【pytorch】ResNet源码解读和基于迁移学习的实战
“工欲善其事,必先利其器”,掌握ResNet网络有必要先了解其原理和源码。本文分别从原理、源码、运用三个方面出发行文,先对ResNet原理进行阐述,然后对pytorch中的源码进行详细解读,最后再基于迁移学习对模型进行调整、实战。本文若有疏漏、需更正、改进的地方,望读者予以指正!!!
笔者的运行设备与软件:CPU (AMD Ryzen 5 4600U) + pytorch (1.13,CPU版) + jupyter;本文所用的资源链接:https://pan.baidu.com/s/1YWZJTbA7BkmbRnBRFU1qdw ;提取码:1212。
1. ResNet网络原理
1.1. 深度网络的退化问题
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果。但是更深的网络其性能一定会更好吗?实验发现,深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度度出现饱和,甚至下降。这个现象可以在图1中直观看出来:56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练,但是现在已经存在一些技术手段如BatchNorm(简称BN)来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。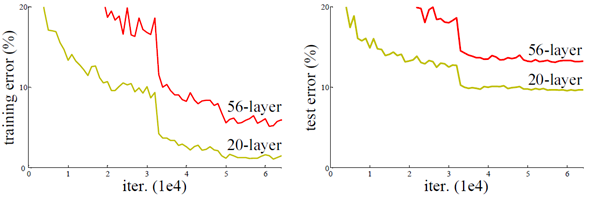
1.2. 残差学习
深度网络的退化问题说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。好吧,你不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为 x 时其学习到的特征记为 H(x) ,现在我们希望其可以学习到残差 F(x)=H(x)−x ,这样其实原始的学习特征是 F(x)+x 。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图2所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。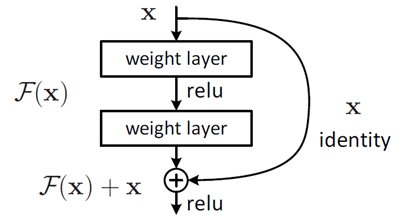
1.3. ResNet的网络结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图3所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图3中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图3展示的是34-layer的ResNet,当然,还可以构建更深的网络如图4所示。从图4中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。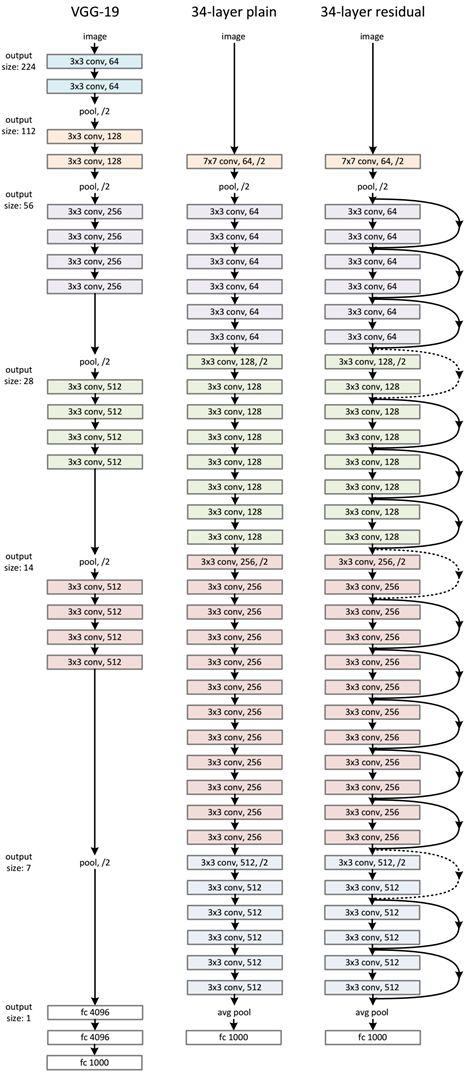
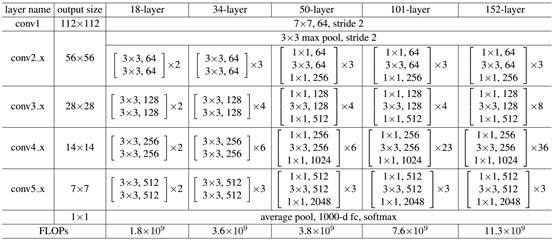
下面我们再分析一下残差单元,ResNet使用两种残差单元BasicBlock(图5左图)和Bottleneck(图5右图),BasicBlock对应的是浅层网络,而Bottleneck对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略可以解决 :(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。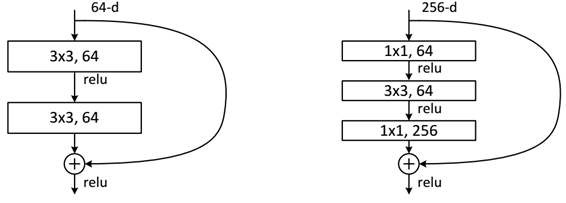
2. pytorch中的resnet源码解读
在阅读pytorch中的源码时,可以参考下图右三中的网络示意,这有助于理解。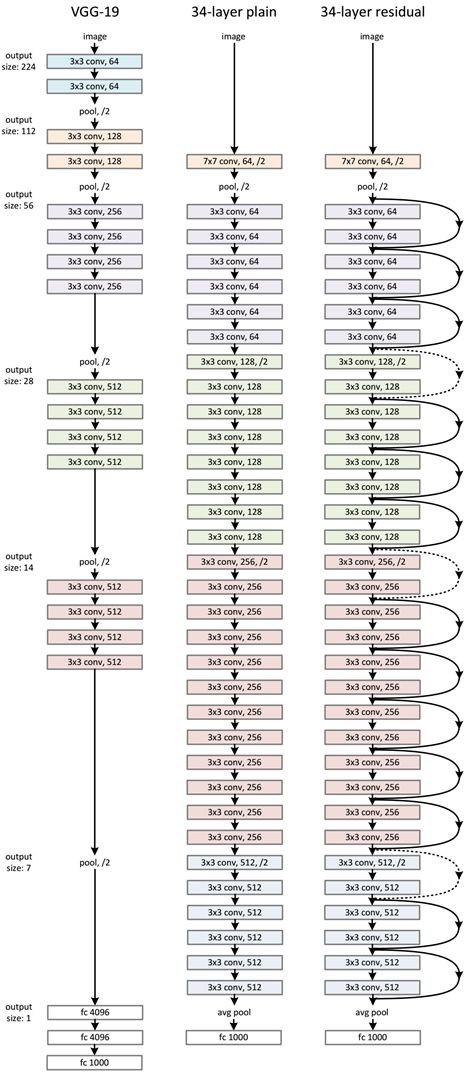
2.1. resnet模块中的类和函数
首先来看一下我们可以从resnet模块中导入哪些类和函数,from torchvision.models.resnet import *导入的类和函数:
__all__ = [
"ResNet",
"ResNet18_Weights",
"ResNet34_Weights",
"ResNet50_Weights",
"ResNet101_Weights",
"ResNet152_Weights",
"ResNeXt50_32X4D_Weights",
"ResNeXt101_32X8D_Weights",
"ResNeXt101_64X4D_Weights",
"Wide_ResNet50_2_Weights",
"Wide_ResNet101_2_Weights",
"resnet18",
"resnet34",
"resnet50",
"resnet101",
"resnet152",
"resnext50_32x4d",
