kube-proxy 流量流转方式
简介
kube-proxy 是 Kubernetes 集群中负责服务发现和负载均衡的组件之一。它是一个网络代理,运行在每个节点上, 用于 service 资源的负载均衡。它有两种模式:iptables 和 ipvs。
iptables
iptables 是 Linux 系统中的一个用户空间实用程序,用于配置内核的网络包过滤和网络地址转换(NAT)规则。它是 Linux 内核中的 netfilter 框架的一部分,并负责在网络包进入、转发或离开计算机时进行筛选和处理。其主要功能和用途包括:
- 防火墙:iptables 提供了强大的防火墙功能,可以根据不同的规则来过滤和拒绝不需要的网络包。管理员可以创建自定义的规则集,允许或拒绝从特定 IP 地址、端口或协议的数据包。
- NAT(网络地址转换):iptables 支持 NAT 功能,可以用来将私有网络中的计算机与外部网络连接。例如,它可以在一个 NAT 路由器上将内部网络的多个设备映射到单个外部 IP 地址。
- 端口转发:iptables 可以将特定的端口流量从一个网络接口转发到另一个接口或目标 IP 地址,通常用于内部网络的服务公开。
- 负载均衡:它也可以通过 DNAT(目标网络地址转换)功能将流量转发给多个内部服务器,实现简单的负载均衡。
iptables 是通过链(chains)和表(tables)来组织规则的。每个链由一组规则组成,当网络数据包经过时,这些规则会逐一执行。常用的表包括:
- filter 表:用于包过滤,是最常用的表。
- nat 表:用于网络地址转换。
- mangle 表:用于修改数据包的 IP 层字段。
- raw 表:用于绕过连接跟踪。
链的流向为:
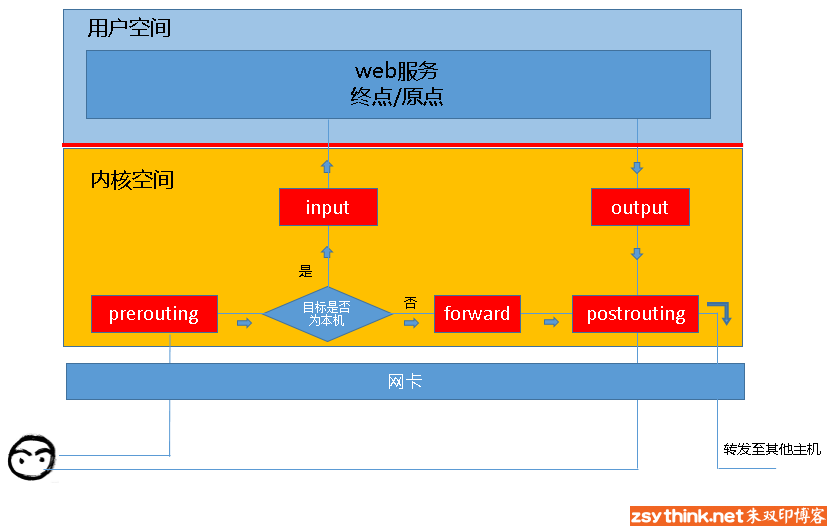
所以,根据上图,我们能够想象出某些常用场景中,报文的流向:
到本机某进程的报文:PREROUTING –> INPUT
由本机转发的报文:PREROUTING –> FORWARD –> POSTROUTING
由本机的某进程发出报文(通常为响应报文):OUTPUT –> POSTROUTING
尽管在某些情况下配置 iptables 规则可能复杂,但它提供了高度的灵活性和强大的功能,使其成为 Linux 网络安全的重要组成部分。
service 负载均衡
我启动了一个 3 个 nginx pod,和一个对应的 service,service 的类型是 ClusterIP,这样 service 就会有一个虚拟 IP,这个 IP 会被 kube-proxy 代理到后端的 pod 上。
~ » k get pod 130 ↵ zhy@daemon
NAME READY STATUS RESTARTS AGE
nginx-deployment-59f546cb79-2k9ng 1/1 Running 0 3m33s
nginx-deployment-59f546cb79-wfw84 1/1 Running 0 3m1s
nginx-deployment-59f546cb79-zr9xm 1/1 Running 0 3m1s
----------------------------------------------------------------------------------------------------------------------------------------------------
~ » k get svc nginx-service zhy@daemon
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service ClusterIP 10.101.57.97 <none> 80/TCP 29m
当我们在 master 使用 curl 10.101.57.97 访问 service 的时候,首先会进入 PREROUTING 链:
root@minikube:/# iptables-save |grep PREROUTING
:PREROUTING ACCEPT [0:0]
:PREROUTING ACCEPT [77:4620]
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -d 192.168.49.1/32 -j DOCKER_OUTPUT
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
首先会尝试匹配 KUBE-SERVICES 链,这个链是 kube-proxy 生成的,用于处理 service 的请求。后两个是 docker 的链,用于处理 docker 的请求。
root@minikube:/# iptables-save |grep "\-A KUBE-SERVICES"
