【论文阅读】VDBFusion: Flexible and Efficient TSDF Integration of Range Sensor Data
Type: Sensors
Year: 2022
tag: Mapping
组织: Bonn
参考与前言
论文链接:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8838740/
其他参考建议看一下本篇论文的对应reference paper处
代码链接:https://github.com/PRBonn/vdbfusion
整篇文章首先revisit了基础的mapping算法,然后提供了一种方法可以: building effective and efficient real-world mapping systems.
与常见的SLAM和建图算法不同的是,我们并不会对要构建的环境或者传感器最远距离做出任何前提假设。主要使用OpenVDB去实现 an effective 3D map representation.
1. Motivation
- 现在很多的系统都会对传感器类型(比如LiDAR, RGB-D等)做出假设,或者对建图范围进行限制
- 关于TSDF的加速大多在GPU上进行,并不适用于mobile robots
- 不同于其他将RGB-D/LiDAR 转成image形式的,此篇我们直接将使用point cloud 数据,使得此系统可以适用于其他的range sensor
整个系统主要是针对三维点云的建图库,从SLAM中将其分离保证使用的灵活性和便携性;所以数据中需要给出对应odom
Contribution
原文使用了一句话总结,主要就是给出了一个高效的建图系统
The main contribution of this paper is an effective mapping system that comes as an open-source TSDF library and does not require making assumptions about the size of the environment to be mapped.
Related Work
首先是指出在建图系统中常用的稀疏的数据结构: octrees 或 voxel hashing
In this line, sparse data structures have also been explored to build such systems, for example, octrees [1,29,33,34] or voxel hashing approaches
但是他们存在问题:
- 可能是为某个传感器或sensor type进行的设计,比如Microsoft’s Kinect;这通常使得他们并不能受用于其他的传感器 比如不能直接把360度环绕的LiDAR转成pin hole的相机
- 大多使用GPU进行加速,并不适用于小型的移动机器人平台上;而且GPU也没有完全在小型计算平台上进行展开部署
In sum, building a 3D mapping system that is memory efficient and fast at the same time remains a challenge. In this work, we aim to fill this gap with the aid of the VDB data structure
2. Method
When using our library that builds on top of OpenVDB, the application developer can safely ignore the underlying data structure implementation and use the structure as if it would be a dense voxel grid.
相关术语转换:

2.1 VDB 数据结构
当对3D 数据进行处理时,eg point clouds,通常我们会使用树结构,eg octrees;使用这种结构的主要原因如下。同样也有其他领域有这种需求,比如流体计算,仿真空间大小并不会提前预知,fluids也可以virtually expand infinitely
- virtually unbounded sparse representations of the scene, 对场景大小并无限制,稀疏式表达
