logstash配置文件
1. 安装 logstash
安装过程很简单,直接参照官方文档: https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# vim /etc/yum.repos.d/logstash.repo
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# sudo yum install logstash # ln -s /usr/share/logstash/bin/logstash /usr/bin/logstash # 可以对logstash可执行文件建立一个软链接,便于直接使用logstash命令
2. logstash配置文件说明 logstash
logstash.yml 主配置文件
# cat /etc/logstash/logstash.yml |grep -v ^#
path.data: /data/logstash #数据存储路径
path.config: /etc/logstash/conf.d/*.conf #配置文件目录
path.logs: /var/log/logstash #日志输出路径
# mkdir -p /data/logstash #创建data目录
# chown logstash.logstash /data/logstash #授权
jvm.options 这个配置文件是有关jvm的配置,可以配置运行时内存的最大最小值,垃圾清理机制等
-Xms256m #设置内存大小
-Xmx256m
startup.options logstash运行相关的参数
配置文件是写在/etc/logstash/conf.d/ 下,以.conf结尾。
3. logstash配置文件
logstash pipeline 包含两个必须的元素:input和output,和一个可选元素:filter。
从input读取事件源,(经过filter解析和处理之后),从output输出到目标存储库(elasticsearch或其他)。
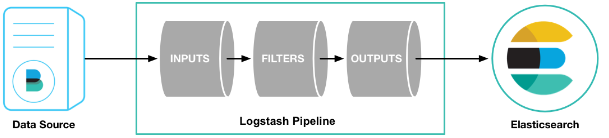
运行一个最基本的logstash测试一下:
# logstash -e'input {stdin {}} output {stdout {}}'
看到 - Successfully started Logstash API endpoint {:port=>9600} 这条信息后 说明logstash已经成功启动,这时输入你要测试的内容
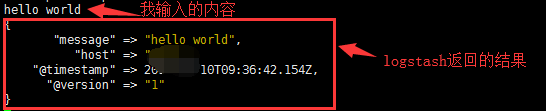
这只是一个测试事件,生产环境使用logstash,一般使用都将配置写入文件里面,然后启动logstash。
例如,我要处理nginx日志,我先在/etc/logstash/conf.d 下创建一个 nginx_access.conf的日志。
# cat nginx_access.conf
input{
file{
path => "/var/log/nginx/access.log"
start_position => "beginning"
type => "nginx_access_log"
}
}
filter{
grok{
match => {"message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) \"(?:-|%{DATA:referrer})\" \"%{DATA:user_agent}\" (?:%{IP:proxy}|-) %{DATA:upstream_addr} %{NUMBER:upstream_request_time:float} %{NUMBER:upstream_response_time:float}"}
match => {"message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) \"%{DATA:referrer}\" \"%{DATA:user_agent}\" \"%{DATA:proxy}\""}
}
if [request] {
urldecode {
field => "request"
}
ruby {
init => "@kname = ['url_path','url_arg']"
code => "
new_event = LogStash::Event.new(Hash[@kname.zip(event.get('request').split('?'))])
event.append(new_event)"
}
if [url_arg] {
ruby {
init => "@kname = ['key', 'value']"
code => "event.set('url_args', event.get('url_arg').split('&').collect {|i| Hash[@kname.zip(i.split('='))]})"
}
}
}
geoip{
source => "clientip"
}
useragent{
source => "user_agent"
target => "ua"
remove_field => "user_agent"
}
date {
match => ["timestamp","dd/MMM/YYYY:HH:mm:ss Z"]
locale => "en"
}
mutate{
remove_field => ["message","timestamp","request","url_arg"]
}
}
output{
elasticsearch {
hosts => "localhost:9200"
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
# stdout {
# codec => rubydebug
# }
}
如果是想测试配置文件写的是否正确,用下面这个方式启动测试一下
/usr/share/logstash/bin/logstash -t -f /etc/logstash/conf.d/nginx.conf #测试配置文件
Configuration OK
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/nginx_access.conf #启动logstash
启动logstash
# systemctl start logstash
logstash的配置详解
input plugin 让logstash可以读取特定的事件源。
官网:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
事件源可以是从stdin屏幕输入读取,可以从file指定的文件,也可以从es,filebeat,kafka,redis等读取
- stdin 标准输入
- file 从文件读取数据
file{
path => ['/var/log/nginx/access.log'] #要输入的文件路径
type => 'nginx_access_log'
start_position => "beginning"
}
# path 可以用/var/log/*.log,/var/log/**/*.log,如果是/var/log则是/var/log/*.log
# type 通用选项. 用于激活过滤器
# start_position 选择logstash开始读取文件的位置,begining或者end。
还有一些常用的例如:discover_interval,exclude,sincedb_path,sincedb_write_interval等可以参考官网 - syslog 通过网络将系统日志消息读取为事件
syslog{
port =>""
type => "syslog"
}
# port 指定监听端口(同时建立TCP/UDP的514端口的监听) #从syslogs读取需要实现配置rsyslog:
# cat /etc/rsyslog.conf 加入一行
*.* @172.17.128.200:514 #指定日志输入到这个端口,然后logstash监听这个端口,如果有新日志输入则读取
# service rsyslog restart #重启日志服务 - beats 从Elastic beats接收事件
beats {
port => 5044 #要监听的端口
}
# 还有host等选项 # 从beat读取需要先配置beat端,从beat输出到logstash。
# vim /etc/filebeat/filebeat.yml
..........
output.logstash:
hosts: ["localhost:5044"] - kafka 将 kafka topic 中的数据读取为事件
kafka{
bootstrap_servers=> "kafka01:9092,kafka02:9092,kafka03:9092"
topics => ["access_log"]
group_id => "logstash-file"
codec => "json"
}kafka{
bootstrap_servers=> "kafka01:9092,kafka02:9092,kafka03:9092"
topics => ["weixin_log","user_log"]
codec => "json"
}# bootstrap_servers 用于建立群集初始连接的Kafka实例的URL列表。
# topics 要订阅的主题列表,kafka topics
# group_id 消费者所属组的标识符,默认为logstash。kafka中一个主题的消息将通过相同的方式分发到Logstash的group_id
# codec 通用选项,用于输入数据的编解码器。
还有很多的input插件类型,可以参考官方文档来配置。
filter plugin 过滤器插件,对事件执行中间处理
- grok 解析文本并构造 。把非结构化日志数据通过正则解析成结构化和可查询化
grok {
match => {"message"=>"^%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) %{QS:referrer} %{QS:agent}$"}
}
匹配nginx日志
# 203.202.254.16 - - [22/Jun/2018:16:12:54 +0800] "GET / HTTP/1.1" 200 3700 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.7 (KHTML, like Gecko) Version/9.1.2 Safari/601.7.7"
#220.181.18.96 - - [13/Jun/2015:21:14:28 +0000] "GET /blog/geekery/xvfb-firefox.html HTTP/1.1" 200 10975 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" - 注意这里grok 可以有多个match匹配规则,如果前面的匹配失败可以使用后面的继续匹配。例如
grok {
match => ["message", "%{IP:clientip} - %{USER:user} \[%{HTTPDATE:raw_datetime}\] \"(?:%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion})\" (?:\"%{DATA:body}\" )?(?:\"%{DATA:cookie}\" )?%{NUMBER:response} (?:%{NUMBER:bytes:int}|-) \"%{DATA:referrer}\" \"%{DATA:agent}\" (?:(%{IP:proxy},? ?)*|-|unknown) (?:%{DATA:upstream_addr} |)%{NUMBER:request_time:float} (?:%{NUMBER:upstream_time:float}|-)"]
match => ["message", "%{IP:clientip} - %{USER:user} \[%{HTTPDATE:raw_datetime}\] \"(?:%{WORD:verb} %{URI:request} HTTP/%{NUMBER:httpversion})\" (?:\"%{DATA:body}\" )?(?:\"%{DATA:cookie}\" )?%{NUMBER:response} (?:%{NUMBER:bytes:int}|-) \"%{DATA:referrer}\" \"%{DATA:agent}\" (?:(%{IP:proxy},? ?)*|-|unknown) (?:%{DATA:upstream_addr} |)%{NUMBER:request_time:float} (?:%{NUMBER:upstream_time:float}|-)"]
}
grok 语法:%{SYNTAX:SEMANTIC} 即 %{正则:自定义字段名}
官方提供了很多正则的grok pattern可以直接使用 :https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns
grok debug工具: http://grokdebug.herokuapp.com
正则表达式调试工具: https://www.debuggex.com/
正则学习文档:https://www.jb51.net/tools/zhengze.html
自定义模式: (?<字段名>the pattern)
例如: 匹配 2018/06/27 14:00:54
(?<datetime>\d\d\d\d\/\d\d\/\d\d \d\d:\d\d:\d\d)
得到结果: "datetime": "2018/06/27 14:00:54"
- date 日期解析 解析字段中的日期,然后转存到@timestamp
[2018-07-04 17:43:35,503]
grok{
match => {"message"=>"%{DATA:raw_datetime}"}
}
date{
match => ["raw_datetime","YYYY-MM-dd HH:mm:ss,SSS"]
remove_field =>["raw_datetime"]
} #将raw_datetime存到@timestamp 然后删除raw_datetime #24/Jul/2018:18:15:05 +0800
date {
match => ["timestamp","dd/MMM/YYYY:HH:mm:ss Z]
} #
date{
match => ["sql_timestamp","UNIX"]
locale => "en"
} - mutate 对字段做处理 重命名、删除、替换和修改字段。
- covert 类型转换。类型包括:integer,float,integer_eu,float_eu,string和boolean
filter{
mutate{
# covert => ["response","integer","bytes","float"] #数组的类型转换
convert => {"message"=>"integer"}
}
}
#测试------->
{
"host" => "localhost",
"message" => 123, #没带“”,int类型
"@timestamp" => 2018-06-26T02:51:08.651Z,
"@version" => ""
} - split 使用分隔符把字符串分割成数组
mutate{
split => {"message"=>","}
}
#---------->
aaa,bbb
{
"@timestamp" => 2018-06-26T02:40:19.678Z,
"@version" => "",
"host" => "localhost",
"message" => [
[0] "aaa",
[1] "bbb"
]}
192,128,1,100
{
"host" => "localhost",
"message" => [
[0] "",
[1] "",
[2] "",
[3] ""
],
"@timestamp" => 2018-06-26T02:45:17.877Z,
"@version" => ""
} - merge 合并字段 。数组和字符串 ,字符串和字符串
filter{
mutate{
add_field => {"field1"=>"value1"}
}
mutate{
split => {"message"=>"."} #把message字段按照.分割
}
mutate{
merge => {"message"=>"field1"} #将filed1字段加入到message字段
}
}
#--------------->
abc
{
"message" => [
[0] "abc,"
[1] "value1"
],
"@timestamp" => 2018-06-26T03:38:57.114Z,
"field1" => "value1",
"@version" => "",
"host" => "localhost"
} abc,.123
{
"message" => [
[0] "abc,",
[1] "",
[2] "value1"
],
"@timestamp" => 2018-06-26T03:38:57.114Z,
"field1" => "value1",
"@version" => "",
"host" => "localhost"
} - rename 对字段重命名
filter{
mutate{
rename => {"message"=>"info"}
}
}
#-------->
123
{
"@timestamp" => 2018-06-26T02:56:00.189Z,
"info" => "",
"@version" => "",
"host" => "localhost"
} - remove_field 移除字段
mutate {
remove_field => ["message","datetime"]
} - join 用分隔符连接数组,如果不是数组则不做处理
mutate{
split => {"message"=>":"}
}
mutate{
join => {"message"=>","}
}
------>
abc:123
{
"@timestamp" => 2018-06-26T03:55:41.426Z,
"message" => "abc,123",
"host" => "localhost",
"@version" => ""
}
aa:cc
{
"@timestamp" => 2018-06-26T03:55:47.501Z,
"message" => "aa,cc",
"host" => "localhost",
"@version" => ""
} - gsub 用正则或者字符串替换字段值。仅对字符串有效
mutate{
gsub => ["message","/","_"] #用_替换/
} ------>
a/b/c/
{
"@version" => "",
"message" => "a_b_c_",
"host" => "localhost",
"@timestamp" => 2018-06-26T06:20:10.811Z
} - update 更新字段。如果字段不存在,则不做处理
mutate{
add_field => {"field1"=>"value1"}
}
mutate{
update => {"field1"=>"v1"}
update => {"field2"=>"v2"} #field2不存在 不做处理
}
---------------->
{
"@timestamp" => 2018-06-26T06:26:28.870Z,
"field1" => "v1",
"host" => "localhost",
"@version" => "",
"message" => "a"
} - replace 更新字段。如果字段不存在,则创建
mutate{
add_field => {"field1"=>"value1"}
}
mutate{
replace => {"field1"=>"v1"}
replace => {"field2"=>"v2"}
}
---------------------->
{
"message" => "",
"host" => "localhost",
"@timestamp" => 2018-06-26T06:28:09.915Z,
"field2" => "v2", #field2不存在,则新建
"@version" => "",
"field1" => "v1"
}
- gsub 用正则或者字符串替换字段值。仅对字符串有效
- geoip 根据来自Maxmind GeoLite2数据库的数据添加有关IP地址的地理位置的信息
geoip {
source => "clientip"
database =>"/tmp/GeoLiteCity.dat"
} - ruby ruby插件可以执行任意Ruby代码
filter{
urldecode{
field => "message"
}
ruby {
init => "@kname = ['url_path','url_arg']"
code => "
new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('?'))])
event.append(new_event)"
}
if [url_arg]{
kv{
source => "url_arg"
field_split => "&"
target => "url_args"
remove_field => ["url_arg","message"]
}
}
}
# ruby插件
# 以?为分隔符,将request字段分成url_path和url_arg
-------------------->
www.test.com?test
{
"url_arg" => "test",
"host" => "localhost",
"url_path" => "www.test.com",
"message" => "www.test.com?test",
"@version" => "",
"@timestamp" => 2018-06-26T07:31:04.887Z
}
www.test.com?title=elk&content=学习elk
{
"url_args" => {
"title" => "elk",
"content" => "学习elk"
},
"host" => "localhost",
"url_path" => "www.test.com",
"@version" => "",
"@timestamp" => 2018-06-26T07:33:54.507Z
} - urldecode 用于解码被编码的字段,可以解决URL中 中文乱码的问题
urldecode{
field => "message"
} # field :指定urldecode过滤器要转码的字段,默认值是"message"
# charset(缺省): 指定过滤器使用的编码.默认UTF-8 - kv 通过指定分隔符将字符串分割成key/value
kv{
prefix => "url_" #给分割后的key加前缀
target => "url_ags" #将分割后的key-value放入指定字段
source => "message" #要分割的字段
field_split => "&" #指定分隔符
remove_field => "message"
}
-------------------------->
a=1&b=2&c=3
{
"host" => "localhost",
"url_ags" => {
"url_c" => "",
"url_a" => "",
"url_b" => ""
},
"@version" => "",
"@timestamp" => 2018-06-26T07:07:24.557Z - useragent 添加有关用户代理(如系列,操作系统,版本和设备)的信息
if [agent] != "-" {
useragent {
source => "agent"
target => "ua"
remove_field => "agent"
}
}
# if语句,只有在agent字段不为空时才会使用该插件
#source 为必填设置,目标字段
#target 将useragent信息配置到ua字段中。如果不指定将存储在根目录中
logstash 比较运算符
等于: ==, !=, <, >, <=, >=
正则: =~, !~ (checks a pattern on the right against a string value on the left)
包含关系: in, not in
支持的布尔运算符:and, or, nand, xor
支持的一元运算符: !
output plugin 输出插件,将事件发送到特定目标。over
- stdout 标准输出。将事件输出到屏幕上
output{
stdout{
codec => "rubydebug"
}
} - file 将事件写入文件
file {
path => "/data/logstash/%{host}/{application}
codec => line { format => "%{message}"} }
} - kafka 将事件发送到kafka
kafka{
bootstrap_servers => "localhost:9092"
topic_id => "test_topic" #必需的设置。生成消息的主题
} - elasticseach 在es中存储日志
elasticsearch {
hosts => "localhost:9200"
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
#index 事件写入的索引。可以按照日志来创建索引,以便于删旧数据和按时间来搜索日志
补充一个codec plugin 编解码器插件
codec 本质上是流过滤器,可以作为input 或output 插件的一部分运行。例如上面output的stdout插件里有用到。
- multiline codec plugin 多行合并, 处理堆栈日志或者其他带有换行符日志需要用到
input {
stdin {
codec => multiline {
pattern => "pattern, a regexp" #正则匹配规则,匹配到的内容按照下面两个参数处理
negate => "true" or "false" # 默认为false。处理匹配符合正则规则的行。如果为true,处理不匹配符合正则规则的行。
what => "previous" or "next" #指定上下文。将指定的行是合并到上一行或者下一行。
}
}
}
codec => multiline {
pattern => "^\s"
what => "previous"
}
# 以空格开头的行都合并到上一行 codec => multiline {
# Grok pattern names are valid! :)
pattern => "^%{TIMESTAMP_ISO8601} "
negate => true
what => "previous"
}
# 任何不以这个时间戳格式开头的行都与上一行合并 codec => multiline {
pattern => "\\$"
what => "next"
}
# 以反斜杠结尾的行都与下一行合并
logstash配置文件的更多相关文章
- Logstash配置文件介绍
Logstash配置文件介绍 Logstash配置文件有两种,分别是pipeline配置文件和setting配置文件. Pipeline配置文件主要定义logstash使用的插件以及每个插件的设置,定 ...
- Logstash配置文件详情
logstash 配置文件编写详解 说明 它一个有jruby语言编写的运行在java虚拟机上的具有收集分析转发数据流功能的工具能集中处理各种类型的数据能标准化不通模式和格式的数据能快速的扩展自定义日志 ...
- logstash 配置文件实例
这个配置文件记不起来是从那个地方下载的来的了,感谢那位无私的朋友 input { beats { #shipper 端用的是 filebeat,所以用这个插件 port ...
- 【ELK】抓取AWS-ELB日志的logstash配置文件
前言 ELK搭建没有难度,难的是logstash的配置文件,logstash主要分为三个部分,input,filter和output. input,输入源可选的输入源由很多,详情见ELK官网,这里我们 ...
- ELK之Logstash配置文件详解
Logstash 是一个开源的数据收集引擎,它具有备实时数据传输能力.它可以统一过滤来自不同源的数据,并按照开发者的制定的规范输出到目的地.它以插件的形式来组织功能,通过配置文件来描述需要插件做什么, ...
- logstash配置文件详解
logstash pipeline 包含两个必须的元素:input和output,和一个可选元素:filter. 从input读取事件源,(经过filter解析和处理之后),从output输出到目标 ...
- logstash 配置文件语法
需要一个配置文件 管理输入.过滤器和输出相关的配置.配置文件内容格式如下: # 输入 input { ... } # 过滤器 filter { ... } # 输出 output { ... } 先来 ...
- Logstash配置文件修改自动加载和指定目录进行启动
检查配置并启动Logstash,修改后自动加载 指定配置文件目录并启动Logstash
- 轻松测试 logstash 的配置文件
配置文件本身非常脆弱!所以修改配置文件自然会引入部署失败的风险.如果能够对配置文件进行自动化测试将会极大的降低这种风险.本文将介绍一个可以自动化测试 logstash 配置文件的工具,让大家可以像写单 ...
随机推荐
- dp小结|背包问题
1.先放上0-1背包模板 二维数组 for(int i=1;i<=n;i++)//枚举 物品 for(int j=1;j<=V;j++)//枚举体积 //这个位置是可以正序枚举的. qwq ...
- MetInfo V5.1 GetShell一键化工具
# 漏洞解析: config/config.inc.php $langoks = $db->get_one("SELECT * FROM $met_lang WHERE lang='$ ...
- Java日期时间(Date/Time)
获取当前日期和时间 在Java中容易得到当前的日期和时间.可以使用一个简单的Date对象的toString()方法,如下所示打印当前日期和时间: import java.util.Date; publ ...
- 论文笔记:Person Re-identification with Deep Similarity-Guided Graph Neural Network
Person Re-identification with Deep Similarity-Guided Graph Neural Network 2018-07-27 17:41:45 Paper: ...
- Tutorials on training the Skip-thoughts vectors for features extraction of sentence.
Tutorials on training the Skip-thoughts vectors for features extraction of sentence. 1. Send emails ...
- 浅谈IIS 和 asp.net的应用之间的关系
IIS可以理解为一个web服务器. 用于提供web相关的各种服务. IIS6.0中添加了一个新的功能, application pool. application pool的作用是将运行在同一个ser ...
- std::cout << char + int
#include<iostream> int main(){ char ch; std::cout << "Type, and I shall repeat.\n&q ...
- PHP 内置函数fgets读取文件
php fgets()函数从文件指针中读取一行 语法: fgets(file,length) 参数 描述 file 必需.规定尧要读取的文件 length 可选 .规定尧都区的字节数.默认是102字 ...
- 什么是java OOM?如何分析及解决oom问题?
最近查找了很多关于OOM,甚至于Java内存管理以及JVM的相关资料,发现这方面的东西太多了,竟有一种眼花缭乱的感觉,要想了解全面的话,恐非一篇文章能说清的,因此按照自己的理解整理了一篇,剩下的还需要 ...
- JAVA怎样理解面向对象
一.对象 现实世界中,随处可见的一种事物就是对象,对象是事物存在的实体,如人类.书桌.计算机.高楼大厦等.人类解决问题的方式总是将复杂的事物简单化,于是就会思考这些对象都是由哪些部分组成的.通常都 ...