掉了两根头发后,我悟了!vue3的scoped原来是这样避免样式污染(上)
前言
众所周知,在vue中使用scoped可以避免父组件的样式渗透到子组件中。使用了scoped后会给html增加自定义属性data-v-x,同时会给组件内CSS选择器添加对应的属性选择器[data-v-x]。这篇我们来讲讲vue是如何给CSS选择器添加对应的属性选择器[data-v-x]。注:本文中使用的vue版本为3.4.19,@vitejs/plugin-vue的版本为5.0.4。
关注公众号:【前端欧阳】,给自己一个进阶vue的机会
看个demo
我们先来看个demo,代码如下:
<template>
<div class="block">hello world</div>
</template>
<style scoped>
.block {
color: red;
}
</style>
经过编译后,上面的demo代码就会变成下面这样:
<template>
<div data-v-c1c19b25 class="block">hello world</div>
</template>
<style>
.block[data-v-c1c19b25] {
color: red;
}
</style>
从上面的代码可以看到在div上多了一个data-v-c1c19b25自定义属性,并且css的属性选择器上面也多了一个[data-v-c1c19b25]。
可能有的小伙伴有疑问,为什么生成这样的代码就可以避免样式污染呢?
.block[data-v-c1c19b25]:这里面包含两个选择器。.block是一个类选择器,表示class的值包含block。[data-v-c1c19b25]是一个属性选择器,表示存在data-v-c1c19b25自定义属性的元素。
所以只有class包含block,并且存在data-v-c1c19b25自定义属性的元素才能命中这个样式,这样就能避免样式污染。
并且由于在同一个组件里面生成的data-v-x值是一样的,所以在同一组件内多个html元素只要class的值包含block,就可以命中color: red的样式。
接下来我将通过debug的方式带你了解,vue是如何在css中生成.block[data-v-c1c19b25]这样的属性选择器。
@vitejs/plugin-vue
还是一样的套路启动一个debug终端。这里以vscode举例,打开终端然后点击终端中的+号旁边的下拉箭头,在下拉中点击Javascript Debug Terminal就可以启动一个debug终端。

假如vue文件编译为js文件是一个毛线团,那么他的线头一定是vite.config.ts文件中使用@vitejs/plugin-vue的地方。通过这个线头开始debug我们就能够梳理清楚完整的工作流程。
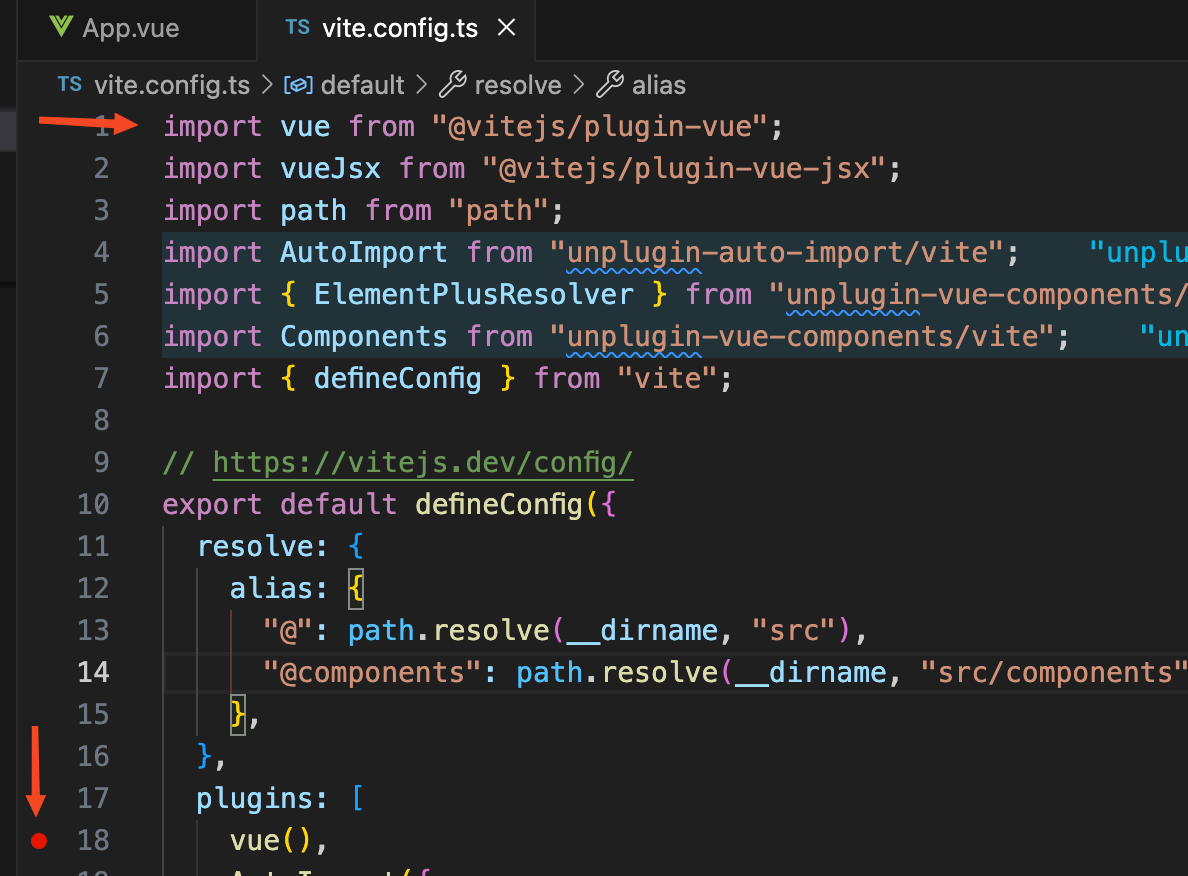
vuePlugin函数
我们给上方图片的vue函数打了一个断点,然后在debug终端上面执行yarn dev,我们看到断点已经停留在了vue函数这里。然后点击step into,断点走到了@vitejs/plugin-vue库中的一个vuePlugin函数中。我们看到简化后的vuePlugin函数代码如下:
function vuePlugin(rawOptions = {}) {
return {
name: "vite:vue",
// ...省略其他插件钩子函数
transform(code, id, opt) {
// ..
