pandas高效读取大文件的探索之路
使用 pandas 进行数据分析时,第一步就是读取文件。
在平时学习和练习的过程中,用到的数据量不会太大,所以读取文件的步骤往往会被我们忽视。
然而,在实际场景中,面对十万,百万级别的数据量是家常便饭,即使千万,上亿级别的数据,单机处理也问题不大。
不过,当数据量和数据属性多了之后,读取文件的性能瓶颈就开始浮现出来。
当我们第一次拿到数据时,经常会反反复复的读取文件,尝试各种分析数据的方法。
如果每次读取文件都要等一段时间,不仅会影响工作效率,还影响心情。
下面记录了我自己优化pandas读取大文件效率的探索过程。
1. 准备部分
首先,准备数据。
下面的测试用的数据是一些虚拟币的交易数据,除了常用的K线数据之外,还包含很多分析因子的值。
import pandas as pd
fp = "all_coin_factor_data_12H.csv"
df = pd.read_csv(fp, encoding="gbk")
df.shape
# 运行结果
(398070, 224)
总数据量接近40万,每条数据有224个属性。
然后,封装一个简单的装饰器来计时函数运行时间。
from time import time
def timeit(func):
def func_wrapper(*args, **kwargs):
start = time()
ret = func(*args, **kwargs)
end = time()
spend = end - start
print("{} cost time: {:.3f} s".format(func.__name__, spend))
return ret
return func_wrapper
2. 正常读取
先看看读取这样规模的数据,需要多少时间。
下面的示例中,循环读取10次上面准备的数据all_coin_factor_data_12H.csv。
import pandas as pd
@timeit
def read(fp):
df = pd.read_csv(
fp,
encoding="gbk",
parse_dates=["time"],
)
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.csv"
for i in range(10):
read(fp)
运行结果如下:
读取一次大概27秒左右。
3. 压缩读取
读取的文件all_coin_factor_data_12H.csv大概1.5GB左右,pandas是可以直接读取压缩文件的,尝试压缩之后读取性能是否能够提高。
压缩之后,大约 615MB 左右,压缩前大小的一半不到点。
import pandas as pd
@timeit
def read_zip(fp):
df = pd.read_csv(
fp,
encoding="gbk",
parse_dates=["time"],
compression="zip",
)
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.zip"
for i in range(10):
read_zip(fp)
运行结果如下: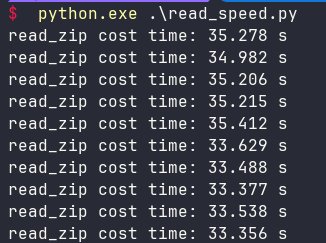
读取一次大概34秒左右,还不如直接读取来得快。
4. 分批读取
接下来试试分批读取能不能提高速度,分批读取的方式是针对数据量特别大的情况,
单机处理过亿数据量的时候,经常会用到这个方法,防止内存溢出。
先试试每次读取1万条:
import pandas as pd
@timeit
def read_chunk(fp, chunksize=1000):
df = pd.DataFrame()
reader = pd.read_csv(
fp,
encoding="gbk",
parse_dates=["time"],
chunksize=chunksize,
)
for chunk in reader:
df = pd.concat([df, chunk])
df = df.reset_index()
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.csv"
for i in range(10):
read_chunk(fp, 10000)
运行结果如下: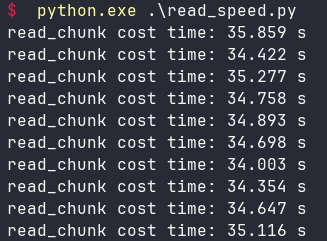
和读取压缩文件的性能差不多。
如果调整成每次读取10万条,性能会有一些微提高。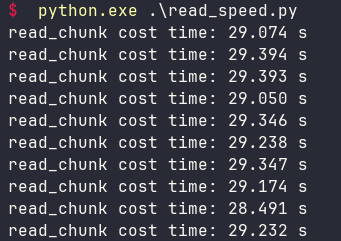
