1.无状态应用与有状态应用
应用的有状态和无状态是根据应用是否有持久化保存数据的需求而言的,即持久化保存数据的应用为有状态的应用,反之则为无状态的应用。常见的系统往往是有状态的应用,比如对于微博和微信这类应用,所有用户发布的内容和留言都是要保存记录的。但是一个系统往往是由众多微服务或更小的应用模块构成的。有的微服务或模块其实并没有数据持久化的需求。例如,搭建一个Wordpress博客系统需要部署一个前端的PHP应用,以及一个后端的MySQL数据库。虽然整个博客系统有持久化的需求,是一个有状态的系统,但是其子模块前端PHP应用并没有将数据保存在本地,而是存放到MySQL数据库中。所以一个Wordpress系统可以拆解成一个无状态的前端以及一个有状态的后端。有状态和无状态的应用在现实当中比比皆是。从实例数量上来说,无状态的应用应该会更多一些,因为对大多数的系统而言,读请求的数量往往远远高于写请求的数量。
非持久化的容器
容器的一个特点是当容器退出后,其内部所有的数据和状态就会丢失。同样的镜像再次启动一个新的容器实例,该实例默认不会继承之前实例的状态。这对无状态应用来说不是问题,相反是一个很好的特性,可以很好地保证无状态应用的一致性。但是对于有状态的应用来说则是很大的障碍。试想一下,如果你的MySQL容器每次重启后,之前所有的数据都丢失了,那将会是怎样一种灾难!
容器数据持久化
不可避免地用户会在容器中运行有状态的应用,因此,在容器引擎的层面必须满足数据持久化的需求。Docker在容器引擎的层面提供了卷(Volume)的概念。用户可以建立数据卷容器来为容器提供持久化的支持。容器实例需要将持久化的数据写入数据卷容器中保存。当应用容器退出时,数据仍然安然地在储存于数据卷容器当中。此外Docker以插件的形式支持多种存储方式。通过卷插件(VolumePlugin),目前Docker容器可以对接主机的目录、软件定义存储(如GlusterFS及Ceph)、云存储(如AWS及GCE等公有云提供的云储存)及储存管理解决方案(如Flocker等)。
持久化卷与持久化卷请求
Docker在容器引擎的层面提供了卷的机制来满足容器数据持久化的需求。在多主机的环境下,容器云的场景中需要考虑的细节会更多。比如一个有状态应用的容器实例从一个主机漂移到另一台主机上时,如何保证其所挂载的卷仍然可以被正确对接。此外,在云平台上,用户需要以一种简单方式获取和消费存储这一资源,而无须过度关心底层的实现细节。比如用户有一个应用,需要一个100GB的高速存储空间储存大量的零碎文件。用户需要做的是向云平台提交资源申请,然后获取并消费这个储存资源,而不需要操心底层这个存储究竟是具体来自哪一台储存服务器的哪一块磁盘。
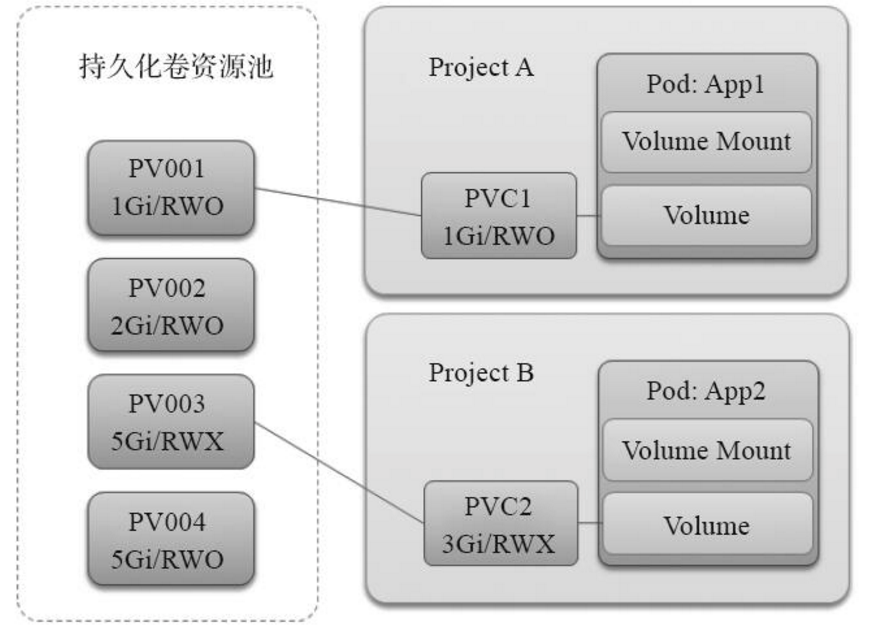
为了满足容器用户在云环境储存的需求。Kubernetes在容器编排的层面提供了持久化卷(PersistentVolume,PV)及持久化卷请求(PersistentVolumeClaim,PVC)的概念。持久化卷定义了具体的储存的连接信息,如NFS服务器的地址和端口、卷的位置、卷的大小及访问方式。在OpenShift中,集群管理员会定义一系列的持久化卷,形成一个持久化卷的资源池。当用户部署有持久化需求的容器应用时,用户需要创建一个持久化卷请求。在这个请求中,用户申明所需储存的大小及访问方式。Kubernetes将负责根据用户的持久化卷请求找到匹配需求的持久化卷进行对接。最终的结果是容器启动后,持久化卷定义的后端储存将会被挂载到容器的指定目录。OpenShift在架构上基于Kubernetes,因此用户可以在OpenShift中使用Kubernetes的持久化卷与持久化卷请求的储存供给模型,以满足数据持久化的需求。