"resnext101_32x8d",
"resnext101_64x4d",
"wide_resnet50_2",
"wide_resnet101_2",
]
2.2. 残差块的构建
残差块是resnet的构建单元。根据深度的不同有两种残差块,分别是BasicBlock(resnet18和resnet34中的残差块)和Bottleneck(resnet50、resnet101和resnet152中的残差块)。两种残差块的的构成如下图所示,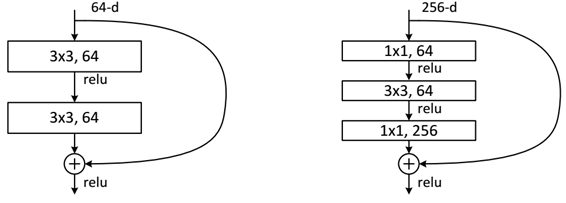
可知,需要1x1,3x3两种卷积层构建,这两种卷积的定义如下。
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 卷积与填充"""
return nn.Conv2d(
in_planes, # 输入通道(特征图)数
out_planes, # 输出通道(特征图)数
kernel_size=3, # 卷积核尺寸
stride=stride, # 卷积时的步长
padding=dilation, # 边缘填充层大小,卷积核为3x3,故padding应为1
groups=groups,
bias=False, # 是否采用偏置值
dilation=dilation,
)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
从上图以及残差学习原理可知,BasicBlock的构建除却卷积层外还需标准化层、激活函数、恒等映射函数,部分BasicBlock还需要下采样层用以减少特征图数量。因此,BasicBlock类的定义如下。
class BasicBlock(nn.Module):
expansion: int = 1 # expansion属性
def __init__( # 初始化
self,
inplanes: int, # 输入通道(特征图)数
planes: int, # 输出通道(特征图)数
stride: int = 1, # 卷积时的步长,默认为1
downsample: Optional[nn.Module] = None, # 下采样,可选
groups: int = 1, # 分组卷积个数,默认为1,即默认采用普通卷积
base_width: int = 64, # 基通道数,常规resnet不用管,wide resnet就是调整这个参数
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None, # 卷积后数据标准化,可选
) -> None:
super().__init__() # 继承nn.Module的初始化
if norm_layer is None: # 如果不指定数据标准化方式,默认使用nn.BatchNorm2d
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64: # 采用BasicBlock残差块的resnet不允许使用分组卷积和wide resnet
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1: # 采用BasicBlock残差块的resnet不允许使用空洞卷积
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride) # 3x3卷积层,若stride=1,特征图数量不做改变;若stride!=1进行下采样
self.bn1 = norm_layer(planes) # 数据标准化
self.relu = nn.ReLU(inplace=True) # ReLU激活函数
self.conv2 = conv3x3(planes, planes) # 3x3卷积层,特征图数量不做改变
self.bn2 = norm_layer(planes) # 数据标准化
self.downsample = downsample # 下采样,用于处理短路相加时维度不同的情况
self.stride = stride # 步长
def forward(self, x: Tensor) -> Tensor: # 前向传播计算
identity = x # 输入张量,(B, C, H, W)
out = self.conv1(x) # 卷积操作
out = self.bn1(out) # 数据标准化操作
out = self.relu(out) # 激活函数操作
out = self.conv2(out) # 卷积操作
out = self.bn2(out) # 数据标准化操作
if self.downsample is not None: # 如果为identity指定了下采样方式则使用该方式,否则做恒等变换
identity = self.downsample(x)
out += identity # 残差块学习到的特征
out = self.relu(out) # 将该特征经激活函数操作
