LLaMA 3 源码解读-大语言模型5
本来不是很想写这一篇,因为网上的文章真的烂大街了,我写的真的很有可能没别人写得好。但是想了想,创建这个博客就是想通过对外输出知识的方式来提高自身水平,而不是说我每篇都能写得有多好多好然后吸引别人来看。那作为对整个合集内容的完善,这篇博客会解析现在最火的LLaMA3的模型架构,搞清楚现在的LLM都是啥样的。
事先说明,LlaMA 3 相较于LLaMA 2 在网络架构上没有改进。用知乎网友的话说,“llama3的发布,更强调了数据工程的重要:模型架构不变,更多的数据量和更高数据质量能够带来明显模型效果提升”。但是仔细看看一个LLM的源码,对于我这种初学者,还是非常有必要的。
还有就是,这个博客解析的源码是d6e09315954d1a547bf45e37269978c049e73d33这个版本的。如果后面Meta更新的部分代码导致和这篇博客内容对不上,你可以先翻阅这个版本的源码。如果还有什么解决不了的,可以在这篇博客下面给我留言,我们共同学习共同进步。
Llama类:起步
Llama.build与如何看源码
我们通过llama3的ReadMe,找到了这个demo,demo通过
from llama import Dialog, Llama
generator = (ckpt_dir, tokenizer_path, max_seq_len, max_batch_size)
results = generator.chat_completion(dialogs, max_gen_len, temperature, top_p)
完成对话。它先调用了 Llama.build,再对返回的对象调用了generator.chat_completion完成对话的功能;导入的库是llama。 进而关注到repo下面的llama文件夹,所以会先看一看文件夹下面的__init__.py:
from .generation import Llama
from .model import ModelArgs, Transformer
from .tokenizer import Dialog, Tokenizer
所以demo调用的 Llama.build在 .generation里面。顺藤摸瓜找到:
class Llama:
@staticmethod
def build(
ckpt_dir: str,
tokenizer_path: str,
max_seq_len: int,
max_batch_size: int,
model_parallel_size: Optional[int] = None,
seed: int = 1,
) -> "Llama":
"""
Build a Llama instance by initializing and loading a model checkpoint.
Args:
ckpt_dir (str): 模型检查点文件的路径
tokenizer_path (str): 模型tokenizer文件路径.
max_seq_len (int): Maximum sequence length for input text.
max_batch_size (int): Maximum batch size for inference.
model_parallel_size (Optional[int], optional): Number of model parallel processes.
If not provided, it's determined from the environment. Defaults to None.
Returns:
Llama: An instance of the Llama class with the loaded model and tokenizer.
"""
# 这里首先是一些模型并行设置
if not torch.distributed.is_initialized():
torch.distributed.init_process_group("nccl")
if not model_parallel_is_initialized():
if model_parallel_size is None:
model_parallel_size = int(os.environ.get("WORLD_SIZE", 1))
initialize_model_parallel(model_parallel_size)
# 多机训练/推理一个模型的话,每个机器都会有个rank。这里就是配置这个rank的。
local_rank = int(os.environ.get("LOCAL_RANK", 0))
torch.cuda.set_device(local_rank)
# 随机种子
torch.manual_seed(seed)
# 设置输出只在一台设备上进行
if local_rank > 0:
sys.stdout = open(os.devnull, "w")
# 终于到加载模型相关的代码了
start_time = time.time()
checkpoints = sorted(Path(ckpt_dir).glob("*.pth"))
# 检查模型检查点文件的数量是否合乎要求
assert len(checkpoints) > 0, f"no checkpoint files found in {ckpt_dir}"
assert model_parallel_size == len(
checkpoints
), f"Loading a checkpoint for MP={len(checkpoints)} but world size is {model_parallel_size}"
# 加载模型。多机运行时`get_model_parallel_rank()`返回的结果不一样,所以不需要写for循环。这里的思想有cuda编程那味了
ckpt_path = checkpoints[get_model_parallel_rank()]
checkpoint = torch.load(ckpt_path, map_location="cpu")
# TODO: 读取`params.json`并通过类`ModelArgs`加载进变量`model_args`。这个类我们待会讲
with open(Path(ckpt_dir) / "params.json", "r") as f:
params = json.loads(f.read())