}
};
}
@vitejs/plugin-vue是作为一个plugins插件在vite中使用,vuePlugin函数返回的对象中的transform方法就是对应的插件钩子函数。vite会在对应的时候调用这些插件的钩子函数,vite每解析一个模块都会执行一次transform钩子函数。更多vite钩子相关内容查看官网。
我们这里只需要看transform钩子函数,解析每个模块时调用。
由于解析每个文件都会走到transform钩子函数中,但是我们只关注index.vue文件是如何解析的,所以我们给transform钩子函数打一个条件断点。如下图:
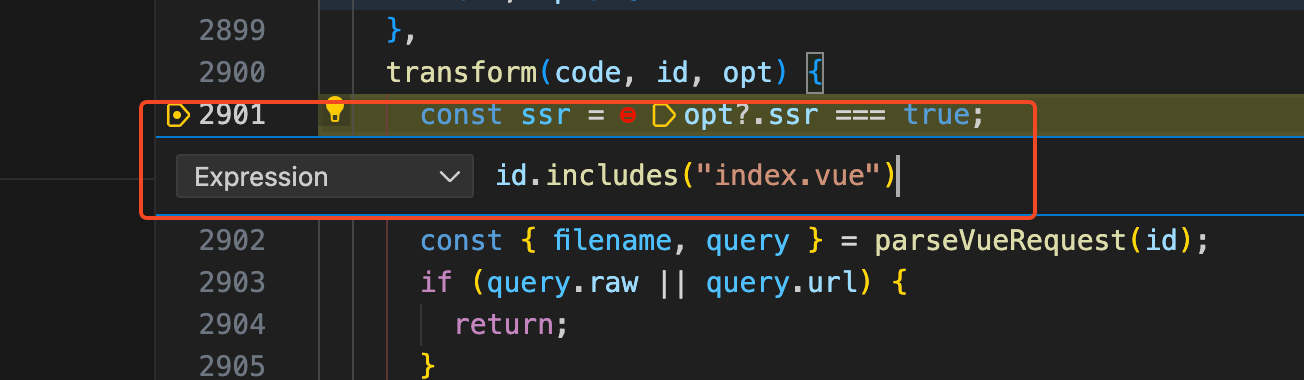
然后点击Continue(F5),vite服务启动后就会走到transform钩子函数中打的断点。我们可以看到简化后的transform钩子函数代码如下:
function transform(code, id, opt) {
const { filename, query } = parseVueRequest(id);
if (!query.vue) {
return transformMain(
code,
filename,
options.value,
this,
ssr,
customElementFilter.value(filename)
);
} else {
const descriptor = getDescriptor(filename);
if (query.type === "style") {
return transformStyle(
code,
descriptor,
Number(query.index || 0),
options.value
);
}
}
}
首先调用parseVueRequest函数解析出当前要处理的文件的filename和query,在debug终端来看看此时这两个的值。如下图:
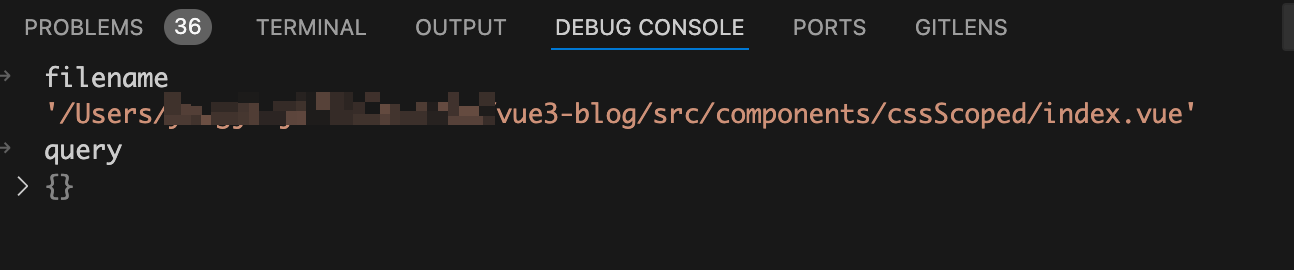
从上图中可以看到filename为当前处理的vue文件路径,query的值为空数组。所以此时代码会走到transformMain函数中。
transformMain函数
将断点走进transformMain函数,在我们这个场景中简化后的transformMain函数代码如下:
async function transformMain(code, filename, options) {
const { descriptor } = createDescriptor(filename, code, options);
const { code: templateCode } = await genTemplateCode(
descriptor
// ...省略
);
const { code: scriptCode } = await genScriptCode(
descriptor
// ...省略
);
const stylesCode = await genStyleCode(
descriptor
// ...省略
);
const output = [scriptCode, templateCode, stylesCode];
let resolvedCode = output.join("\n");
return {
code: resolvedCode,
};
}
我们在 通过debug搞清楚.vue文件怎么变成.js文件文章中已经深入讲解过transformMain函数了,所以这篇文章我们不会深入到transformMain函数中使用到的每个函数中。
首先调用createDescriptor函数根据当前vue文件的code代码字符串生成一个descriptor对象,简化后的createDescriptor函数代码如下:
const cache = new Map();
function createDescriptor(
