Critic算法在PG策略的更新过程中使用Q函数来代替了G,同时构建了Critic网络来计算Q函数,此时Actor相关参数的梯度为:
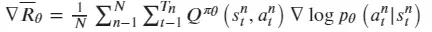
而Critic的损失函数使用Q估计和Q实际值差的平方损失来表示:
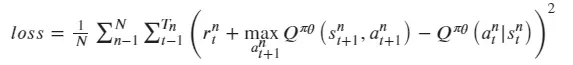
- A2C算法
A2C在AC算法的基础上使用状态价值函数给Q值增加了基线V,使反馈可以为正或者为负,因此Actor的策略梯变为:
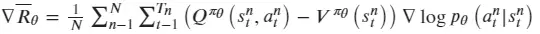
同时Critic网络的损失函数使用实际状态价值和估计状态价值的平方损失来表示:
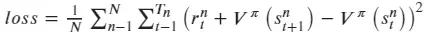
LunarLander-v2游戏环境简介
LunarLander-v2,是基于gym和box2d提供的游戏环境。游戏任务为玩家通过操作登月器的喷气主引擎和副引擎来控制登月器降落。
gym:开源强化学习python库,提供了算法和环境交互的标准API,以及符合该API的标准环境集。
box2d:gym提供的一种环境集合
注意事项
- 本案例运行环境为 TensorFlow-1.13.1,且需使用 GPU 运行,请查看《ModelAtrs JupyterLab 硬件规格使用指南》了解切换硬件规格的方法;
- 如果您是第一次使用 JupyterLab,请查看《ModelAtrs JupyterLab使用指导》了解使用方法;
- 如果您在使用 JupyterLab 过程中碰到报错,请参考《ModelAtrs JupyterLab常见问题解决办法》尝试解决问题。
实验步骤
1. 程序初始化
第1步:安装基础依赖
要确保所有依赖都安装成功后,再执行之后的代码。如果某些模块因为网络原因导致安装失败,直接重试一次即可。
!pip install gym
!conda install swig -y
!pip install box2d-py
!pip install gym[box2d]
第2步:导入相关的库
import os
import gym
import numpy as np
import tensorflow as tf
import pandas as pd
2. 参数设置¶
本案例设置的 游戏最大局数 MAX_EPISODE = 100,保存模型的局数 SAVE_EPISODES = 20,以便快速跑通代码。
你也可以调大 MAX_EPISODE 和 SAVE_EPISODES 的值,如1000和100,可以达到较好的训练效果,训练耗时约20分钟。
MAX_EPISODE = 100 # 游戏最大局数
DISPLAY_REWARD_THRESHOLD = 100 # 开启可视化的reward阈值
SAVE_REWARD_THRESHOLD = 100 # 保存模型的reward阈值
MAX_EP_STEPS = 2000 # 每局最大步长
TEST_EPISODE = 10 # 测试局
RENDER = False # 是否启用可视化(耗时)
GAMMA = 0.9 # TD error中reward衰减系数
RUNNING_REWARD_DECAY=0.95 # running reward 衰减系数
LR_A = 0.001 # Actor网络的学习率
LR_C = 0.01 # Critic网络学习率
NUM_UNITS = 20 # FC层神经元个数
SEED = 1 # 种子数,减小随机性
SAVE_EPISODES = 20 # 保存模型的局数
model_dir = './models' # 模型保存路径
3. 游戏环境创建
def create_env():
env = gym.make('LunarLander-v2')
# 减少随机性
env.seed(SEED)
env = env.unwrapped
num_features = env.observation_space.shape[0]
num_actions = env.action_space.n
return env, num_features, num_actions
4. Actor-Critic网络构建¶
class Actor:
"""
Actor网络
Parameters
----------
sess : tensorflow.Session()
n_features : int
特征维度
n_actions : int
动作空间大小
lr : float
学习率大小
"""
def __init__(self, sess, n_features, n_actions, lr=0.001):
self.sess = sess
# 状态空间
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
# 动作空间
self.a = tf.placeholder(tf.int32, None, "action")
# TD_error
self.td_error = tf.placeholder(tf.float32, None, "td_error")
# actor网络为两层全连接层,输出为动作概率
with tf.variable_scope('Actor'):
l1 = tf.layers.dense(
inputs=self.s,
units=NUM_UNITS,
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='l1'
)
self.acts_prob = tf.layers.dense(
inputs=l1,
units=n_actions,
activation=tf.nn.softmax,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='acts_prob'
)
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
# 损失函数
self.exp_v = tf.reduce_mean(log_prob * self.td_error)
with tf.variable_scope('train'):
# minimize(-exp_v) = maximize(exp_v)
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v)
def learn(self, s, a, td):
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
# 生成动作
def choose_action(self, s):
s = s[np.newaxis, :]
probs = self.sess.run(self.acts_prob, {self.s: s})
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel())
class Critic:
"""
Critic网络
Parameters
----------
sess : tensorflow.Session()
n_features : int
特征维度
lr : float
学习率大小
"""
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
# 状态空间
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
# value值
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