return out # 返回激活后的特征
Bottleneck残差块与BasicBlock的区别在于卷积层的不同,其源码如下。
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion: int = 4 # expansion属性
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation) # 卷积层可实现普通卷积、分组卷积和空洞卷积
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion) # 需要将隐含层的特征图数量扩大4倍
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample # 下采样,用于处理短路相加时维度不同的情况
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
2.3. 构建ResNet网络
ResNet基础块的构建已经了解,现在让我们看一下pytorch中的ResNet网络。ResNet网络构建的要点就是卷积堆积层的构建,这个部分搞懂的话就没什么难点了。
class ResNet(nn.Module):
# 初始化函数
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]], # 选择基础块
layers: List[int], # len(layers)个卷积堆积层分别具有残差块的个数
num_classes: int = 1000, # 类别大小
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None, # 数据标准化
) -> None:
super().__init__()
_log_api_usage_once(self) # 和API有关
if norm_layer is None: # 如果不指定数据标准化方式,默认使用nn.BatchNorm2d
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# replace_stride_with_dilation为None时重新赋值
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
# resnet中共有四个卷积堆积层,其中后三个需要下采样,下采样有池化、普通卷积、空洞卷积
# replace_stride_with_dilation列表的三个bool值决定是否使用空洞卷积替换普通卷积
# 由于空洞卷积计算量大,一般情况下不建议使用
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
# 使用7x7卷积核,缩小图像为原来的1/2
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
# 数据标准化
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
# 最大值池化,继续缩小图像至1/2,实际上这个池化层可以看作是layer1的下采样层
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 卷积堆积层1,
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
# 自适应平均池化层,输出固定尺寸的特征图
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 利用He初始化方法初始化模型中卷积层的权重
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
# init.constant初始化权重
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 对每个残差分支中的最后一个 BN 进行零初始化,使残差分支以零开头,
# 并且每个残差块的行为类似于一个恒等式。这使模型提高了0.2~0.3%
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck) and m.bn3.weight is not None:
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock) and m.bn2.weight is not None:
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
# 定义卷积堆积层函数
def _make_layer(
self,
block: Type[Union[BasicBlock, Bottleneck]],
planes: int,
blocks: int,
stride: int = 1,