- efficiently employed on robotics systems where memory and CPU resources are constrained, 高效部署机器人平台
VDB 是由计算机图形学领域提出的,主要针对于 unbounded volumetric data manipulation in the context of creating animated movies
VDB 表示主要由 a sparse collection of blocks of voxels 通常来说是8x8x8=512个voxels,可以通过具有两个 internal levels 的 分层树结构 访问,a fixed height of the involved trees
这种height balance的结构也正是与octree八叉树的区别,对比八叉树,VDB在每个spatial维度上都仅两个branching factor,如下图:
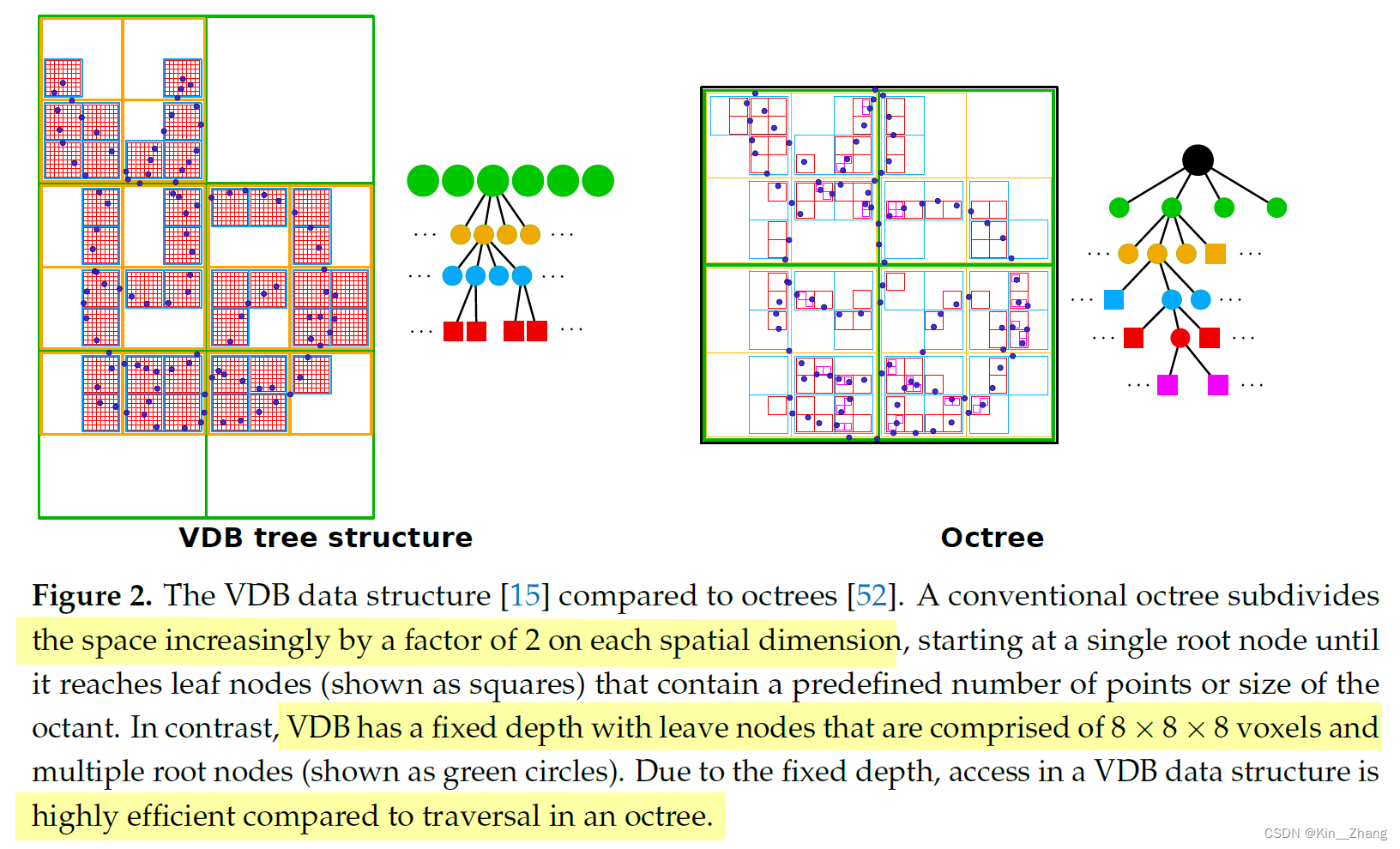
文中有提到为什么这种更好的数据结构并没有为机器人领域所大量使用,主要在 名词的使用 上 图形学和机器人的不同(问浩哥 浩哥看法 是因为八叉树历史更久一点 但是时代总是往前走的 需要慢慢让大家看到的
2.2 输入与转换
整个系统的输入为 N 个点云点 \(\mathcal{P}=\left\{\mathbf{p}_1, \ldots, \mathbf{p}_N\right\} \text {, where } \mathbf{p}_i \in \mathbb{R}^3\). 同时我们也已知每个点的位置。知道pose \(\mathbf T_i \in \R^{4\times4}\) ,在代码中我们使用 numpy.ndarray 或 std::vectorEigen::Vector3d进行点云的保存。Given such point clouds and sensor locations, we can now integrate the data into the TSDF, exploiting the VDB data structure via the VDBFusion approach.
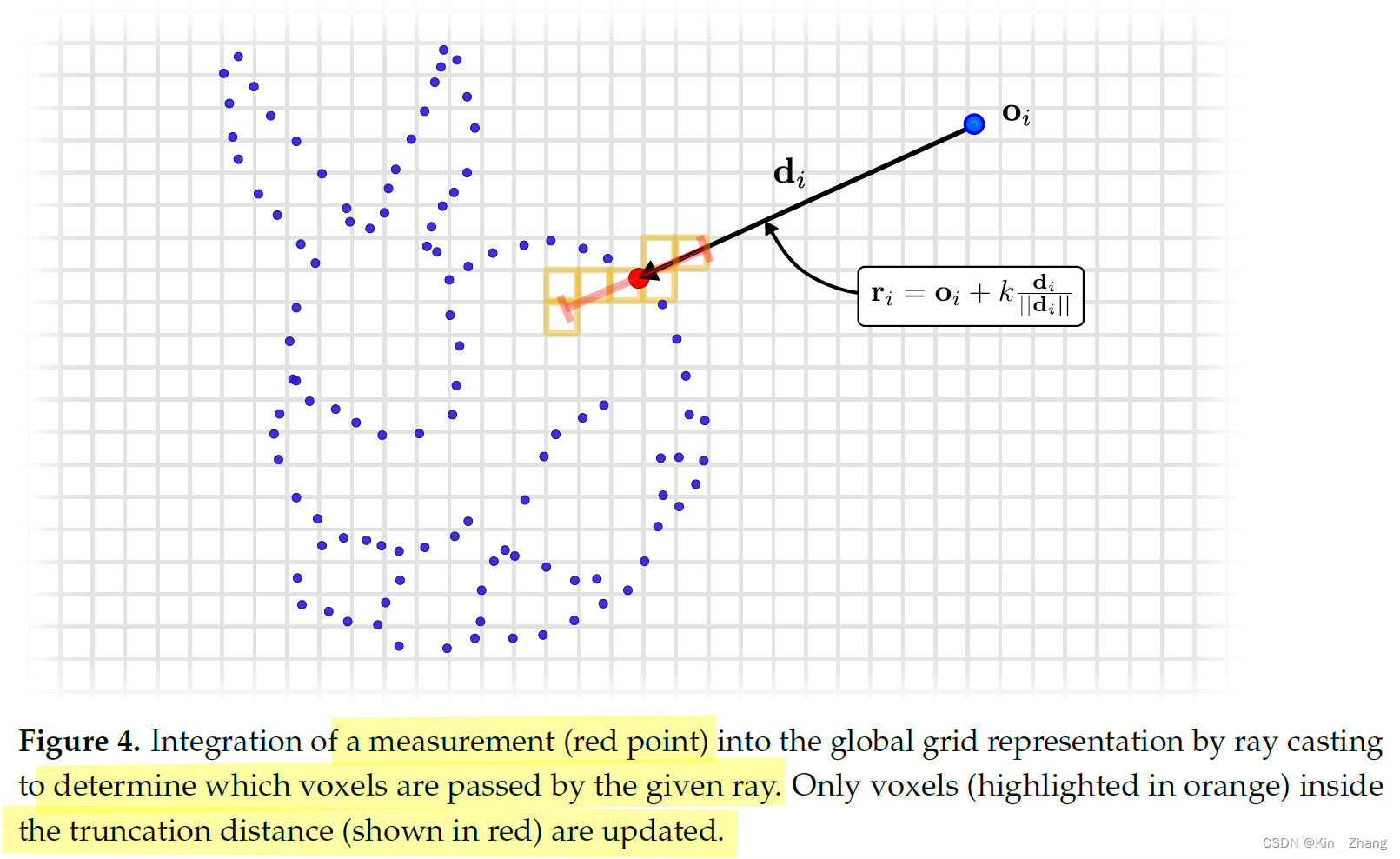
为了将新的观测 \(\mathcal{P}\) 加入到系统中,首先我们需要计算voxels并将其转到全局grid下。为了计算voxel在VDB grid的位置,我们使用raycast 也就是射线组成的集合 \(\mathcal{R}=\left\{\mathbf{r}_1, \ldots, \mathbf{r}_N\right\}\),每一个的定义如下
\]
其中 o为原点,d为方向 也就是 \(\mathbf{d}_i=\mathbf{p}_i-\mathbf o_i\) 对于所有射线的原点就是传感器在全局下的坐标 即 \(\mathbf o_i=\mathbf t_i\),we truncate the rays by considering only \(k \in\left[\left\|\mathbf{d}_i\right\|-\tau_{\mathrm{TD}},\left\|\mathbf{d}_i\right\|+\tau_{\mathrm{TD}}\right]\) for fast integration,其中\(\tau_{\mathrm{TD}}\) 是truncation distance,此步骤对应code:
// Truncate the Ray before and after the source unless space_carving_ is specified.
const auto depth = static_cast<float>(direction.norm());
const float t0 = space_carving_ ? 0.0f : depth - sdf_trunc_;
const float t1 = depth + sdf_trunc_;
// Create one DDA per ray(per thread), the ray must operate on voxel grid coordinates.
const auto ray = openvdb::math::Ray<float>(eye, dir, t0, t1).worldToIndex(*tsdf_);