# 奖励
self.r = tf.placeholder(tf.float32, None, 'r')
# critic网络为两层全连接层,输出为value值
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
# number of hidden units
units=NUM_UNITS,
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
# output units
units=1,
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + GAMMA * self.v_ - self.v
# TD_error = (r+gamma*V_next) - V_eval
self.loss = tf.square(self.td_error)
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
5. 创建训练函数
def model_train():
env, num_features, num_actions = create_env()
render = RENDER
sess = tf.Session()
actor = Actor(sess, n_features=num_features, n_actions=num_actions, lr=LR_A)
critic = Critic(sess, n_features=num_features, lr=LR_C)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
for i_episode in range(MAX_EPISODE+1):
cur_state = env.reset()
cur_step = 0
track_r = []
while True:
# notebook暂不支持该游戏的可视化
# if RENDER:
# env.render()
action = actor.choose_action(cur_state)
next_state, reward, done, info = env.step(action)
track_r.append(reward)
# gradient = grad[reward + gamma * V(next_state) - V(cur_state)]
td_error = critic.learn(cur_state, reward,
next_state)
# true_gradient = grad[logPi(cur_state,action) * td_error]
actor.learn(cur_state, action, td_error)
cur_state = next_state
cur_step += 1
if done or cur_step >= MAX_EP_STEPS:
ep_rs_sum = sum(track_r)
if 'running_reward' not in locals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * RUNNING_REWARD_DECAY + ep_rs_sum * (1-RUNNING_REWARD_DECAY)
# 判断是否达到可视化阈值
# if running_reward > DISPLAY_REWARD_THRESHOLD:
# render = True
print("episode:", i_episode, " reward:", int(running_reward), " steps:", cur_step)
break
if i_episode > 0 and i_episode % SAVE_EPISODES == 0:
if not os.path.exists(model_dir):
os.mkdir(model_dir)
ckpt_path = os.path.join(model_dir, '{}_model.ckpt'.format(i_episode))
saver.save(sess, ckpt_path)
6. 开始训练
训练一个episode大约需1.2秒
print('MAX_EPISODE:', MAX_EPISODE)
model_train()
# reset graph
tf.reset_default_graph()
7.使用模型推理
由于本游戏内核可视化依赖于OpenGL,需要桌面化操作系统的窗口显示,但当前环境暂不支持弹窗,因此无法可视化,您可将代码下载到本地,取消 env.render() 这行代码的注释,查看可视化效果。
def model_test():
env, num_features, num_actions = create_env()
sess = tf.Session()
actor = Actor(sess, n_features=num_features, n_actions=num_actions, lr=LR_A)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint(model_dir))
for i_episode in range(TEST_EPISODE):
cur_state = env.reset()
cur_step = 0
track_r = []
while True:
# 可视化
# env.render()
action = actor.choose_action(cur_state)
next_state, reward, done, info = env.step(action)
track_r.append(reward)
cur_state = next_state
cur_step += 1
if done or cur_step >= MAX_EP_STEPS:
ep_rs_sum = sum(track_r)
print("episode:", i_episode, " reward:", int(ep_rs_sum), " steps:", cur_step)
break
model_test()
episode: 0 reward: -31 steps: 196
episode: 1 reward: -99 steps: 308
episode: 2 reward: -273 steps: 533
episode: 3 reward: -5 steps: 232
episode: 4 reward: -178 steps: 353
episode: 5 reward: -174 steps: 222
episode: 6 reward: -309 steps: 377
episode: 7 reward: 24 steps: 293
episode: 8 reward: -121 steps: 423
episode: 9 reward: -194 steps: 286
8.可视化效果
下面的视频为训练1000 episode模型的推理效果,该视频演示了在三个不同的地形情况下,登月器都可以安全着陆
动手实践丨基于ModelAtrs使用A2C算法制作登月器着陆小游戏的更多相关文章
- 实践案例丨基于ModelArts AI市场算法MobileNet_v2实现花卉分类
概述 MobileNetsV2是基于一个流线型的架构,它使用深度可分离的卷积来构建轻量级的深层神经网,此模型基于 MobileNetV2: Inverted Residuals and Linear ...
