nodejs加jq来实现下载word文档
先看效果 浏览器上:
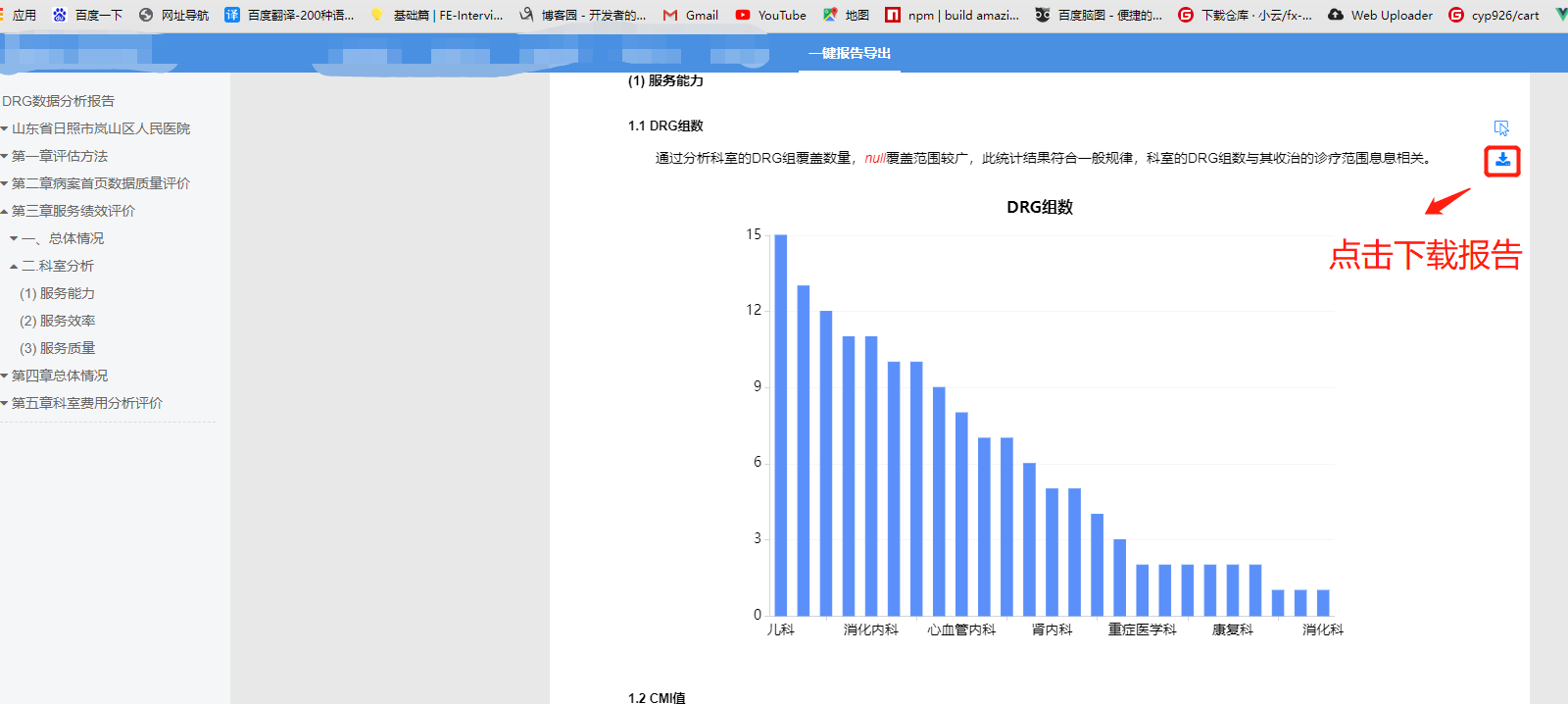
下载的效果:
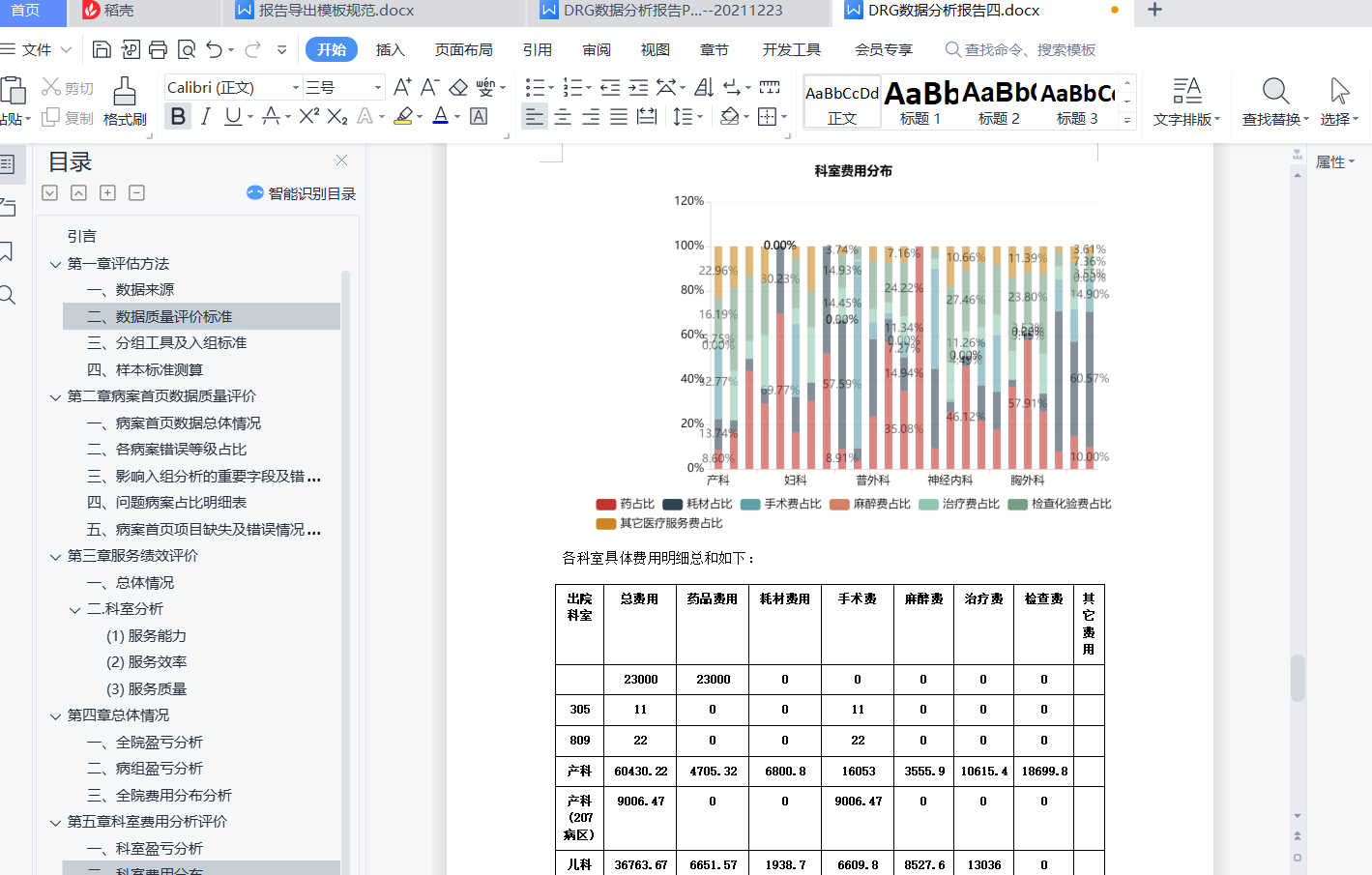
第一步是自己先搭建前端页面把自己写的结构数据全部传到后端 下面就是整个的结构
结构分析后端拿到数据后端解析:
第一层菜单层:
{
role: '分析报告', //顶级菜单标题
aimTarget: 'role_1', //对应的code
vte_ais: [] //第二级菜单
} 第二级菜单层vte_ais:
[
{
title: '二级标题 ',//二级菜单标题
aimTarget: 'role_1_1',//对应的code
project_items: [Array]//三级菜单层
}
] 第三级菜单层project_items:
//同一个段落里面文本信息有时候会多出来几个我就多写了一些字段来分开 表格也是 三个表格就写了三个字段
[
{
title: '一、总体情况',//三级菜单标题
aimTarget: 'role_1_4_1',//对应的code
project_unit_text: '  通过统计近两年内的住院患者,共计428份病例, 本院DRG入组数为168,是XM-DIP1.0(医保编码2.0)组数的0%,说明本院诊疗范
围有一定扩大空间,可根据医院发展规划进行适当补充。本院DRG入组率为0%,建议提升病案数据质量以提高DRG入组率。',//文本信息
tableTitle: '',//表格标题
projectTable: {//第一个表格
uniteTable: [],//colspan
columns: [Array],//表格表头
list: [Array],//表格数据
uniteTabler: [Array]// rowspan
},
project_unit_textTwo: '  根据TOP10 2019-2020年DRG入组数及占比情况统计,全院病例入组数最高的为ES29 呼吸系统感染/炎症,代表我院呼吸系统
感染病例相对其他病例数量居多,可重点关注本组病案质量及学科发展,前十位入组数及占比排序如下:',//文本信息
proiect_unit_textH3: 'TOP10 2021-2022 年DRG入组数及占比 ',//标题
project_unit_textTherr: '  通过科室的入组率统计,入组率相对较高的主要为null,入组率较低的为null。入组率较低的原因有可能为患者数量较多
且病案数据质量不够完善,建议重点关注此类科室的问题病案数量。',//文本信息
projectTableTwo: {//第二个表格
columns: [Array], //表格表头
list: [] },//表格数据
echarts: {
src: 12112 //对应echarts报表图片id
},
clsaaTable: { //第三个项目表格
title: '全院费用分布及占比情况',//表格标题
columns: allHeaderT[11],//表格表头
uniteTable: allcolspan[1],//colspan
list: allTbody[11],//表格数据
rowspan: [[], [], []],//rowspan
},
class_items: [],//s四级菜单
project_unit_name: '一、总体情况'//三级菜单标题
},
] 四级菜单层 class_items:
{
title: '(1) 服务能力',//四级菜单标题
aimTarget: 'role_1_4_2_1',//对应的code
target_items: [ [Object], [Object], [Object] ]//五级菜单(只展示四级菜单,五级算是四级里面扩展的小段落)
}, 五级菜单层 target_items:
[ {
target: '3.1 死亡率',//五级菜单标题
item_text: '通过科室的死亡率统计,null的死亡率明显高于其他科室,这一统计结果符合一般规律,与科室自身的诊疗特性有一定关系',//文本信息
echart: {
src: 12118 //echarts报表id
}
}
]
有echarts报表必须把echarts转换成图片传给后端保存 下载的时候去后端拿对应图片就行了 点击下载先保存图片 先前端:

chartAboutEvent: function () {
var _t = this;
//下载报表对应图片
//获取报告中所有的报表,将其转成图片,存储在download根文件夹下
var urlArr = []
var chartId = []
var chartDom = $('.imgBox').find('.zhurong_chartCont_box') || 'iChartPart';//获取echarts父级DOM实例 这是自己定义calss找到的 echarts官网有直接写成图片的api你们可以去看看 不一定用这里的
for (var i = 0; i < _t.dataList.length; i++) {//是每个echarts的code 不同编号 是个数组 是按照这个code来请求echarts的