model_args: ModelArgs = ModelArgs(
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
**params,
)
# TODO: 加载Tokenizer。Tokenizer我们待会讲
tokenizer = Tokenizer(model_path=tokenizer_path)
assert model_args.vocab_size == tokenizer.n_words
# 半精度相关
if torch.cuda.is_bf16_supported():
torch.set_default_tensor_type(torch.cuda.BFloat16Tensor)
else:
torch.set_default_tensor_type(torch.cuda.HalfTensor)
# TODO: 是的,llama3的模型主体就是这里的Transformer类。直接model.load_state_dict就能加载好权重。这个也待会讲
model = Transformer(model_args)
model.load_state_dict(checkpoint, strict=False)
print(f"Loaded in {time.time() - start_time:.2f} seconds")
# TODO: 到这里其实啥都加载完了,这里返回了个Llama类。
return Llama(model, tokenizer)
这段代码看下来逻辑很清晰,就是给我们留下了几个TODO,这些我们都会讲到。
ModelArgs类
我们首先看到ModelArgs类,这个类只用于保存一些参数,@dataclass装饰器就已经说明了一切:
@dataclass
class ModelArgs:
dim: int = 4096 # 模型维度
n_layers: int = 32 # 层数
n_heads: int = 32 # 头数
n_kv_heads: Optional[int] = None
vocab_size: int = -1 # 词汇表大小
multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2
ffn_dim_multiplier: Optional[float] = None
norm_eps: float = 1e-5
rope_theta: float = 500000
max_batch_size: int = 32
max_seq_len: int = 2048 # 序列长度
llama.__init__()
最后这一句return Llama(model, tokenizer),它实际上会调用Llama.__init__(),代码如下:
from llama.tokenizer import ChatFormat, Dialog, Message, Tokenizer
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
# TODO: ChatFormat类解析
self.formatter = ChatFormat(tokenizer)
是的,简单赋值就结束了。formatter这里用到的ChatFormat类我们一会随tokenizer一起解析。
Transformer类:Llama3模型架构详解
这一部分应该是被人关心得最多的部分了。
Transformer.__init__()
首先看模型初始化,这里就是设置了一堆类的属性。我们直接上代码,解析见代码注释:
from fairscale.nn.model_parallel.layers import (
ColumnParallelLinear,
RowParallelLinear,
VocabParallelEmbedding,
) # FairScale库的模块都是用于实现模型并行化的,不需要深究
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
# VocabParallelEmbedding类导入自fairscale,功能同`torch.nn.embedding`
self.tok_embeddings = VocabParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
# TODO: TransformerBlock
self.layers.append(TransformerBlock(layer_id, params))
# TODO: RMSNorm
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
# ColumnParallelLinear 相当于 `torch.nn.linear`
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
# TODO: precompute_freqs_cis
self.freqs_cis = precompute_freqs_cis(
params.dim // params.n_heads,
params.max_seq_len * 2,
params.rope_theta,
)
RMSNorm
RMSNorm是均值为0的LayerNorm:
\bar{a}_i=\frac{a_i}{R M S(a)} g_i \text{ where }
R M S(a)=\sqrt{\frac{1}{n} \sum_{i=1}^n a_i{ }^2}
\end{equation}
\]
注:layerNorm为 $$\begin{equation}\bar{a}i=\frac{a_i - \mu }{ \sigma } g_i \text{ where } \mu=\frac{1}{n} \sum^n {a_i }
\text{ and } \sigma=\sqrt{\frac{1}{n} \sum_{i=1}^n {(a_i - \mu)}^2} \end{equation} $$
用代码实现出来是这个样子的:
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim)) # 初始化为1的可学习参数
def _norm(self, x):