We determine the voxel locations x by the ray–voxel intersections determined via Differential Digital Analyzer (DDA) available in the OpenVDB library,示意代码如下:
openvdb::math::DDA<decltype(ray)> dda(ray);
do {
const auto voxel = dda.voxel();
const auto voxel_center = GetVoxelCenter(voxel, xform);
const auto sdf = ComputeSDF(origin, point, voxel_center);
if (sdf > -sdf_trunc_) {
const float tsdf = std::min(sdf_trunc_, sdf);
const float weight = weighting_function(sdf);
const float last_weight = weights_acc.getValue(voxel);
const float last_tsdf = tsdf_acc.getValue(voxel);
const float new_weight = weight + last_weight;
const float new_tsdf = (last_tsdf * last_weight + tsdf * weight) / (new_weight);
tsdf_acc.setValue(voxel, new_tsdf);
weights_acc.setValue(voxel, new_weight);
}
} while (dda.step());
注意 voxel 更新后,我们会计算投影的signed distance,从点到其voxel的中心距离
const auto sdf = ComputeSDF(origin, point, voxel_center);
weight的更新则是依据TSDF原论文中[16] 公式进行的,但是文中也提到 这个是function进来 其实是一个 lambda expression 所以可改
\]
完整integrate 函数如下 与github代码一致:
void VDBVolume::Integrate(const std::vector<Eigen::Vector3d>& points,
const Eigen::Vector3d& origin,
const std::function<float(float)>& weighting_function) {
if (points.empty()) {
std::cerr << "PointCloud provided is empty\n";
return;
}
// Get some variables that are common to all rays
const openvdb::math::Transform& xform = tsdf_->transform();
const openvdb::Vec3R eye(origin.x(), origin.y(), origin.z());
// Get the "unsafe" version of the grid acessors
auto tsdf_acc = tsdf_->getUnsafeAccessor();
auto weights_acc = weights_->getUnsafeAccessor();
// Launch an for_each execution, use std::execution::par to parallelize this region
std::for_each(points.cbegin(), points.cend(), [&](const auto& point) {
// Get the direction from the sensor origin to the point and normalize it
const Eigen::Vector3d direction = point - origin;
openvdb::Vec3R dir(direction.x(), direction.y(), direction.z());
dir.normalize();
// Truncate the Ray before and after the source unless space_carving_ is specified.