dilate: bool = False,
) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
# 若dilate==True,则卷积时的步长变为1;下采样改为空洞采样,且self.dilation *= stride
if dilate:
self.dilation *= stride
stride = 1
# 定义残差块中的下采样器,该采样器仅可能在每个卷积堆积层的第一个残差块中出现
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
# 将第一个残差块添加进layers
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
# 第一个残差块以后的全部的输入特征图数量为planes * block.expansion
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
# 返回一个顺序封装的网络块,即一个卷积堆积层
return nn.Sequential(*layers)
# 定义前向传播计算函数
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 前向传播
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
2.4. 实现不同深度的resnet
ResNet网络构建好后,如何实现不同深度的网络呢?这里我们看看resnet34的源码,其他深度的网络大同小异。实例化模型时最为关键的一点就是权重的初始化,pytorch提供了基于ImageNet训练的权重。我们可以选择加载预训练权重进行初始化或者使用默认定义的初始化。
@register_model()
@handle_legacy_interface(weights=("pretrained", ResNet34_Weights.IMAGENET1K_V1))
def resnet34(*, weights: Optional[ResNet34_Weights] = None, progress: bool = True, **kwargs: Any) -> ResNet:
# 初始化权重,当pretrained==True时使用预训练权重,否则按ResNet类中的定义初始化权重
weights = ResNet34_Weights.verify(weights)
# 返回一个resnet网络模型
return _resnet(BasicBlock, [3, 4, 6, 3], weights, progress, **kwargs)
def _resnet(
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
weights: Optional[WeightsEnum],
progress: bool,
**kwargs: Any,
) -> ResNet:
if weights is not None:
_ovewrite_named_param(kwargs, "num_classes", len(weights.meta["categories"]))
# 实例化resnet网络
model = ResNet(block, layers, **kwargs)
if weights is not None:
# 按传入的参数初始化模型
model.load_state_dict(weights.get_state_dict(progress=progress))
return model
2.5. 解读resnet34的参数
from torchvision.models.resnet import *
net=resnet34(pretrained=True)
for param in net.parameters():
print(param.size())

3. 基于迁移学习得到自己的resnet模型
3.1. 迁移学习概述
迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中。
迁移学习(Transfer learning) 顾名思义就是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。
在CNN中实现迁移学习主要有以下两种常见的方法:
- 微调(Fine-tuning):冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层,因为这些层保留了大量底层信息)或不冻结任何网络层,训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
- 提取特征向量(Extract Feature Vector):冻结除全连接层外的所有网络的权重,最后的全连接层用一个具有随机权重的新层来替换,并且仅训练该层。
以上两种迁移方法应如何选择呢?