# torch.rsqrt: 平方根的倒数,这里用于计算标准差的倒数
# x.pow(2).mean(-1, keepdim=True): 沿着倒数第一维计算平方并求平均
# a_i * 元素平方的均值取平方根后再取倒数 + 无穷小量
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
作者认为这种模式在简化了Layer Norm的同时,可以在各个模型上减少约 7%∼64% 的计算时间
旋转位置编码RoPE
该部分内容参考了 苏剑成的博客。苏剑成是RoPE的发明者。
旋转位置编码通过绝对位置编码的方式实现相对位置编码。假设通过下述运算来给 \(q,k\) 添加绝对位置信息:
分别为 \(q,k\) 设计操作 \(\boldsymbol{f}(\cdot, m),\boldsymbol{f}(\cdot, n)\) ,使得经过该操作后,\(\tilde{\boldsymbol{q}}_m,\tilde{\boldsymbol{k}}_n\) 就带有了位置 \(m,n\) 的绝对位置信息。Attention的核心运算是内积,所以我们希望的内积的结果带有相对位置信息,因此假设存在恒等关系:
\]
解得:
\boldsymbol{f}(\boldsymbol{q}, m) = R_f (\boldsymbol{q}, m)e^{\text{i}\Theta_f(\boldsymbol{q}, m)}
= \Vert q\Vert e^{\text{i}(\Theta(\boldsymbol{q}) + m\theta)} = \boldsymbol{q} e^{\text{i}m\theta}\end{equation}
\]
可以写成:
\boldsymbol{f}(\boldsymbol{q}, m) =\begin{pmatrix}\cos m\theta & -\sin m\theta\\ \sin m\theta & \cos m\theta\end{pmatrix} \begin{pmatrix}q_0 \\ q_1\end{pmatrix}\end{equation}
\]
由于内积满足线性叠加性,因此任意偶数维的RoPE,我们都可以表示为二维情形的拼接,即:
\cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
\sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\
0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\
0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2-1} & -\sin m\theta_{d/2-1} \\
0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2-1} & \cos m\theta_{d/2-1} \\
\end{pmatrix}}_{\boldsymbol{\mathcal{R}}_m} \begin{pmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}\end{pmatrix}}\end{equation}
\]
我们便可以通过以下方式实现RoPE:
\end{pmatrix}\otimes\begin{pmatrix}\cos m\theta_0 \\ \cos m\theta_0 \\ \cos m\theta_1 \\ \cos m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_{d/2-1}
\end{pmatrix} + \begin{pmatrix}-q_1 \\ q_0 \\ -q_3 \\ q_2 \\ \vdots \\ -q_{d-1} \\ q_{d-2}
\end{pmatrix}\otimes\begin{pmatrix}\sin m\theta_0 \\ \sin m\theta_0 \\ \sin m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_{d/2-1}
\end{pmatrix}\end{equation}
\]
precompute_freqs_cis
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
# 计算词向量元素两两分组以后,每组元素对应的旋转角度
# torch.arange(0, dim, 2): 生成 [0,2,4...126]
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device, dtype=torch.float32) # t = [0,....end]
# torch.outer: torch.outer(a, b) = a^T * b
freqs = torch.outer(t, freqs) # freqs.shape = (t.len(),freqs.len()) #shape (end,dim//2)
# 根据角坐标生成复数向量
# torch.polar(abs,angle): abs*cos(angle) + abs*sin(angle)*j
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # freqs_cis.shape = (end,dim//2)
return freqs_cis
reshape_for_broadcast
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
# ndim为x的维度数, 此时应该为4
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
# (1, x.shape[1], 1, x.shape[-1])
return freqs_cis.view(*shape)
apply_rotary_emb
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""将xq和xk的最后一个维度进行复数运算,得到新的xq和xk"""