var myChart = echarts.getInstanceByDom(chartDom.get(i));//获取每一个echartsDOM实例 内置api
if (myChart) {
const chaId = myChart._dom.offsetParent.classList[1].replace(/zhurong_chartWrp/g, '')//获取每个的echarts的code 因为有时候没有数据就得和dataList对比 有对应的code才做成图片
var url = myChart.getConnectedDataURL({//内置pai
pixelRatio: 2, //导出的图片分辨率比率,默认是1
backgroundColor: '#fff', //图表背景色
excludeComponents: [ //保存图表时忽略的工具组件,默认忽略工具栏
'toolbox'
],
type: 'png' //图片类型支持png和jpeg
});
chartId.push({ chart_id: chaId })
urlArr.push({ url })
}
}
if (urlArr) {
$.axios({
url: Urls.saveChartImgs,
data: {
pageId: 'drgs',
chartId: chartId, //chart_id
imgData: urlArr
},
success: function (res) {
if (res.code == 200) {
_t.downloadWord(chartId);
} else {
$('body').toast('echarts图表暂无数据无法生成报告', 'warning');
}
}
})
} else { //ie8不支持getConnectedDataURL方法,不支持图表导出
$('body').toast('浏览器版本太低,不支持png图表导出', 'warning');
}
},
node端接受图片的接口:
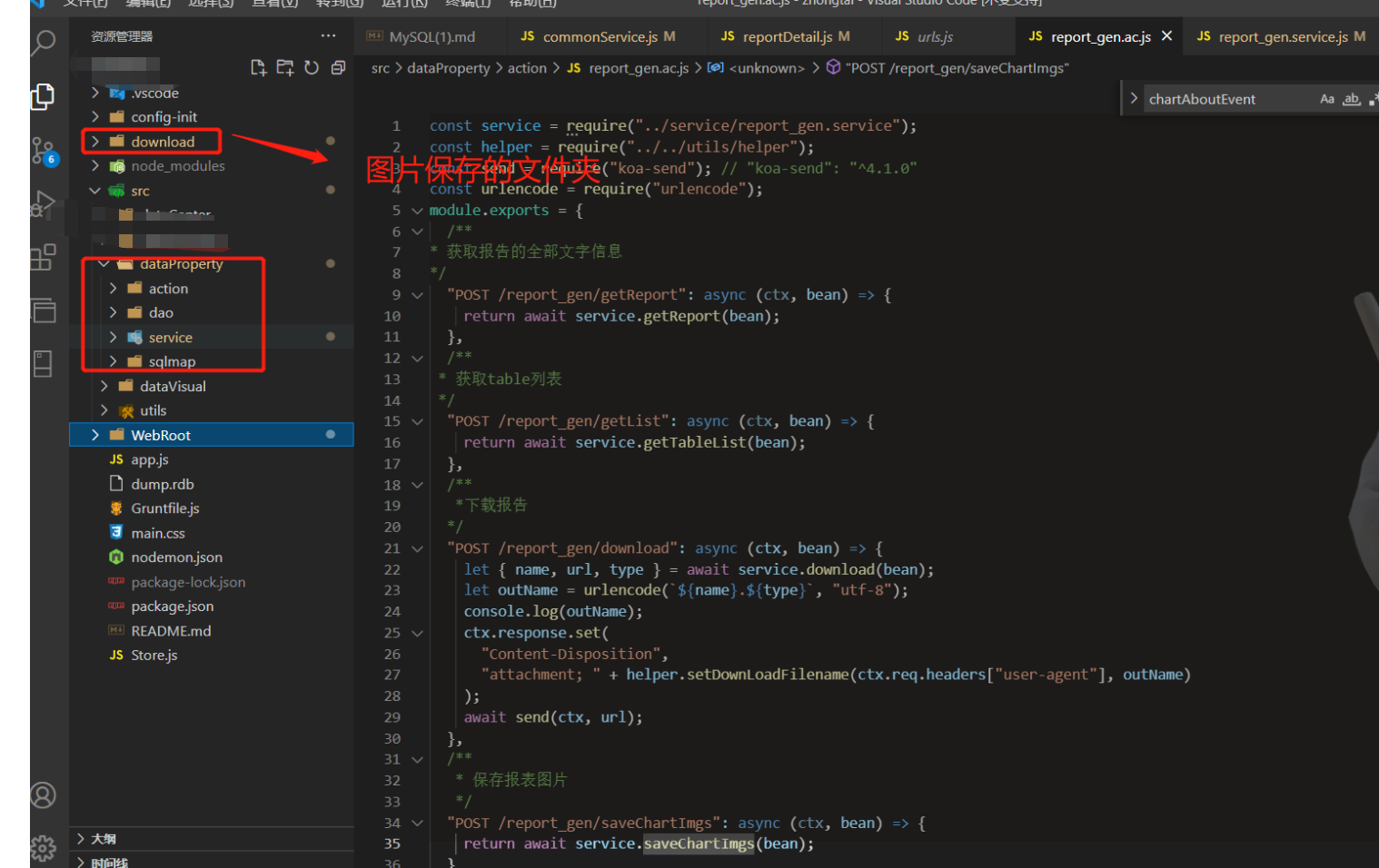
const service = require("../service/report_gen.service");
const helper = require("../../utils/helper");
const send = require("koa-send"); // "koa-send": "^4.1.0"
const urlencode = require("urlencode");
module.exports = {
/**
*下载报告
*/
"POST /report_gen/download": async (ctx, bean) => {
let { name, url, type } = await service.download(bean);
let outName = urlencode(`${name}.${type}`, "utf-8");
console.log(outName);
ctx.response.set(
"Content-Disposition",
"attachment; " + helper.setDownLoadFilename(ctx.req.headers["user-agent"], outName)
);
await send(ctx, url);
},
/**
* 保存报表图片
*/
"POST /report_gen/saveChartImgs": async (ctx, bean) => {
return await service.saveChartImgs(bean);
}
}
service文件里面的saveChartImgs
const dao = require("../dao/report_gen.dao");
const fs = require("fs");
const path = require("path");
/**
* 保存图表图片
*/
async saveChartImgs(params) {
let { pageId, chartId, imgData } = params;
//过滤data:URL
for (var i = 0; i < chartId.length; i++) {
if (imgData[i]) {
var base64Data = imgData[i].url.replace(/^data:image\/\w+;base64,/, "");
var dataBuffer = new Buffer.from(base64Data, 'base64');
/*
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。
但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,
每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内 存。*/
if (!fs.existsSync(path.join('download/', pageId + '/'))) {
