NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监督的文本匹配模型的训练流程。文本匹配多用于计算两段「自然文本」之间的「相似度」。
例如,在搜索引擎中,我们通常需要判断用户的搜索内容是否相似:
A:蛋黄吃多了有什么坏处 B:吃鸡蛋白过多有什么坏处 -> 不相似
A:蛋黄吃多了有什么坏处 B:蛋黄可以多吃吗 -> 相似
...
那最直觉的思路就是让人工去标注文本对,再喂给模型去学习,这种方法称为基于「监督学习」训练出的模型:
但是,如果我们今天没有这么多的标注数据,只有一大堆的「未标注」数据,我们还能训练一个匹配模型吗?这种不依赖于「人工标注数据」的方式,就叫做「无监督」(或自监督)学习方式。我们今天要讲的 SimCSE, 就是一种「无监督」训练模型。
SimCSE: Simple Contrastive Learning of Sentence Embeddings
1.SimCSE 是如何做到无监督的?
SimCSE 将对比学习(Contrastive Learning)的思想引入到文本匹配中。对比学习的核心思想就是:将相似的样本拉近,将不相似的样本推远。
但现在问题是:我们没有标注数据,怎么知道哪些文本是相似的,哪些是不相似的呢?SimCSE 相出了一种很妙的办法,由于预训练模型在训练的时候通常都会使用 dropout 机制。这就意味着:即使是同一个样本过两次模型也会得到两个不同的 embedding。而因为同样的样本,那一定是相似的,模型输出的这两个 embedding 距离就应当尽可能的相近;反之,那些不同的输入样本过模型后得到的 embedding 就应当尽可能的被推远。
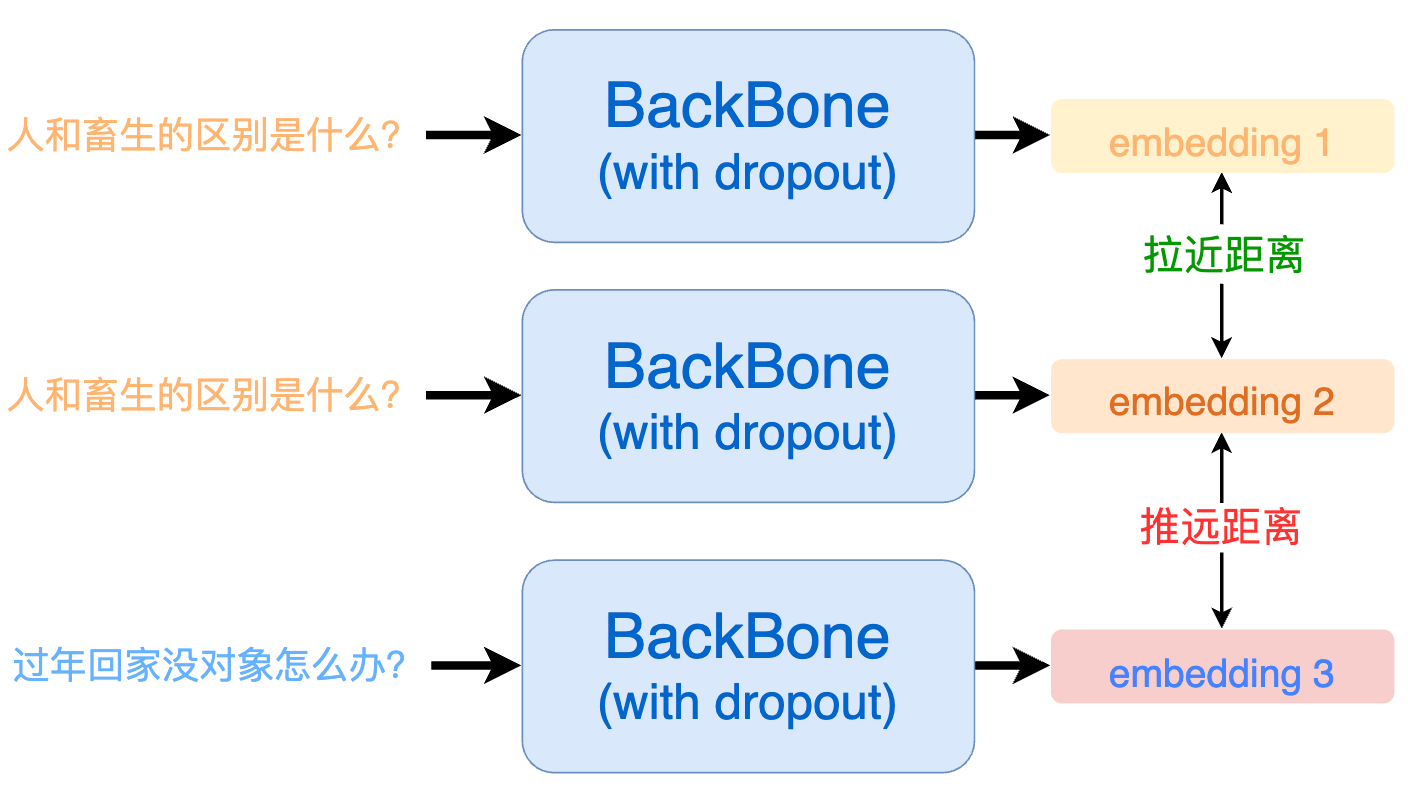
具体来讲,一个 batch 内每个句子会过 2 次模型,得到 2 * batch 个向量,将这些句子中通过同样句子得到的向量设置为正例,其他设置为负例。
假设 a1 和 a2 是由句子 a 过两次模型得到的结果,那么一个 batch 内的正负例构建如下所示:
| a1 | a2 | b1 | b2 | c1 | c2 | |
|---|---|---|---|---|---|---|
| a1 | -100 | 1 | 0 | 0 | 0 | 0 |
| a2 | 1 | -100 | 0 | 0 | 0 | 0 |
| b1 | 0 | 0 | -100 | 1 | 0 | 0 |
| b2 | 0 | 0 | 1 | -100 | 0 | 0 |