# xq.shape = [bsz, seqlen, self.n_local_heads, self.head_dim]
# xq_.shape = [bsz, seqlen, self.n_local_heads, self.head_dim//2 , 2]
# torch.view_as_complex用于将二维向量转换为复数域 torch.view_as_complex即([x,y]) -> (x+yj)
# 所以经过view_as_complex变换后xq_.shape = [bsz, seqlen, self.n_local_heads, self.head_dim//2]
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_) # freqs_cis.shape = (1,x.shape[1],1,x.shape[-1])
# xq_ 与freqs_cis广播哈达玛积
# [bsz, seqlen, self.n_local_heads, self.head_dim//2] * [1,seqlen,1,self.head_dim//2]
# torch.view_as_real用于将复数再转换回实数向量, 再经过flatten展平第4个维度
# [bsz, seqlen, self.n_local_heads, self.head_dim//2] ->[bsz, seqlen, self.n_local_heads, self.head_dim//2,2 ] ->[bsz, seqlen, self.n_local_heads, self.head_dim]
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
TransformerBlock类
这个类比较简单,只是一个transformer block。
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
"""初始化函数主要就是定义了transformer block的各个组件,包括自注意力机制和前馈神经网络。"""
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
# TODO: Attention
self.attention = Attention(args)
# TODO: FeedForward
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of, ffn_dim_multiplier=args.ffn_dim_multiplier,
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""这个函数是transformer block的前向传播函数,输入是x,start_pos,freqs_cis,mask,输出是out"""
# 这个函数的实现比较简单,首先对输入张量x进行自注意力机制计算,然后对计算结果进行残差连接和归一化,再通过前馈神经网络计算,最后再次进行残差连接和归一化。
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward(self.ffn_norm(h))
return out
Attention类
为了实现Group Query Attention,这里用到了一个函数repeat_kv,它的作用是将key和value的head维度重复n_rep次,以匹配query的head数。repeat_kv函数使用 expand 方法将输入张量在第四个维度上扩展 n_rep 次,并使用 reshape 方法将其调整为适当的形状
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
# 精简版Attention
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.wq = Linear(...)
self.wk = Linear(...)
self.wv = Linear(...)
self.freqs_cis = precompute_freqs_cis(dim, max_seq_len * 2)
def forward(self, x: torch.Tensor):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# attention 操作之前,应用旋转位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
#...
# 进行后续Attention计算
scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim)
scores = F.softmax(scores.float(), dim=-1)
output = torch.matmul(scores, xv) # (batch_size, seq_len, dim)
FeedForward类与SwiGLU激活函数
FeedForward类实现的是:
FFN_{swiGLU}(x, W, V, W_2)=(Swish1 (xW) \bigotimes xV)W_2
\end{equation}\]
使用的激活函数是SwiGLU,这里有:
\]
\]
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
): # 我们不妨跳过这个函数,太无聊了
...
def forward(self, x):
# w2 * silu(w1 * x) * w3
return self.w2(F.silu(self.w1(x)) * self.w3(x))
以下内容参考知乎
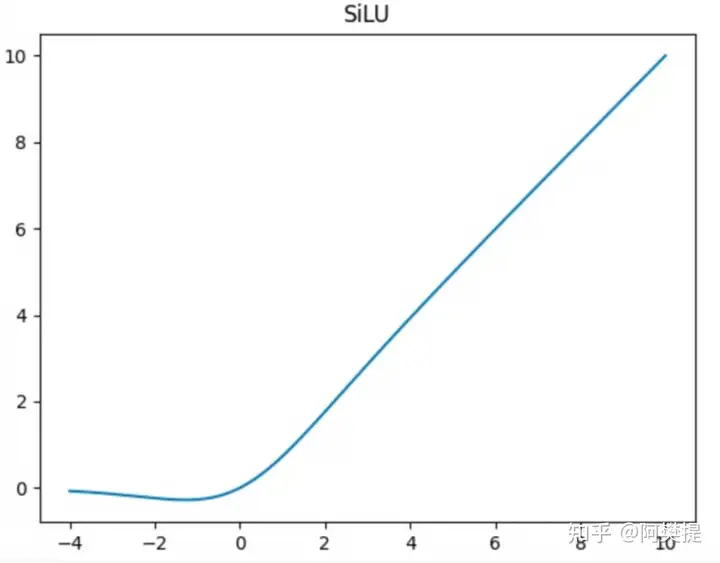
\(\beta = 1\) 时 \(swish(x)\)就是$silu(x) $
\]
函数图像如下:
Transformer.forward()
前向传播就是我们熟悉的 Transformer 前向传播了。
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape # 批大小和序列长度
h = self.tok_embeddings(tokens) # 词嵌入层进行嵌入,得到表示输入序列的张量h
self.freqs_cis = self.freqs_cis.to(h.device) # 将频率转换为与输入张量相同的设备
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen] # 从预计算的频率张量中提取频率
mask = None # 用于在自注意力机制中屏蔽不必要的位置的mask
