KubeDL 0.4.0 - Kubernetes AI 模型版本管理与追踪
简介:欢迎更多的用户试用 KubeDL,并向我们提出宝贵的意见,也期待有更多的开发者关注以及参与 KubeDL 社区的建设!
作者:陈裘凯( 求索)
前言
KubeDL 是阿里开源的基于 Kubernetes 的 AI 工作负载管理框架,取自"Kubernetes-Deep-Learning"的缩写,希望能够依托阿里巴巴的场景,将大规模机器学习作业调度与管理的经验反哺社区。目前 KubeDL 已经进入 CNCF Sandbox 项目孵化,我们会不断探索云原生 AI 场景中的最佳实践,助力算法科学家们简单高效地实现创新落地。
在最新的 KubeDL Release 0.4.0 版本中,我们带来了模型版本管理(ModelVersion)的能力,AI 科学家们可以像管理镜像一样轻松地对模型版本进行追踪,打标及存储。更重要的是,在经典的机器学习流水线中,“训练”与“推理”两个阶段相对独立,算法科学家视角中的“训练->模型->推理”流水线缺乏断层,而“模型”作为两者的中间产物正好能够充当那个“承前启后”的角色。
模型管理现状
模型文件是分布式训练的产物,是经过充分迭代与搜索后保留的算法精华,在工业界算法模型已经成为了宝贵的数字资产。通常不同的分布式框架会输出不同格式的模型文件,如 Tensorflow 训练作业通常输出 CheckPoint(*.ckpt)、GraphDef(*.pb)、SavedModel 等格式,而 PyTorch 则通常以 .pth 后缀,不同的框架会在加载模型时解析其中承载的运行时的数据流图、运行参数及其权重等信息,对于文件系统来说,它们都是一个(或一组)特殊格式的文件,就像 JPEG 和 PNG 格式的图像文件一样。
因此典型的管理方式就是把它们当作文件,托管在统一的对象存储中(如阿里云 OSS 和AWS S3),每个租户/团队分配一个目录,各自成员再把模型文件存储在自己对应的子目录中,由 SRE 来统一进行读写权限的管控:
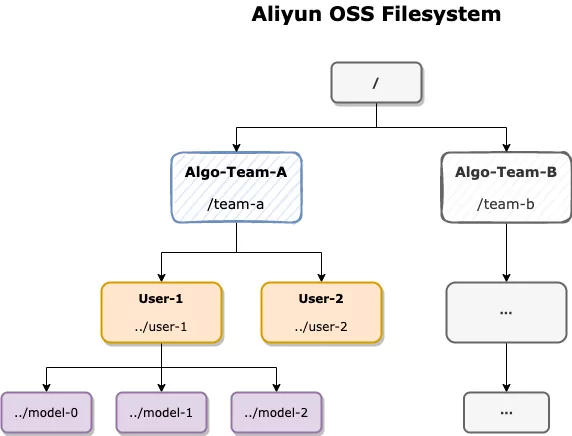
这种管理方式的优缺点都很明显:
- 好处是保留了用户的 API 使用习惯,在训练代码中将自己的目录指定为输出路径,之后将云存储的对应目录 mount 到推理服务的容器内加载模型即可;
- 但这对 SRE 提出了较高的要求,不合理的读写权限授权及误操作,可能造成文件权限泄露,甚至大面积的误删除;同时基于文件的管理方式不易实现模型的版本管理,通常要求用户自身根据文件名来标记,或是上层平台自己承担版本管理的复杂度;此外,模型文件与算法代码/训练参数的对应关系也无法直接映射,甚至同个文件在多次训练中会被多次覆写,难以追溯历史;
基于以上现状,KubeDL 充分结合了 Docker 镜像管理的优势,引入了一套 Image-Based 的镜像管理 API,让分布式训练和推理服务结合得更紧密自然,同时也极大简化了模型管理的复杂度。
从镜像出发
镜像(Image)是 Docker 的灵魂,也是容器时代的核心基础设施。镜像本身即分层的不可变文件系统,模型文件天然地可以作为其中的一个独立镜像层,两者结合的还会迸发出其他火花:
- 用户不用再面向文件管理模型,而是直接使用 KubeDL 提供的 ModelVersion API 即可,训练与推理服务之间通过 ModelVersion API 桥接;
- 与镜像一样,可以对模型打 Tag 实现版本追溯,并推送到统一的镜像 Registry 存储,通过 Registry 进行鉴权,同时镜像 Registry 的存储后端还可以替换成用户自己的 OSS/S3,用户可以平滑过渡;
- 模型镜像一旦构建完毕,即成为只读的模板,无法再被覆盖及篡写,践行 Serverless “不可变基础设施” 的理念;
- 镜像层(Layer)通过压缩算法及哈希去重,减少模型文件存储的成本并加快了分发的效率;
在“模型镜像化”的基础上,还可以充分结合开源的镜像管理组件,最大化镜像带来的优势:
- 大规模的推理服务扩容场景中,可以通过 Dragonfly 来加速镜像分发效率,面对流量突发型场景时可以快速弹出无状态的推理服务实例,同时避免了挂载云存储卷可能出现的大规模实例并发读时的限流问题;
- 日常的推理服务部署,也可以通过 OpenKruise 中的 ImagePullJob 来提前对节点上的模型镜像进行预热,提升扩容发布的效率。
Model 与 ModelVersion
KubeDL 模型管理引入了 2 个资源对象:Model 及 ModelVersion,Model 代表某个具体的模型,ModelVersion 则表示该模型迭代过程中的一个具体版本,一组 ModelVersion 从同一个 Model 派生而来。以下是示例:
apiVersion: model.kubedl.io/v1alpha1
kind: ModelVersion
metadata:
name: my-mv
namespace: default
spec:
# The model name for the model version
modelName: model1