fs.mkdirSync(path.join('download/', pageId + '/'));
}//提供的一种API,用于以围绕标准POSIX函数的紧密建模方式与文件系统进行交互。 fs.mkdirSync()方法用于同步创建目录
var result = await fs.writeFileSync(path.join('download/', pageId + '/') + "chart_" + chartId[i].chart_id + ".png", dataBuffer, function (err) {
if (err) {
return { data: err };
} else {
return { data: '保存成功' }
}
});
}
}
return { id: pageId };;
},
这样图片就好了 再开始下载:
先添加form表单随便在元素挂载后调用一下就行
/**
* 添加form下载组件
* @param {*} wrp
*/
appendFormDownload: function () {
if ($('body').find('#review_download_form').length === 0) {
$('body').append('<form action="" method="post" style="display: none;" id="review_download_form"><input name="data" value="" id="review_download_ipt"></form>');
}
},
再下载函数 用的 officegen这个第三方插件 可以去开源里面看一下怎么用的https://www.npmjs.com/package/officegen
里面表格有合并单元格的 示例:https://github.com/Ziv-Barber/officegen/issues/364
所以在前端做表格的时候要注意合并单元格 示例:
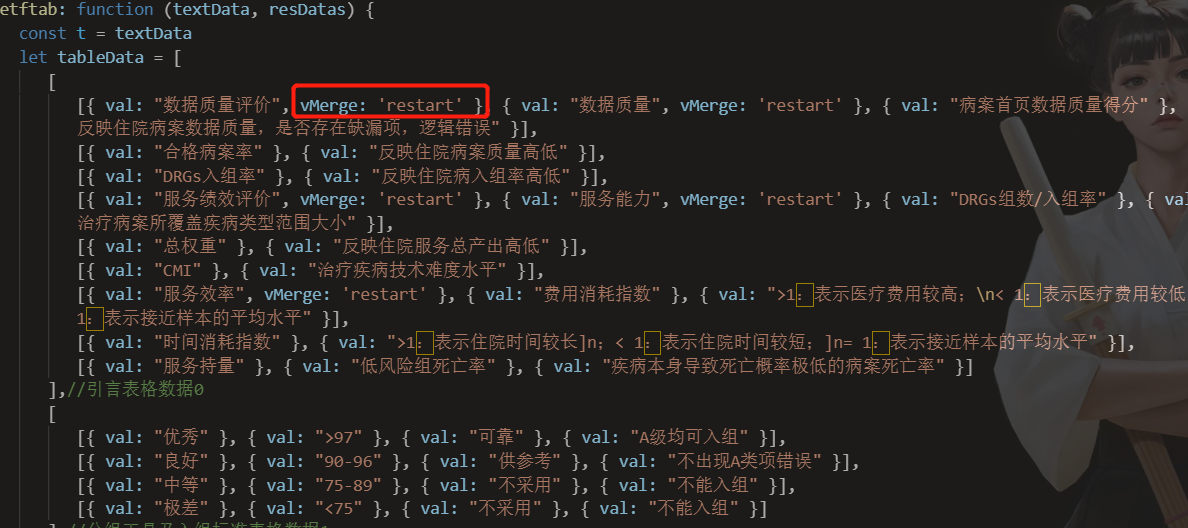
数据必须写val 才能识别 vMerge是合并单元格的开始 看下网上的https://github.com/Ziv-Barber/officegen/pull/348
/**
* 下载word
*/
downloadWord: function (chartId) {
var _t = this;
var formData = {
curChartId: chartId
};
if (_t.mainData) {
for (var key in _t.mainData) {
formData[key] = _t.mainData[key];
}
}
$("#review_download_form").attr("action", Urls.downloadWord);
var t = JSON.stringify(formData);
$("#review_download_ipt").attr("value", t),
$("#review_download_form").submit();
},
node端接受数据结构解析:
const dao = require("../dao/report_gen.dao");
const officegen = require("officegen");
const fs = require("fs");
const path = require("path");
const sizeOf = require('image-size');
/**
* 下载word
* @param {*} params
*/
async download(params) {
let { data } = params;
let datalist = JSON.parse(data)
let curChartId = datalist.curChartId
let outFile = { name: "DRG数据分析报告", type: "docx" };
let file = await generate(
{
type: "docx",
title: "DRG数据分析报告",
},
outFile,
datalist[0],
curChartId
);
return file;
},
};
/**
* 生成word 文件
* @param {officegen 配置文件} options
* @param {写出的文件设置} outFile
*/
async function generate(options, { name = "example", type = "docx" }, sourceData, curChartId) {
return new Promise((resolve, reject) => {
const createDirIfNotExists = (dir) => (!fs.existsSync(dir) ? fs.mkdirSync(dir) : dir); // 创建目录
createDirIfNotExists("download"); // 创建文件夹