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device) # 创建一个形状为(seqlen, seqlen)的张量,填充为负无穷
mask = torch.triu(mask, diagonal=1) # 上三角矩阵
mask = torch.hstack(
[torch.zeros((seqlen, start_pos), device=tokens.device), mask]
).type_as(h) # 将mask张量与全零张量水平拼接,以适应输入张量h的维度
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask) # 逐层进行transformer计算
h = self.norm(h) # 对输出张量进行归一化
output = self.output(h).float() # 输出层进行线性变换
return output
Tokenizer类
Tokenizer类主要调用tiktoken库,没啥好讲的。这里的函数大多是前面定义了一大堆东西,但是翻阅具体业务的时候发现其实还是在调库。
class Tokenizer:
"""
Tokenizing and encoding/decoding text using the Tiktoken tokenizer.
"""
special_tokens: Dict[str, int]
num_reserved_special_tokens = 256
pat_str = r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+" # noqa: E501
def __init__(self, model_path: str):
"""
Initializes the Tokenizer with a Tiktoken model.
Args:
model_path (str): The path to the Tiktoken model file.
"""
assert os.path.isfile(model_path), model_path
mergeable_ranks = load_tiktoken_bpe(model_path)
num_base_tokens = len(mergeable_ranks)
special_tokens = [
"<|begin_of_text|>", "<|end_of_text|>",
"<|start_header_id|>", "<|end_header_id|>", "<|eot_id|>", # end of turn
"<|reserved_special_token_0|>", "<|reserved_special_token_1|>",
"<|reserved_special_token_2|>", "<|reserved_special_token_3|>", "<|reserved_special_token_4|>",
] + [
f"<|reserved_special_token_{i}|>"
for i in range(5, self.num_reserved_special_tokens - 5)
]
self.special_tokens = {
token: num_base_tokens + i for i, token in enumerate(special_tokens)
}
self.model = tiktoken.Encoding(
name=Path(model_path).name, pat_str=self.pat_str,
mergeable_ranks=mergeable_ranks, special_tokens=self.special_tokens,
)
self.n_words: int = self.model.n_vocab
# BOS / EOS token IDs
self.bos_id: int = self.special_tokens["<|begin_of_text|>"]
self.eos_id: int = self.special_tokens["<|end_of_text|>"]
self.pad_id: int = -1
self.stop_tokens = {
self.special_tokens["<|end_of_text|>"],
self.special_tokens["<|eot_id|>"],
}
def encode(
self, s: str, *, bos: bool, eos: bool,
allowed_special: Union[Literal["all"], AbstractSet[str]] = set(),
disallowed_special: Union[Literal["all"], Collection[str]] = (),
) -> List[int]:
"""
Encodes a string into a list of token IDs.
Args:
s (str): The input string to be encoded.
bos (bool): Whether to prepend the beginning-of-sequence token.
eos (bool): Whether to append the end-of-sequence token.
allowed_tokens ("all"|set[str]): allowed special tokens in string
disallowed_tokens ("all"|set[str]): special tokens that raise an error when in string
Returns:
list[int]: A list of token IDs.
By default, setting disallowed_special=() encodes a string by ignoring
special tokens. Specifically:
- Setting `disallowed_special` to () will cause all text corresponding
to special tokens to be encoded as natural text (insteading of raising
an error).