2.持久化卷的生命周期
持久化卷的生命周期一共分为“供给”“绑定”“使用”“回收”及“释放”五个阶段。
1.供给
在Kubernetes中,储存资源的供给分为两种类型:静态供给和动态供给。对于静态供给,集群管理员会创建一些列的持久化卷,形成一个持久化卷的资源池。动态供给是集群所在的基础设施云根据需求动态地创建出持久化卷,如OpenStack、AmazonWebService。
访问方式是描述持久化卷的访问特性,比如是只读还是可读可写。是只能被一个Node节点挂载,还是可以被多个Node节点使用。
目前有三种访问方式可供选择。
·ReadWriteOnce:可读可写,只能被一个Node节点挂载。
·ReadWriteMany:可读可写,可以被多个Node节点挂载。
·ReadOnlyMany:只读,能被多个Node节点挂载。
这里要注意的是,访问方式和后端使用的储存有很大的关系,并不是将一个持久化卷设置为ReadWriteMany,这个持久化卷就可以被多个Node节点挂载。比如OpenStack的Cinder和CephRDB这些块设备就不支持ReadWriteMany这种模式。在Kubernetes的官方文档中对各种后端存储的访问方式有详细的描述。
2.绑定
用户在部署容器应用时会定义持久化卷请求持久化卷请求。用户在持久化卷请求中声明需要的储存资源的特性,如大小和访问方式。Kubernetes负责在持久化卷的资源池中寻找配的持久化卷对象,并将持久化卷请求与目标持久化卷进行对接。这时持久化卷和持久化卷请求的状态都将变成Bound,即绑定状态。
3.使用
在用户部署容器时会在DeploymentConfig的容器定义中指定Volume的挂载点,并将这个挂载点和持久化卷请求关联。当容器启动时,持久化卷指定的后端储存被挂载到容器定义的挂载点上。应用在容器内部运行,数据通过挂载点最终写入后端储存中,从而实现持久化。
4.释放
当应用下线不再使用储存时,可以删除相关的持久化卷请求,这样持久化卷的状态就会变成released,即释放。
5.回收
当持久化卷的状态变为released后,Kubernetes将根据持久化卷定义的回收策略回收持久化卷。
当前支持的回收策略有三种:
·Retian:保留数据,人工回收持久化卷。
·Recycle:通过执行rm-rf删除卷上的所有数据。目前只有NFS及HostPath支持这种方式。
·Delete:动态地删除后端储存。该模式需要下层IaaS的支持,目前AWSEBS、GCEPD及OpenStackCinder支持这种模式。
Kubernetes通过持久化卷及持久化卷请求这一供给模型为用户提供容器云上的储存消费的途径。在这个模型下,用户可以简单快速地构建出满足应用需要的容器云上的储存解决方案。在Kubernetes1.3中,持久化卷和持久化卷请求引入了标签的概念,这了给用户更大的灵活性。例如,我们可以为不同类型的持久化卷贴上不同的标签,如“SSD”“RAID0”“Ceph”“深圳机房”或“美国机房”等。用户在持久化卷请求中可以定义相应的标签选择器,从而获取更精确匹配应用需求的后端持久化卷。
3.持久化卷与储存
Kubernetes的持久化卷支持的后端储存的类型很多,包括宿主机的本地目录(HostPath)、网络文件系统(NFS)、OpenStackCinder分布式储存(如GlusterFS、CephRBD及CephFS)及云储存(如AWSElasticBlockStore或GCEPersistentDisk)等。一个常见的困惑是“我应该选择哪一种储存?”不同的储存后端有不同特性,并不存在一种满足所有场景的储存。用户应该根据当前容器应用的需求,选择满足需求的储存。