const outDir = path.join(`download/`); // 写出文件目录
const office = officegen(options);
// // 构建数据结构
let data = bindSourceData(sourceData, curChartId);
office.createByJson(data);
let url = path.join(outDir, `${name}.${type}`);
const out = fs.createWriteStream(url);
office.generate(out, {
finalize: function (data) {
process.logger.info(`${name}.${type} 文档生成成功!`);
},
error: reject,
});
out.on("finish", function () {
resolve({ name, url, type });
});
});
}
const h1 = {
type: "text",
opt: {
bold: true,
font_size: 24,
},
};
const h2 = {
type: "text",
opt: {
bold: true,
font_size: 20,
},
};
const h3 = {
type: "text",
opt: {
bold: true,
font_size: 16,
},
};
const h4 = {
type: "text",
opt: {
bold: true,
font_size: 14,
},
};
const h5 = {
type: "text",
opt: {
bold: true,
font_size: 12,
},
}
const page = {
type: "text",
opt: {
color: "000000",
},
};
const spaceBar = {
type: "text",
opt: {
color: "fff",
font_size: 10,
},
};
const images = function (url) {
const dimensions = sizeOf(url);
let oldWidth = dimensions.width / 2;
let oldHeight = dimensions.height / 2;
let width = 0, height = 0;
//设置最大width为600
if (oldWidth > 600) {
width = 600;
height = 600 * oldHeight / oldWidth;
} else {
width = oldWidth;
height = oldHeight;
}
return {
type: "image",
path: url,
opt: {
cx: width,
cy: height
}
}
};
const tableStyle = function (width) {
return {
tableColWidth: Math.floor(9000 / width),
tableSize: 14,
sz: '20', //字体大小
tableAlign: "left",
borders: true,
borderSize: 1,
};
};
const tableNoWidth = function () {
return {
type: "table",
opt: tableStyleNoWidth(),
};
};
const tableStyleNoWidth = function () {
return {
// tableColWidth: width || 1000,
tableSize: 14,
sz: '20', //字体大小
tableAlign: "left",
borders: true,
borderSize: 1,
};
};
const table = function (width) {
return {
type: "table",
opt: tableStyle(width),
};
};
const tr = {
opts: {
b: true,
color: "000000",
align: "center",
shd: {
fill: "92CDDC",
themeFill: "text1",
},
},
};
/**
* 合并列
* @param {*} spanNum
*/
const gridSpan = function (spanNum) {
return {
opts: {
b: true,
color: "000000",
align: "center",
shd: {
fill: "92CDDC",
themeFill: "text1",
},
gridSpan: spanNum || 0
}
}
}
/**
* 合并行
* @param {*} type: restart||continue
*/
const vMerge = function (type) {
return {
opts: {
b: true,
color: "000000",