- 动手实践丨手把手教你用STM32做一个智能鱼缸
摘要:本文基于STM32单片机设计了一款基于物联网的智能鱼缸. 本文分享自华为云社区<基于STM32+华为云IOT设计的物联网鱼缸[玩转华为云]>,作者: DS小龙哥 . 1. 前言 为了 ...
- 中国.NET开发者峰会特别活动-基于k8s的微服务和CI/CD动手实践报名
2019.11.9 的中国.NET开发者峰会将在上海举办,到目前为止,大会的主题基本确定,这两天就会和大家会面,很多社区的同学基于对社区的信任在我们议题没有确定的情况下已经购票超过了300张,而且分享 ...
- Redis集群研究和实践(基于redis 3.0.5)
前言 redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用.现在的2.x的稳定版本是2.8.19,也是我们项目中普遍用到的版本. redis在年初发布了3.0. ...
- dis集群研究和实践(基于redis 3.0.5) 《转载》
https://www.cnblogs.com/wxd0108/p/5798498.html 前言 redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用.现在的 ...
- 在Hadoop上运行基于RMM中文分词算法的MapReduce程序
原文:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-count-on-hadoop/ 在Hadoop上运行基于RMM中文分词 ...
- [转帖]Docker从入门到动手实践
Docker从入门到动手实践 https://www.cnblogs.com/nsky/p/10853194.html dockerfile的图很好呢. 但是自己没有做实验 , 其实知识都挺好. do ...
- 推荐系统实践 0x09 基于图的模型
用户行为数据的二分图表示 用户的购买行为很容易可以用二分图(二部图)来表示.并且利用图的算法进行推荐.基于邻域的模型也可以成为基于图的模型,因为基于邻域的模型都是基于图的模型的简单情况.我们可以用二元 ...
- JavaScript基于时间的动画算法
转自:https://segmentfault.com/a/1190000002416071 前言 前段时间无聊或有聊地做了几个移动端的HTML5游戏.放在不同的移动端平台上进行测试后有了诡异的发现, ...
- 最小生成树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind
最小支撑树树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind 最小支撑树树 前几节中介绍的算法都是针对无权图的,本节将介绍带权图的最小 ...
随机推荐
- 漫谈C#的定时执行程序
1.写法1 task的lambda表达式 #region 写法1 task的lambda表达式 //static void Main() //{ // // 创建并启动两个任务 // Task tas ...
- 低代码平台探讨-MetaStore元数据缓存
背景及需求 之前提到我们模型驱动的实现选择的是解释型,需要模型的元数据信息,在接到请求后动态处理逻辑. 此外,应用的通用能力中还包括:页面dsl查询,菜单查询等. 而且后期加入触发器,用户自定义api ...
- XX-net安装
1.下载https://github.com/XX-net/XX-Net 2. 3. 4.运行google浏览器 5.找到安装XX-net的位置,点击即可访问google ps:校园网用户可以直接使用 ...
- MAC版本vmware无法识别虚拟机网卡适配器
一.问题 莫名其妙的突然mac上的vmware无法识别网络适配器了 二.解决过程 1.重装vmware-无效 2.降级安装vmware-无效 3.安装pd虚拟机,并使用sudo命令启动-偶尔有效 4. ...
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-22-处理select下拉框-上篇
1.简介 在实际自动化测试过程中,我们也避免不了会遇到下拉框选择的测试,因此宏哥在这里直接分享和介绍一下,希望小伙伴或者童鞋们在以后工作中遇到可以有所帮助.今天,我们讲下playwright的下拉框怎 ...
- UML学习入门就这一篇文章(转)
1.1 UML基础知识扫盲 UML这三个字母的全称是Unified Modeling Language,直接翻译就是统一建模语言,简单地说就是一种有特殊用途的语言. 你可能会问:这明明是一种图形,为什 ...
- linux 使用crontab 创建定时任务
转载请注明出处: 在服务器中需要创建一个定时任务,每天执行去清理很早之前备份的文件,所以想到在linux上创建一个shell脚本,通过linux的 crontab 命令定时去执行该shell脚本,从而 ...
- HTML基础_01
HTML 基础_01 01.初识 HTML 什么是 HTML! Hyper Text Markup Language(超文本标记语言).超文本包括文字.图片.音频.视频.动画等. HTML5,提供了一 ...
- L2-032 彩虹瓶
#include <bits/stdc++.h> using namespace std; const int N = 1010; int main() { ios::sync_with_ ...
- Kubernetes 中的服务注册与发现原理分析
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 对k8s有点了解技术人员,应该都只知道k8s是有服务注册发现的,今天就分析下这个原理,看看怎么实现的. 什么是服务注册与发 ...