# The entity (user or training job) that creates the model
createdBy: user1
# The image repo to push the generated model
imageRepo: modelhub/resnet
imageTag: v0.1
# The storage will be mounted at /kubedl-model inside the training container.
# Therefore, the training code should export the model at /kubedl-model path.
storage:
# The local storage to store the model
localStorage:
# The local host path to export the model
path: /foo
# The node where the chief worker run to export the model
nodeName: kind-control-plane
# The remote NAS to store the model
nfs:
# The NFS server address
server: ***.cn-beijing.nas.aliyuncs.com
# The path under which the model is stored
path: /foo
# The mounted path inside the container
mountPath: /kubedl/models ---
apiVersion: model.kubedl.io/v1alpha1
kind: Model
metadata:
name: model1
spec:
description: "this is my model"
status:
latestVersion:
imageName: modelhub/resnet:v1c072
modelVersion: mv-3
Model 资源本身只对应某类模型的描述,并追踪最新的版本的模型及其镜像名告知给用户,用户主要通过 ModelVersion 来自定义模型的配置:
- modelName:用来指向对应的模型名称;
- createBy:创建该 ModelVersion 的实体,用来追溯上游的生产者,通常是一个分布式训练作业;
- imageRepo:镜像 Registry 的地址,构建完成模型镜像后将镜像推送到该地址;
- storage:模型文件的存储载体,当前我们支持了 NAS,AWSEfs 和 LocalStorage 三种存储介质,未来会支持更多主流的存储方式。以上的例子中展示了两种模型输出的方式(本地存储卷和 NAS 存储卷),一般只允许指定一种存储方式。
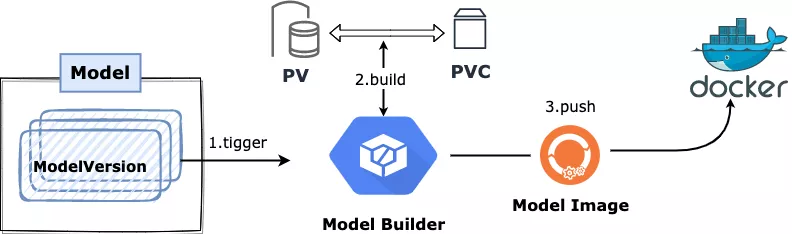

当 KubeDL 监听到 ModelVersion 的创建时,便会触发模型构建的工作流:
- 监听 ModelVersion 事件,发起一次模型构建;
- 根据 storage 的类型创建出对应的 PV 与 PVC 并等待 volume 就绪;
- 创建出 Model Builder 进行用户态的镜像构建,Model Builder 我们采用了 kaniko 的方案,其构建的过程与镜像格式,和标准的 Docker 完全一致,只不过这一切都在用户态发生,不依赖任何宿主机的 Docker Daemon;
- Builder 会从 volume 的对应路径中拷贝出模型文件(可以是单文件也可以是一个目录),并将其作为独立的镜像层来构建出一个完整的 Model Image;
- 把产出的 Model Image 推送到 ModelVersion 对象中指定的镜像 Registry 仓库;
- 结束整个构建过程;
至此,该 ModelVersion 对应版本的模型便固化在了镜像仓库中,可以分发给后续的推理服务进行消费。
从训练到模型
虽然 ModelVersion 支持独立创建并发起构建,但我们更期望在分布式训练作业成功结束后自动触发模型的构建,天然串联成一个流水线。
KubeDL 支持这种提交方式,以 TFJob 作业为例,在发起分布式训练时即指定好模型文件的输出路径和推送的仓库地址,当作业成功执行完毕时就会自动创建出一个 ModelVersion 对象,并将 createdBy 指向上游的作业名,而当作业执行失败或提前终止时并不会触发 ModelVersion 的创建。
以下是一个分布式 mnist 训练的例子,其将模型文件输出到本地节点的 /models/model-example-v1 路径,当顺利运行结束后即触发模型的构建:
apiVersion: "training.kubedl.io/v1alpha1"
kind: "TFJob"
metadata:
name: "tf-mnist-estimator"
spec:
cleanPodPolicy: None
# modelVersion defines the location where the model is stored.
modelVersion:
modelName: mnist-model-demo
# The dockerhub repo to push the generated image
imageRepo: simoncqk/models
storage:
localStorage:
path: /models/model-example-v1
mountPath: /kubedl-model
nodeName: kind-control-plane
tfReplicaSpecs:
Worker:
replicas: 3
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubedl/tf-mnist-estimator-api:v0.1
imagePullPolicy: Always
command:
- "python"
- "/keras_model_to_estimator.py"
- "/tmp/tfkeras_example/" # model checkpoint dir
- "/kubedl-model" # export dir for the saved_model format
% kubectl get tfjob
NAME STATE AGE MAX-LIFETIME MODEL-VERSION
tf-mnist-estimator Succeeded 10min mnist-model-demo-e7d65
% kubectl get modelversion
NAME MODEL IMAGE CREATED-BY FINISH-TIME
mnist-model-demo-e7d65 tf-mnist-model-example simoncqk/models:v19a00 tf-mnist-estimator 2021-09-19T15:20:42Z
% kubectl get po
NAME READY STATUS RESTARTS AGE
image-build-tf-mnist-estimator-v19a00 0/1 Completed 0 9min
通过这种机制,还可以将其他“仅当作业执行成功才会输出的 Artifacts 文件”一起固化到镜像中,并在后续的阶段中使用。
从模型到推理
有了前面的基础,在部署推理服务时直接引用已构建好的 ModelVersion,便能加载对应模型并直接对外提供推理服务。至此,算法模型生命周期(代码->训练->模型->部署上线)各阶段通过模型相关的 API 联结了起来。
通过 KubeDL 提供的 Inference 资源对象部署一个推理服务时,只需在某个 predictor 模板中填充对应的 ModelVersion 名,Inference Controller 在创建 predictor 时会注入一个 Model Loader,它会拉取承载了模型文件的镜像到本地,并通过容器间共享 Volume 的方式把模型文件挂载到主容器中,实现模型的加载。如上文所述,与 OpenKruise 的 ImagePullJob 相结合我们能很方便地实现模型镜像预热,来为模型的加载提速。为了用户感知的一致性,推理服务的模型挂载路径与分布式训练作业的模型输出路径默认是一致的。
apiVersion: serving.kubedl.io/v1alpha1
kind: Inference
metadata:
name: hello-inference
spec:
framework: TFServing
predictors:
- name: model-predictor
# model built in previous stage.
modelVersion: mnist-model-demo-abcde
replicas: 3
batching:
batchSize: 32
template:
spec:
containers:
- name: tensorflow
args:
- --port=9000
- --rest_api_port=8500
- --model_name=mnist
- --model_base_path=/kubedl-model/
command:
- /usr/bin/tensorflow_model_server
image: tensorflow/serving:1.11.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9000
- containerPort: 8500
resources:
limits:
cpu: 2048m
memory: 2Gi
requests:
cpu: 1024m
memory: 1Gi
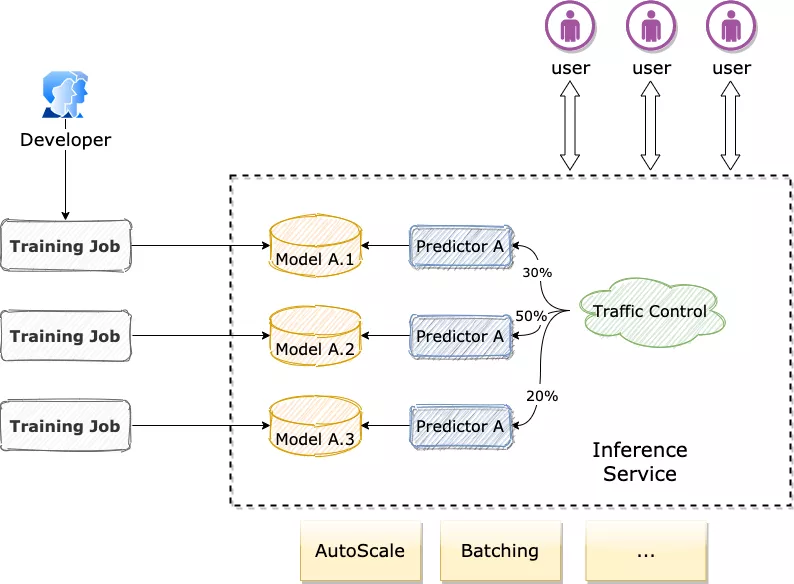
对于一个完整的推理服务,可能同时 Serve 多个不同模型版本的 predictor,比如在常见搜索推荐的场景中,期望以 A/B Testing 实验来同时对比多次模型迭代的效果,通过 Inference+ModelVersion 可以很容易做到。我们对不同的 predictor 引用不同版本的模型,并分配合理权重的流量,即可达到一个推理服务下同时 Serve 不同版本的模型并灰度比较效果的目的:
apiVersion: serving.kubedl.io/v1alpha1
kind: Inference
metadata:
name: hello-inference-multi-versions
spec:
framework: TFServing
predictors:
- name: model-a-predictor-1
modelVersion: model-a-version1
replicas: 3
trafficWeight: 30 # 30% traffic will be routed to this predictor.
batching:
batchSize: 32
template:
spec:
containers:
- name: tensorflow
// ...
- name: model-a-predictor-2
modelVersion: model-version2
replicas: 3
trafficWeight: 50 # 50% traffic will be roted to this predictor.
batching:
batchSize: 32
template:
spec:
containers:
- name: tensorflow
// ...
- name: model-a-predictor-3
modelVersion: model-version3
replicas: 3
trafficWeight: 20 # 20% traffic will be roted to this predictor.
batching:
batchSize: 32
template:
spec:
containers:
- name: tensorflow
// ...

总结
KubeDL 通过引入 Model 和 ModelVersion 两种资源对象,与标准的容器镜像相结合实现了模型构建,打标与版本追溯,不可变存储与分发等功能,解放了粗放型的模型文件管理模式,镜像化还可以与其他优秀的开源社区相结合,实现镜像分发加速,模型镜像预热等功能,提升模型部署的效率。同时,模型管理 API 的引入很好地连接了分布式训练与推理服务两个原本割裂的阶段,显著提升了机器学习流水线的自动化程度,以及算法科学家上线模型、实验对比的体验和效率。
原文链接
本文为阿里云原创内容,未经允许不得转载。
KubeDL 0.4.0 - Kubernetes AI 模型版本管理与追踪的更多相关文章
- CANN5.0黑科技解密 | 别眨眼!缩小隧道,让你的AI模型“身轻如燕”!
摘要:CANN作为释放昇腾硬件算力的关键平台,通过深耕先进的模型压缩技术,聚力打造AMCT模型压缩工具,在保证模型精度前提下,不遗余力地降低模型的存储空间和计算量. 随着深度学习的发展,推理模型巨大的 ...
- 带你从0到1开发AI图像分类应用
摘要:通过一个垃圾分类应用的开发示例,介绍AI Gallery在AI应用开发流程中的作用. 本文分享自华为云社区<AI Gallery:从0到1开发AI图像分类应用>,作者: yd_269 ...
- TensorFlow2.0(12):模型保存与序列化
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60分钟入门 PyTorch入门 PyTorch自动微分 PyTorch神经网络 P ...
- Newbe.ObjectVisitor 0.4.4 发布,模型验证器上线
Newbe.Claptrap 0.4.4 发布,模型验证器上线. 更新内容 完全基于表达式树的模型验证器 本版本,我们带来了基于表达式树实现的模型验证器.并实现了很多内置的验证方法. 我们罗列了与 F ...