| 数据集大小 | 和预训练模型使用数据集的相似度 | 一般选择 |
|---|---|---|
| 小 | 高 | 特征提取 |
| 大 | 高 | 参数微调 |
| 小 | 低 | 特征提取+SVM |
| 大 | 低 | 从头训练或参数微调(推荐) |
3.2. 基于迁移学习得到自己的resnet模型
以下示例中所用数据集的信息如下:
| 种类 | 训练集 | 验证集 |
|---|---|---|
| 猫 | 130 | 100 |
| 狗 | 222 | 102 |
| 蚂蚁 | 123 | 70 |
| 蜜蜂 | 121 | 83 |
| 合计 | 596 | 355 |
参数微调
本文使用预训练的参数来初始化我们的网络模型,修改全连接层后再训练所有层。
# 导入模块
import os
import cv2
import matplotlib.pyplot as plt
import torch
import torchvision
import numpy as np
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import ImageFolder
import torchvision.models as models
import torch.nn as nn
import torch.optim as optim
import time
import copy
from tqdm import tqdm
# 数据集的制作
# train/eval/test数据集目录
root_train="D:\\Users\\CV learning\\pytorch\\data\\cat_dog_ants_bees\\train"
root_eval="D:\\Users\\CV learning\\pytorch\\data\\cat_dog_ants_bees\\eval"
root_test="D:\\Users\\CV learning\\pytorch\\data\\cat_dog_ants_bees\\test"
# 计算数据集的normMean、normStd,结果用于输入transforms.Normalize(mean_train, std_train)
def cal_mean_std(root):
img_h, img_w = 300, 300 # 根据自己数据集适当调整,影响不大
means = [0, 0, 0]
stdevs = [0, 0, 0]
img_list = []
imgs_path = root
imgs_path_list = os.listdir(imgs_path)
num_imgs = 0
for data in imgs_path_list:
data_path = os.path.join(imgs_path, data)
data_list = os.listdir(data_path)
for pic in data_list:
num_imgs += 1
img = cv2.imread(os.path.join(data_path+'\\', pic))
try:
img.shape
except:
print(os.path.join(data_path+'\\', pic))
print("Can not read this image !")
img = img.astype(np.float32) / 255.
for i in range(3):
means[i] += img[:, :, i].mean()
stdevs[i] += img[:, :, i].std()
means.reverse()
stdevs.reverse()
means = np.asarray(means) / num_imgs
stdevs = np.asarray(stdevs) / num_imgs
return list(np.around(means, 3)), list(np.around(stdevs, 3))
# train,eval数据集的mean、std
mean_train = cal_mean_std(root_train)[0]
std_train = cal_mean_std(root_train)[1]
mean_eval = cal_mean_std(root_train)[0]
std_eval = cal_mean_std(root_train)[1]
# 数据增强
transformer={"train":transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean_train, std_train)]),
"eval":transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean_eval, std_eval)])}
# 制作数据集
dataset_train = ImageFolder(root_train, transform=transformer["train"])
dataset_eval = ImageFolder(root_train, transform=transformer["eval"])
loader_train = DataLoader(dataset=dataset_train, batch_size=6, shuffle=True, worker_init_fn=6)
loader_eval = DataLoader(dataset=dataset_eval, batch_size=6, shuffle=True, worker_init_fn=6)
class_name = dataset_train.classes
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 查看制作完成的数据集
print(dataset_train.classes)
print(dataset_train.class_to_idx)
print(dataset_train.imgs[0])
# 训练数据可视化
batch_imgs, lables = next(iter(loader_eval))
grid_img = torchvision.utils.make_grid(batch_imgs)
# 反归一化
grid_img = grid_img.permute(1, 2, 0)
grid_img = grid_img*torch.Tensor(std_train)+torch.Tensor(mean_train)
# 可视化展示
plt.title([class_name[i] for i in lables])
plt.imshow(grid_img)
plt.show()
运行以上代码的输出:
['0_cat', '1_dog', '2_ants', '3_bees']
{'0_cat': 0, '1_dog': 1, '2_ants': 2, '3_bees': 3}
('D:\Users\CV learning\pytorch\data\cat_dog_ants_bees\train\0_cat\cat.0.jpg', 0)
# 对resnet34模型进行微调
net = models.resnet34()
net.load_state_dict(torch.load("D:\\Users\\CV learning\\pytorch\\data\\resnet34-b627a593.pth"))
# 加载预训练模型的全连接层参数
for i in net.fc.parameters():
print(i.size())
num_ftrs = net.fc.in_features
# 调整全连接层的输出数为len(class_name),此时net.fc.parameters()的size也一起进行了调整
net.fc = nn.Linear(num_ftrs, len(class_name))