-A KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.101.57.97/32 -p tcp -m comment --comment "default/nginx-service cluster IP" -j KUBE-SVC-V2OKYYMBY3REGZOG
-A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -j KUBE-SVC-JD5MR3NA4I4DYORP
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
我们这个 nginx-service 的 cluster IP 是 10.101.57.97, 所以会走 KUBE-SVC-V2OKYYMBY3REGZOG 链:
root@minikube:/# iptables-save |grep "\-A KUBE-SVC-V2OKYYMBY3REGZOG"
-A KUBE-SVC-V2OKYYMBY3REGZOG ! -s 10.244.0.0/16 -d 10.101.57.97/32 -p tcp -m comment --comment "default/nginx-service cluster IP" -j KUBE-MARK-MASQ
-A KUBE-SVC-V2OKYYMBY3REGZOG -m comment --comment "default/nginx-service -> 10.244.0.20:80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-2UTZI2N25QKZP7U7
-A KUBE-SVC-V2OKYYMBY3REGZOG -m comment --comment "default/nginx-service -> 10.244.0.21:80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-AIL3NEC5N472IS6X
-A KUBE-SVC-V2OKYYMBY3REGZOG -m comment --comment "default/nginx-service -> 10.244.0.22:80" -j KUBE-SEP-SPCGRBSAA3XFMN3D
-A KUBE-SVC-V2OKYYMBY3REGZOG ! -s 10.244.0.0/16 -d 10.101.57.97/32 -p tcp -m comment --comment "default/nginx-service cluster IP" -j KUBE-MARK-MASQ 这条规则的如果源ip 不是 10.244.0.0/16 的 ip(也就是不是 pod发出来的请求),目的ip 是 service ip,jump 跳转到 这个链 KUBE-MARK-MASQ
root@minikube:/# iptables-save |grep "\-A KUBE-MARK-MASQ"
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
这条规则的作用是给数据包打上 0x4000 这个标记。这个标记会被后续的 NAT 规则识别到,从而让这些数据包通过特定的 NAT 规则进行 IP 地址转换。
接下来看主要的三条规则:
-A KUBE-SVC-V2OKYYMBY3REGZOG -m comment --comment "default/nginx-service -> 10.244.0.20:80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-2UTZI2N25QKZP7U7
-A KUBE-SVC-V2OKYYMBY3REGZOG -m comment --comment "default/nginx-service -> 10.244.0.21:80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-AIL3NEC5N472IS6X
-A KUBE-SVC-V2OKYYMBY3REGZOG -m comment --comment "default/nginx-service -> 10.244.0.22:80" -j KUBE-SEP-SPCGRBSAA3XFMN3D
第一条是说有 33.33% 的几率会被转发到 KUBE-SEP-2UTZI2N25QKZP7U7, 第二条是 50% 的几率会被转发到 KUBE-SEP-AIL3NEC5N472IS6X, 第三条是一定会被转发到 KUBE-SEP-SPCGRBSAA3XFMN3D。
转到第一条的概率是 33.33%,转到第二条的概率是 66.67%(没有到第一条的概率) * 50% = 33.33%,第三条就是 66.67%(没有到第一条的概率) * 50%(没有到第二条的概率) = 33.33%。所以这三条规则的概率是一样的。都是 33.33%。
那么 KUBE-SEP-2UTZI2N25QKZP7U7 又是什么呢?
