大数据(3)---HDFS客户端命令及java连接
一、参数设置
之前有说到HDFS的备份数量和切块大小都是可以配置的,默认是备份3,切块大小默认128M
文件的切块大小和存储的副本数量,都是由客户端决定!
所谓的由客户端决定,是通过客户端机器上面的配置参数来定
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
更多参数详见:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
因此我们只需要在客户端的机器上面hdfs-site.xml中进行配置:
<property> <name>dfs.blocksize</name> <value>64m</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property>
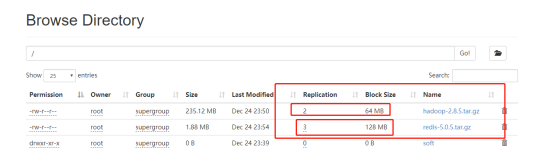
我们在两个客户端进行上传,一个客户端修改为上述配置,查看上传文件信息
可以看见一个文件是3和128m,另外一个是2和64m
二、客户端命令行操作
1、上传文件到hdfs中
hadoop fs -put /本地文件 /aaa
2、下载文件到客户端本地磁盘
hadoop fs -get /hdfs中的路径 /本地磁盘目录
3、在hdfs中创建文件夹
hadoop fs -mkdir -p /aaa/xxx
4、移动hdfs中的文件(更名)
hadoop fs -mv /hdfs的路径1 /hdfs的另一个路径2
复制hdfs中的文件到hdfs的另一个目录
hadoop fs -cp /hdfs路径_1 /hdfs路径_2
5、删除hdfs中的文件或文件夹
hadoop fs -rm -r /aaa
6、查看hdfs中的文本文件内容
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt
更多命令:https://www.cnblogs.com/houkai/p/3848089.html
三、java连接
1.首先需要搭建本地开发环境,因为本地启动应用的时候会从hadoop里面回去调用c的函数操作本地文件系统,因此我们需要在本地配置hadoop的环境信息。
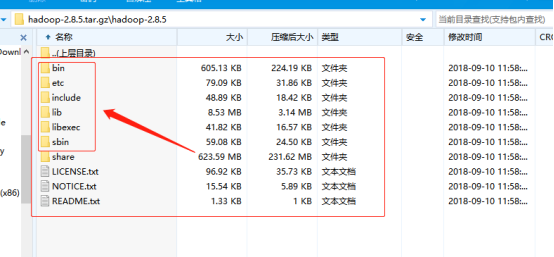
将hadoop压缩包解压出来,留下脚本所在的目录就可以了,其他的一些目录可以丢掉,留下下图圈上的即可
配置hadoop环境变量,将bin目录的里面的文件替换问windows的脚本文件。

windows的脚本文件去哪儿弄呢,可以自己去编译,也可以找别人编译好的:
https://github.com/steveloughran/winutils
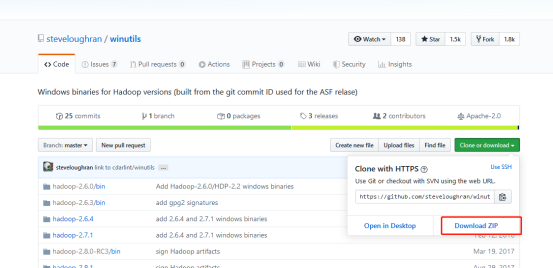
这是别人已经编译好的windows脚本,换到自己的bin目录里面去就行了。
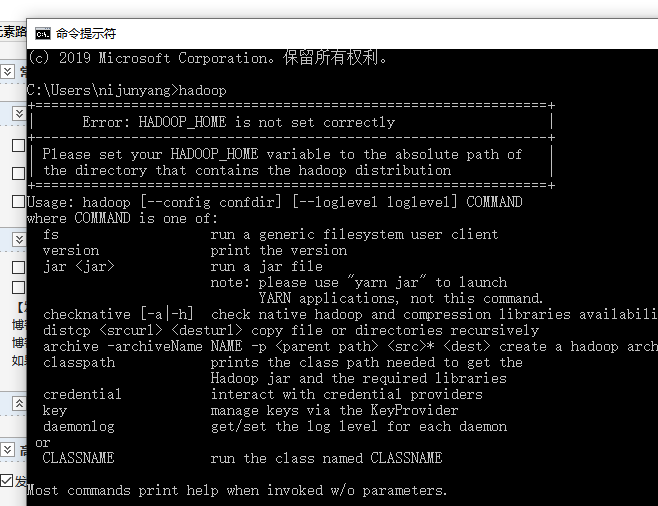
配置好之后检查下能否识别hadoop指令
2. 准备完毕就可以导包撸代码了
导包:版本最好和自己安装hadoop版本一致
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
上代码:
package com.nijunyang.hadoop.hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.Before;
import org.junit.Test; import java.net.URI;
import java.util.Arrays; /**
* Description:
* Created by nijunyang on 2019/12/25 20:26
*/
public class HDFSDemo { FileSystem fs; @Before
public void init() throws Exception{ URI uri = new URI("hdfs://nijunyang68:9000/");
/**
* Configuration 构造会从 classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等文件
* 也可使用set方法进行自己设置值
* https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
*/
Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
// 切块的规格大小:32M
conf.set("dfs.blocksize", "32m");
fs = FileSystem.get(uri, conf, "root");
} @Test
public void test1() throws Exception {
// 上传一个文件到HDFS中
fs.copyFromLocalFile(new Path("E:/安装包/linux/jdk-8u191-linux-x64.tar.gz"), new Path("/soft/"));
//下载到本地
fs.copyToLocalFile(new Path("/soft/jdk-8u191-linux-x64.tar.gz"), new Path("f:/"));
//在hdfs内部移动文件/修改名称
fs.rename(new Path("/redis-5.0.5.tar.gz"), new Path("/redis5.0.5.tar.gz"));
//在hdfs中创建文件夹
fs.mkdirs(new Path("/xx/yy/zz"));
//在hdfs中删除文件或文件夹
fs.delete(new Path("/xx/yy/zz"), true);
//查询hdfs指定目录下的文件信息
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true);
while(iter.hasNext()){
LocatedFileStatus status = iter.next();
System.out.println("文件全路径:"+status.getPath());
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("块信息:"+ Arrays.toString(status.getBlockLocations()));
System.out.println("--------------------------------");
}
//查询hdfs指定目录下的文件和文件夹信息
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus status:listStatus){
System.out.println("文件全路径:"+status.getPath());
System.out.println(status.isDirectory()?"这是文件夹":"这是文件");
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("--------------------------------");
}
fs.close();
}
}
简单来说java代码也就是一个客户端访问,所以说配置信息都可以塞到Configuration里面去。
大数据(3)---HDFS客户端命令及java连接的更多相关文章
- 大数据学习——hdfs客户端操作
package cn.itcast.hdfs; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configur ...