| c1 | 0 | 0 | 0 | 0 | -100 | 1 |
| c2 | 0 | 0 | 0 | 0 | 1 | -100 |
其中,对角线上的 - 100 表示自身和自身不做相似度比较。
2. SimCSE 的缺点?
从 SimCSE 的正例构建中我们可以看出来,所有的正例都是由「同一个句子」过了两次模型得到的。这就会造成一个问题:模型会更倾向于认为,长度相同的句子就代表一样的意思。由于数据样本是随机选取的,那么很有可能在一个 batch 内采样到的句子长度是不相同的。
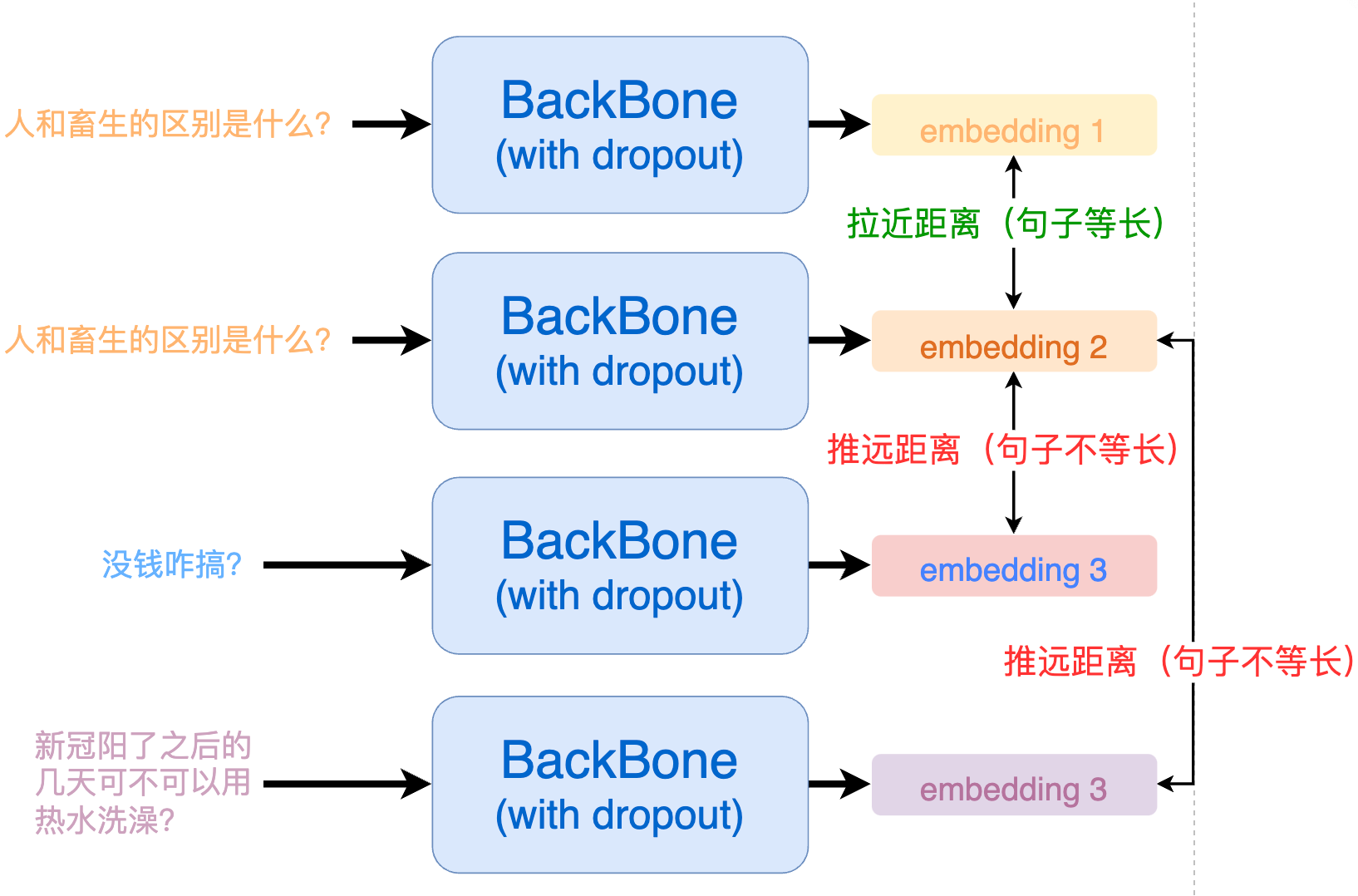
为了解决这个问题,我们最终采取的实现方式为 ESimCSE。
3. ESimCSE 解决模型对文本长度的敏感问题
ESimCSE 通过随机重复单词(Word Repetition)的方式来构建正例,巧妙的解决了句子长度敏感性的问题:
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
要想消除模型对句子长度的敏感,我们就需要在构建正例的时候让输入句子的长度发生改变,如下所示:
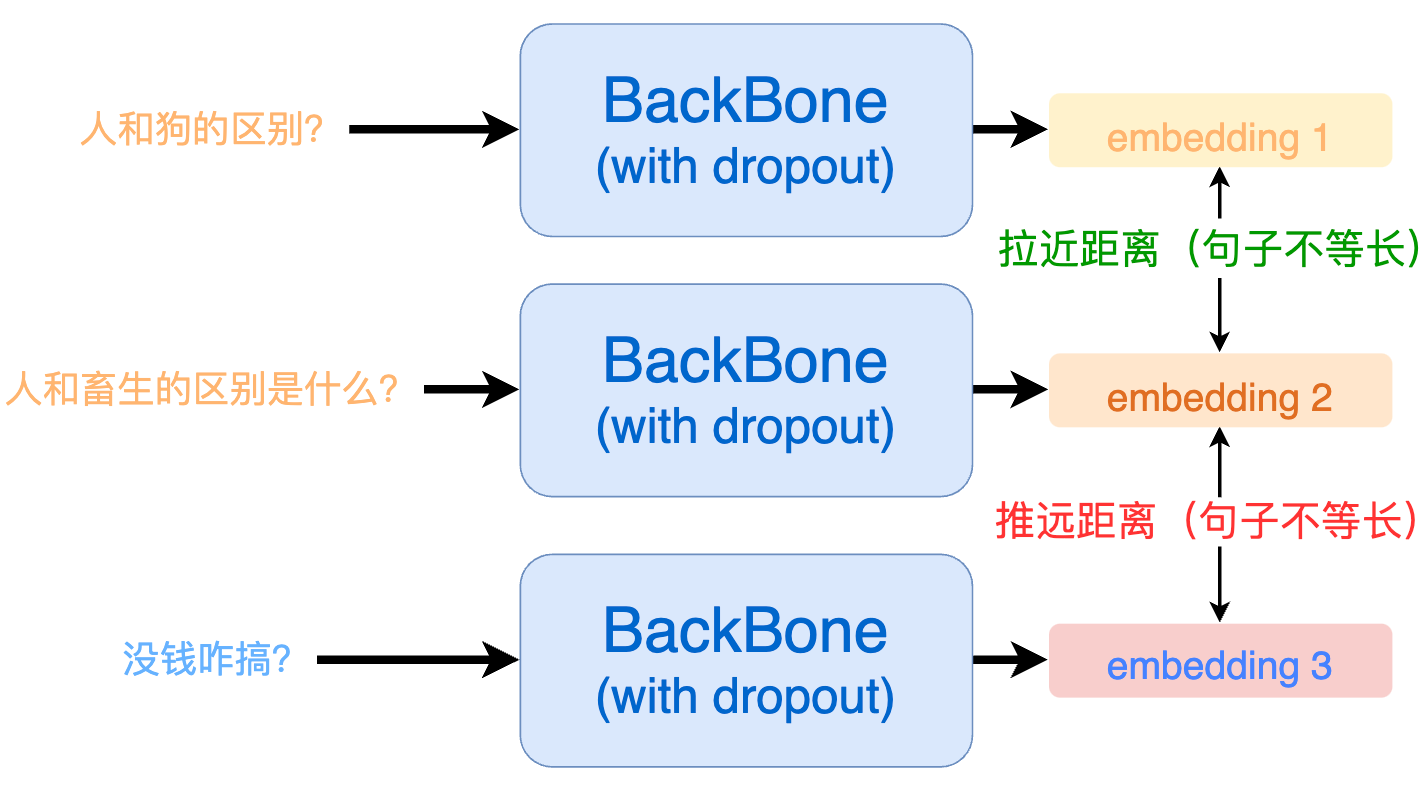