# 将模型放到cpu/gpu
net = net.to(device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(net.parameters(), lr=0.0001)
# 调整后的net.fc.parameters()
for i in net.fc.parameters():
print(i.size())
运行以上代码的输出:
torch.Size([1000, 512])
torch.Size([1000])
torch.Size([4, 512])
torch.Size([4])
# 定义训练评估函数
def train_and_eval(model, epochs, loss_func, optimizer, loader_train, loader_eval):
# 初始化参数
t_start = time.time()
best_weights = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(epochs):
print("-"*125)
# train
model.train()
running_loss = 0.0
running_acc = 0.0
train_bar = tqdm(loader_train)
train_bar.desc = f"第{epoch+1}次训练,Processing"
for inputs, lables in train_bar:
inputs = inputs.to(device)
lables = lables.to(device)
# 梯度归零
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 损失值
loss = loss_func(outputs, lables)
# 输出最大的概率的类
pred = torch.argmax(outputs, 1)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 统计这个batch的损失值和与分类正确数
running_loss += loss.item()*inputs.size(0)
running_acc += (pred==lables.data).sum()
# 计算本epoch的损失值和正确率
train_loss = running_loss/len(dataset_train)
train_acc = running_acc/len(dataset_train)
print(f"第{epoch+1}次训练,train_loss:{train_loss:.6f}, train_acc:{train_acc:.6f}")
# eval
model.eval()
running_loss = 0.0
running_acc = 0.0
with torch.no_grad():
eval_bar = tqdm(loader_eval)
eval_bar.desc = f"第{epoch+1}次评估,Processing"
for inputs, lables in eval_bar:
inputs = inputs.to(device)
lables = lables.to(device)
outputs = model(inputs)
loss = loss_func(outputs, lables)
pred = torch.argmax(outputs, 1)
running_loss += loss.item()*inputs.size(0)
running_acc += (pred==lables.data).sum()
val_loss = running_loss/len(dataset_eval)
val_acc = running_acc/len(dataset_eval)
print(f"第{epoch+1}次评估,val_loss:{val_loss:.6f}, val_acc:{val_acc:.6f}")
if val_acc > best_acc:
best_acc = val_acc
best_weights = copy.deepcopy(model.state_dict())
t_end = time.time()
total_time = t_end - t_start
print("-"*125)
print(f"{epochs}次训练与评估共计用时{total_time//60:.0f}m{total_time%60:.0f}s")
print(f"最高正确率是{best_acc:.6f}")
# 加载最佳的模型权重
model.load_state_dict(best_weights)
return model
# 创建参数微调模型
net_fine_tune = train_and_eval(net, 10, loss_func, optimizer, loader_train, loader_eval)
# 保存训练好的模型参数
torch.save(net_fine_tune.state_dict(), "D:\\Users\\CV learning\\pytorch\\data\\cat_dog_ants_bees\\resnet34_fine_tune.pth")

可以看到,前三次的训练和评估val_acc已经达到了0.986577,说明模型的泛化能力已经挺不错了,此时train_acc也高达0.869128。最终的结果如下图,
由于笔者是用cpu跑的因此使用了近20分钟的时间。十轮训练后,模型的val_acc可以高达0.998322,已经是一个很好的结果了。
特征提取
该方法冻结除全连接层外的所有层的权重,修改全连接层后仅训练全连接层。
特征提取仅仅在构造模型时与参数微调方法有所区别,其他内容都是一样的。
import torchvision.models as models
import torch.nn as nn
import torch.optim as optim
net = models.resnet34()
net.load_state_dict(torch.load("D:\\Users\\CV learning\\pytorch\\data\\resnet34-b627a593.pth"))
# 加载预训练权重的net.fc.parameters()
for i in net.fc.parameters():
print(i.size())
for param in net.parameters():
param.requires_grad = False
num_ftrs = net.fc.in_features
# 调整全连接层的输出数为len(class_name),此时net.fc.parameters()也一起调整
net.fc = nn.Linear(num_ftrs, len(class_name))
# 将模型放到cpu/gpu
net = net.to(device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(net.parameters(), lr=0.0001)
# 调整后的net.fc.parameters()
for i in net.fc.parameters():
print(i.size())
最终运行结果如下:

4. 参考内容
- 你必须要知道CNN模型:ResNet
- torchvision.models.resnet — Torchvision 0.15 documentation
- 【PyTorch】迁移学习教程(计算机视觉应用实例)_Xavier Jiezou的博客-CSDN博客
【pytorch】ResNet源码解读和基于迁移学习的实战的更多相关文章
- [源码解读] ResNet源码解读(pytorch)
自己看读完pytorch封装的源码后,自己又重新写了一边(模仿其书写格式), 一些问题在代码中说明. import torch import torchvision import argparse i ...