filename,
source,
{ root, isProduction, sourceMap, compiler, template }
) {
const { descriptor, errors } = compiler.parse(source, {
filename,
sourceMap,
templateParseOptions: template?.compilerOptions,
});
const normalizedPath = slash(path.normalize(path.relative(root, filename)));
descriptor.id = getHash(normalizedPath + (isProduction ? source : ""));
cache.set(filename, descriptor);
return { descriptor, errors };
}
首先调用compiler.parse方法根据当前vue文件的code代码字符串生成一个descriptor对象,此时的descriptor对象主要有三个属性template、scriptSetup、style,分别对应的是vue文件中的<template>模块、<template setup>模块、<style>模块。
然后调用getHash函数给descriptor对象生成一个id属性,getHash函数代码如下:
import { createHash } from "node:crypto";
function getHash(text) {
return createHash("sha256").update(text).digest("hex").substring(0, 8);
}
从上面的代码可以看出id是根据vue文件的路径调用node的createHash加密函数生成的,这里生成的id就是scoped生成的自定义属性data-v-x中的x部分。
然后在createDescriptor函数中将生成的descriptor对象缓存起来,关于descriptor对象的处理就这么多了。
接着在transformMain函数中会分别以descriptor对象为参数执行genTemplateCode、genScriptCode、genStyleCode函数,分别得到编译后的render函数、编译后的js代码、编译后的style代码。
编译后的render函数如下图:
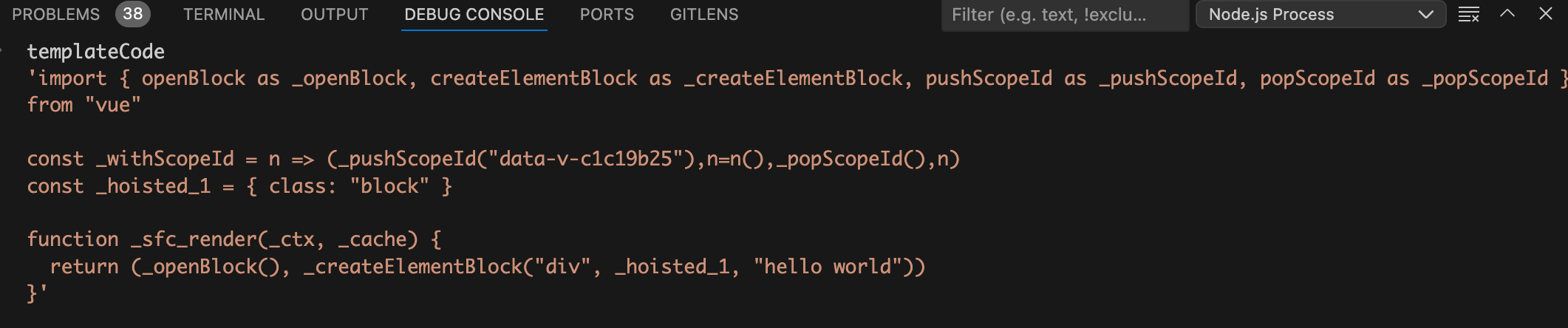
从上图中可以看到template模块已经编译成了render函数
编译后的js代码如下图:

从上图中可以看到script模块已经编译成了一个名为_sfc_main的对象,因为我们这个demo中script模块没有代码,所以这个对象是一个空对象。
编译后的style代码如下图:

从上图中可以看到style模块已经编译成了一个import语句。
最后就是使用换行符\n将templateCode、scriptCode、stylesCode拼接起来就是vue文件编译后的js文件啦,如下图:
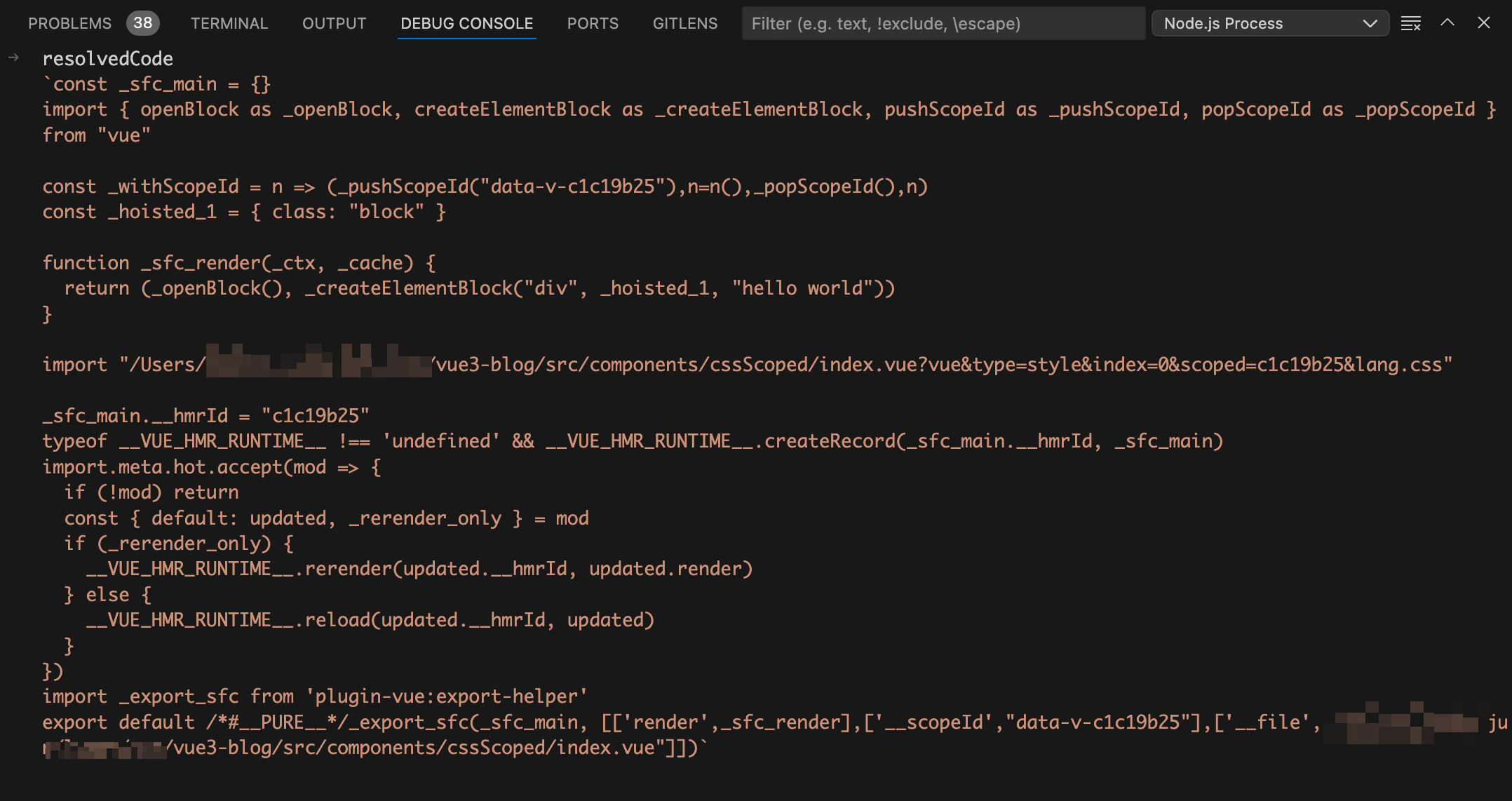
想必细心的同学已经发现有地方不对啦,这里的style模块编译后是一条import语句,并不是真正的css代码。这条import语句依然还是import导入的index.vue文件,只是加了一些额外的query参数。
?vue&type=style&index=0&lang.css:这个query参数表明当前import导入的是vue文件的css部分。
还记得我们前面讲过的transform钩子函数吗?vite每解析一个模块都会执行一次transform钩子函数,这个import导入vue文件的css部分,当然也会触发transform钩子函数的执行。
第二次执行transform钩子函数