分批读取时,一次读取的越多(只要内存够用),速度越快。
其实我也试了一次读取1千条的性能,非常慢,这里就不截图了。
5. 使用polars读取
前面尝试的方法,效果都不太好,下面引入一个和pandas兼容的库Polars。
Polars是一个高性能的DataFrame库,它主要用于操作结构化数据。
它是用Rust写的,主打就是高性能。
使用Polars读取文件之后返回的Dataframe虽然和pandas的DataFrame不完全一样,
当可以通过一个简单的to_pandas方法来完成转换。
下面看看使用Polars读取文件的性能:
import polars as pl
@timeit
def read_pl(fp):
df = pl.read_csv(
fp,
encoding="gbk",
try_parse_dates=True,
)
return df.to_pandas()
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.csv"
for i in range(10):
read_pl(fp)
运行结果如下: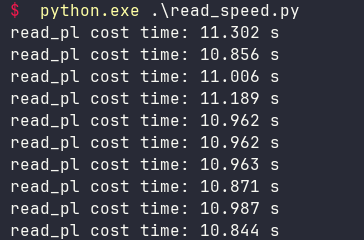
使用Polars后性能提高非常明显,看来,混合使用Polars和pandas是一个不错的方案。
6. 序列化后读取
最后这个方法,其实不是直接读取原始数据,而是将原始数据转换为python自己的序列化格式(pickle)之后,再去读取。
这个方法多了一个转换的步骤:
fp = "./all_coin_factor_data_12H.csv"
df = read(fp)
df.to_pickle("./all_coin_factor_data_12H.pkl")
生成一个 序列化文件:all_coin_factor_data_12H.pkl。
然后,测试下读取这个序列化文件的性能。
@timeit
def read_pkl(fp):
df = pd.read_pickle(fp)
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.pkl"
for i in range(10):
read_pkl(fp)
运行结果如下: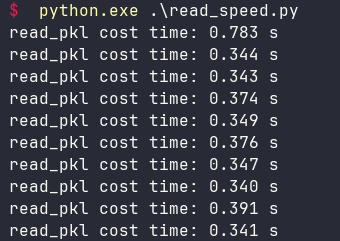
这个性能出乎意料之外的好,而且csv文件序列化成pkl文件之后,占用磁盘的大小也只有原来的一半。csv文件1.5GB左右,pkl文件只有690MB。
这个方案虽然性能惊人,但也有一些局限,
首先是原始文件不能是那种实时变化的数据,因为原始csv文件转换为pkl文件也是要花时间的(上面的测试没有算这个时间)。
其次,序列化之后的pkl文件是python专用的,不像csv文件那样通用,不利于其他非python的系统使用。
7. 总结
本文探讨了一些pandas读取大文件的优化方案,最后比较好的就是Polars方案和pickle序列化方案。
如果我们的项目是分析固定的数据,比如历史的交易数据,历史天气数据,历史销售数据等等,
那么,就可以考虑pickle序列化方案,先花时间讲原始数据序列化,
后续的分析中不担心读取文件浪费时间,可以更高效的尝试各种分析思路。
除此之外的情况,建议使用Polars方案。
最后补充一点,如果读取文件的性能对你影响不大,那就用原来的方式,千万不要画蛇添足的去优化,
把精力花在数据分析的业务上。
pandas高效读取大文件的探索之路的更多相关文章
- Java高效读取大文件
1.概述 本教程将演示如何用Java高效地读取大文件.这篇文章是Baeldung (http://www.baeldung.com/) 上“Java——回归基础”系列教程的一部分. 2.在内存中读取 ...
- Java高效读取大文件(转)
1.概述 本教程将演示如何用Java高效地读取大文件.这篇文章是Baeldung(http://www.baeldung.com/) 上“Java——回归基础”系列教程的一部分. 2.在内存中读取 读 ...
- 高效读取大文件,再也不用担心 OOM 了!
内存读取 第一个版本,采用内存读取的方式,所有的数据首先读读取到内存中,程序代码如下: Stopwatch stopwatch = Stopwatch.createStarted(); // 将全部行 ...
- pandas read_csv读取大文件的Memory error问题
今天在读取一个超大csv文件的时候,遇到困难:首先使用office打不开然后在python中使用基本的pandas.read_csv打开文件时:MemoryError 最后查阅read_csv文档发现 ...