- Setting `allowed_special` to "all" will treat all text corresponding
to special tokens to be encoded as special tokens.
"""
assert type(s) is str
# The tiktoken tokenizer can handle <=400k chars without pyo3_runtime.PanicException.
TIKTOKEN_MAX_ENCODE_CHARS = 400_000
# Here we iterate over subsequences and split if we exceed the limit of max consecutive non-whitespace or whitespace characters.
MAX_NO_WHITESPACES_CHARS = 25_000
substrs = (
substr
for i in range(0, len(s), TIKTOKEN_MAX_ENCODE_CHARS)
for substr in self._split_whitespaces_or_nonwhitespaces(
s[i : i + TIKTOKEN_MAX_ENCODE_CHARS], MAX_NO_WHITESPACES_CHARS
)
)
t: List[int] = []
for substr in substrs:
t.extend(
# 调用在这里
self.model.encode(
substr,
allowed_special=allowed_special,
disallowed_special=disallowed_special,
)
)
if bos:
t.insert(0, self.bos_id)
if eos:
t.append(self.eos_id)
return t
def decode(self, t: Sequence[int]) -> str:
"""
Decodes a list of token IDs into a string.
Args:
t (List[int]): The list of token IDs to be decoded.
Returns:
str: The decoded string.
"""
# Typecast is safe here. Tiktoken doesn't do anything list-related with the sequence.
return self.model.decode(cast(List[int], t))
@staticmethod
def _split_whitespaces_or_nonwhitespaces(
s: str, max_consecutive_slice_len: int
) -> Iterator[str]:
"""
Splits the string `s` so that each substring contains no more than `max_consecutive_slice_len`
consecutive whitespaces or consecutive non-whitespaces.
"""
current_slice_len = 0
current_slice_is_space = s[0].isspace() if len(s) > 0 else False
slice_start = 0
for i in range(len(s)):
is_now_space = s[i].isspace()
if current_slice_is_space ^ is_now_space:
current_slice_len = 1
current_slice_is_space = is_now_space
else:
current_slice_len += 1
if current_slice_len > max_consecutive_slice_len:
yield s[slice_start:i]
slice_start = i
current_slice_len = 1
yield s[slice_start:]
ChatFormat类
ChatFormat类借助Tokenizer类,对Tokenizer进行了进一步包装,提供了encode_header、encode_message、encode_dialog_prompt三种encode方式。
class ChatFormat:
def __init__(self, tokenizer: Tokenizer):
self.tokenizer = tokenizer
def encode_header(self, message: Message) -> List[int]:
tokens = []
tokens.append(self.tokenizer.special_tokens["<|start_header_id|>"])
tokens.extend(self.tokenizer.encode(message["role"], bos=False, eos=False))
tokens.append(self.tokenizer.special_tokens["<|end_header_id|>"])
tokens.extend(self.tokenizer.encode("\n\n", bos=False, eos=False))
return tokens
def encode_message(self, message: Message) -> List[int]:
tokens = self.encode_header(message)
tokens.extend(
self.tokenizer.encode(message["content"].strip(), bos=False, eos=False)
)
tokens.append(self.tokenizer.special_tokens["<|eot_id|>"])
return tokens
def encode_dialog_prompt(self, dialog: Dialog) -> List[int]:
tokens = []
tokens.append(self.tokenizer.special_tokens["<|begin_of_text|>"])
for message in dialog:
tokens.extend(self.encode_message(message))
# Add the start of an assistant message for the model to complete.
tokens.extend(self.encode_header({"role": "assistant", "content": ""}))
return tokens
总结
以上就是全部的源码解读。如有疑问请留言。
LLaMA 3 源码解读-大语言模型5的更多相关文章
- SDWebImage源码解读之干货大总结
这是我认为的一些重要的知识点进行的总结. 1.图片编码简介 大家都知道,数据在网络中是以二进制流的形式传播的,那么我们该如何把那些1和0解析成我们需要的数据格式呢? 说的简单一点就是,当文件都使用二进 ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
- AFNetworking 3.0 源码解读 总结(干货)(下)
承接上一篇AFNetworking 3.0 源码解读 总结(干货)(上) 21.网络服务类型NSURLRequestNetworkServiceType 示例代码: typedef NS_ENUM(N ...