- 大数据学习——hdfs客户端流式操作代码的实现
package cn.itcast.bigdata.hdfs.diceng; import org.apache.hadoop.conf.Configuration; import org.apach ...
- 大数据自学3-Windows客户端DbVisualizer/SQuirreL配置连接hive
前面已经学习了将数据从Sql Server导入到Hive DB,并在Hue的Web界面可以查询,接下来是配置客户端工具直接连Hive数据库,常用的有DbVisualizer.SQuirreL SQL ...
- hdfs shell命令及java客户端编写
一. hdfs shell命令 可以通过hadoop fs 查看所有的shell命令及其用法. 传文件到hdfs: hadoop fs -put /home/koushengrui/Downloads ...
- FusionInsight大数据开发---HDFS应用开发
HDFS应用开发 HDFS(Dadoop Distributed File System) HDFS概述 高容错性 高吞吐量 大文件存储 HDFS架构包含三部分 Name Node DataNode ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 老李分享:大数据测试之HDFS文件系统
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- 大数据(1)---大数据及HDFS简述
一.大数据简述 在互联技术飞速发展过程中,越来越多的人融入互联网.也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了.比如淘宝,每天的活跃用户 ...
- 大数据面试——HDFS
一.Hadoop1.0 与 Hadoop2.0的区别
随机推荐
- 【GKCTF 2020】ez三剑客
[GKCTF 2020]ez三剑客 收获 gopher协议SSRF 多利用github搜索已存在的函数漏洞 CMS审计的一些方法 1. ezweb 打开题目给了一个输入框,能够向输入的url发送htt ...
- 《深入理解 FFmpeg》第一章彩色插图汇总
layout: post title: "<深入理解 FFmpeg>第一章彩色插图" tags: - "FFmpeg" 这是<深入理解 FFm ...
- LLM面面观之LLM复读机问题及解决方案
1. 背景 关于LLM复读机问题,本qiang~在网上搜刮了好几天,结果是大多数客观整理的都有些支离破碎,不够系统. 因此,本qiang~打算做一个相对系统的整理,包括LLM复读机产生的原因以及对应的 ...
- 'parent.relativePath' of POM com.qbb:log_record_elegant:1.0-SNAPSHOT points at com.qbb:qiu_code instead of org.springframework.boot:spring-boot-starter-parent
完整的错误: 'parent.relativePath' of POM com.qbb:log_record_elegant:1.0-SNAPSHOT (F:\QbbCode\qiu_code\log ...
- 10个必备的 async/await 工具函数
| 当谈到异步编程时,async/await是JavaScript中常用的功能之一.下面是10个常用的await和async函数示例,以及对它们的代码用途的解析: 1.异步获取数据 async fun ...
- 数字孪生为何通过融合GIS系统能够更好地助力智慧城市发展?
随着城市化进程的不断加速,智慧城市建设已成为许多城市发展的重要方向.在智慧城市中,数字孪生技术和GIS系统的融合,为城市发展带来了全新的可能性和机遇.数字孪生是一种将物理世界和数字世界相结合的技术,通 ...
- iMessage群发,iMessage群发基础知识,iMessage群发源代码分享
在当今的数字化时代,即时通讯已经成为我们日常生活和工作中不可或缺的一部分,其中,苹果的iMessage服务因其出色的用户体验和无缝的设备间同步而备受用户喜爱. 然而,你是否想过如何利用iMessage ...
- 从零玩转文件上传之七牛云-qiniufileupload
title: 从零玩转文件上传之七牛云 date: 2022-03-27 02:21:00.478 updated: 2022-04-10 14:13:35.426 url: https://www. ...
- java桌面小闹钟
写了个桌面的小闹钟,在运行环境可以编译,但是打包成jar文件,想用批处理命令直接调用报错"找不到或无法加载主类". 需求 为防止整天久坐,编写一个桌面闹钟.该闹钟功能很简单,一个小 ...
- 文心一言 VS 讯飞星火 VS chatgpt (38)-- 算法导论5.4 2题
二.假设我们将球投入到b个箱子里,直到某个箱子中有两个球.每一次投掷都是独立的并且每个球落入任何箱子的机会均等.请问投球次数期望是多少? 文心一言: 这是一个典型的鸽巢原理(Pigeonhole Pr ...