当在浏览器中执行vue文件编译后的js文件时会触发import "/Users/xxx/index.vue?vue&type=style&index=0&lang.css"语句的执行,导致再次执行transform钩子函数。
transform钩子函数代码如下:
function transform(code, id, opt) {
const { filename, query } = parseVueRequest(id);
if (!query.vue) {
return transformMain(
code,
filename,
options.value,
this,
ssr,
customElementFilter.value(filename)
);
} else {
const descriptor = getDescriptor(filename);
if (query.type === "style") {
return transformStyle(
code,
descriptor,
Number(query.index || 0),
options.value
);
}
}
}
由于此时的query中是有vue字段,所以!query.vue的值为false,这次代码就不会走进transformMain函数中了。在else代码在先执行getDescriptor函数拿到descriptor对象,getDescriptor函数代码如下:
function getDescriptor(filename) {
const _cache = cache;
if (_cache.has(filename)) {
return _cache.get(filename);
}
}
我们在第一次执行transformMain函数的时候会去执行createDescriptor函数,他的作用是根据当前vue文件的code代码字符串生成一个descriptor对象,并且将这个descriptor对象缓存起来了。在getDescriptor函数中就是将缓存的descriptor对象取出来。
由于query中有type=style,所以代码会走到transformStyle函数中。
transformStyle函数
接着将断点走进transformStyle函数,代码如下:
async function transformStyle(code, descriptor, index, options) {
const block = descriptor.styles[index];
const result = await options.compiler.compileStyleAsync({
...options.style,
filename: descriptor.filename,
id: `data-v-${descriptor.id}`,
source: code,
scoped: block.scoped,
});
return {
code: result.code,
};
}
从上面的代码可以看到transformStyle函数依然不是干活的地方,而是调用的@vue/compiler-sfc包暴露出的compileStyleAsync函数。
在调用compileStyleAsync函数的时候有三个参数需要注意:source、id和scoped。
source字段的值为code,值是当前css代码字符串。
id字段的值为data-v-${descriptor.id},是不是觉得看着很熟悉?没错他就是使用scoped后vue帮我们自动生成的html自定义属性data-v-x和css选择属性选择器[data-v-x]。
其中的descriptor.id就是在生成descriptor对象时根据vue文件路径加密生成的id。
scoped字段的值为block.scoped,而block的值为descriptor.styles[index]。由于一个vue文件可以写多个style标签,所以descriptor对象的styles属性是一个数组,分包对应多个style标签。我们这里只有一个style标签,所以此时的index值为0。block.scoped的值为style标签上面是否有使用scoped。