const auto depth = static_cast<float>(direction.norm());
const float t0 = space_carving_ ? 0.0f : depth - sdf_trunc_;
const float t1 = depth + sdf_trunc_;
// Create one DDA per ray(per thread), the ray must operate on voxel grid coordinates.
const auto ray = openvdb::math::Ray<float>(eye, dir, t0, t1).worldToIndex(*tsdf_);
openvdb::math::DDA<decltype(ray)> dda(ray);
do {
const auto voxel = dda.voxel();
const auto voxel_center = GetVoxelCenter(voxel, xform);
const auto sdf = ComputeSDF(origin, point, voxel_center);
if (sdf > -sdf_trunc_) {
const float tsdf = std::min(sdf_trunc_, sdf);
const float weight = weighting_function(sdf);
const float last_weight = weights_acc.getValue(voxel);
const float last_tsdf = tsdf_acc.getValue(voxel);
const float new_weight = weight + last_weight;
const float new_tsdf = (last_tsdf * last_weight + tsdf * weight) / (new_weight);
tsdf_acc.setValue(voxel, new_tsdf);
weights_acc.setValue(voxel, new_weight);
}
} while (dda.step());
});
}
注意以上步骤并不是主要耗时的地方,Reading and writing values in sparse data structures are usually the most expensive and hard-to-implement steps for these types of mapping pipelines. By levering the VDB data structure, we efficiently carry out read/write operations in our global map grid.
2.4 Space Carving
也就是前面我们提到k的范围,其实在代码中如果开启了space carving,就是传感器中心到物体点上所有经过的voxel都会被更新。这主要是为mapping应用而进行的修改:Some mapping applications need to be aware of the free space in the vicinity of the sensor or must distinguish free from unobserved regions.
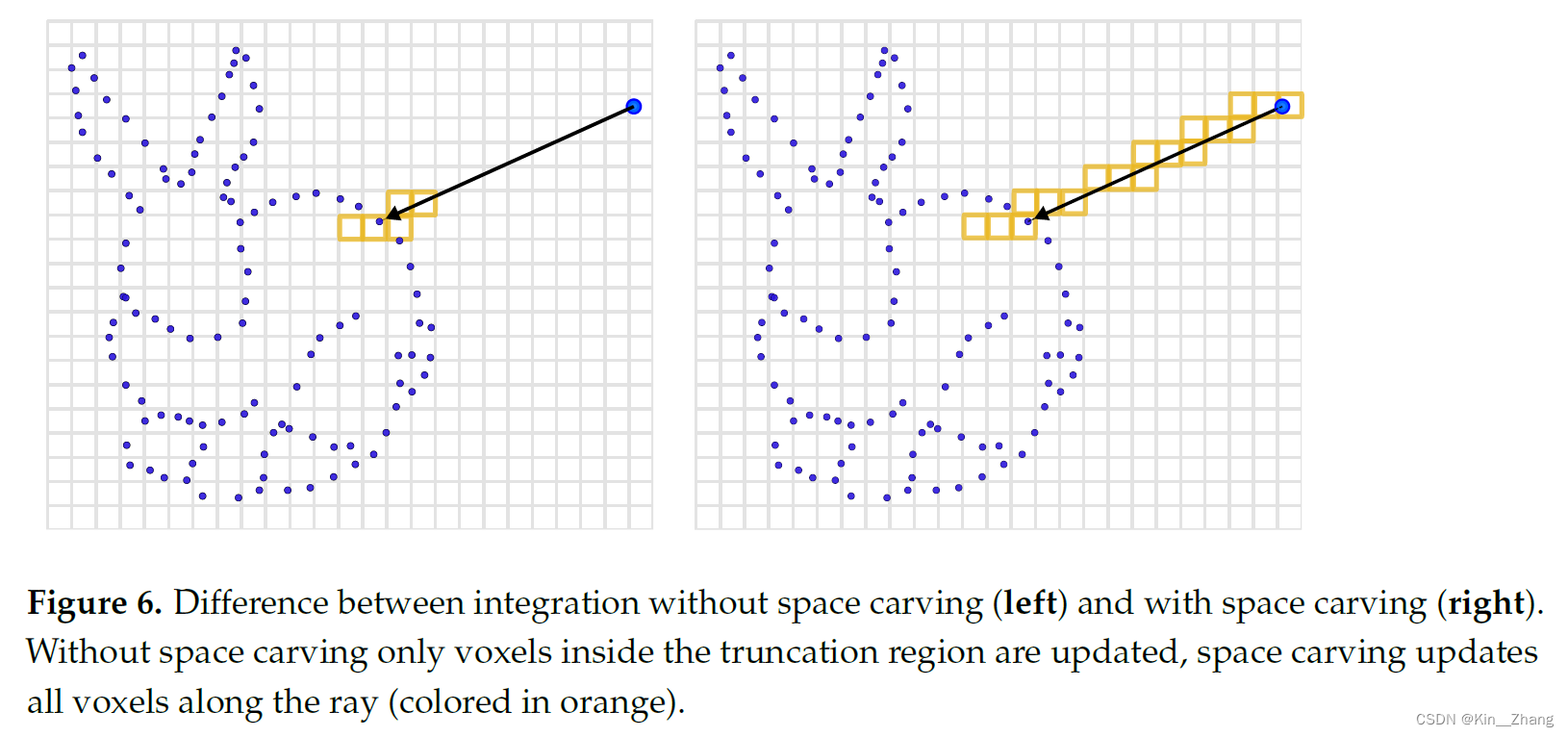
整个系统的参数,简单调整层面的话,其实只有三个:
- Voxel size (float)
- Truncation distance (float) \(\tau_{\mathrm{TD}}\)
- Space Carving (bool)
后续还提到了关于meshing的部分,如下:
- 由Open3D [55] 实现的marching cubes[54]
- 使用[16] 提出的 来进行filling holes
- 引入了可选的min_weight参数,来进行mesh中三角形的提取 (?这一点还没用过 → 代码默认设置0.5,感觉够用了(jjiao)