align: "center",
shd: {
fill: "92CDDC",
themeFill: "text1",
},
vMerge: type || 'restart '
}
}
}
/**
* 处理合并单元格表格
* @param {*} datas
*/
const handleMergeTable = function (datas, isBody) {
var spanAll = 0;
datas.forEach((column) => {
if (column.gridSpan) {
spanAll += Number(column.gridSpan);
} else {
spanAll += 1
}
})
return datas.map((item) => {
var cellWidth = { cellColWidth: (spanAll && Math.floor(9000 / spanAll * (item.gridSpan || 1))) || 1000 }
if (typeof item.gridSpan != 'undefined') {
var trResult = Object.assign({}, gridSpan(item.gridSpan).opts, cellWidth);
return {
val: item.val,
opts: trResult
}
}
if (typeof item.gridSpan == 'undefined' && typeof item.vMerge == 'undefined') {
var trResult = Object.assign({}, tr.opts, cellWidth);
return {
val: item.val,
opts: trResult
}
}
else if (typeof item.vMerge != 'undefined') {
var trResult = Object.assign({}, vMerge(item.vMerge).opts, cellWidth);
if (typeof item.val != 'undefined') {
return {
val: item.val,
opts: trResult
}
} else {
return {
opts: trResult
}
}
}
})
}
/**
* 构建整体数据集合
* @param {*} sourceData
*/
const bindSourceData = (sourceData, curChartId) => {
if (Array.isArray(sourceData) && sourceData.length === 0) return [];
//从结构数据中获取echarts,获取到echart对应的产品类型+图片名称,进行替换 替换的值:{...image(path.join(`download/`)+'drgs/chart_1221.png')}
let docs = [];
docs.push({ ...h1, val: sourceData.role });
let vte_ais = sourceData.vte_ais; // 标题
if (Array.isArray(vte_ais) && vte_ais.length > 0) {
bindVteAis(vte_ais, docs, curChartId);
}
return docs;
};
/**
* 构建头部标题
* @param {*} vteAis 二级标题及里面的内容
* docs h1一级标题
*/
function bindVteAis(vteAis, docs, curChartId) {
for (let i = 0; i < vteAis.length; i++) {
const vai = vteAis[i];
docs.push({ ...h2, val: vai.title });
let project_items = vai.project_items; // 二级项目内容
if (Array.isArray(project_items) && project_items.length > 0) {
bindProjectItems(project_items, docs, curChartId);
}
}
}
/**
* 构建项目集合
* @param {*} project_items 三级内容
* @param {*} docs 一级和二级标题
*/
function bindProjectItems(project_items, docs, curChartId) {
for (let p = 0; p < project_items.length; p++) {
const pro = project_items[p];
let _proTable = [];
let _proTbableTwo = [];
let _proTbableClass = [];
docs.push({ ...h3, val: pro.title });
docs.push({ ...page, val: getTxtFromHtml(pro.project_unit_text) || '' })