直到进入compileStyleAsync函数之前代码其实一直都还在@vitejs/plugin-vue包中执行,真正干活的地方是在@vue/compiler-sfc包中。
@vue/compiler-sfc
接着将断点走进compileStyleAsync函数,代码如下:
function compileStyleAsync(options) {
return doCompileStyle({
...options,
isAsync: true,
});
}
从上面的代码可以看到实际干活的是doCompileStyle函数。
doCompileStyle函数
接着将断点走进doCompileStyle函数,在我们这个场景中简化后的doCompileStyle函数代码如下:
import postcss from "postcss";
function doCompileStyle(options) {
const {
filename,
id,
scoped = false,
postcssOptions,
postcssPlugins,
} = options;
const source = options.source;
const shortId = id.replace(/^data-v-/, "");
const longId = `data-v-${shortId}`;
const plugins = (postcssPlugins || []).slice();
if (scoped) {
plugins.push(scopedPlugin(longId));
}
const postCSSOptions = {
...postcssOptions,
to: filename,
from: filename,
};
let result;
try {
result = postcss(plugins).process(source, postCSSOptions);
return result.then((result) => ({
code: result.css || "",
// ...省略
}));
} catch (e: any) {
errors.push(e);
}
}
在doCompileStyle函数中首先使用const定义了一堆变量,我们主要关注source和longId。
其中的source为当前css代码字符串,longId为根据vue文件路径加密生成的id,值的格式为data-v-x。他就是使用scoped后vue帮我们自动生成的html自定义属性data-v-x和css选择属性选择器[data-v-x]。
接着就是判断scoped是否为true,也就是style中使用有使用scoped。如果为true,就将scopedPlugin插件push到plugins数组中。从名字你应该猜到了这个plugin插件就是用于处理css scoped的。
最后就是执行result = postcss(plugins).process(source, postCSSOptions)拿到经过postcss转换编译器处理后的css。
可能有的小伙伴对postcss不够熟悉,我们这里来简单介绍一下。
postcss 是 css 的 transpiler(转换编译器,简称转译器),它对于 css 就像 babel 对于 js 一样,能够做 css 代码的分析和转换。同时,它也提供了插件机制来做自定义的转换。
在我们这里主要就是用到了postcss提供的插件机制来完成css scoped的自定义转换,调用postcss的时候我们传入了source,他的值是style模块中的css代码。并且传入的plugins插件数组中有个scopedPlugin插件,这个自定义插件就是vue写的用于处理css scoped的插件。