那么,改变句子长度通常有 3 种方法:随机删除、随机添加、同义词替换,但它们均存在句意变化的风险:
| 方法 | 原句子 | 变换后的句子 | 句意是否改变 |
|---|---|---|---|
| 随机删除 | 我 [不] 喜欢你 | 我喜欢你 | 是 |
| 随机添加 | 今天的饭好吃 | 今天的饭 [不] 好吃 | 是 |
| 同义词替换 | 小明长得像一只 [狼] | 小明长得像一只 [狗] | 是 |
用语义变换后的句子去构建正例,模型效果自然会受到影响。
那如果我们随机重复一些单词呢?
| 方法 | 原句子 | 变换后的句子 | 句意是否改变 |
|---|---|---|---|
| 随机重复单词 | 今天天气很好 | 今今天天气很好好 | 否 |
| 随机重复单词 | 我喜欢你 | 我我喜欢欢你 | 否 |
可以看到,通过随机重复单词,既能够改变句子长度,又不会轻易改变语义。
实现上,假设我们有一个 batch 的句子,我们先依次将每一个句子都进行随机单词重复(产生正例),如下:
origin -> ['人和畜生的区别', '今天天气很好', '三星手机屏幕是不是最好的?']
repetition -> ['人人和畜生的的区别', '今今天天气很好好', '三星星手机屏屏幕是不是最最好好的?']
随后,我们将 origin 的 embedding(batch,768) 和 repetition 的 embedding(batch,768)做矩阵乘法,可以得到一个矩阵(batch,batch),矩阵对角线上就是正例,其余的均是负例:
| 句子 a | 句子 b | 句子 c | |
|---|---|---|---|
| 句子 a | 0.9248 | 0.2342 | 0.4242 |
| 句子 b | 0.3142 | 0.9123 | 0.1422 |
| 句子 c | 0.2903 | 0.1857 | 0.9983 |
矩阵中第(i,j)个元素代表 origin 列表中的第 i 个元素和 repetition 列表中第 j 个元素的相似度。
接下来就好构建训练标签了,因为 label 都在对角线上,所以第 n 行的 label 就是 n 。
labels = [i for i in range(len(origin))] # labels = [0, 1, 2]
之后就用 CrossEntropyLoss 去计算并梯度回传就能开始训练啦。
def forward(
self,
query_input_ids: torch.tensor,
query_token_type_ids: torch.tensor,
doc_input_ids: torch.tensor,
doc_token_type_ids: torch.tensor,
device='cpu'
) -> torch.tensor:
"""
传入query/doc对,构建正/负例并计算contrastive loss。
Args:
query_input_ids (torch.LongTensor): (batch, seq_len)
query_token_type_ids (torch.LongTensor): (batch, seq_len)
doc_input_ids (torch.LongTensor): (batch, seq_len)
doc_token_type_ids (torch.LongTensor): (batch, seq_len)
device (str): 使用设备
Returns:
torch.tensor: (1)
"""
query_embedding = self.get_pooled_embedding(
input_ids=query_input_ids,
token_type_ids=query_token_type_ids
) # (batch, self.output_embedding_dim)
doc_embedding = self.get_pooled_embedding(
input_ids=doc_input_ids,
token_type_ids=doc_token_type_ids
) # (batch, self.output_embedding_dim)
cos_sim = torch.matmul(query_embedding, doc_embedding.T) # (batch, batch)
margin_diag = torch.diag(torch.full( # (batch, batch), 只有对角线等于margin值的对角矩阵
size=[query_embedding.size()[0]],
fill_value=self.margin
)).to(device)
cos_sim = cos_sim - margin_diag # 主对角线(正例)的余弦相似度都减掉 margin
cos_sim *= self.scale # 缩放相似度,便于收敛
labels = torch.arange( # 只有对角上为正例,其余全是负例,所以这个batch样本标签为 -> [0, 1, 2, ...]
0,
query_embedding.size()[0],
dtype=torch.int64
).to(device)
loss = self.criterion(cos_sim, labels)
return loss
4.DiffCSE
结合句子间差异的无监督句子嵌入对比学习方法——DiffCSE主要还是在SimCSE上进行优化(可见SimCSE的重要性),通过ELECTRA模型的生成伪造样本和RTD(Replaced Token Detection)任务,来学习原始句子与伪造句子之间的差异,以提高句向量表征模型的效果。
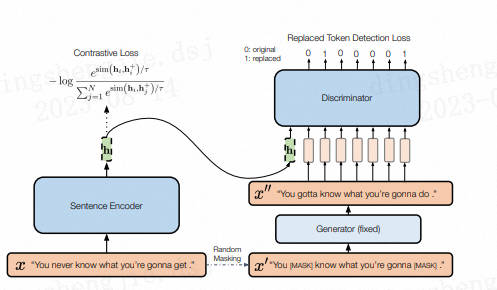
其思想同样来自于CV领域(采用不变对比学习和可变对比学习相结合的方法可以提高图像表征的效果)。作者提出使用基于dropout masks机制的增强作为不敏感转换学习对比学习损失和基于MLM语言模型进行词语替换的方法作为敏感转换学习「原始句子与编辑句子」之间的差异,共同优化句向量表征。
在SimCSE模型中,采用pooler层(一个带有tanh激活函数的全连接层)作为句子向量输出。该论文发现,采用带有BN的两层pooler效果更为突出,BN在SimCSE模型上依然有效。
①对于掩码概率,经实验发现,在掩码概率为30%时,模型效果最优。
②针对两个损失之间的权重值,经实验发现,对比学习损失为RTD损失200倍时,模型效果最优。
参考链接:https://blog.csdn.net/PX2012007/article/details/127696477
5. 数据集准备
项目中提供了一部分示例数据,我们使用未标注的用户搜索记录数据来训练一个文本匹配模型,数据在 data/LCQMC 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
- 训练集:
喜欢打篮球的男生喜欢什么样的女生
我手机丢了,我想换个手机
大家觉得她好看吗
晚上睡觉带着耳机听音乐有什么害处吗?
学日语软件手机上的
...
- 测试集:
开初婚未育证明怎么弄? 初婚未育情况证明怎么开? 1
谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌 0
人和畜生的区别是什么? 人与畜生的区别是什么! 1
男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩 0
...
由于是无监督训练,因此训练集(train.txt)中不需要记录标签,只需要大量的文本即可。
测试集(dev.tsv)用于测试无监督模型的效果,因此需要包含真实标签。
每一行用 \t 分隔符分开,第一部分部分为句子A,中间部分为句子B,最后一部分为两个句子是否相似(label)。
6.模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python train.py \
--model "nghuyong/ernie-3.0-base-zh" \
--train_path "data/LCQMC/train.txt" \
--dev_path "data/LCQMC/dev.tsv" \
--save_dir "checkpoints/LCQMC" \
--img_log_dir "logs/LCQMC" \
--img_log_name "ERNIE-ESimCSE" \
--learning_rate 1e-5 \
--dropout 0.3 \
--batch_size 64 \
--max_seq_len 64 \
--valid_steps 400 \
--logging_steps 50 \
--num_train_epochs 8 \
--device "cuda:0"
正确开启训练后,终端会打印以下信息:
...
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 226.41it/s]
DatasetDict({
train: Dataset({
features: ['text'],
num_rows: 477532
})
dev: Dataset({
features: ['text'],
num_rows: 8802
})
})
global step 50, epoch: 1, loss: 0.34367, speed: 2.01 step/s
global step 100, epoch: 1, loss: 0.19121, speed: 2.02 step/s
global step 150, epoch: 1, loss: 0.13498, speed: 2.00 step/s
global step 200, epoch: 1, loss: 0.10696, speed: 1.99 step/s
global step 250, epoch: 1, loss: 0.08858, speed: 2.02 step/s
global step 300, epoch: 1, loss: 0.07613, speed: 2.02 step/s
global step 350, epoch: 1, loss: 0.06673, speed: 2.01 step/s
global step 400, epoch: 1, loss: 0.05954, speed: 1.99 step/s
Evaluation precision: 0.58459, recall: 0.87210, F1: 0.69997, spearman_corr:
0.36698
best F1 performence has been updated: 0.00000 --> 0.69997
global step 450, epoch: 1, loss: 0.25825, speed: 2.01 step/s
global step 500, epoch: 1, loss: 0.27889, speed: 1.99 step/s
global step 550, epoch: 1, loss: 0.28029, speed: 1.98 step/s
global step 600, epoch: 1, loss: 0.27571, speed: 1.98 step/s
global step 650, epoch: 1, loss: 0.26931, speed: 2.00 step/s
...
在 logs/LCQMC 文件下将会保存训练曲线图:
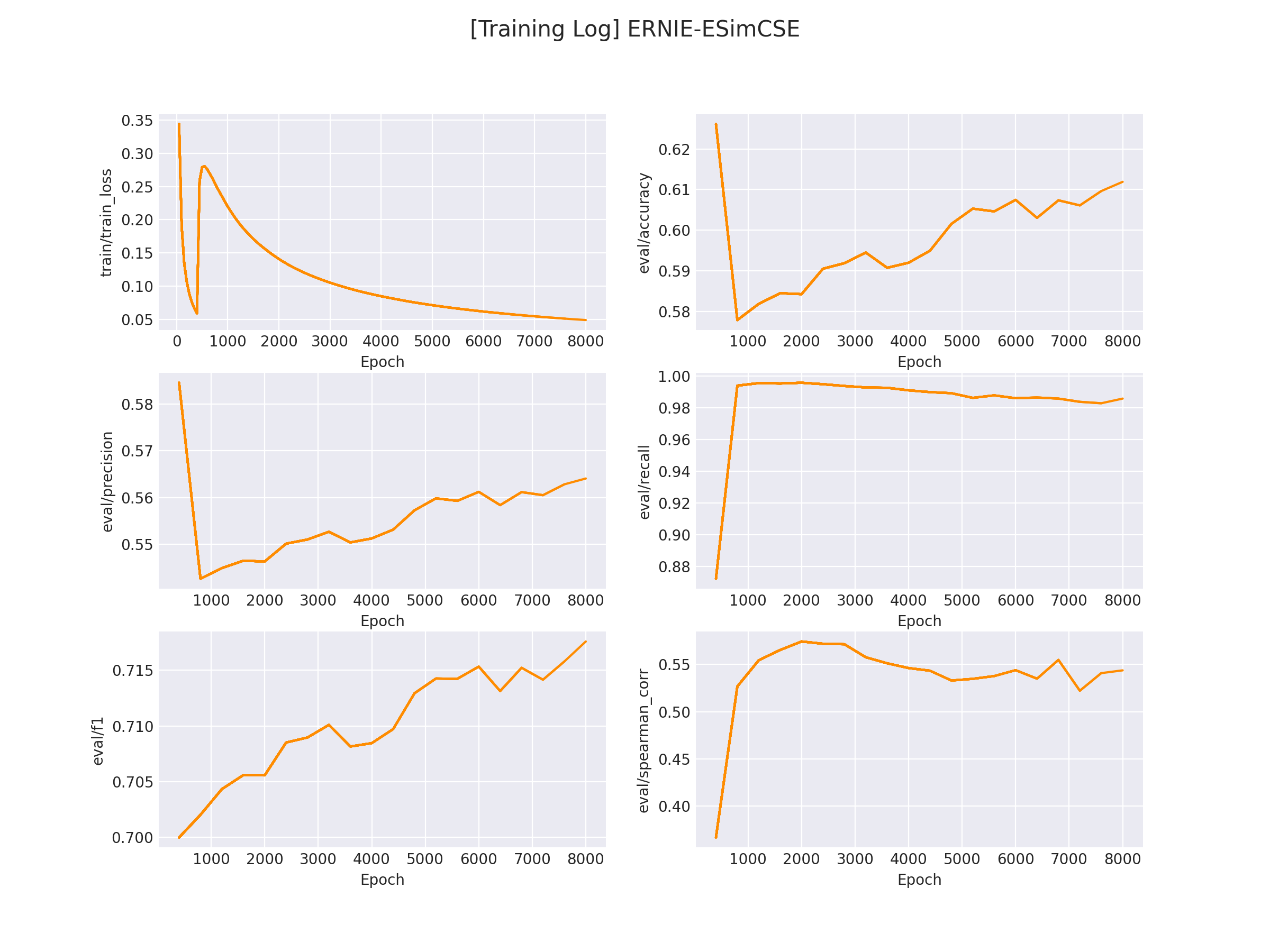
7.模型推理
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
...
if __name__ == '__main__':
...
sentence_pair = [
('男孩喝女孩的故事', '怎样才知道是生男孩还是女孩'),
('这种图片是用什么软件制作的?', '这种图片制作是用什么软件呢?')
]
...
res = inference(query_list, doc_list, model, tokenizer, device)
print(res)
运行推理程序:
python inference.py
得到以下推理结果:
[0.1527191698551178, 0.9263839721679688] # 第一对文本相似分数较低,第二对文本相似分数较高
参考链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/text_matching/supervised
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践的更多相关文章
- 【转】有监督训练 & 无监督训练
原文链接:http://m.blog.csdn.net/article/details?id=49591213 1. 前言 在学习深度学习的过程中,主要参考了四份资料: 台湾大学的机器学习技法公开课: ...
- 转:Deep learning系列(十五)有监督和无监督训练
http://m.blog.csdn.net/article/details?id=49591213 1. 前言 在学习深度学习的过程中,主要参考了四份资料: 台湾大学的机器学习技法公开课: Andr ...
- 跨模态语义关联对齐检索-图像文本匹配(Image-Text Matching)
论文介绍:Negative-Aware Attention Framework for Image-Text Matching (基于负感知注意力的图文匹配,CVPR2022) 代码主页:https: ...
- UFLDL深度学习笔记 (三)无监督特征学习
UFLDL深度学习笔记 (三)无监督特征学习 1. 主题思路 "UFLDL 无监督特征学习"本节全称为自我学习与无监督特征学习,和前一节softmax回归很类似,所以本篇笔记会比较 ...
- 特定领域知识图谱融合方案:文本匹配算法(Simnet、Simcse、Diffcse)
特定领域知识图谱融合方案:文本匹配算法(Simnet.Simcse.Diffcse) 本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5 ...
- text matching(文本匹配) 相关资料总结
最近工作上需要做句子语义去重相关的工作,本质上这是属于NLP中text matching(文本匹配)相关的内容.因此我花了一些时间整理了一些关于这个方向的资料,整理如下(也许会持续更新): BiMPM ...
- 将句子表示为向量(上):无监督句子表示学习(sentence embedding)
1. 引言 word embedding技术如word2vec,glove等已经广泛应用于NLP,极大地推动了NLP的发展.既然词可以embedding,句子也应该可以(其实,万物皆可embeddin ...
- NLP文本分类
引言 其实最近挺纠结的,有一点点焦虑,因为自己一直都期望往自然语言处理的方向发展,梦想成为一名NLP算法工程师,也正是我喜欢的事,而不是为了生存而工作.我觉得这也是我这辈子为数不多的剩下的可以自己去追 ...
- LUSE: 无监督数据预训练短文本编码模型
LUSE: 无监督数据预训练短文本编码模型 1 前言 本博文本应写之前立的Flag:基于加密技术编译一个自己的Python解释器,经过半个多月尝试已经成功,但考虑到安全性问题就不公开了,有兴趣的朋友私 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- python argparse传入布尔参数不生效解决
前言 在一个需要用到flag作为信号控制代码中一些代码片段是否运行的,比如"--flag True"或者"--flag False". 但是古怪的是无法传入Fa ...
- 叫板GPT-4的Gemini,我做了一个聊天网页,可图片输入,附教程
先看效果: 简介 Gemini 是谷歌研发的最新一代大语言模型,目前有三个版本,被称为中杯.大杯.超大杯,Gemini Ultra 号称可与GPT-4一较高低: Gemini Nano(预览访问) 为 ...
- 【Django-Vue】手机号是否存在接口 多方式登录接口 腾讯云短信介绍和申请 api与sdk
目录 昨日回顾 今日内容 0 登录注册功能设计 1 短信登录接口 视图类 2 多方式密码登录接口 视图类 序列化类 路由 3 腾讯云短信介绍和申请 3.1api与sdk 补充 练习 昨日回顾 # 你的 ...
- 为什么 Serverless 能提升资源利用率?
木吴|阿里云智能高级技术专家 业务的负载往往不是一成不变的,而是随着时间呈现一定的上下波动.传统的应用构建方式一般是备足充分的资源以保障业务可用性,造成资源利用率不高的现象.随着容器技术的普及,应用可 ...
- [吉他谱]duvet
- Vue第一篇 ES6的常用语法
01-变量的定义 <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- 非标准库--conio.h库
1.getch函数 主要内容 int getch(void): 所在头文件:conio.h 函数用途:从控制台读取一个字符,但不显示在屏幕上,即一个不需要通过ENTER确定的getchar. 函数原型 ...
- Kafka 社区KIP-382中文译文(MirrorMaker2/集群复制/高可用/灾难恢复)
译者:对于Kafka高可用的课题,我想每个公司都有自己的方案及思考,这是一个仁者见仁智者见智的命题,而社区给出了一个较大的特性,即MirrorMaker 2.0,不论是准备做高可用还是单纯的数据备份, ...
- mysq-DQL-过滤条件-where
- ext4 扩容磁盘的方式方法
ext4 扩容磁盘的方式方法 背景 前期一直处理xfs,lvm磁盘的扩容 很少处理ext4的磁盘扩容 今天发现自己竟然对这一块有盲区. 晚上回家自己学习研究了会儿, 发现知识点还挺多 所以总结一下. ...