docs.push({ ...page, val: pro.echartsTitle || '' });
if (pro.aimTarget == "role_1_5_1" || pro.aimTarget == "role_1_6_1" || pro.aimTarget == "role_1_6_2") {
for (let i = 0; i < curChartId.length; i++) {
if (pro.echarts.src == curChartId[i].chart_id) {
docs.push({ ...images(path.join(`download/drgs/chart_`) + pro.echarts.src + '.png') });
}
}
}
docs.push({ ...page, val: pro.tableTitle || '' });
if (pro.projectTable) {// projectTable表格对象
let proTable = pro.projectTable;
proTable.list.map((item, index) => {
if (proTable.list[0].length > proTable.list[index].length) {
let num = proTable.list[0].length - proTable.list[index].length
if (num == 1) {
proTable.list[index].unshift({ vMerge: "continue" })
} else if (num == 2) {
proTable.list[index].unshift({ vMerge: "continue" }, { vMerge: "continue" })
}
return proTable.list[index]
}
})
let arr = []
arr = proTable.columns.map(item => {
if (!item.val) {
item = { val: item }
}
return item
})
var cols = [], list = [];
cols = handleMergeTable(arr);
list = proTable.list.map((item) => {
return handleMergeTable(item, true);
})
//合并单元格demo end
_proTable.push(cols);
_proTable.push(...list);
docs.push({
...tableNoWidth(),
val: _proTable,
}); //纸张除去边距后大约宽度
docs.push({ ...spaceBar, val: ' ' });
}
if (pro.aimTarget == "role_1_4_1") {
docs.push({ ...page, val: getTxtFromHtml(pro.project_unit_textTwo) || '' });
docs.push({ ...page, val: pro.proiect_unit_textH3 || '' });
}
if (pro.projectTableTwo) {// projectTableTwo表格对象
let proTableTwo = pro.projectTableTwo
let colspans = proTableTwo.columns;//表头
let titleTwo = proTableTwo.title || '';
let listTwo = proTableTwo.list; // 表格的数据
docs.push({ ...page, val: titleTwo || '' });
let cols = [];
for (let t = 0; t < colspans.length; t++) {
const col = colspans[t];
cols.push({ ...tr, val: col });
}
_proTbableTwo.push(cols);
_proTbableTwo.push(...listTwo);
docs.push({
...table(colspans.length),
val: _proTbableTwo,
}); //纸张除去边距后大约宽度
docs.push({ ...spaceBar, val: ' ' });
}
if (pro.aimTarget == 'role_1_4_1') {
docs.push({ ...page, val: getTxtFromHtml(pro.project_unit_textTherr) || '' });
for (let i = 0; i < curChartId.length; i++) {
if (pro.echarts.src == curChartId[i].chart_id) {
docs.push({ ...images(path.join(`download/drgs/chart_`) + pro.echarts.src + '.png') });