- pandas读取大文件时memoryerror的解决办法
再用pd.read_csv读取大文件时,如果文件太大,会出现memoryerror的问题. 解决办法一:pd.read_csv的参数中有一个chunksize参数,为其赋值后,返回一个可迭代对象Tex ...
- php如何高效的读取大文件
通常来说在php读取大文件的时候,我们采用的方法一般是一行行来讲取,而不是一次性把文件全部写入内存中,这样会导致php程序卡死,下面就给大家介绍这样一个例子. 需求:有一个800M的日志文件,大约有5 ...
- PHP如何快速读取大文件
在PHP中,对于文件的读取时,最快捷的方式莫过于使用一些诸如file.file_get_contents之类的函数,简简单单的几行代码就能 很漂亮的完成我们所需要的功能.但当所操作的文件是一个比较大的 ...
- php使用file函数、fseek函数读取大文件效率分析
php读取大文件可以使用file函数和fseek函数,但是二者之间效率可能存在差异,本文章向大家介绍php file函数与fseek函数实现大文件读取效率对比分析,需要的朋友可以参考一下. 1. 直接 ...
- PHP读取大文件的几种方法介绍
读取大文件一直是一个头痛的问题,我们像使用php开发读取小文件可以直接使用各种函数实现,但一到大文章就会发现常用的方法是无法正常使用或时间太长太卡了,下面我们就一起来看看关于php读取大文件问题解决办 ...
- php -- 读取大文件
在PHP中,对于文件的读取时,最快捷的方式莫过于使用一些诸如file.file_get_contents之类的函数,简简单单的几行代码就能 很漂亮的完成我们所需要的功能.但当所操作的文件是一个比较大的 ...
随机推荐
- Rocketmq学习2——Rocketmq消息过滤&事务消息&延迟消息原理源码浅析
系列文章目录和关于我 零丶引入 在<Rocketmq学习1--Rocketmq架构&消息存储&刷盘机制>中我们学习了rocketmq的架构,以及消息存储设计,在此消息存储设 ...
- 用ChatGPT 玩转哔哩哔哩
用ChatGPT 玩转哔哩哔哩 哔哔终结者 BibiGPT 哔哩哔哩 BiliGPT,一款智能AI工具,帮助用户一键总结 哔哩哔哩视频内容,非常省心,软件基于GPT-3.5 AI,如果无法使用,可以使 ...
- JSP开发模式(四种模式)
原作者为 RioTian@cnblogs, 本作品采用 CC 4.0 BY 进行许可,转载请注明出处. 学习编程开发少不了学习开发模式, JSP在创立至今有 \(4\) 种流行的开发模式: 包括 JS ...
- windows 系统关闭占用端口的应用
开发中有时候开发工具把程序关闭了,但是后台并没有真正关闭程序,导致再次启动相同端口的程序时报端口已经被使用的错误,这时如何强制关闭已占用的端口 1.打开dos对话框 2.查找被占用的端口的进程号 ne ...
- Python的excel文件读写(未完)
写在前面: 因为每次用到都要查感觉太烦了,所以干脆写了一篇博客总结( •̥́ ˍ •̀ू ) 一.xlwt写入excel文件(.xls) import xlwt data1=[[1,2,3,4],[5 ...
- P1228-递归【黄】
这道大递归我一开始就找对了方向,不过了MLE,然后从网上搜索到了一个贼有用的概念--尾递归,即如果递归的下一句就是return且没有返回值或者返回值不含有递归函数则编译器会做优化,不会压入新的函数而是 ...
- plsqll连接Oracle的两种方式
第一种方式:配置tnsnames.ora 找到plsql软件根目录 下的配置文件
- 项目启动一直 DruidDataSource inited,启动很慢
解决方案: 由于在调试过程中,代码中设置了断点,在启动的时候,服务就一直卡住了,当关闭断点,重新启动就ok了.
- JMS微服务远程调用性能测试 vs .Net Core gRPC服务
gRPC性能测试(.net 5) 创建一个最简单的gRPC服务,服务器代码如下: using Grpc.Core; using Microsoft.Extensions.Logging; using ...
- [转帖]使用S3F3在Linux实例上挂载Bucket
https://docs.jdcloud.com/cn/object-storage-service/s3fs S3F3是基于FUSE的文件系统,允许Linux 挂载Bucket在本地文件系统,S3f ...