- 将PUMA[40] 中的进行了实现,实现了out-of-the-box的动态障碍物的移除
- 但是实验中其实 space carving对于动态障碍物的去除也起到了一定的作用,那PUMA的实现
3. 实验及结果
主要就是速度快!在without space carving下快了快2倍的建图速度
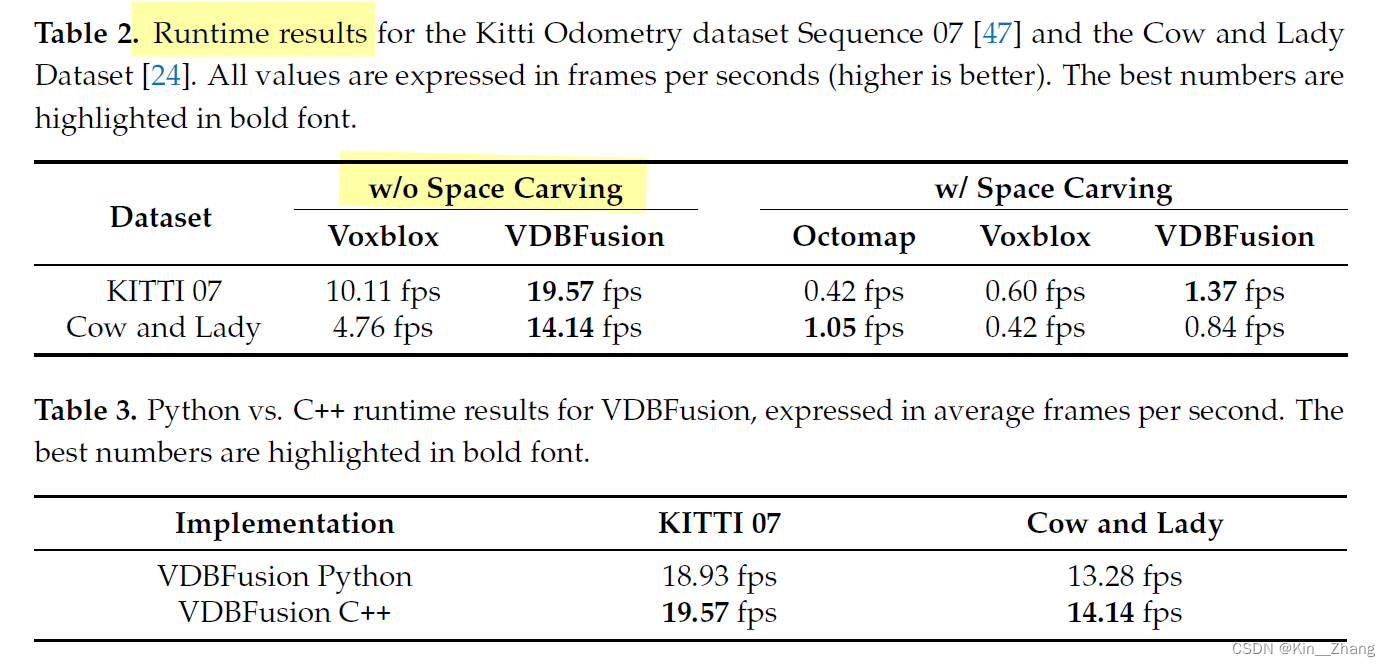
再一个就是省内存!和存储
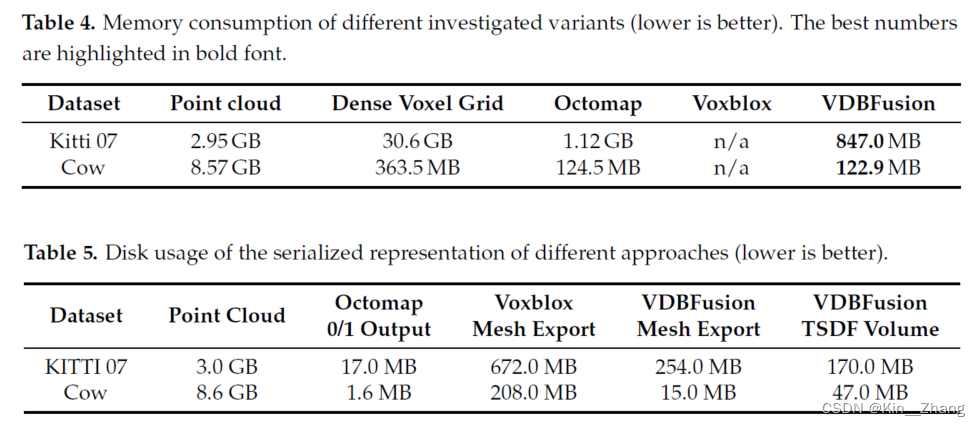
更多的定性分析图:

后面就是关于有无space carving的对比,毕竟在速度上with space其实没有提升很多,但是精度上确实会对整体建图会更好,比如下面的定性分析图:
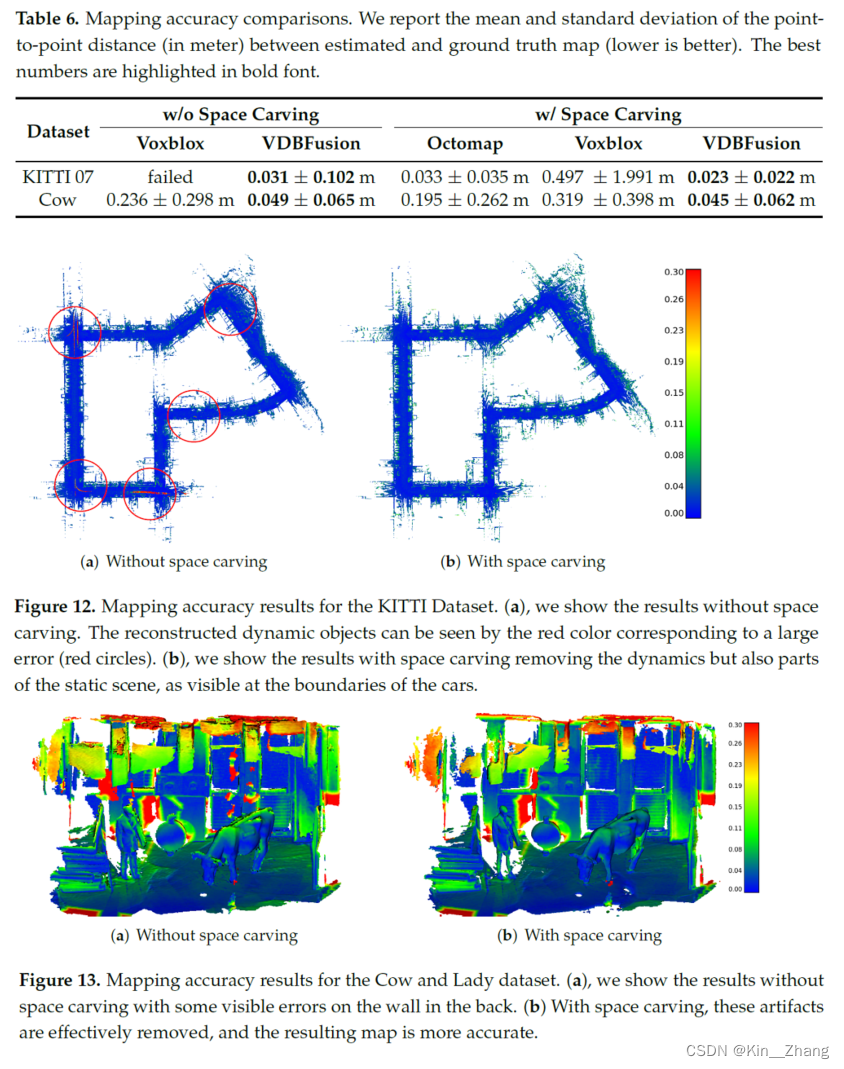
更多的请移步原文论文进行查看,论文进行了大量的实验和很多数据集上的测试,包括LiDAR 和 RGB-D都是用的这套系统,因为都可以有 point cloud信息
- 关于 we show the results with space carving removing the dynamics but also parts of the static scene, as visible at the boundaries of the cars. 后面看一下PUMA那块的部分 [Poisson Surface Reconstruction for LiDAR Odometry and Mapping]
整个框架的各个部分的时间耗时情况
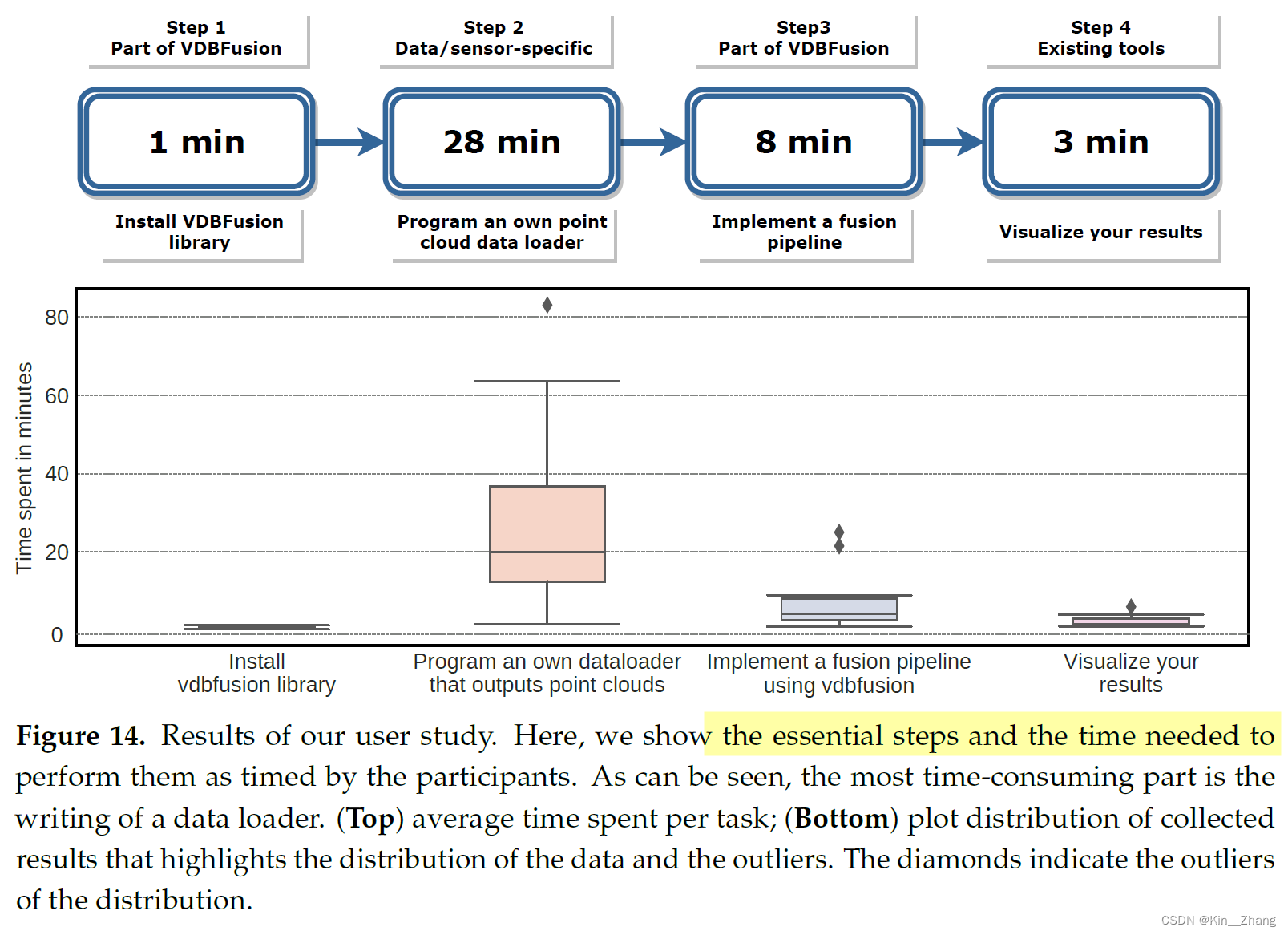
4. Conclusion
In this paper, we propose an approach for volumetric mapping based on TSDF representation that exploits a readily available efficient and sparse data structure called VDB.
实验证明 不仅在速度上有提升,同时精度上也有很大的提升
文章虽然VDB和TSDF都是经过前人的铺垫,但是确实将这两者一起用,并提出一个统一的mapping框架 是一个很大的贡献,为后人使用奠定了基础,比如后面他们基于此 又发了一篇稀疏到dense mesh的重构的make it dense一文
碎碎念
牛掰!虽然是融合,但是做的是真的好啊,故事讲的也很棒,框架完整,最重要是 实验真的很丰富,很好的印证了 为什么提出这一系统的几个重要点:速度、精度和统一 general framework
后面看看浩哥提取的ros版本 再学习一下 整体。狗狗实验中发现,vdbfusion 主要是需要提供一个还不错的odom作为mapping前提,不然还是比较gg的 可能需要odom 滤一滤?不过好像大多mapping都假设odom drift不大
然后新组里博后Daniel说 拿实现octree不太好的 octomap 对比有点不太说服人,COPY一段博后的原话 Daniel是UFOMapping的作者:
In the paper they compare to OctoMap, which is has a very poor octree implementation. In the image with the comparison of the two they write "VDB has a fixed depth..." which seems odd to me since OctoMap also has a fixed depth; however it is 16 instead of 4 as in their case. It seems strange to me that they argue that 4 layers is much faster than 16, then Voxblox would be even faster than VBD since they have only a single layer.