root@minikube:/# iptables-save |grep "\-A KUBE-SEP-2UTZI2N25QKZP7U7"
-A KUBE-SEP-2UTZI2N25QKZP7U7 -s 10.244.0.20/32 -m comment --comment "default/nginx-service" -j KUBE-MARK-MASQ
-A KUBE-SEP-2UTZI2N25QKZP7U7 -p tcp -m comment --comment "default/nginx-service" -m tcp -j DNAT --to-destination 10.244.0.20:80
第一条规则确保流量从 10.244.0.20 发出时被打上 MASQUERADE 标记,以便通过 NAT 机制进行 IP 伪装。
第二条是将流量转发到 10.244.0.20:80 并使用 DNAT 机制进行目标地址转换。
KUBE-SEP-AIL3NEC5N472IS6X 和 KUBE-SEP-SPCGRBSAA3XFMN3D 的规则和这条同理。
ipvs
IPVS(IP Virtual Server)是 Linux 内核中实现负载均衡功能的模块。是一种高效的负载均衡技术,可以在第 4 层(传输层)进行流量转发和调度。IPVS 通常被用于构建高性能、高可用性的负载均衡集群。
查看 ipvs 的规则:
root@minikube:/etc/apt# sudo ipvsadm -Ln|grep -A 4 10.101.57.97
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.101.57.97:80 rr
-> 10.244.0.27:80 Masq 1 0 0
-> 10.244.0.28:80 Masq 1 0 0
-> 10.244.0.30:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
这个的意思是到10.101.57.97:80 的 tcp 浏览会使用 rr(轮询)的方式转发到 10.244.0.27:80,10.244.0.28:80,10.244.0.30:80 这三个 pod 上。Masq:指示 "Masquerading",表示通过 NAT 来处理网络流量。
不是说开启了 ipvs 就不会有 iptables 了,还需要 iptables 的 SNAT 规则来处理返回的数据包。
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
-m set --match-set KUBE-LOOP-BACK dst,dst,src 的意思是匹配 KUBE-LOOP-BACK 这个 set,这个 set 里面存放的是 pod 的 ip,这个规则的作用是将数据包的源地址替换为本机的地址,以便数据包能够正确返回到客户端。
为什么是 pod ip 而不是 service cluster ip 呢?因为已经通过 ipvs DNAT 过了,所以这里是 pod ip。
root@minikube:/etc/apt# ipset -L|grep -A 15 KUBE-LOOP-BACK
Name: KUBE-LOOP-BACK
Type: hash:ip,port,ip
Revision: 6
Header: family inet hashsize 1024 maxelem 65536 bucketsize 12 initval 0xe4e21451
Size in memory: 544
References: 1
Number of entries: 6
Members:
10.244.0.28,tcp:80,10.244.0.28
10.244.0.30,tcp:80,10.244.0.30
10.244.0.29,tcp:9153,10.244.0.29
10.244.0.29,tcp:53,10.244.0.29
10.244.0.27,tcp:80,10.244.0.27
10.244.0.29,udp:53,10.244.0.29
很明显我们的三个 pod 都在这个 set 里面。
-A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
这条规则的作用是将数据包的源地址替换为本机的地址,以便数据包能够正确返回到客户端。现在我们使用 curl 发出的包目标 ip 是 pod ip了,源 ip 是 node ip。等到数据包返回的时候,kernel 会根据 链路追踪 中的数据记录,会把包的源ip 的pod ip 替换为 serice cluster ip, 目标 ip 从 node ip 替换为我发起请求的 ip。这样包就能正确返回到客户端了。
References
kube-proxy 流量流转方式的更多相关文章
- APS系统生产流转方式和批量算法研究
01.前言 在经济领域,生产型企业是经济的根基,有了生产型企业生产出的各种产品,才有物流.网上购物和金融融资等活动.对于生产型企业,其制造能力是其核心竞争力.如何提升制造能力一直是生产型企业面临的课题 ...
- 通过代理模块拦截网页应用程序流量 - Intercept Web Application Traffic Using Proxy Modules
测试网站: http://testphp.vulnweb.com/login.php 浏览器代理设置为:127.0.0.1:8080 查看拦截流量: 方式1:通Proxy - Intercept 方式 ...