在执行postcss对css代码进行转换之前我们在debug终端来看看此时的css代码是什么样的,如下图:
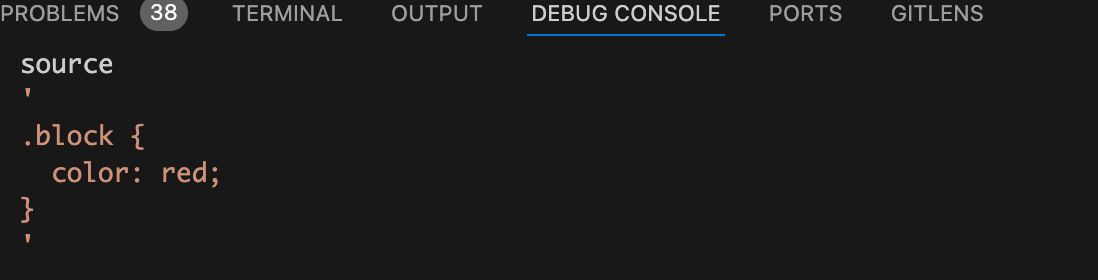
从上图可以看到此时的css代码还是和我们源代码是一样的,并没有css选择属性选择器[data-v-x]
scopedPlugin插件
scopedPlugin插件在我们这个场景中简化后的代码如下:
const scopedPlugin = (id = "") => {
return {
postcssPlugin: "vue-sfc-scoped",
Rule(rule) {
processRule(id, rule);
},
// ...省略
};
};
这里的id就是我们在doCompileStyle函数中传过来的longId,也就是生成的css选择属性选择器[data-v-x]中的data-v-x。
在我们这个场景中只需要关注Rule钩子函数,当postcss处理到选择器开头的规则就会走到Rule钩子函数。
我们这里需要在使用了scoped后给css选择器添加对应的属性选择器[data-v-x],所以我们需要在插件中使用Rule钩子函数,在处理css选择器时手动给选择器后面塞一个属性选择器[data-v-x]。
给Rule钩子函数打个断点,当postcss处理到我们代码中的.block时就会走到断点中。在debug终端看看rule的值,如下图:
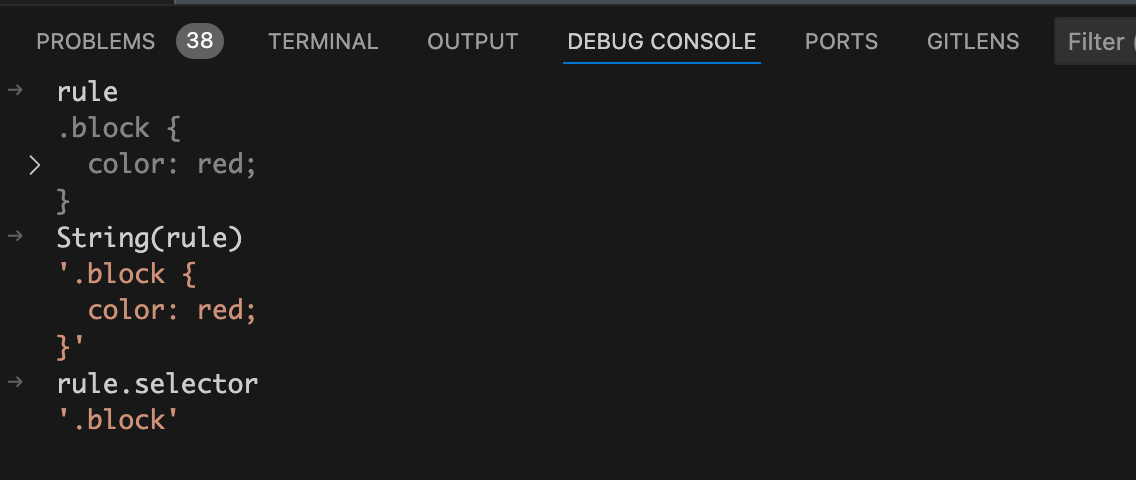
从上图中可以看到此时rule.selector的值为.block,是一个class值为block的类选择器。
processRule函数
将断点走进processRule函数中,在我们这个场景中简化后的processRule函数代码如下:
import selectorParser from "postcss-selector-parser";
function processRule(id: string, rule: Rule) {
rule.selector = selectorParser((selectorRoot) => {
selectorRoot.each((selector) => {
rewriteSelector(id, selector, selectorRoot);
});
}).processSync(rule.selector);
}
前面我们讲过rule.selector的值为.block,通过重写rule.selector的值可以将当前css选择器替换为一个新的选择器。在processRule函数中就是使用postcss-selector-parser来解析一个选择器,进行处理后返回一个新的选择器。
processSync方法的作用为接收一个选择器,然后在回调中对解析出来的选择器进行处理,最后将处理后的选择器以字符串的方式进行返回。
在我们这里processSync方法接收的选择器是字符串.block,经过回调函数处理后返回的选择器字符串就变成了.block[data-v-c1c19b25]。
我们接下来看selectorParser回调函数中的代码,在回调函数中会使用selectorRoot.each去遍历解析出来的选择器。
为什么这里需要去遍历呢?
答案是css选择器可以这样写:.block.demo,如果是这样的选择器经过解析后,就会被解析成两个选择器,分别是.block和.demo。
在each遍历中会调用rewriteSelector函数对当前选取器进行重写。
rewriteSelector函数
将断点走进rewriteSelector函数,在我们这个场景中简化后的代码如下:
function rewriteSelector(id, selector) {
let node;
const idToAdd = id;
selector.each((n) => {
node = n;
});
selector.insertAfter(
node,