- AFNetworking 3.0 源码解读 总结(干货)(上)
养成记笔记的习惯,对于一个软件工程师来说,我觉得很重要.记得在知乎上看到过一个问题,说是人类最大的缺点是什么?我个人觉得记忆算是一个缺点.它就像时间一样,会自己消散. 前言 终于写完了 AFNetwo ...
- AFNetworking 3.0 源码解读(八)之 AFImageDownloader
AFImageDownloader 这个类对写DownloadManager有很大的借鉴意义.在平时的开发中,当我们使用UIImageView加载一个网络上的图片时,其原理就是把图片下载下来,然后再赋 ...
- AFNetworking 3.0 源码解读(七)之 AFAutoPurgingImageCache
这篇我们就要介绍AFAutoPurgingImageCache这个类了.这个类给了我们临时管理图片内存的能力. 前言 假如说我们要写一个通用的网络框架,除了必备的请求数据的方法外,必须提供一个下载器来 ...
随机推荐
- CA:用于移动端的高效坐标注意力机制 | CVPR 2021
论文提出新颖的轻量级通道注意力机制coordinate attention,能够同时考虑通道间关系以及长距离的位置信息.通过实验发现,coordinate attention可有效地提升模型的准确率, ...
- KingbaseES V8R6 集群运维案例-- sys_internal.init.*文件引起sys_basebackup失败
案例说明: KingbaseES V8R6集群在执行'repmgr standby clone'或sys_basebackup克隆备库时出现如下图相关sys_internal.init文件错误: 适用 ...
- mybatis踩坑之integer类型是0的时候会被认为0!=''是假
当你的参数类型是integer类型,并且传的是0的时候,在SQL里面做if判断的时候 <if test="auditStatus != null and auditStatus != ...
- #树状数组,哈希#洛谷 6687 论如何玩转 Excel 表格
题目 分析 首先一列的数不会发生变化,只是交换列, 并且交换列的时候奇数列变成偶数列取反, 偶数列变成奇数列取反,考虑直接将偶数列全部取反, 那只需要交换列就可以了,奇数列交换到偶数列会取反, 奇数列 ...
- Jetty的https模块
启用https模块,执行如下命令: java -jar $JETTY_HOME/start.jar --add-modules=https 命令的输出,如下: INFO : https initial ...
- FindBugs问题EQ_COMPARETO_USE_OBJECT_EQUALS的解决方法
本文记录的是2016年4月初发生的事情. 前几天,标准CI的静态检查页面发现一个项目组同事引入的FindBugs问题,EQ_COMPARETO_USE_OBJECT_EQUALS,CI对这个问题给出的 ...
- OpenHarmony 4.1 Release版本正式发布,邀您体验
春风轻拂的4月,OpenAtom OpenHarmony(以下简称"OpenHarmony")4.1 Release版本如期而至,开发套件同步升级到API 11 Release. ...
- 华为帐号为AITO问界M5助力,打造懂你的智能座舱
12月23日,在华为冬季旗舰新品发布会上,AITO问界M5正式发布.华为赋能的AITO问界M5搭载HUAWEI DriveONE纯电驱增程平台和HarmonyOS智能座舱,并且带来华为终端云服务软硬协 ...
- java集合源码详解
一 Collection接口 1.List 1.1ArrayList 特点 1.底层实现基于动态数组,数组特点根据下表查找元素速度所以查找速度较快.继承自接口 Collection ->Lis ...
- Spark常见的问题以及解决方案
Spark为什么比Hadoop要快? Spark比hadoop快的原因,我认为主要是spark的DAG机制优于hadoop太多,spark的DAG机制以及RDD的设计避免了很多落盘的操作,在窄依赖的情 ...