}
}
}
if (pro.clsaaTable) {//clsaaTable表格对象
let clsaaTable = pro.clsaaTable
let title = clsaaTable.title
docs.push({ ...page, val: title || '' });
var cols = [], list = [];
list = clsaaTable.list.map((item) => {
return handleMergeTable(item, true);
})
clsaaTable.columns.push({ val: '' })
cols = handleMergeTable(clsaaTable.columns);
_proTbableClass.push(cols);
_proTbableClass.push(...list);
docs.push({
...tableNoWidth(),
val: _proTbableClass,
}); //纸张除去边距后大约宽度
}
// class_items 四级标题
let class_items = pro.class_items;
if (Array.isArray(class_items) && class_items.length > 0) {
bindClassItems(class_items, docs, curChartId);
}
}
}
/**
* 根据html获取内容文本
*/
function getTxtFromHtml(str) {
!str && (str = '');
if (str && typeof str === 'string') {
str = str.replace(/<br.*?>/g, '\n'); //将换行符替换为字符实体\n
//然后去除其他的html tag
str = str.replace(/<\/?[^>]*>/g, ''); //去除HTML tag
str = str.replace(/  /g, ' '); //去掉 后面必须要很多空格不然空格比较小
str = str.replace(/"/g, '"'); //去掉"
str = str.replace(/'/g, "'"); //去掉'
str = str.replace(/</g, '<'); // 替换大于小于号
str = str.replace(/>/g, '>'); // 替换大于小于号
str = str.replace(/&/g, '&'); // 替换&
}
return str;
}
/**
* 构建类型结合
* @param {*} class_items 三级子菜单(四级)
* @param {*} docs 一级和二级,三级菜单所有内容
*/
function bindClassItems(class_items, docs, curChartId) {
for (let c = 0; c < class_items.length; c++) {
const cl = class_items[c];
docs.push({ ...h4, val: cl.title });
// target_items start 目标对象
let target_items = cl.target_items;
if (Array.isArray(target_items) && target_items.length > 0) {
bindTargetItems(target_items, docs, curChartId);
}
}
}
/**
* 三级子菜单(四级)全部内容
* @param {*} target_items
* @param {*} docs
*/
function bindTargetItems(target_items, docs, curChartId) {
for (let i = 0; i < target_items.length; i++) {
const tar = target_items[i];
docs.push({ ...h5, val: tar.target });
docs.push({ ...page, val: getTxtFromHtml(tar.item_text) });
for (let i = 0; i < curChartId.length; i++) {
if (tar.echart.src == curChartId[i].chart_id) {
docs.push({ ...images(path.join(`download/drgs/chart_`) + curChartId[i].chart_id + '.png') });
}
}
}
}
nodejs加jq来实现下载word文档的更多相关文章
- Java导出freemarker实现下载word文档格式功能
首先呢,先说一下制作freemarker模板步骤, 1. 在WPS上写出所要的下载的word格式当做模板 2. 把模板内不固定的内容(例:从数据库读取的信息)写成123或者好代替的文字标注 3. 把固 ...