selectorParser.attribute({
attribute: idToAdd,
value: idToAdd,
raws: {},
quoteMark: `"`,
})
);
}
在rewriteSelector函数中each遍历当前selector选择器,给node赋值。将断点走到each遍历之后,我们在debug终端来看看selector选择器和node变量。如下图:
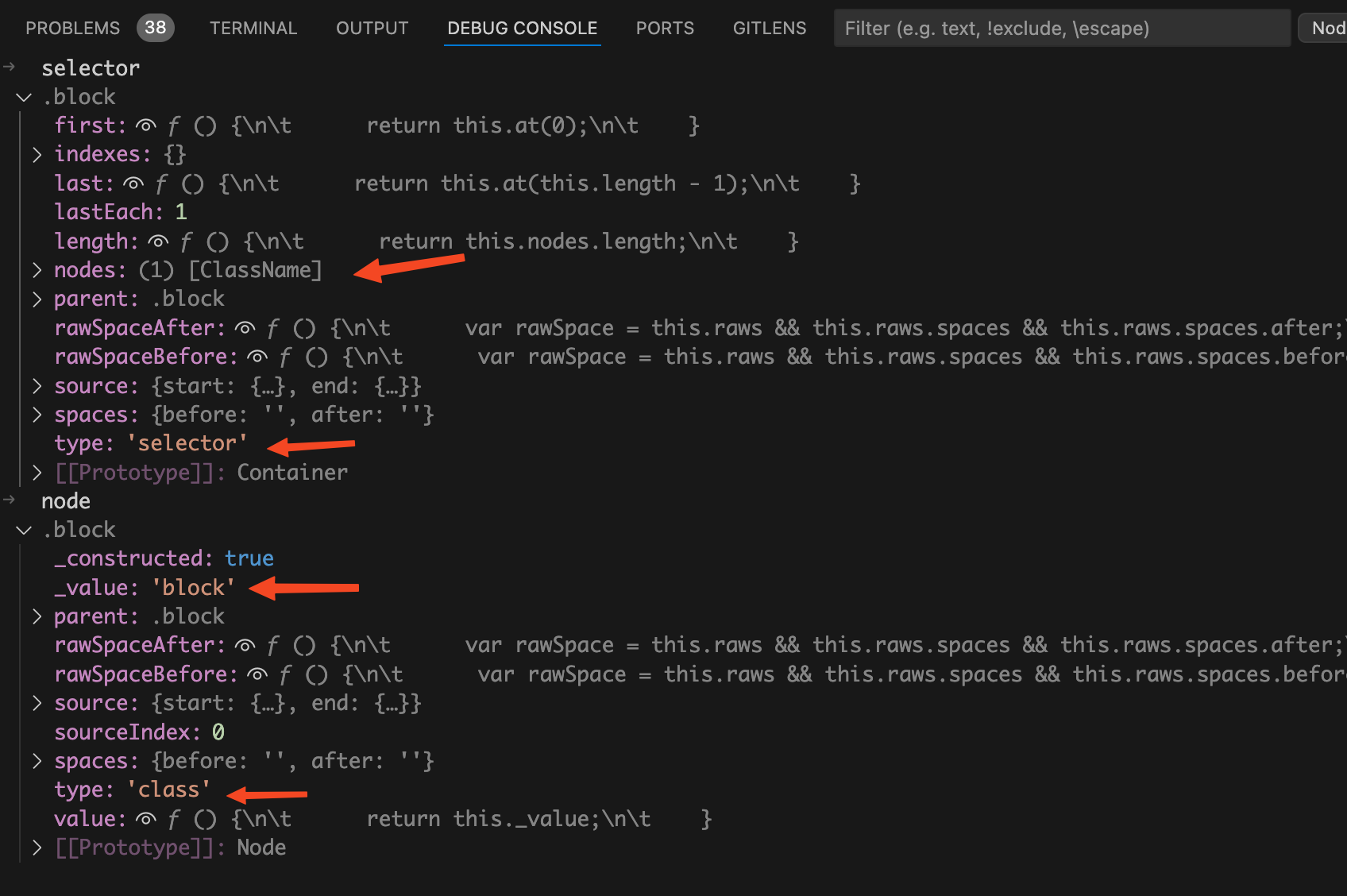
在这里selector是container容器,node才是具体要操作的选择器节点。
比如我们这里要执行的selector.insertAfter方法就是在selector容器中在一个指定节点后面去插入一个新的节点。这个和操作浏览器DOM API很相似。
我们再来看看要插入的节点,selectorParser.attribute函数的作用是创建一个attribute属性选择器。在我们这里就是创建一个[data-v-x]的属性选择器,如下图:

所以这里就是在.block类选择器后面插入一个[data-v-c1c19b25]的属性选择器。
我们在debug终端来看看执行insertAfter函数后的selector选择器,如下图:

将断点逐层走出,直到processRule函数中。我们在debug终端来看看此时被重写后的rule.selector字符串的值是什么样的,如下图

原来rule.selector的值为.block,通过重写rule.selector的值可以将.block类选择器替换为一个新的选择器,而这个新的选择器是在原来的.block类选择器后面再塞一个[data-v-c1c19b25]属性选择器。
总结
这篇文章我们讲了当使用scoped后,vue是如何给组件内CSS选择器添加对应的属性选择器[data-v-x]。主要分为两部分,分别在两个包里面执行。
第一部分为在
@vitejs/plugin-vue包内执行。首先会根据当前vue文件的路径进行加密算法生成一个id,这个id就是添加的属性选择器
[data-v-x]中的x。然后就是执行
transformStyle函数,这个transformStyle并不是实际干活的地方,他调用了@vue/compiler-sfc包的compileStyleAsync函数。并且传入了id、code(css代码字符串)、scoped(是否在style中使用scoped)。
第二部分在
@vue/compiler-sfc包执行。compileStyleAsync函数依然不是实际干活的地方,而是调用了doCompileStyle函数。在
doCompileStyle函数中,如果scoped为true就向plugins数组中插入一个scopedPlugin插件,这个是vue写的postcss插件,用于处理css scoped。然后使用postcss转换编译器对css代码进行转换。当
postcss处理到选择器开头的规则就会走到scopedPlugin插件中的Rule钩子函数中。在Rule钩子函数中会执行processRule函数。在
processRule函数中会使用postcss-selector-parser包将当前选择器替换为一个新的选择器,新的选择器和原来的选择器的区别是在后面会添加一个属性选择器[data-v-x]。其中的x就是根据当前vue文件的路径进行加密算法生成的id。
在下一篇文章中我们会讲vue是如何给html元素增加自定义属性data-v-x。
关注公众号:【前端欧阳】,给自己一个进阶vue的机会

掉了两根头发后,我悟了!vue3的scoped原来是这样避免样式污染(上)的更多相关文章
- 掉了10根头发都无法解决的数学题,python帮你完美解答
本来这个周末过得开开心心,结果为了解一道数学题薅掉了一把头发...整整10根! 而且还是一道小学数学题!!! 到底是什么题呢?大家看看吧 这不就是一道逻辑题嘛! 先假如丁错,则甲乙丙对,此时最小的ab ...
