【四】多智能体强化学习(MARL)近年研究概览 {Learning cooperation(协作学习)、Agents modeling agents(智能体建模)}
相关文章:
【二】最新多智能体强化学习文章如何查阅{顶会:AAAI、 ICML }
【三】多智能体强化学习(MARL)近年研究概览 {Analysis of emergent behaviors(行为分析)_、Learning communication(通信学习)}
【四】多智能体强化学习(MARL)近年研究概览 {Learning cooperation(协作学习)、Agents modeling agents(智能体建模)}
下面遵循综述 Is multiagent deep reinforcement learning the answer or the question? A brief survey 对多智能体强化学习算法的分类方法,将 MARL 算法分为以下四类:
- Analysis of emergent behaviors(行为分析)
- Learning communication(通信学习)
- Learning cooperation(协作学习)
- Agents modeling agents(智能体建模)
下面我将分别按照时间顺序对这四类算法中的一些典型工作进行详细讨论。
3.协作学习
此类工作并不显式地学习智能体之间的通信,而是将 multi-agent learning 领域的一些思想引入到 MARL 中。而这类方案又可以分为以下三个类别:
基于值函数的方法:
Sunehag, Peter, et al. "Value-decomposition networks for cooperative multi-agent learning" arXiv preprint arXiv:1706.05296 (2017).
Rashid, Tabish, et al. "QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning" arXiv preprint arXiv:1803.11485 (2018).
Son, Kyunghwan, et al. "QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning" arXiv preprint arXiv:1905.05408 (2019).
基于演员-评论家的方法:
Lowe, Ryan, et al. "Multi-agent actor-critic for mixed cooperative-competitive environments" Advances in Neural Information Processing Systems . 2017.
Foerster, Jakob N., et al. "Counterfactual multi-agent policy gradients" Thirty-Second AAAI Conference on Artificial Intelligence . 2018.
Wei, Ermo, et al. "Multiagent soft q-learning" 2018 AAAI Spring Symposium Series . 2018.
Iqbal, Shariq, and Fei Sha. "Actor-Attention-Critic for Multi-Agent Reinforcement Learning" arXiv preprint arXiv:1810.02912 (2018).
基于经验回放缓存的方法:
Foerster, Jakob, et al. "Stabilising experience replay for deep multi-agent reinforcement learning" Proceedings of the 34th International Conference on Machine Learning-Volume 70 . JMLR. org, 2017.
Omidshafiei, Shayegan, et al. "Deep decentralized multi-task multi-agent reinforcement learning under partial observability" Proceedings of the 34th International Conference on Machine Learning-Volume 70 . JMLR. org, 2017.
下面我们将从这三个方面分别进行讨论。
3.1 基于值函数的方法
3.1.1论文标题:Value-Decomposition Networks For Cooperative Multi-Agent Learning
论文链接:https://arxiv.org/abs/1706.05296

基于值函数的方法可以说是多智能体强化学习算法最开始的尝试(例如 Independent Q-Learning, IQL 算法)。虽然前面也提到将 IQL 算法与 DQN 算法结合能够在多智能体问题上取得比较好的效果,但是对于较为复杂的环境,IQL 还是无法很好地处理由于环境非平稳而带来的问题。
而中心化的方法,即将所有智能体的状态空间以及动作空间合并,当作一个智能体来考虑的方法,虽然能够较好的处理环境非平稳性问题,但是也存在以下缺陷:
- 在大规模多智能体环境中算法可扩展性较差
- 由于所有智能体联合训练,一旦某个智能体较早学到一些有用的策略,则其余智能体会选择较为懒惰的策略。这是因为其余智能体由于进度较慢,从而做出的策略会阻碍已经学到一些策略的智能体,从而使得全局汇报下降(来源原论文)
本文提出的 VDN 方法的基本思想是,中心化地训练一个联合的 Q network,但是这个联合的网络是由所有智能体局部的 Q networks 加和得到,这样不仅可以通过中心化训练处理由于环境非平稳带来的问题,而且由于实际是在学习每个智能体的局部模型,因而解耦智能体之间复杂的相互关系。
最后,由于训练完毕后每个智能体拥有只基于自己局部观察的 Q network,可以实现去中心化执行,即 VDN 遵循 CTDE 框架,并且解决的是 Dec-POMDP 问题。
具体来说,本文做出了如下假设:
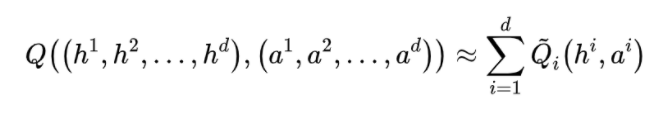
这里之所以使用 而不是 是因为我们解决的是 POMDP 问题,并且也因为此,这里的 Q network 是使用 LSTM 构建。
我们注意到,上述分解满足一个很好的性质,即对左边的联合 Q function 进行 操作,等价于对右边每一个局部 Q function 分别进行 。这样可以保证训练完毕后去中心化执行时,即使整个系统只基于局部观察进行决策,其策略也是与基于全局观察进行决策是一致的。
下面我们简单推导一下上式是怎样得到的。假定整个多智能体系统中包含两个智能体,并且全局回报函数是每个智能体的局部回报函数的加和,
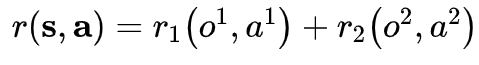

但是我们看到分解后的 Q 函数是基于全局观察的。这里我们可以假设 相比于会更加依赖于 ,并且即使使用 不能准确估计 。
但由于我们使用的网络结构是 LSTM,那么估计误差是可以缩小的,并且还可以通过智能体之间的通信来进一步减小误差,所以本文假设:
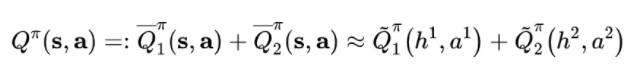
同时还是为了算法在大规模环境下的可扩展性以及为了避免上面提到的中心化训练带来的第二个问题,VDN 采用了 parameter sharing 方法,并因此提出了 Agent Invariance 的定义(图片来源原论文):

即使用 parameter sharing 的多智能体系统均满足这一性质。但是实际上并不是所有的多智能体系统都应该满足这一性质,因为不同的智能体在特定任务中,即使观测到同样的局部观察,其策略也是不同的。
为了解决这一问题,VDN(像其他方法一样),在输入中引入了类似于智能体索引号这样的额外信息来表示智能体的不同角色。这样,我们说整个多智能体系统是 conditionally agent invariant。
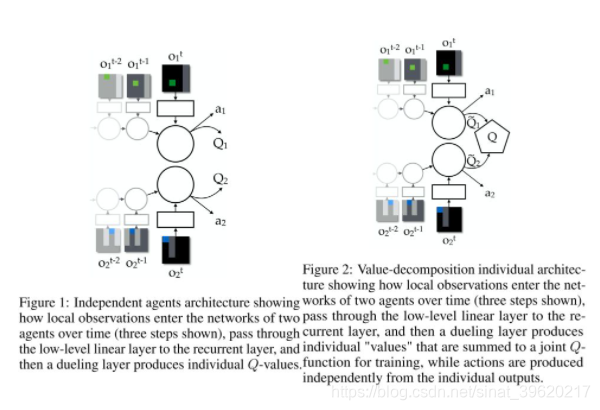
整个算法的框架如下图所示(图片来源原论文):
最后本文进行了如下对比实验,baseline 模型设置如下(图片来源原论文):
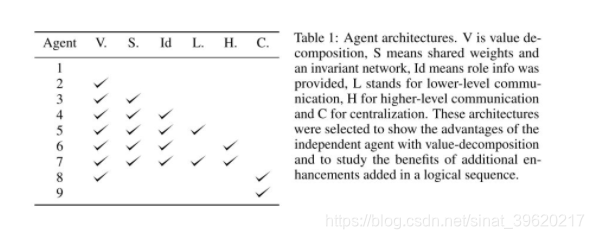
我们可以看到,实验为了减小 value decompostion 带来的误差,显式加入了通信模块,并分为高层通信以及低层通信(低层通信其实是互相共享局部观察),不同 baseline 具体网络结构以及部分实验结果对比如下图所示(图片来源原论文):
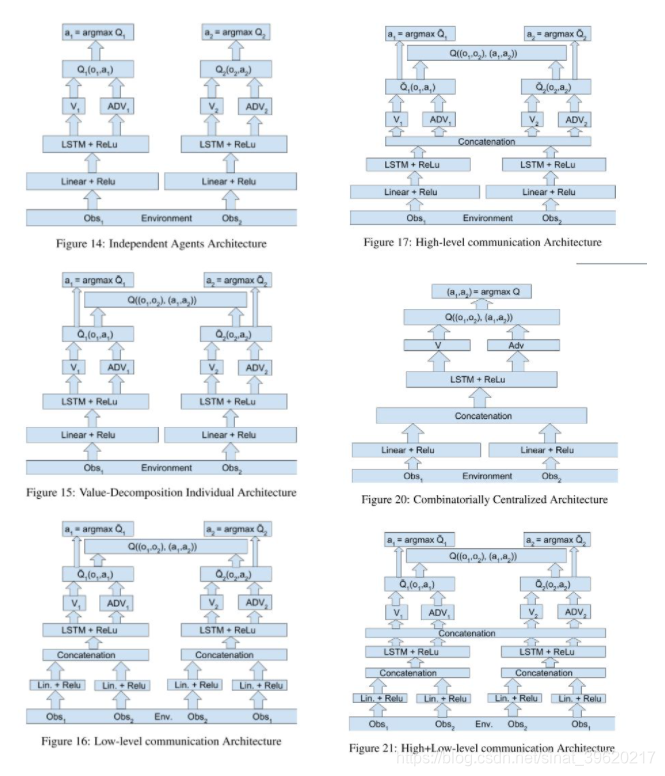
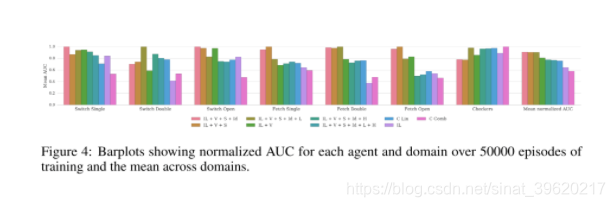
3.1.2论文标题:QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
论文链接:https://arxiv.org/abs/1803.11485
QMIX 算法是 VDN 算法的后续工作,它的出发点是 VDN 做联合 Q-value 分解时只是进行简单的加和,这种做法会使得学到的局部 Q 函数表达能力有限,没有办法捕捉到智能体之间更复杂的相互关系,因而对 VDN 算法进行了修改。
具体来说,本文认为联合 Q 函数以及局部 Q 函数需要满足下述约束:

而 VDN 提出的加和分解方式只是满足这一约束的一个特例。QMIX 认为上述约束可以泛化到一个更大的单调函数族中,上述约束是这个单调函数族的必要非充分条件。这个单调函数族满足下面的约束:
为了使得学到的联合 Q 函数以及局部 Q 函数满足上述条件,QMIX 使用了如下包含 agent network、mixing network 以及 hypernetworks 的架构(图片来源原论文),注意到,QMIX 由于 mixing network 是一个非线性网络的原因,其表达能力因而超过 VDN:
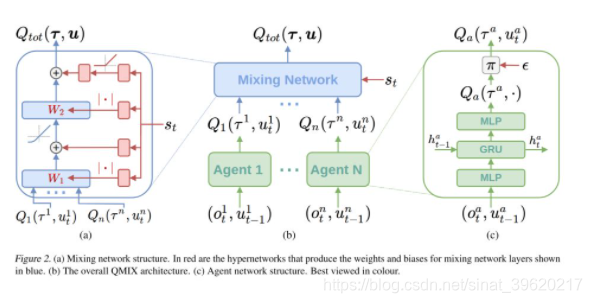
实际上,约束 使得 mixing network 关于每一个局部 Q-value 的权重必须非负,这也是为什么 mixing network 中的 hyperneteorks 会加绝对值操作或者 ReLU 操作的原因。
另外,我们注意到,每个时刻的全局状态作为 mixing network 的额外输入,这个出发点与 VDN 一样,即每个智能体只依赖于局部观察可能无法准确估计其局部 Q 函数,在 VDN 中通过低层或者高层通信来引入全局信息,而 QMIX 中则更加直接。
最后实验结果也表明加上这一全局信息会大幅提升性能(图片来源原论文,NS 代表不加入全局状态作为输入):
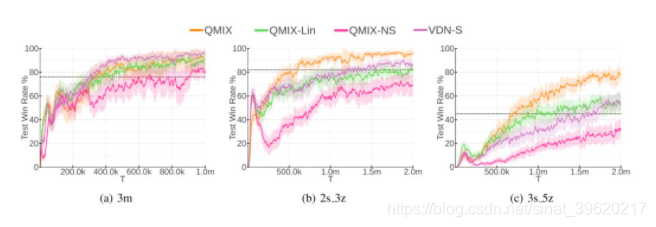
3.1.2 论文标题:QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement learning
论文链接:https://arxiv.org/abs/1905.05408
QTRAN 算法是对 VDN 以及 QMIX 算法的进一步改进(所以这三个工作是一条线),本文认为直接根据局部 Q 函数采用神经网络去逼近联合 Q 函数是一件比较困难的事情,因而将整个逼近过程分为两步:
首先采用 VDN 的方式得到加和的局部 Q 函数,作为联合 Q 函数的近似,接着去拟合局部 Q 函数与联合 Q 函数的差值,并证明了以下定理:
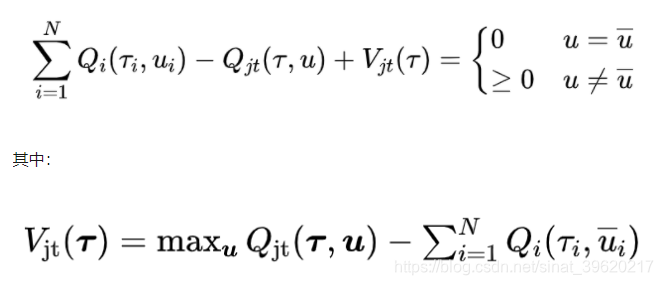
这里的 代表局部 得到的 action 的集合。并且定义一个 transformed joint-action value function (其实就是加和,用来逼近联合 Q 函数)。

为了满足上述定理,QTRAN 提出了两个算法 QTRAN-base 以及 QTRAN-alt,下面是这两个算法的结构图(图片来源原论文):
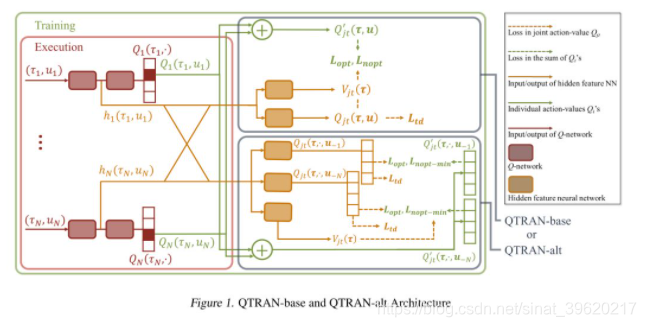
我们先来看看 QTRAN-base 方法,该方法模型分为三部分:
独立 Q 网络:
联合 Q 网络:
联合 V 网络:
整体的损失函数如下:

其中:
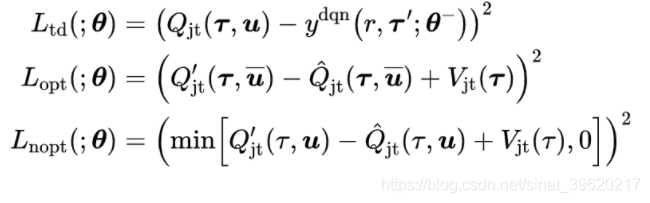
接下来,本文认为约束:
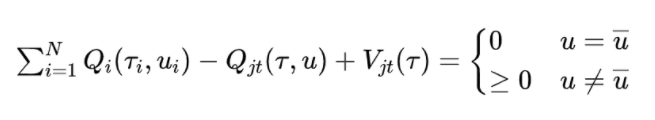
对于非 的 action 的约束过于松弛(因为训练数据中 的数据很少,因而大部分的数据都是满足第二个约束),会使得算法很难拟合联合 Q 函数。
为此,本文提出了一个新的定理,即将上述约束中的第二个约束替换为下面一个更强的约束,最终得到的结果是一致的:
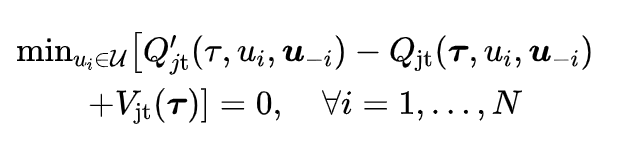
这个约束更多的聚焦于非 的训练数据(这一部分数据占训练初期训练集的大部分)。为了满足这一约束,我们需要把上面列出的第三个损失函数替换如:
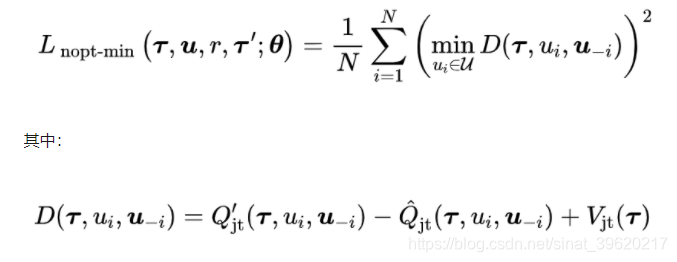
以上就是 QTRAN-alt 算法。
3.2 基于演员-评论家的方法
将单智能体强化学习算法扩展到多智能体环境中,最简单就是 IQL 类别方法,但是此类方法在复杂环境中无法处理由于环境非平稳带来的问题;另一方面,虽然中心化方法能够处理上述问题,但是与 IQL 相比又失去了较好的可扩展性。
前面介绍的基于 value-based 方法通过 value decomposition 方式来解决可扩展性问题,那么对于基于演员-评论家方法,由于其结构的特殊性,我们可以通过中心化学习(共享/独立)评论家但是每个智能体独立的演员,来很好的处理算法可扩展性问题的同时,拥有很好的抗环境非平稳能力。
3.2.1论文标题:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
论文链接:https://arxiv.org/abs/1706.02275

本文提出的 MADDPG 算法将 DDPG 算法扩展到多智能体环境中,MADDPG 算法假定每一个智能体拥有自己独立的 critic network 以及 actor network,并且假定每个智能体拥有自己独立的回报函数,这样 MADDPG 算法就可以同时解决协作环境、竞争环境以及混合环境下的多智能体问题。
但是 MADDPG 算法假定每个智能体在训练时都能够获取其余所有智能体的局部观察以及动作,因而即使每个智能体的 critic network 是独立的,训练时也需要中心化训练,因而遵循 CTDE 框架。
MADDPG 算法框架如下图所示(图片来源原论文):
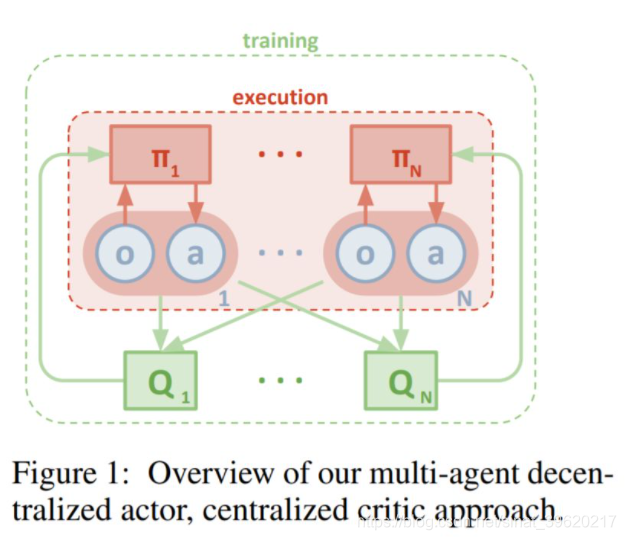
由于每个智能体的 critic 网络是基于全局信息的,因而可以处理环境非平稳问题。每个智能体 actor network 的梯度通过如下方式计算:
 critic network 的损失函数如下:
critic network 的损失函数如下:
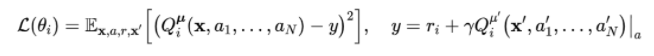
算法伪代码如下:

另外,算法还进行了两点改进。
其一,由于算法假设中心化训练每个智能体的 critic network 时,需要知晓所有智能体当前时间步的局部观察以及动作,本文认为知晓每个智能体的动作(即策略)是一个比较强的假设,因而提出了一个估计其余智能体 policy 的方法。
具体来说,每个智能体均维护一个其余智能体 actor network 的估计,通过历史每个智能体的数据,使用以下损失函数监督训练这个估计的 actor network:

因而估计的 Q-value 通过如下方式计算:

另外,在多智能体环境中,本文认为训练出的针对每个智能体的 policy 容易对其余智能体过拟合,但是其余智能体的 policy 随着训练过程的进行是不断更新的,因而本文希望通过给每个智能体同时训练 k 个 actor network 的方式,使得智能体对于其他智能体策略的变化更加鲁棒
具体来说,每个 episode 开始前,都从 k 个 actor 中随机采样一个来进行训练,并且每个 actor 都有独立的 experience replay。每个 actor 参数梯度计算方式如下:
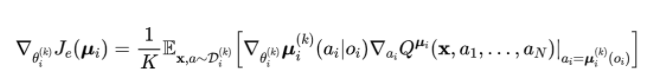
3.2.2 论文标题:Counterfactual Multi-Agent Policy Gradients
论文链接:https://arxiv.org/abs/1705.08926

本文提出的算法 COMA 旨在解决 Dec-POMDP 问题中的 multi-agent credit assignment 问题,即多智能体信用分配问题。这个问题简单概括来说,由于 Dec-POMDP 问题中所有智能体共享同一个全局回报,因而每个智能体不知道自己的行为到底对这个全局回报产生了多大的影响,这就是多智能体信用分配问题。
COMA 算法与 MADDPG 一样,遵循 CTDE 训练框架,但是因为解决的是 Dec-POMDP 问题,所以所有的智能体共享一个联合的 critic network,该 network 与 MADDPG 一样,基于所有智能体的局部观察以及动作,但是 actor network 是独立的并且只基于局部观察。
COMA 与 MADDPG 在 actor network 上的不同之处在于前者使用的是 GRU 网络,为了更好的处理局部观察问题,但是后者使用的则是普通的 DNN。COMA 算法具体框架如下图所示:
COMA 使用的是 vanilla 的 actor-critic 方法,其核心之处在于引入了一个 counterfactual 的 baseline 函数。这个思路是受到 difference rewards 方法启发的(具体可参见 [4] [5]),该方法通过比较智能体遵循当前 actor network 进行决策得到的全局回报与遵循某个默认策略进行决策得到的全局回报,来解决多智能体信用分配问题。
但是这种方法包括以下几个问题:
- 由于需要知道遵循某个默认策略得到的全局回报,需要重复访问仿真环境;
- 该默认策略得到的回报可能并不在仿真器的建模之中,因而需要进行估计;
- 该默认策略的选取是完全主观的。
COMA 算法通过使用联合的 critic 来去计算每个智能体独自的优势函数来解决上述问题,该优势函数计算的是智能体遵循当前 actor network 进行决策得到的全局回报与一个反事实 baseline 之间的差值,这个反事实 baseline 通过求得该智能体 Q-value 的期望值得到,即:
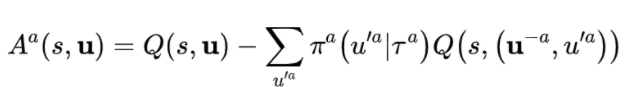
算法伪代码如下:

3.2.3 论文标题:Multiagent Soft Q-Learning
论文链接:https://arxiv.org/abs/1804.09817

本文提出了一个类似于 MADDPG 的遵循 CTDE 框架的 MASQL(论文中没有这样进行缩写) 算法,本质上是将 Soft Q-Learning 算法迁移到多智能体环境中,因而与将 DDPG 算法迁移到多智能体环境中的 MADDPG 算法类似,不过 MASQL 算法解决的是 Dec-POMDP 问题。
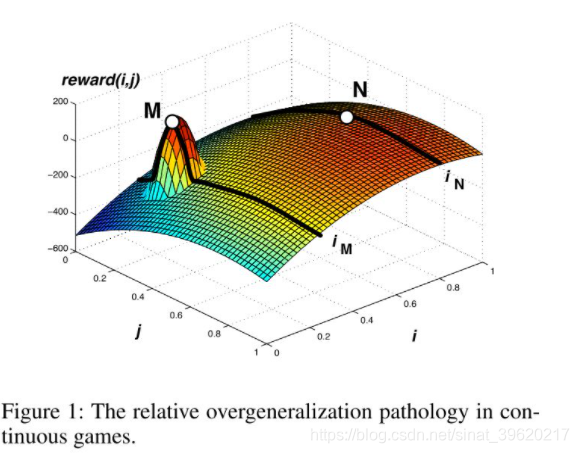
与 MADDPG 相比,MASQL 算法并不只是换了一种单智能体算法并将其迁移到多智能体环境,而是为了解决 Dec-POMDP 中的 relative overgeneralization 问题 [6],该问题可简单描述如下(具体后面我们再进行分析):
考虑一个如下图所示的 continuous game, 坐标轴是两个智能体能够采取的动作,曲面代表联合动作对应的全局回报。虽然联合动作 相比于联合动作 拥有更高的全局回报,但是对于智能体 来说,执行动作 带来的期望收益要低于执行动作 带来的期望收益,那么整体就会收敛到 (次优)点。
接下来我们看看 relative overgeneralization 问题会如何影响到 multi-agent actor-critic 算法。对于一个 Dec-POMDP 问题,我们有如下多智能体(随机)策略梯度定理(本文证明得来):
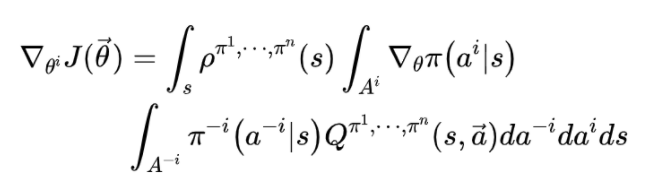
我们再来对比一下单智能体的(随机)策略梯度定理:

可以看到现在某个特定智能体的策略梯度是根据以下来放缩的:
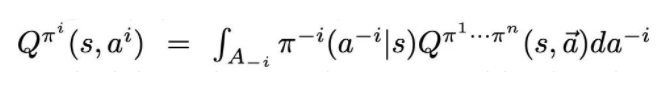
这一项相当于根据其余智能体当前策略得到的一个期望联合 Q-value。
这样一个策略梯度的估计公式存在以下几个问题:
- 由于策略梯度是由根据其余智能体当前策略得到的一个期望联合 Q-value 来进行放缩的,其余智能体的当前策略不一定是最优的回应该智能体的策略,会导致策略梯度估计不准确;
- 即使我们解决了第一个问题,依旧存在前面提到的 relative overgeneralization 问题。
MADDPG 算法虽然通过中心化学习一个联合的 critic 可以尽可能保证第一个问题得以解决,但是第二个问题依旧存在。下面我们详细讨论为什么 MASQL 算法可以解决第二个问题。首先我们简单回顾一下 Soft Q-Learning 方法。
SQL 方法目的在于解决最优策略不是唯一的的任务,因而尝试学习一个最优策略的分布,从而学到所有可能的最优策略。为了实现这个目标,其实是求得下列优化问题的最优解:

然而,直接使用这个策略在环境中进行采样非常困难,因而 SQL 方法采用 Stein Variational Gradient Descent (SVGD) 方法最小化以下 KL 散度来对这个最优策略进行估计:

因而 SQL 方法需要学习一个 Q function 以及 policy,可以被看作是一个 actor-critic 方法(但与实际的 actor-critic 方法还是不同的,将其看作 AC 方法只是为了能够实现 CTDE 框架)。接下来我们将其扩展到多智能体环境中,具体算法伪代码如下:

MASQL 算法与 MADDPG 算法一样,使用了一个中心化的 criti;但与 MADDPG 不同,每个智能体的 policy 不是只输出自己的action,而是输出所有智能体的 joint action,然后与环境交互时从中选取属于自己的 action。 值从大到小意味着在训练初期会尽可能探索更大的 policy space,随着训练的进行会逐步收敛到最优的 policy 上,这样就可以解决上述第二个问题。
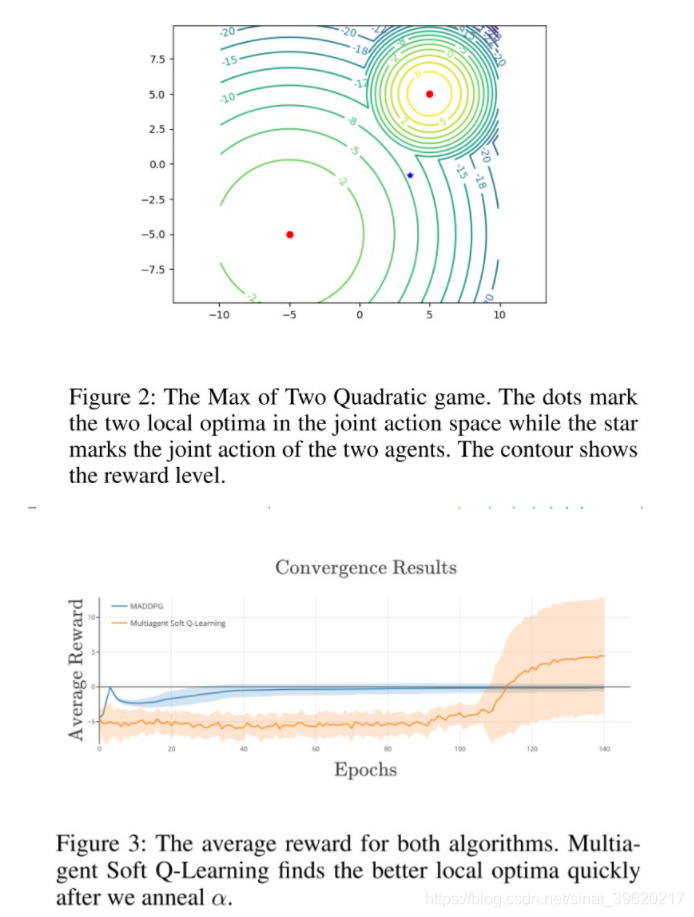
本文的实验设置也是为了表明 MASQL 相比 MADDPG 在解决 relative overgeneralization 问题上的有效性:
3.2.4 论文标题:Actor-Attention-Critic for Multi-Agent Reinforcement Learning
论文链接:https://arxiv.org/abs/1810.02912
本文提出的 MAAC 算法是在 MADDPG 上进行了一些修改,将 MADDPG 采用的 DDPG 算法替换为 SAC(soft actor-critic)算法,并将 COMA 提出的 counterfactual baseline 引入进来,因而可以同时处理协作、竞争以及混合环境,遵循 CTDE 框架。
其核心思想体现在,对于 MADDPG 算法,其每个智能体对应的 Q function 都是将其余智能体的局部观察以及动作无差别的作为输入,但是在现实场景中,智能体对于其余智能体的关注度是不一样的。
为此,MAAC 算法将注意力机制引入到 Q function 的构建之中,具体来说,每个智能体的 Q-function 网络结构如下(图片来源原论文):
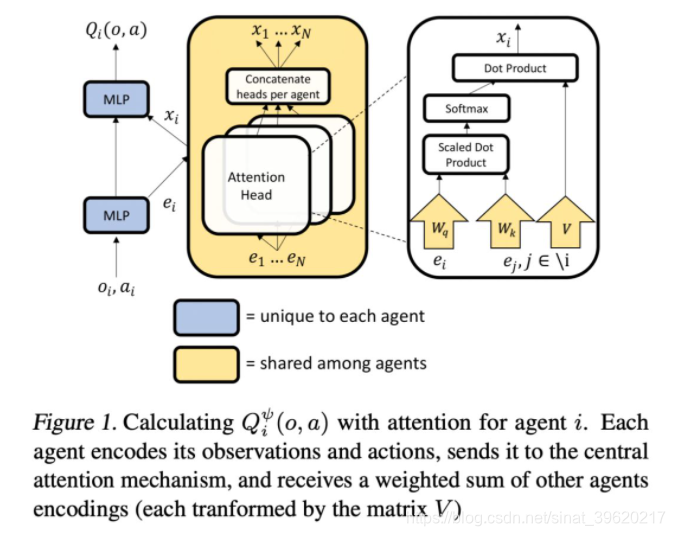
具体来说,每个智能体的 Q function 如下所示:
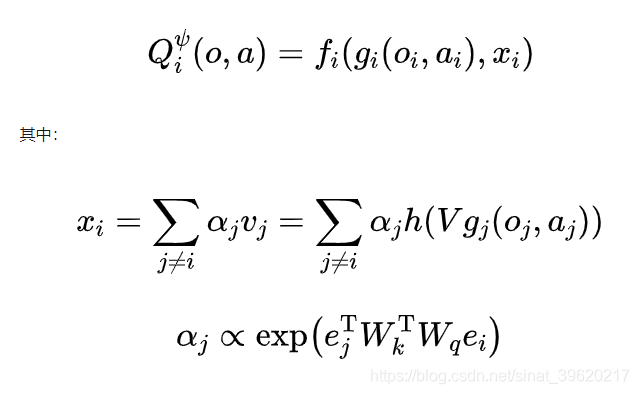
本文注意力机制采用的是多头注意力机制。由于在每个智能体的 Q function 中存在共享参数,因而优化目标与 MADDPG 不同:

算法伪代码如下:


3.3 基于经验回放(ER)的方法
Foerster, Jakob, et al. "Stabilising experience replay for deep multi-agent reinforcement learning" Proceedings of the 34th International Conference on Machine Learning-Volume 70 . JMLR. org, 2017.
Omidshafiei, Shayegan, et al. "Deep decentralized multi-task multi-agent reinforcement learning under partial observability" Proceedings of the 34th International Conference on Machine Learning-Volume 70 . JMLR. org, 2017.
由于这部分要介绍的两个工作主要聚焦于使用 ER 训练 Q-function 时增加稳定性(CommNet 甚至因为 ER 在 multi-agent 环境下的不稳定性而禁用了 ER),这两个方法前者遵循 CTDE 框架,并且类似 MADDPG 方法一样,均假设每个智能体拥有自己独立的 Q-function;后者则是完全独立的 IQL。这两个方法都是基于 Q-Learning 算法。
Omidshafiei, Shayegan, et al. 的工作致力解决 partial observation 的问题,因而采用的是 DRQN 算法,本文提出采用 ER 训练 DRQN 时应当采用如下方式,并提出了 concurrent experience replay trajectories 的概念(图片来源原论文):
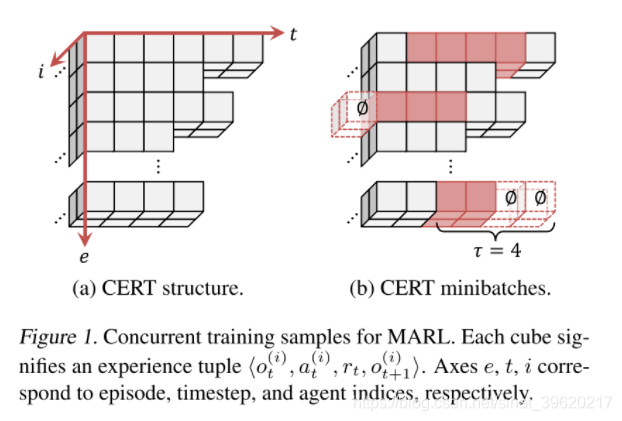
即每个智能体在独立训练自己的 Q-function 时,从 ER 中 sample 出来的数据需要从 episode 层面以及时间层面上对齐。
Foerster, Jakob, et al. 则是从 importance sampling 的角度来考虑这个问题。对于某个智能体的 Q-function,我们有:

而 就是导致 ER 在多智能体环境下不稳定的原因。
具体来说,不同时刻收集的数据 是不同的,但是我们将其直接拿来使用,就像 on-policy 的方法使用 off-policy 的数据一样。
因而,本文基于 importance sampling 方法,把每一时刻的 作为额外项存入ER, 即每一时刻存入如下五元组:
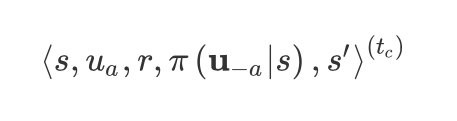
并将训练 Q-function 时的损失函数改为:
注意到以上 Q-function 基于全局观察。
下面我们再看看局部观察的情况。首先我们定义一个增广状态空间 已经对应的观察函数 ,回报函数 以及状态转移函数:

那么对应的贝尔曼方程为:

将其展开,我们有:
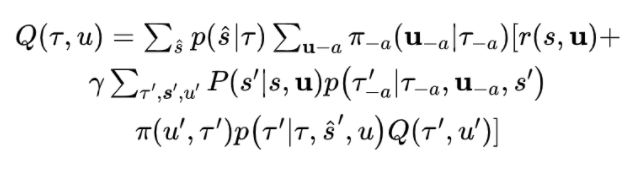
这时候我们可以看到 依旧是导致不稳定问题的部分原因(完全的是因为 ),但因为不是全部,因而采用上述损失函数在部分观察的环境下只是一种估计。
4. 智能体建模
这一类方法主要聚焦于通过对其他智能体的策略、目标、类别等等建模来进行更好的协作或者更快地打败竞争对手。由于这一类方法我掌握的还不够全面,因而在这里简单的讨论几个估计其他智能体策略的相关工作。
Foerster, Jakob, et al. "Stabilising experience replay for deep multi-agent reinforcement learning" Proceedings of the 34th International Conference on Machine Learning-Volume 70 . JMLR. org, 2017.
Rabinowitz, Neil C., et al. "Machine theory of mind" arXiv preprint arXiv:1802.07740 (2018).
4.1论文标题:Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
论文链接:https://arxiv.org/abs/1702.08887

这篇文章我们之前已经讨论过,但是本文还提出了一种估计其他智能体策略的方法。这篇文章首先从 hyper Q-Learning 算法 [7] 出发,该算法通过贝叶斯估计的方法来估计其他智能体的策略。但是这种方法会增加 Q function 的输入维度,使得 Q function 更难学习。
上述情况在深度强化学习中更加明显。考虑如下一个简单的 idea,我们把其他智能体策略函数的参数作为额外输入 ,但是在深度强化学习中策略函数一般是 DNN,因而维度太高基本不可行。
那么更进一步,我们不用基于所有可能的 ,只要是在 ER 中出现的就可以,那么每一条轨迹都可以看作是 policy 的表示,但是轨迹数据维度还是太高了,我们需要找到一个低维的 “指纹“ 来代替轨迹,并且这个指纹还不能随着训练过程的进行变化太大,即需要光滑。
本文提出了一个十分简单的指纹表示—— episode 索引号。这样一个听上去过于简单的指纹在性能上确实可以带来提升。但是存在一个比较大的问题在于,当其他智能体的策略收敛之后,索引号还在不断增加。
另外,本文在之前指纹的基础上还增加了一个新的指纹—— exploration rate,这个值也能够一定程度上反应 policy 的特点。
当然,指纹的构建也催生了另外一个方向,叫做 轨迹嵌入(trajectory embedding),这个我们留待下次讨论。
4.2论文标题:Machine Theory of Mind
论文链接:https://arxiv.org/abs/1802.07740

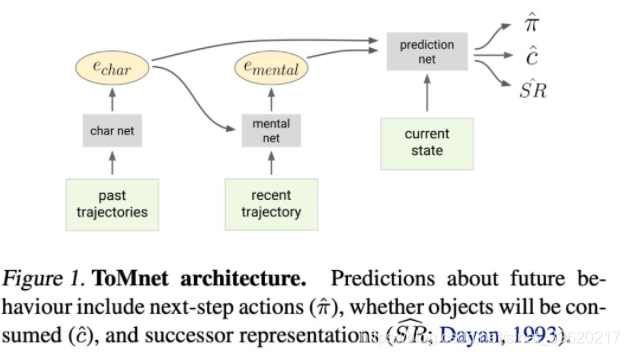
这篇论文是将行为以及脑科学领域 Theory of Mind(ToM)理论 [8] 引入到多智能体强化学习中,用以根据其他智能体历史行为数据来预测其未来行为等( 这里我们只关注行为)。
ToM 理论认为,预测一个智能体的未来行为,我们需要知道其性格(character)、思想(mental)以及当前状态。对于智能体各自的性格表示,我们通过以下方法编码:
对于某个智能体 过去的轨迹数据 ,我们使用一个神经网络编码每一条轨迹 ,最后将这些编码加起来即可, 。
不同的智能体在不同时刻其思想会根据已经历过的事件以及性格的不同而不同,因而我们可以通过下面的计算方法来得到智能体当前思想的编码:
最后,在当前状态,我们结合智能体的性格以及当前思想,来预测其行为。整体网络结构如下所示:
文章参考链接:
https://www.sohu.com/a/380219083_500659
https://blog.csdn.net/weixin_40005454/article/details/111161097
【四】多智能体强化学习(MARL)近年研究概览 {Learning cooperation(协作学习)、Agents modeling agents(智能体建模)}的更多相关文章
- 关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL))
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL)) 欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习 ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- Deep Learning(深度学习)学习笔记整理系列之(四)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- 深度强化学习:入门(Deep Reinforcement Learning: Scratching the surface)
RL的方案 两个主要对象:Agent和Environment Agent观察Environment,做出Action,这个Action会对Environment造成一定影响和改变,继而Agent会从新 ...
- Deep learning with Python 学习笔记(1)
深度学习基础 Python 的 Keras 库来学习手写数字分类,将手写数字的灰度图像(28 像素 ×28 像素)划分到 10 个类别 中(0~9) 神经网络的核心组件是层(layer),它是一种数据 ...
- 《A Survey on Transfer Learning》迁移学习研究综述 翻译
迁移学习研究综述 Sinno Jialin Pan and Qiang Yang,Fellow, IEEE 摘要: 在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- 阅读《LEARNING HARD C#学习笔记》知识点总结与摘要一
本人有幸在Learning Hard举行的整点抢书活动<Learninghard C#学习笔记>回馈网友,免费送书5本中免费获得了一本<LEARNING HARD C#学习笔记> ...
- Deep Learning(深度学习)学习笔记整理
申明:本文非笔者原创,原文转载自:http://www.sigvc.org/bbs/thread-2187-1-3.html 4.2.初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎样的表 ...
随机推荐
- 多线程 ThreadPoolTaskExecutor 应用
1.如何判断线程池所有任务是否执行完毕 package com.vipsoft.web; import org.junit.jupiter.api.Test; import org.slf4j.Log ...
- Skywalking 8.1 Docker 服务端部署
前置条件 Docker 安装 Elasticsearch ### 部署服务端 skywalking-oap-server docker pull apache/skywalking-oap-serve ...
- 玩转Python:在Python中处理表格数据,几个非常流行且功能强大的库
在Python中处理表格数据,有几个非常流行且功能强大的库.以下是一些最常用的库及其示例代码: 1. Pandas Pandas是一个开放源代码的.BSD许可的库,为Python编程语言提供高性能.易 ...
- 地图区域大数据量 marker 坐标点高效抽稀算法
按网上的思路一般要写双层循环,第一层循环遍历点集合,时间复杂度为O(N),第二层循环遍历结果集,逐一计算距离,距离小于阈值的不加入结果集,距离大于阈值的加入结果集,时间复杂度为O(M),双层循环总时间 ...
- Spring注解@Resource和@Autowired区别对比 (附 Maven 引入方法)
@Resource 导入方法: <dependency> <groupId>javax.annotation</groupId> <artifactId> ...
- Codeforces Round #658 (Div. 2)
A.Common Subsequence 题意 给你两组数,问你有没有相同 的书,有的话,输出最短的那组(大家都知道,1是最小的) AC #include<bits/stdc++.h> ...
- 最全!即学即会 Serverless Devs 基础入门(下)
作者 | 刘宇(阿里云 Serverless 产品经理) 在上篇<最全!即学即会 Serverless Devs 基础入门>中,我们阐述了工具链的重要性,并对安装方式 & 密钥配置 ...
- freeswitch on centos dockerfile模式
概述 freeswitch是一款简单好用的VOIP开源软交换平台. centos7 docker上编译安装fs的流程记录,本文使用dockerfile模式. 环境 docker engine:Vers ...
- C#商品金额大小写转换
见图 代码如下 public string NumToChinese(string x) { //数字转换为中文后的数组 string[] P_array_num = new string[] { & ...
- 广搜 广搜 poj 3984
***求最短路径,然后再输出路径, BFS+路径输出*** #include <iostream> #include <cstdio> #include <cstring ...