预处理共轭梯度算法(Preconditioned Conjugate Gradients Method)的代码实现
前文:
预处理共轭梯度算法(Preconditioned Conjugate Gradients Method)
给出代码:
import numpy as np
# from rllab.misc.ext import sliced_fun
EPS = np.finfo('float64').tiny
def cg(f_Ax, b, cg_iters=10, callback=None, verbose=False, residual_tol=1e-10):
"""
Demmel p 312
"""
p = b.copy()
r = b.copy()
x = np.zeros_like(b)
rdotr = r.dot(r)
fmtstr = "%10i %10.3g %10.3g"
titlestr = "%10s %10s %10s"
if verbose: print(titlestr % ("iter", "residual norm", "soln norm"))
for i in range(cg_iters):
if callback is not None:
callback(x)
if verbose: print(fmtstr % (i, rdotr, np.linalg.norm(x)))
z = f_Ax(p)
v = rdotr / p.dot(z)
x += v * p
r -= v * z
newrdotr = r.dot(r)
mu = newrdotr / rdotr
p = r + mu * p
rdotr = newrdotr
if rdotr < residual_tol:
break
if callback is not None:
callback(x)
if verbose: print(fmtstr % (i + 1, rdotr, np.linalg.norm(x))) # pylint: disable=W0631
return x
def preconditioned_cg(f_Ax, f_Minvx, b, cg_iters=10, callback=None, verbose=False, residual_tol=1e-10):
"""
Demmel p 318
"""
x = np.zeros_like(b)
r = b.copy()
p = f_Minvx(b)
y = p
ydotr = y.dot(r)
fmtstr = "%10i %10.3g %10.3g"
titlestr = "%10s %10s %10s"
if verbose: print(titlestr % ("iter", "residual norm", "soln norm"))
for i in range(cg_iters):
if callback is not None:
callback(x, f_Ax)
if verbose: print(fmtstr % (i, ydotr, np.linalg.norm(x)))
z = f_Ax(p)
v = ydotr / p.dot(z)
x += v * p
r -= v * z
y = f_Minvx(r)
newydotr = y.dot(r)
mu = newydotr / ydotr
p = y + mu * p
ydotr = newydotr
if ydotr < residual_tol:
break
if verbose: print(fmtstr % (cg_iters, ydotr, np.linalg.norm(x)))
return x
def test_cg():
A = np.random.randn(5, 5)
A = A.T.dot(A)
b = np.random.randn(5)
x = cg(lambda x: A.dot(x), b, cg_iters=5, verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
x = preconditioned_cg(lambda x: A.dot(x), lambda x: np.linalg.solve(A, x), b, cg_iters=5,
verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
x = preconditioned_cg(lambda x: A.dot(x), lambda x: x / np.diag(A), b, cg_iters=5,
verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
def lanczos(f_Ax, b, k):
"""
Runs Lanczos algorithm to generate a orthogonal basis for the Krylov subspace
b, Ab, A^2b, ...
as well as the upper hessenberg matrix T = Q^T A Q
from Demmel ch 6
"""
assert k > 1
alphas = []
betas = []
qs = []
q = b / np.linalg.norm(b)
beta = 0
qm = np.zeros_like(b)
for j in range(k):
qs.append(q)
z = f_Ax(q)
alpha = q.dot(z)
alphas.append(alpha)
z -= alpha * q + beta * qm
beta = np.linalg.norm(z)
betas.append(beta)
print("beta", beta)
if beta < 1e-9:
print("lanczos: early after %i/%i dimensions" % (j + 1, k))
break
else:
qm = q
q = z / beta
return np.array(qs, 'float64').T, np.array(alphas, 'float64'), np.array(betas[:-1], 'float64')
def lanczos2(f_Ax, b, k, residual_thresh=1e-9):
"""
Runs Lanczos algorithm to generate a orthogonal basis for the Krylov subspace
b, Ab, A^2b, ...