- MT【168】还是两根法
设二次函数$f(x)=ax^2+bx+c(a>0)$,方程$f(x)=x$的两根$x_1,x_2$满足$0<x_1<x_2<\dfrac{1}{a}$,(Ⅰ)当$x\in(0, ...
- 9.11排序与查找(一)——给定两个排序后的数组A和B,当中A的末端有足够的缓冲空间容纳B。将B合并入A并排序
/** * 功能:给定两个排序后的数组A和B,当中A的末端有足够的缓冲空间容纳B.将B合并入A并排序. */ /** * 问题:假设将元素插入数组A的前端,就必须将原有的元素向后移动,以腾出空间. ...
- JS函数 编程练习 使用javascript代码写出一个函数:实现传入两个整数后弹出较大的整数。
编程练习 使用javascript代码写出一个函数:实现传入两个整数后弹出较大的整数. 任务 第一步: 编写代码完成一个函数的定义吧. 第二步: 我们来补充函数体中的控制语句,完成函数功能吧. 提示: ...
- 安装两个JDK后配置环境变量没用?
在实际开发中,由于项目的需要,可能JDK的版本是不同的.比如我们前一个项目所需JDK版本是1.6的,项目完成后,下一个项目JDK版本又是需要1.7的,为了防止由于切换项目我们需要频繁的安装卸载JDK, ...
- 当装了两个tomcat后,如何修改tomcat端口
链接地址:http://blog.csdn.net/alongwilliam/article/details/8199974 以前只知道当tomcat端口号冲突了如何修改tomcat默认的8080端口 ...
- sql 两表查询后 更新某表中部分字段
这是上一个sql更新某表字段的一个延伸,在更新表数据时,实际上会有多表数据查询场景,查询后,只需要更新某一个表中的数据,以下提供两个方法, 第一种使用update 两表查询 update api_ma ...
- 两个月后才更新一篇。。。。LIB和DLL的差别
共同拥有两种库: 一种是LIB包括了函数所在的DLL文件和文件里函数位置的信息(入口).代码由执行时载入在进程空间中的DLL提供,称为动态链接库dynamic link library. 一种是 ...
- 如何将EXCEL两列比较后不重复的数据复制到另一列上
Q1:我有两列数据,需要做重复性比较,比较完后需要将不重复的数据提取出来自成一列,请问该如何操作? 假如你要比较A列与B列数据是否重复,应该有三种结果(即AB皆有,A有B无,B有A无),可在C列存放A ...
- 通过两根RS232连接两台电脑
把RS232的有5脚那边放下面,最左边是GND,第二三是TXD和RXD,两个RS232反接,然后两个usb连接电脑就可以通信了
随机推荐
- 五:大数据架构回顾-LambdaPlus架构
Blink是阿里云在 Apache Flink 基础上深度改进的实时计算平台,Blink旨在将流处理和批处理统一,实现了全新的 Flink SQL 技术栈,在功能上,Blink支持现在标准 SQL 几 ...
- Zeppelin未授权访问 getshell
Zeppelin未授权访问 getshell 1.漏洞简介 Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的notebook.Zeppelin提供了数据可视化的框架. Zepp ...
- 一键自动化博客发布工具,用过的人都说好(segmentfault篇)
segmentfault是我在这些平台中看过界面最为简洁的博客平台了. 今天就以segmentfault为例,讲讲在blog-auto-publishing-tools中的实现原理. 前提条件 前提条 ...
- linux文本三剑客之grep及正则表达式详解
linux文本三剑客之grep及正则表达式详解 目录 linux文本三剑客之grep及正则表达式详解 1. grep命令详解 2. 正则表达式 2.1 基本正则表达式 2.2 扩展正则表达式 1. g ...
- 海康iSC综合安防平台-视频web插件调试
综合安防管理平台 视频WEB插件 1.demo_window_simple_playback.html.demo_window_simple_preview.html为简化版demo,可在此基础上开发 ...
- openstack虚拟机用keep alive添加的VIP,其它机器无法访问
neutron port-list |grep ipneutron port-update a7fbxxf6cc2 --allowed_address_pairs type=dict list=tru ...
- 我开源的H5商城2.0版本发布,强烈推荐
简介 waynboot-mall 是一套全部开源的 H5 商城项目,包含运营后台.H5 商城前台和后端接口三个项目 .实现了一套完整的商城业务,有首页展示.商品分类.商品详情.sku 详情.商品搜索. ...
- [渗透测试] HTB_Surveillance WriteUp [上]
靶机:Surveillance (from Hack The Box) 工具:Kali Linux 目标:拿到user和root的一串32位hex字符串 ## 配置hosts 环境启动后,要设置 ...
- ef.core 事务不回滚的我遇到的一种情况分享
比如有几个Repository:_storeRep,_inventoryRep,_storeItemRep.基类封装有BeginTransaction(): using(var trans=_st ...
- 8.15考试总结(NOIP模拟40)[送花·星空·零一串]
我只对现实世界绝望过,却未对自己绝望过! T1 送花 解题思路 线段树维护序列. 我们暴力枚举右端点,用线段树搞出当前右端点的最优的左端点的值. 假设当前扫到的右端点是 r ,颜色是 col. 这种颜 ...