- pytorch bert 源码解读
https://daiwk.github.io/posts/nlp-bert.html 目录 概述 BERT 模型架构 Input Representation Pre-training Tasks ...
- KClient——kafka消息中间件源码解读
目录 kclient消息中间件 kclient-processor top.ninwoo.kclient.app.KClientApplication top.ninwoo.kclient.app.K ...
- 基于Docker的TensorFlow机器学习框架搭建和实例源码解读
概述:基于Docker的TensorFlow机器学习框架搭建和实例源码解读,TensorFlow作为最火热的机器学习框架之一,Docker是的容器,可以很好的结合起来,为机器学习或者科研人员提供便捷的 ...
- Flask(4)- flask请求上下文源码解读、http聊天室单聊/群聊(基于gevent-websocket)
一.flask请求上下文源码解读 通过上篇源码分析,我们知道了有请求发来的时候就执行了app(Flask的实例化对象)的__call__方法,而__call__方法返回了app的wsgi_app(en ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
- AFNetworking 3.0 源码解读(一)之 AFNetworkReachabilityManager
做ios开发,AFNetworking 这个网络框架肯定都非常熟悉,也许我们平时只使用了它的部分功能,而且我们对它的实现原理并不是很清楚,就好像总是有一团迷雾在眼前一样. 接下来我们就非常详细的来读一 ...
随机推荐
- 程序员IT行业,外行眼里高收入人群,内行人里的卷王
程序员 一词,在我眼里其实是贬义词.因为我的其他不是这行的亲朋友好友,你和他们说,你是一名程序员· 他们 第一刻板影响就是,秃头,肥胖,宅男,油腻,不修边幅 反正给人一种不干净,不好形象,,,,不知道 ...
- 2020-12-26:mysql中,表person有字段id、name、age、sex,id是主键,name是普通索引,age和sex没有索引。select * from person where id=1 and name='james' and age=1 and sex=0。请问这条语句有几次回表?
2020-12-26:mysql中,表person有字段id.name.age.sex,id是主键,name是普通索引,age和sex没有索引.select * from person where i ...
- uni-app 创建项目及目录结构
文件-新建-1.项目 ┌─uniCloud 云空间目录,阿里云为uniCloud-aliyun,腾讯云为uniCloud-tcb(详见uniCloud) │─components 符合vue组件规范的 ...
- HTML渲染机制
一直写页面但是很少对一些较深的运行机制的了解,这次趁休假查了一些相关的资料加上个人理解,记录一下关于html渲染的整个过程,也加深一下自己对html渲染的理解 一.先借一张图来看看html的整个加载过 ...
- Kafka实时数据即席查询应用与实践
作者:vivo 互联网搜索团队- Deng Jie Kafka中的实时数据是以Topic的概念进行分类存储,而Topic的数据是有一定时效性的,比如保存24小时.36小时.48小时等.而在定位一些实时 ...
- 入门 Python GUI 开发的第一个坑
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中链接. 使用 Anaconda 3(conda 4.5.11)的 tkinter python 包(c ...
- Kubernetes(k8s)服务service:service的发现和service的发布
目录 一.系统环境 二.前言 三.Kubernetes service简介 四.使用hostPort向外界暴露应用程序 4.1 创建deploy 4.2 使用hostPort向外界暴露pod的端口 五 ...
- WPF中有中心点的slider滑动条
想要实现的效果 原生滑动条 需要认识一下滑动条的组成 在原生控件中生成"资源字典"对应的样式 然后在track所在的列进行添砖加瓦 由于track在row="1" ...
- 传统软件如何SaaS化改造,10个问答带你掌握最优解
摘要:如果您所在企业希望实行SaaS化改造,可访问了解华为云开发者技术团队的SaaS支持计划. 本文分享自华为云社区<[云享问答]第1期:传统软件如何SaaS化改造,10个问答带你掌握最优解!& ...
- 谷歌语法的基础知识&FOFA
谷歌语法 谷歌语法基础符号: "xxx":表示完全匹配,即关键字不能分开,顺序也不能变 +:"xxx"+www.baidu.com 搜索xxx与baidu.c ...