as well as the upper hessenberg matrix T = Q^T A Q
from Demmel ch 6
"""
b = b.astype('float64')
assert k > 1
H = np.zeros((k, k))
qs = []
q = b / np.linalg.norm(b)
beta = 0
for j in range(k):
qs.append(q)
z = f_Ax(q.astype('float64')).astype('float64')
for (i, q) in enumerate(qs):
H[j, i] = H[i, j] = h = q.dot(z)
z -= h * q
beta = np.linalg.norm(z)
if beta < residual_thresh:
print("lanczos2: stopping early after %i/%i dimensions residual %f < %f" % (j + 1, k, beta, residual_thresh))
break
else:
q = z / beta
return np.array(qs).T, H[:len(qs), :len(qs)]
def make_tridiagonal(alphas, betas):
assert len(alphas) == len(betas) + 1
N = alphas.size
out = np.zeros((N, N), 'float64')
out.flat[0:N ** 2:N + 1] = alphas
out.flat[1:N ** 2 - N:N + 1] = betas
out.flat[N:N ** 2 - 1:N + 1] = betas
return out
def tridiagonal_eigenvalues(alphas, betas):
T = make_tridiagonal(alphas, betas)
return np.linalg.eigvalsh(T)
def test_lanczos():
np.set_printoptions(precision=4)
A = np.random.randn(5, 5)
A = A.T.dot(A)
b = np.random.randn(5)
f_Ax = lambda x: A.dot(x) # pylint: disable=W0108
Q, alphas, betas = lanczos(f_Ax, b, 10)
H = make_tridiagonal(alphas, betas)
assert np.allclose(Q.T.dot(A).dot(Q), H)
assert np.allclose(Q.dot(H).dot(Q.T), A)
assert np.allclose(np.linalg.eigvalsh(H), np.linalg.eigvalsh(A))
Q, H1 = lanczos2(f_Ax, b, 10)
assert np.allclose(H, H1, atol=1e-6)
print("ritz eigvals:")
for i in range(1, 6):
Qi = Q[:, :i]
Hi = Qi.T.dot(A).dot(Qi)
print(np.linalg.eigvalsh(Hi)[::-1])
print("true eigvals:")
print(np.linalg.eigvalsh(A)[::-1])
print("lanczos on ill-conditioned problem")
A = np.diag(10 ** np.arange(5))
Q, H1 = lanczos2(f_Ax, b, 10)
print(np.linalg.eigvalsh(H1))
print("lanczos on ill-conditioned problem with noise")
def f_Ax_noisy(x):
return A.dot(x) + np.random.randn(x.size) * 1e-3
Q, H1 = lanczos2(f_Ax_noisy, b, 10)
print(np.linalg.eigvalsh(H1))
if __name__ == "__main__":
test_lanczos()
test_cg()
上面的cg函数是共轭梯度法,preconditioned_cg函数是预处理共轭梯度法。
可以看到,预处理的共轭梯度法和共轭梯度法是比较相似的,下面给出不同的地方:
共轭梯度法:
newrdotr = r.dot(r)
mu = newrdotr / rdotr
p = r + mu * p
rdotr = newrdotr
预处理共轭梯度法:
y = f_Minvx(r)
newydotr = y.dot(r)
mu = newydotr / ydotr
p = y + mu * p
ydotr = newydotr
上面的代码中给出的对预处理共轭梯度法的两次调用:
x = preconditioned_cg(lambda x: A.dot(x), lambda x: np.linalg.solve(A, x), b, cg_iters=5,
verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
x = preconditioned_cg(lambda x: A.dot(x), lambda x: x / np.diag(A), b, cg_iters=5,
verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
运行结果:
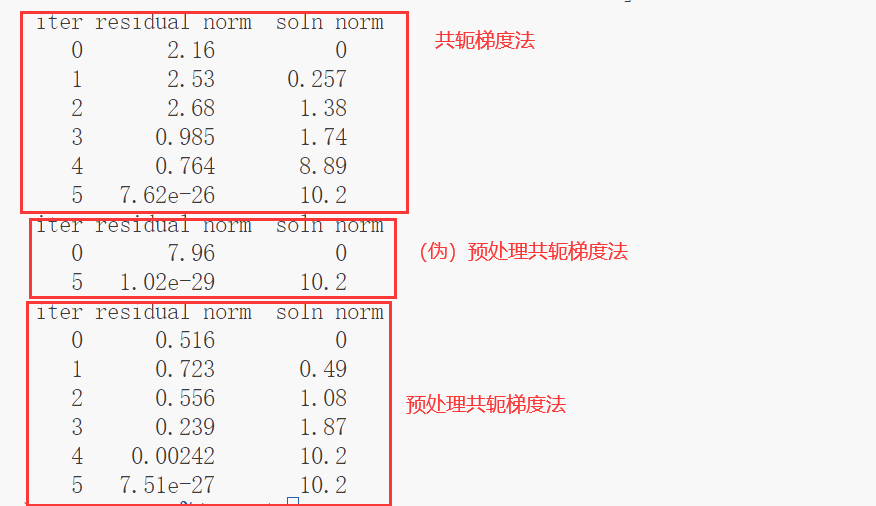
之所以说第一个预处理共轭梯度法是一个伪的呢,是因为其预处理依旧是使用求解A矩阵的解,因此并不具备实际意义和价值。
下图来自:预处理共轭梯度法(2)

可以看到上面代码中的预处理共轭梯度法其实就是使用Jacobi方法的,主要体现:
lambda x: x / np.diag(A)
由于预处理共轭梯度法比共轭梯度法的优势在于对稀疏的系数矩阵且系数矩阵的条件数(最大最小特征值之比)很大的情况,因此上面的Jacobi方法的预处理共轭梯度法并没有明显的优势。
预处理共轭梯度算法(Preconditioned Conjugate Gradients Method)的代码实现的更多相关文章
- 机器学习: 共轭梯度算法(PCG)
今天介绍数值计算和优化方法中非常有效的一种数值解法,共轭梯度法.我们知道,在解大型线性方程组的时候,很少会有一步到位的精确解析解,一般都需要通过迭代来进行逼近,而 PCG 就是这样一种迭代逼近算法. ...
- 共轭梯度算法求最小值-scipy
# coding=utf-8 #共轭梯度算法求最小值 import numpy as np from scipy import optimize def f(x, *args): u, v = x a ...
- Mahout 系列之----共轭梯度
无预处理共轭梯度 要求解线性方程组 ,稳定双共轭梯度法从初始解 开始按以下步骤迭代: 任意选择向量 使得 ,例如, 对 若 足够精确则退出 预处理共轭梯度 预处理通常被用来加速迭代方法的收敛.要使用预 ...
- 3. OpenCV-Python——图像梯度算法、边缘检测、图像金字塔与轮廓检测、直方图与傅里叶变换
一.图像梯度算法 1.图像梯度-Sobel算子 dst = cv2.Sobel(src, ddepth, dx, dy, ksize) ddepth:图像的深度 dx和dy分别表示水平和竖直方向 ks ...
- 近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数.求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的. 考虑一个这样的问题: minx f(x)+λg(x) x ...
- 临近梯度下降算法(Proximal Gradient Method)的推导以及优势
邻近梯度下降法 对于无约束凸优化问题,当目标函数可微时,可以采用梯度下降法求解:当目标函数不可微时,可以采用次梯度下降法求解:当目标函数中同时包含可微项与不可微项时,常采用邻近梯度下降法求解.上述三种 ...
- C++算法之大数加法计算的代码
如下代码段是关于C++算法之大数加法计算的代码,希望对大家有用. { int length; int index; int smaller; int prefix = 0; if(NULL == sr ...
- 基本算法思想Java实现的详细代码
基本算法思想Java实现的详细代码 算法是一个程序的灵魂,一个好的算法往往可以化繁为简,高效的求解问题.在程序设计中算法是独立于语言的,无论使用哪一种语言都可以使用这些算法,本文笔者将以Java语言为 ...
- 【优化算法】Greedy Randomized Adaptive Search算法 超详细解析,附代码实现TSP问题求解
01 概述 Greedy Randomized Adaptive Search,贪婪随机自适应搜索(GRAS),是组合优化问题中的多起点元启发式算法,在算法的每次迭代中,主要由两个阶段组成:构造(co ...
- 《算法导论》第二章demo代码实现(Java版)
<算法导论>第二章demo代码实现(Java版) 前言 表示晚上心里有些不宁静,所以就写一篇博客,来缓缓.囧 拜读<算法导论>这样的神作,当然要做一些练习啦.除了练习题与思考题 ...
随机推荐
- invalid comparison: java.util.ArrayList and java.lang.String 异常分析及解决方法
nvalid comparison: java.util.ArrayList and java.lang.String 异常解决方法异常原因首先我们可以确定是在mybatis的xml中的 list 操 ...
- 超越datetime:Arrow,Python中的日期时间管理大师
介绍 Arrow是一个Python库,它提供了一种合理且对人类友好的方法来创建.操作.格式化和转换日期.时间和时间戳.它实现了对datetime类型的更新,填补了功能上的空白,提供了一个智能的模块AP ...
- echo输出带颜色的字
文章目录 格式 所有颜色 字体样式 示例 格式 \033[A;F;Bm #放在文本的左边,可以影响后面所有字体的样式 解释: F代表字体颜色值(Font),颜色编号30~37. B代表背景颜色值(Ba ...
- idea远程debug(物理机、docker、k8s)
IDEA远程DEBUG 1:物理机部署的Springboot项目远程DEBUG 1.1:idea配置 点击"Edit Configurations",再点击+,选择Remote, ...
- I2S 总线学习:1-有关概念
背景 I2S总线 是一种常见的总线,也是需要掌握的. 概念 I2S(Inter-IC Sound)总线, 又称 集成电路内置音频总线,是飞利浦公司为数字音频设备之间的音频数据传输而制定的一种总线标准, ...
- 使用explain优化慢查询的业务场景分析
问:你最害怕的事情是什么? 答:搓澡 问:为什么? 答:因为有些人一旦错过,就不在了 Explain 这个词在不同的上下文中有不同的含义.在数据库查询优化的上下文中,"EXPLAIN&quo ...
- [UG 二次开发 python ] 截图,并用 opencv 显示出来
需要 numpy,cv2 截图,去除背景,只显示主要部分 # nx: threaded from typing import Dict import NXOpen import numpy as np ...
- 如何让其他模型也能在SemanticKernel中调用本地函数
在SemanticKernel的入门例子中: // Import packages using Microsoft.SemanticKernel; using Microsoft.SemanticKe ...
- SMU Summer 2024 Contest Round 1(7.8)zhaosang
A-A http://162.14.124.219/contest/1005/problem/A 一道数学问题,求概率. 要求成功的概率,有两个色子, 一个用来抛正反面,一个用来控制得分大小,当超过某 ...
- vue项目读取文件问题
问题:在src\assets资源目录存放非图片文件无法获取. 解决:将非图片文件存放到public上,读取的时候路径不带public. 例如:资源的相对路径为:public/roboto/1Kg.wo ...