- 支持 gRPC 长链接,深度解读 Nacos 2.0 架构设计及新模型
支持 gRPC 长链接,深度解读 Nacos 2.0 架构设计及新模型 原创 杨翊(席翁) 阿里巴巴云原生 2020-12-28
- 微调torchvision 0.3的目标检测模型
微调torchvision 0.3的目标检测模型 本文将微调在 Penn-Fudan 数据库中对行人检测和分割的已预先训练的 Mask R-CNN 模型.它包含170个图像和345个行人实例,说明如何 ...
- 从0到1搭建AI中台
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 转自 | 宜信技术学院 作者 | 井玉欣 导读:随着“数据中台”的提出和成功实践,各企业纷纷在“大中台 ...
- 支持边云协同终身学习特性,KubeEdge子项目Sedna 0.3.0版本发布!
摘要:随着边缘设备数量指数级增长以及设备性能的提升,边云协同机器学习应运而生,以期打通机器学习的最后一公里. 本文分享自华为云社区<支持边云协同终身学习特性,KubeEdge子项目Sedna 0 ...
- 如何借助 JuiceFS 为 AI 模型训练提速 7 倍
背景 海量且优质的数据集是一个好的 AI 模型的基石之一,如何存储.管理这些数据集,以及在模型训练时提升 I/O 效率一直都是 AI 平台工程师和算法科学家特别关注的事情.不论是单机训练还是分布式训练 ...
随机推荐
- vim的使用进步
vim的使用进步 1.如果遇到命令行中无法退出的 狂按esc按键 或者也可以使用v模式下切换一下,之后按esc 保存退出 保存退出--:wq 保存:w 不保存退出:q! i--插入模式 v- 可视化模 ...
- 使用JMeter从JSON响应的URL参数中提取特定值
在使用Apache JMeter进行API测试时,我们经常需要从JSON格式的响应中提取特定字段的值.这可以通过使用JMeter内置的JSON提取器和正则表达式提取器来完成.以下是一个具体的例子,展示 ...
- 一些 AppKit 的坑
NSTextField 在 NSTableView 中需要先点一次再点一次才能编辑.且 hover 时鼠标指针不变化 在 storyboard 里,将 NSTableView 的 Highlight ...
- Oracle 字符串拆分成一个一个字符
SELECT (REGEXP_SUBSTR('LW112190', '[A-Z0-9]', 1, ROWNUM)) test FROM DUAL CONNECT BY ROWNUM <= LEN ...
- 如何使用文件传输协议ftp,教你使用文件传输协议命令行
FTP是文件传输协议的缩写.顾名思义,FTP用于在网络上的计算机之间传输文件.您可以使用文件传输协议在计算机帐户之间交换文件,在帐户和台式计算机之间传输文件或访问在线软件档案.但是请记住,许多文件传输 ...
- verilog之random
verilog之random 1.基本作用 random,用于产生随机数.在测试时,有时需要测试的情况太多,无法一一列举,就需要使用抽样测试的方法验证功能是否可行.random是一个有返回值的系统函数 ...
- Minlexes题解
\(\texttt{Problem Link}\) 简要题意 在一个字符串 \(s\) 中,对于每个后缀,任意删掉一些相邻的相同的字符,使得字符串字典序最小. 注意:删掉之后拼起来再出现的相邻相同字符 ...
- #Pollard-Rho,高精度#洛谷 3499 [POI2010]NAJ-Divine Divisor
题目 给定\(m\)个数\(a_i\),令\(n=\prod_{i=1}^m a_i\), 问有多少个大于1的正整数\(d\)满足\(d^{\max k}|n\) 并输出\(\max k\),\(m\ ...
- 使用 Debian、Docker 和 Nginx 部署 Web 应用
前言 本文将介绍基于 Debian 的系统上使用 Docker 和 Nginx 进行 Web 应用部署的过程.着重介绍了 Debian.Docker 和 Nginx 的安装和配置. 第 1 步:更新和 ...
- OpenHarmony Meetup常州站招募令
OpenHarmony Meetup 常州站正火热招募中! 诚邀充满激情的开发者参与线下盛会~ 探索OpenHarmony前沿科技,畅谈未来前景, 感受OpenHarmony生态构建之路的魅力! 线下 ...