1.HostPath
HostPath类型的储存是指容器挂载所在的计算机点主机上的目录。这种方式只适合用于以测试为目的的场景中。允许容器挂载主机目录引入了安全风险。依赖于某一节点上的数据也使得容器和某一计算节点产生了较强的绑定关系性,引入了单点失效的风险。
2.NFS
NFS是一种常用的储存类型。NFS已经存在了很长一段时间,在UNIX和Linux上被广泛应用,所有的Linux系统管理员对它都不会感到陌生。因为系统支持比较广泛,NFS目前是较为常见的持久化卷的储存后端。
3.GlusterFS
GlusterFS是一个开源的分布式文件系统。GlusterFS具有很强的弹性扩展能力,用户可以在通用的计算机硬件上使用GlusterFS构建出PB级别的储存集群用于储存如视频、图片及资料等多种类型的数据。GlusterFS的主要特点是:
·完全基于软件实现。完全不依赖于特定的主机、储存、网络硬件。
·高度弹性扩展。用户可以构建储存的容量从GB到PB级的储存。
·高可用。数据可以在储存集成中保留多个副本,防止单点失效。
·兼容POSIX文件系统标准。基于标准,因此对上层应用进行改造。
·支持多种不同种类的卷。如复制卷、分布式卷及条带卷,满足不同场景的需求。
4.Ceph
Ceph是当前非常流行的开源分布式储存解决方案。和GlusterFS类似,Ceph也是一个完全基于软件实现的分布式储存。Ceph的一个特点是,其原生提供了多种接口方式,如基于RESTful的对象、块(Block)和文件系统。GlusterFS和Ceph都是非常优秀的分布式储存,很多人喜欢将它们进行比较。应该说GlusterFS和Ceph各有优劣,在伯仲之间,青菜萝卜各有所爱。
Kubernetes的持久化卷支持两种方式挂载Ceph储存:块设备(RBD)及文件系统(CephFS)。目前,由于Ceph官方认为CephFS尚未完全成熟以达到企业生产使用的标准,因此虽然Kubernetes和OpenShift的代码中已经存在CephFS的支持,但是并不推荐在生产中使用。
5.OpenStack Cinder
Cinder是OpenStack块储存服务,负责为OpenStack上的主机实例提供灵活的储存支持。对于运行在OpenStack上的OpenShift集群,用户可以定义基于OpenStack Cinder的持久化卷。Cinder持久化卷的定义示例如下。volumeID属性指向了管理员在Cinder创建的数据卷的唯一标识。
4.存储资源定向匹配
不同用户对储存的需求不尽相同,除了大小和访问方式外,可能还有对磁盘的速度、储存所在的数据中心等有特殊的要求。为了灵活满足储存需求和储存资源的对接,Kubernetes支持为持久化卷打上不同的标签(Label),在持久化卷请求侧则通过定义标签选择器来申明该持久化卷请求具体需要与什么样的持久化卷匹配。通过标签和标签选择器(Selector),Kubernetes为持久化卷与持久化卷请求实现了定向匹配。
1 创建持久化卷
创建如下例子中的两个持久化卷pv0001及pv0002。这两个持久化卷具有相同的大小和访问方式,且都没有任何标签。
2 标记标签
通过oc label命令为持久化卷pv0002打上标签disktype=ssd。
3 创建持久化卷请求
创建一个带标签选择器的持久化卷请求。如下面的定义所示,这个持久化卷请求的储存空间大小为1Gi,访问方式是只读共享RWO。标签选择器的类型为matchLabels,定义值为"disktype":"ssd",即表示与该持久化卷请求匹配的持久化卷必须要带有"disktype":"ssd"标签。
4 请求与资源定向匹配
持久化卷请求创建完后,查看持久化卷的状态,可以看到虽然pv0001和pv0002在空间大小和访问方式上都满足了pvc0001的要求,但是pvc0001最终匹配上的是带有目标标签的pv0002。
5 标签选择器
目前,持久化卷请求支持两种标签选择器:matchLabels及matchExpressions。
matchLabels选择器可以精确匹配一个或多个标签。
matchExpressions选择器支持标签的模糊匹配。用户可以使用操作符In或者NotIn对标签的值进行模糊匹配。
5.持久化实例
1 检查挂载点
2 备份数据
在前面章节的示例中已经向Registry推送过不少镜像,所以当前容器内的/registry目录下已经有不少镜像相关的文件。
需要先备份这些文件。通过ocrsync命令,可以将容器中某个目录的数据同步到宿主机上。
oc rsync是一个很方便实用的命令,它可以双向同步容器和宿主机上的文件。要使用这个命令,目标容器内部必须有rync或者tar这两个应用中的一个。
3 创建存储
为了方便实验,本例选用NFS作为后端的储存。在实际的生产中使用GlusterFS、Ceph或其他储存后端的配置过程和步骤也类似。
执行以下命令创建一个NFS的共享目录。
4 创建持久化卷
根据上面创建的NFS的信息,创建持久化卷。在实验主机上将如下JSON保存成文件pv.json。
创建完毕后,通过oc get pv可以查看到刚创建成功的持久化卷,此时它的状态为Available,即可用。
5 创建持久化卷请求
下面将创建持久化卷请求,声明应用的储存需求。在实验主机上将如下JSON保存成文件pvc.json。这里声明了需要3GB的后端储存,访问方式为ReadWriteOnce。
查看持久化卷请求和持久化卷的状态,会发现系统已经将它们连接起来了。持久化卷和持久化卷请求的状态都已经变成Bound。
6 关联持久化卷请求
将备份的数据恢复到前文创建的NFS目录中。
此时,可以测试删除Registry容器,Replication Controller将重新创建它。
容器启动后,再次检查容器/registry目录,会发现目录的数据应消失。因为容器默认是不持久化数据的。
为Reigstry的容器定义添加持久化卷请求docker-registry-claim,并与挂载点registry-storage关联。
Deployment Config的容器定义修改后,OpenShift会创建新的容器实例。检查容器/registry目录,会发现目录的数据恢复了。
至此,我们成功地将Registry组件挂接上了持久化储存。本例的配置基于NFS持久化卷实现,使用GlusterFS或Ceph持久化卷的过程也类似,只是持久化卷的定义需要稍做修改。
- 011.Kubernetes使用共享存储持久化数据
本次实验是以前面的实验为基础,使用的是模拟使用kubernetes集群部署一个企业版的wordpress为实例进行研究学习,主要的过程如下: 1.mysql deployment部署, wordpre ...
- openshift 容器云从入门到崩溃之七《数据持久化》
数据持久化常用的有两种: hostPath 挂载容器宿主机的本地文件夹,直接修改pod的配置 volumes: - hostPath: path: /data/logging-es type: '' ...
- k8s部署mysql数据持久化
在这里我部署mysql的目的是为了后面将上一篇博客docker打包的el-admin镜像部署到k8s上,所以本文主要是部署mysql并实现持久化. 1.将我们的应用都部署到 el-admin 这个命名 ...
- Kubernetes的故事之持久化存储(十)
一.Storage 1.1.Volume 官网网址:https://kubernetes.io/docs/concepts/storage/volumes/ 通过官网说明大致总结下就是这个volume ...
- Redis学习总结(1)——数据持久化
以前研究Redis的时候,很多东西都不太明白,理解得也不太深,现在有时间重新拾起来看看,将一些心得记录下来,希望和大家一起探讨. 一.简介 Redis是一个单线程高可用的Key-Value存储系统,和 ...
- iOS之数据持久化方案
概论 所谓的持久化,就是将数据保存到硬盘中,使得在应用程序或机器重启后可以继续访问之前保存的数据.在iOS开发中,有很多数据持久化的方案,接下来我将尝试着介绍一下5种方案: plist文件(属性列表) ...
- Docker数据持久化与容器迁移
上节讲到当容器运行期间产生的数据是不会在写镜像里面的,重新用此镜像启动新的容器就会初始化镜像,会加一个全新的读写入层来保存数据.如果想做到数据持久化,Docker提供数据卷(Data volume)或 ...
- iOS 两行代码解决数据持久化
在实际的iOS开发中,有些时候涉及到将程序的状态保存下来,以便下一次恢复,或者是记录用户的一些喜好和用户的登录信息等等. 这就需要涉及到数据的持久化了,所谓数据持久化就是数据的本地保存,将数据从内存中 ...
- iOS的数据持久化
所谓的持久化,就是将数据保存到硬盘中,使得在应用程序或机器重启后可以继续访问之前保存的数据.在iOS开发中,有很多数据持久化的方案,接下来我将尝试着介绍一下5种方案: plist文件(属性列表) pr ...
随机推荐
- 利用堆实现堆排序&优先队列
数据结构之(二叉)堆一文在末尾提到"利用堆能够实现:堆排序.优先队列.".本文代码实现之. 1.堆排序 如果要实现非递减排序.则须要用要大顶堆. 此处设计到三个大顶堆的操作:(1) ...
- 安装 Xshell 5/6 时出现.dll以及0xc000007错误的解决
安装 Xshell 5/6 时出现.dll以及0xc000007错误的解决 问题:缺少 mfc110.dll或者是其他.dll文件以及应用程序运行错误,如下所示. 方法: 一种是网上直接下载.(缺少. ...
- java构造函数修饰符
java 构造函数,可以被访问修饰符修饰,而不能被特殊修饰符修饰:(在编译器经过测试) 访问修饰符: public (最常用,其他类的任何位置都可以访问) protected(能够在同一包中被子类访问 ...
- Java知多少(79)哈希表及其应用
哈希表也称为散列表,是用来存储群体对象的集合类结构. 什么是哈希表 数组和向量都可以存储对象,但对象的存储位置是随机的,也就是说对象本身与其存储位置之间没有必然的联系.当要查找一个对象时,只能以某种顺 ...
- Fedora Server 21 安装 搜狗拼音输入法
最新文章:Virson’s Blog 借鉴文章:博客园-怒杀神殿 ChinaUnix-firo 百度贴吧-fedora吧 方法一:解压deb安装包方式安装: 如果本机已安装ibus,需要先卸载, ...
- C# winform写入和读取TXT文件
C# winform写入和读取TXT文件 string str; str=this.textBox1.Text; StreamWriter sw = new ...
- localhost兼容js不能用
- post请求参数设置
控制器参数有[FromBody]修饰参数这么传: 控制器没有[FromBody]修饰参数这么传:
- 用 SQLite 和 FMDB 替代 Core Data
本文转载至 http://blog.csdn.net/majiakun1/article/details/38680147 为什么我不使用Core Data Mike Ash 写到: 就个人而言,我不 ...
- 关于JSON call 的一个小问题
如图当我们在做Json call 的时候,一定要切记,建立的model 一定要与JSON 字符串严格的一一对应,否者会解析不出来