From KTH Postdoc, Daniel Duberg
本机运行示意 & 添加了RGB render
RGB 渲染请看repolink,gitee 和github 个人同步更新 https://github.com/Kin-Zhang/vdbfusion_mapping
渲染效果如下:

这个依赖处理主要需要注意的点是:boost版本 一定要pref path 默认会把本机上的覆盖的,更多查看聪明的gitee链接:https://gitee.com/kin_zhang/vdbfusion_mapping
以下运行时间示意,附上本机配置进行查看:
model name : Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
total used free shared buff/cache available
Mem: 15G 8.6G 746M 298M 6.2G 6.3G
Swap: 27G 768K 27G
运行时间 其余的是默认的参数,给出了有space carving和无space carving的
# ============ no space carving
--------------------- id: 0
[DDA Integrate] takes 77.429086 ms
--------------------- id: 1
[DDA Integrate] takes 66.725936 ms
--------------------- id: 2
[DDA Integrate] takes 66.145924 ms
--------------------- id: 3
[DDA Integrate] takes 67.982556 ms
--------------------- id: 4
[DDA Integrate] takes 65.653812 ms
--------------------- id: 5
[DDA Integrate] takes 66.645916 ms
--------------------- id: 6
[DDA Integrate] takes 66.736198 ms
--------------------- id: 7
[DDA Integrate] takes 65.326826 ms
--------------------- id: 8
[DDA Integrate] takes 65.388174 ms
--------------------- id: 9
[DDA Integrate] takes 65.246777 ms
[Writing VDB to disk] takes 18.666781 ms
[DDA Writing Mesh to disk] takes 80.787827 ms
# ============ have space carving
--------------------- id: 0
[DDA Integrate] takes 899.551559 ms
--------------------- id: 1
[DDA Integrate] takes 896.636835 ms
--------------------- id: 2
[DDA Integrate] takes 880.238141 ms
--------------------- id: 3
[DDA Integrate] takes 860.616463 ms
--------------------- id: 4
[DDA Integrate] takes 859.967681 ms
--------------------- id: 5
[DDA Integrate] takes 858.748218 ms
--------------------- id: 6
[DDA Integrate] takes 853.644677 ms
--------------------- id: 7
[DDA Integrate] takes 844.882369 ms
--------------------- id: 8
[DDA Integrate] takes 837.745561 ms
--------------------- id: 9
[DDA Integrate] takes 822.098719 ms
[Writing VDB to disk] takes 63.951741 ms
[DDA Writing Mesh to disk] takes 292.059824 ms
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh
【论文阅读】VDBFusion: Flexible and Efficient TSDF Integration of Range Sensor Data的更多相关文章
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读 | ERNIE: Enhanced Representation through Knowledge Integration
摘要 知识加强的语义表示模型. knowledge masking strategies : entity-level masking / phrase-level masking 实 ...
- 论文阅读:《Bag of Tricks for Efficient Text Classification》
论文阅读:<Bag of Tricks for Efficient Text Classification> 2018-04-25 11:22:29 卓寿杰_SoulJoy 阅读数 954 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- Spirng 当中 Bean的作用域
Spirng 当中 Bean的作用域 @ 目录 Spirng 当中 Bean的作用域 每博一文案 1. Spring6 当中的 Bean的作用域 1.2 singleton 默认 1.3 protot ...
- 视频讲解如何构建surging微服务调用
surging 是一款优秀的微服务引擎,包括了社区版,标准版,异构版,平台版本来解决公司的业务场景需求,如果你是初学者,或者是技术狂热者,社区版完全可以符合你们的要求来学习或者构建起微服务体系的引擎框 ...
- AI编译器CINN v.s TVM 中CodeGen 源码解读
如下的技术点梳理仅以「日常优化工作」为牵引点,涉及哪个模块,就具体去看哪个模块的代码. 一.CINN 框架 CINN 中CodeGen之后的代码编译主要交给了Compiler类来负责.核心的函数主要是 ...
- csapp-attacklab(完美解决版)
注意:必须阅读Writeup,否则根本看不懂这个lab要怎么做 实验前准备 1.在终端中输入./ctarget和./rtarget结果报错 百度后得知自学的同学需要在执行文件时加上-q参数,不发送结果 ...
- vue3中404路由匹配规则
{ path: '/:pathMatch(.)', component: () => import('@/views/error/404.vue') },
- Asp-Net-Core开发笔记:使用原生的接口限流功能
前言 之前介绍过使用 AspNetCoreRateLimit 组件来实现接口限流 从 .Net7 开始,AspNetCore 开始内置限流组件,当时我们的项目还在 .Net6 所以只能用第三方的 现在 ...
- QtCreator 跨平台开发添加动态库教程(以OpenCV库举例)- Windows篇
Qt具有跨平台的特性,即Qt数据结构与算法库本身跨平台和编译脚本(.pro)跨平台.在同时具有Windows下和Linux开发的需求时,最好的建议是使用QtCreator来开发,虽然也可以使用其他 ...
- minio-搭建个人云存储服务
相信风靡全球的亚马逊 AWS S3 的存储云服务大家已经耳熟能详了,如何自己搭建一个私有的S3存储云服务呢?Minio 提供对象存储服务,兼容了 AWS S3 存储协议,用于非结构化的数据存.非结构化 ...
- 视觉族: 基于Stable Diffusion的免费AI绘画图片生成器工具
视觉族是一款基于Stable Diffusion文生图模型的免费在线AI绘画图片生成器工具,可以使用提示关键词快速生成精美的艺术图片,支持中文提示.无论你是想要创作自己的原创作品,还是想要为你的文字增 ...
- C++笔记(13)数组的引用和引用的数组
数组的引用 数组有二个特性,影响作用在数组上的函数:一是不能复制数组,二是使用数组名时, 数组名会自动指向其第一个元素的指针. 因为不能复制,所以无法编写使用数组类型的形参,数组会自动转化为指针.比如 ...