- 【转载】浅析从外部访问 Kubernetes 集群中应用的几种方式
一般情况下,Kubernetes 的 Cluster Network 是属于私有网络,只能在 Cluster Network 内部才能访问部署的应用.那么如何才能将 Kubernetes 集群中的应用 ...
- Apache HTTP Server 与 Tomcat 的三种连接方式介绍(转)
首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接.事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装好 tomcat 后通过 8080 端 ...
- Apache HTTP Server 与 Tomcat 的三种连接方式介绍
本文转载自IBM developer 首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接.事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装 ...
- [转]Apache HTTP Server 与 Tomcat 的三种连接方式介绍
首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接.事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装好 tomcat 后通过 8080 端 ...
- 开源流量分析系统 Apache Spot 概述(转)
原文地址http://blog.nsfocus.net/apache-spot/ Apache Spot 是一个基于网络流量和数据包分析,通过独特的机器学习方法,发现潜在安全威胁和未知网络攻击能力的开 ...
- 二进制方式安装Kubernetes 1.14.2高可用详细步骤
00.组件版本和配置策略 组件版本 Kubernetes 1.14.2 Docker 18.09.6-ce Etcd 3.3.13 Flanneld 0.11.0 插件: Coredns Dashbo ...
- 二进制文件方式安装kubernetes集群
所有操作全部用root使用者进行,高可用一般建议大于等于3台的奇数,我们使用3台master来做高可用 练习环境说明: 参考GitHub master: kube-apiserver,kube-con ...
- Spring3系列11- Spring AOP——自动创建Proxy
Spring3系列11- Spring AOP——自动创建Proxy 在<Spring3系列9- Spring AOP——Advice>和<Spring3系列10- Spring A ...
随机推荐
- KingbaseES Json 系列一:Json构造函数
KingbaseES Json 系列一--Json构造函数(JSON,ROW_TO_JSON,TO_JSON,TO_JSONB) JSON 数据类型是用来存储 JSON(JavaScript Obje ...
- vue3 快速入门系列 —— vue3 路由
vue3 快速入门系列 - vue3 路由 在vue3 基础上加入路由. vue3 需要使用 vue-router V4,相对于 v3,大部分的 Vue Router API 都没有变化. Tip:不 ...
- 动态库 DLL 封装一:dll分类
动态库分为三种: Non-MFC-DLL(非MFC动态库): 非MFC动态库不采用MFC类库结构,其带出函数为标准C接口,能被非MFC或MFC编写的应用程序所调用 MFC Regular DLL( ...
- openGauss 2.1.0 闪回特性
openGauss 2.1.0 闪回特性 openGauss 2.1.0 于 2021 年 9 月 30 日发布,是 openGauss 的一个 Preview 版本,该版本生命周期仅为半年.该版本的 ...
- Counter 1000
From a 1000 Hz clock, derive a 1 Hz signal, called OneHertz, that could be used to drive an Enable s ...
- 详解K8s 镜像缓存管理kube-fledged
本文分享自华为云社区<K8s 镜像缓存管理 kube-fledged 认知>,作者: 山河已无恙. 我们知道 k8s 上的容器调度需要在调度的节点行拉取当前容器的镜像,在一些特殊场景中, ...
- 重新点亮linux 命令树————selinux[二十六]
简介 简单整理selinux. 正文 selinux 是安全增强软件. 以前是系统安全是用户权限配置(用户自主控制),但是害怕用户自己设置问题,故而增加了一个selinux,也就是强制访问控制. 一般 ...
- Deep Learning on Graphs: A Survey第五章自动编码论文总结
论文地址:https://arxiv.org/pdf/1812.04202.pdf 最近老师让我们读的一片论文,已经开组会讲完了,我负责的是第五章,图的自动编码,现在再总结一遍,便于后者研读.因为这篇 ...
- RC4Drop加密技术:原理、实践与安全性探究
第一章:介绍 1.1 加密技术的重要性 加密技术在当今信息社会中扮演着至关重要的角色.通过加密,我们可以保护敏感信息的机密性,防止信息被未经授权的用户访问.窃取或篡改.加密技术还可以确保数据在传输过程 ...
- DRF自动生成接口文档
自动接口文档能生成的是继承自APIView及其子类的视图. 1. 安装依赖 # 生成接口文档需要coreapi库的支持 pip install coreapi 2 设置接口文档访问路径 # 在总路由中 ...