- 前端调用后台接口下载word文档的两种方法
1传统的ajax虽然能提交到后台,但是返回的数据被解析成json,html,text等字符串,无法响应浏览器下载.就算使用bob模拟下载,数据量大时也不方便 废话不多说:上代码(此处是Layui监听提 ...
- 下载word文档
来源:http://www.cnblogs.com/damonlan/archive/2012/04/28/2473525.html 作者:浪迹天涯 protected void GridView1_ ...
- JSP实现word文档的上传,在线预览,下载
前两天帮同学实现在线预览word文档中的内容,而且需要提供可以下载的链接!在网上找了好久,都没有什么可行的方法,只得用最笨的方法来实现了.希望得到各位大神的指教.下面我就具体谈谈自己的实现过程,总结一 ...
- Android中使用POI加载与显示word文档
最近打算实现一个功能:在Android中加载显示Word文档,当然这里不是使用外部程序打开.查看一些资料后,打算采用poi实现,确定了以下实现思路: 将ftp中的word文档下载到本地. 调用poi将 ...
- SpringBoot+FreeMarker开发word文档下载,预览
背景: 开发一个根据模版,自动填充用户数据并下载word文档的功能 使用freemarker进行定义模版,然后把数据进行填充. maven依赖: <parent> <groupId& ...
- C# 给word文档添加水印
和PDF一样,在word中,水印也分为图片水印和文本水印,给文档添加图片水印可以使文档变得更为美观,更具有吸引力.文本水印则可以保护文档,提醒别人该文档是受版权保护的,不能随意抄袭.前面我分享了如何给 ...
- 使用PHPWord生成word文档
有时我们需要把网页内容保存为Word文档格式,以供其他人员查看和编辑.PHPWord是一个用纯PHP编写的库,使用PHPWord可以轻松处理word文档内容,生成你想要的word文档. 下载源码 安装 ...
- C#中5步完成word文档打印的方法
在日常工作中,我们可能常常需要打印各种文件资料,比如word文档.对于编程员,应用程序中文档的打印是一项非常重要的功能,也一直是一个非常复杂的工作.特别是提到Web打印,这的确会很棘手.一般如果要想选 ...
- C# 复制一个Word文档的部分或全部内容到另一个Word文档
C# 复制一个Word文档的部分或全部内容到另一个Word文档 我最近喜欢折腾Office软件相关的东西,想把很多Office软件提供的功能用.NET来实现,如果后期能把它用来开发一点我自己的小应用程 ...
随机推荐
- 第七課-Channel Study For HTTP Listener & Web Service Sender Intercommunicates Response Handler
示例说明: 系统A发送XML格式患者信息到Mirth的Source端HTTP Listener,完成患者信息入库逻辑:然后Mirth的Destinations端Web Service Sender调用 ...
- 力扣495(java)-提莫攻击(简单)
题目: 在<英雄联盟>的世界中,有一个叫 "提莫" 的英雄,他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态.现在,给出提莫对艾希的攻击时间序列和提莫攻击的中 ...
- [Mobi] 什么是手机 Root 和 Magisk、Magisk App
手机进行 Root 操作就是让我们能够拥有超级权限,包括被手机厂商所禁止的一些操作. 传统 Root 手段会修改系统文件,因而一些安全性要求较高的 App 会禁止自己在 Root 过的手机上运行. M ...
- [FAQ] Composer, Content-Length mismatch
1. $ composer config repos.packagist composer https://php.cnpkg.org$ composer config cache-files-max ...
- NopCommerce 多数据库方案
本文转自:http://www.cnblogs.com/YUTOUYUWEI/p/5538200.html 有时候一个项目需要连接多个数据库,以实现不同数据库的数据在同个项目的共享. 如果已经安装了n ...
- 记录一次fs通话无声的问题
概述 freeswitch是一款简单好用的VOIP开源软交换平台. fs的实际应用中,由于网络.配置等问题,经常会产生通话无声的问题. 环境 CentOS 7.9 freeswitch 1.10.7 ...
- 【Python基础】两个参数的for循环步长写法
一个参数for循环步长写法 >>> for i in range(1,10000,1000):print(i) ... 1 1001 2001 3001 4001 5001 6001 ...
- go-zero goctl命令图解
- 02 Xpath Helper介绍
目录 参考文档 下载地址 安装 使用 参考文档 xpath helper https://www.cnblogs.com/ChevisZhang/p/12869582.html http://c.bi ...
- jeecgboot项目swagger2在线接口转word
1.先找到接口文档地址 2.根据url获取接口数据 3.利用在线工具进行转换生成word 在线工具地址:在线swagger转word文档 生成的word文档如下: