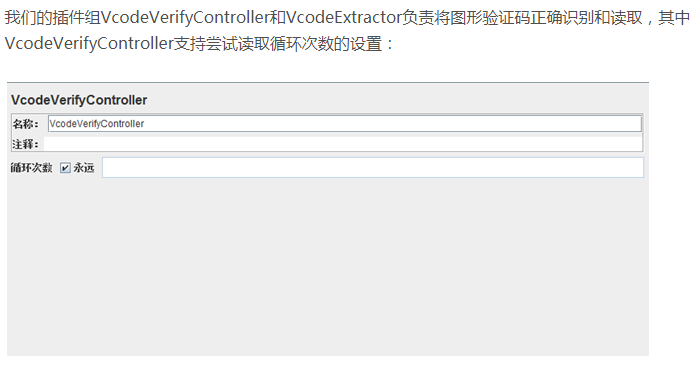
JMeter开发插件——图片验证码识别
我们在性能测试中总会时不时地遭遇到来自于应用系统的各种阻碍,图片验证码就是一类最常见的束缚,登录或交易时需要按照图片中的内容输入正确的验证信息后,数据才可以提交成功,这使得许多性能测试工具只能望而却步。网上也出现了一些LoadRunner的解决方案,但结合LoadRunner对于C脚本内存控制和识别成功率低下等诸多问题,这些方案没有什么实际用途。然而,为JMeter开发插件却给我们提供了一条可行的道路来冲破图片验证码的束缚!
选择一个理想的第三方图形图像识别工具
在此我们首先需要一个比较理想的图形图像识别工具来完成将验证码中的图形图像文字识别转换为文本文字主体识别工作,在此我们选择Tesseract, Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,发布在Googel Project上,地址为http://code.google.com/p/tesseract-ocr/(但Googel Project停止维护后不知道现在在哪里维护)。
一组用于验证码识别的JMeter插件
我们常见的验证码图片样本如下: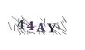
1. 降噪
当你遇到这样的验证码时,首先你要做的就是降噪,将背景的一些干扰我们识别文本内容的线条过滤掉,人眼需要降噪,识别软件在进行识别前也需要帮助其进行降噪来加大识别成功率,通常降噪的方案是对图片像素点进行逐个扫描,通过创建降噪规则对背景噪音进行过滤,如上面的样本,我们可以建立如下降噪规则和方法:
public static int isFilter(int colorInt) {
Color color = new Color(colorInt);
if ((color.getRed() > 85 && color.getRed() < 255)
&& (color.getGreen() > 85 && color.getGreen() < 255)
&& (color.getBlue() > 85 && color.getBlue() < 255)) {
return 1;
}
return 0;
}
public static BufferedImage removeBackgroud(BufferedImage img)
throws Exception {
int width = img.getWidth();
int height = img.getHeight();
for (int x = 0; x < width; ++x) {
for (int y = 0; y < height; ++y) {
if (isFilter(img.getRGB(x, y)) == 1) {
img.setRGB(x, y, Color.WHITE.getRGB());
}
}
}
return img;
}

可以看到效果非常明显,但降噪也有它的局限性,比如会把一些需要正常显示的图形文字过滤掉一部分,诸如此类问题我们会在后面的介绍中通过其他方式解决,但对于图形图像识别软件的输入来说,必须对其加以降噪才能保证读取正确率。
2. 识别插件(第一个Extractor插件)
我们在最初的章节介绍了Extractor的基本实现方法,在此我们还是简单回顾一下后置处理器的一些功能,下图显示了JMeter为我们默认提供的后置处理器:
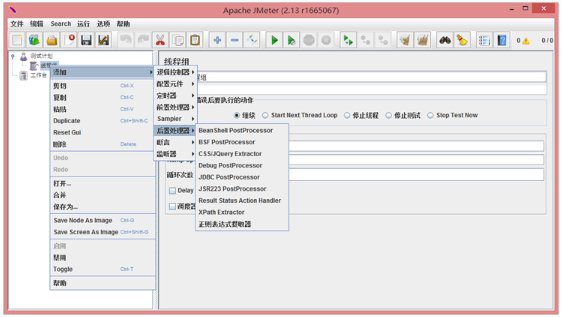
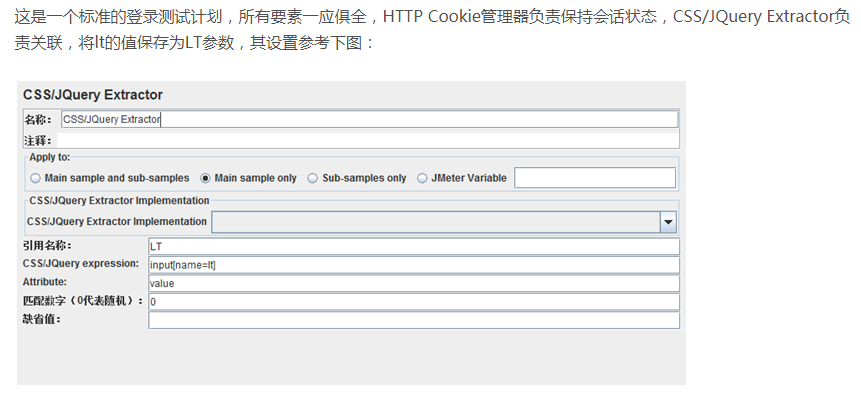
所谓后置处理器是相对Sampler的后置,主要用于处理Sampler所抽样得到的SamplerResult对象,对SamplerResult做修饰或通过SamplerResult抽取信息,最常使用的是“正则表达式提取器”、“CSS/JQuery Extractor”、“XPath Extractor”,使用它们可以实现性能测试脚本中最重要的“关联”操作。
好了,我们的需求是对验证码进行读取,即通过验证码URL获取到图片资源(这部分由“HTTP请求Sampler”完成),然后提取资源中的图形图像信息作为Tesseract的输入,最后在将Tesseract的输出作为一个JMeter参数数据进行保存。惯例使用分离法,分为逻辑控制部分VcodeExtractor和GUI部分VcodeExtractorGUI,另外,还包括对图片进行处理的ImageIOHelper类以及实现调用Tesseract对验证码信息识别并读取的OCR类。
ImageIOHelper主要包含两大部分,一部分就是前面所介绍的降噪逻辑,另一部分是将图片格式转换为tiff格式以更好地进行识别,这部分的代码参考如下:
public static File createImage(File imageFile, String imageFormat) {
File tempFile = null;
ImageInputStream iis = null;
ImageOutputStream ios = null;
ImageReader reader = null;
ImageWriter writer = null;
try {
Iterator<ImageReader> readers = ImageIO.getImageReadersByFormatName(imageFormat);
reader = readers.next();
iis = ImageIO.createImageInputStream(imageFile);
reader.setInput(iis);
IIOMetadata streamMetadata = reader.getStreamMetadata();
TIFFImageWriteParam tiffWriteParam = new TIFFImageWriteParam(Locale.CHINESE);
tiffWriteParam.setCompressionMode(ImageWriteParam.MODE_DISABLED);
Iterator<ImageWriter> writers = ImageIO.getImageWritersByFormatName("tiff");
writer = writers.next();
BufferedImage bi = removeBackgroud(reader.read(0));
IIOImage image = new IIOImage(bi,null,reader.getImageMetadata(0));
tempFile = tempImageFile(imageFile);
ios = ImageIO.createImageOutputStream(tempFile);
writer.setOutput(ios);
writer.write(streamMetadata, image, tiffWriteParam);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if(iis != null){
try {
iis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(ios != null){
try {
ios.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(writer != null){
writer.dispose();
}
if(reader != null){
reader.dispose();
}
}
return tempFile;
}
private static File tempImageFile(File imageFile) {
String path = imageFile.getPath();
StringBuffer strB = new StringBuffer(path);
return new File(strB.toString().replaceFirst("jpg", "tif"));
}
OCR类主要是通过Process调用已经安装的Tesseract程序,调用命令基本形式为 tesseract xxx.tif 1 -l eng,参考如下代码:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List; public class OCR {
private final String LANG_OPTION = "-l";
private final String EOL = System.getProperty("line.separator");
private String tessPath = "D://Program Files (x86)//Tesseract-OCR"; public String recognizeText(File imageFile,String imageFormat) {
File tempImage = ImageIOHelper.createImage(imageFile,imageFormat);
File outputFile = new File(imageFile.getParentFile(),"output" + imageFile.getName());
StringBuffer sb = new StringBuffer();
List<String> cmd = new ArrayList<String>(); cmd.add(tessPath+"//tesseract");
cmd.add("");
cmd.add(outputFile.getName());
cmd.add(LANG_OPTION);
cmd.add("eng");
ProcessBuilder pb = new ProcessBuilder();
pb.directory(imageFile.getParentFile()); cmd.set(1, tempImage.getName());
pb.command(cmd);
pb.redirectErrorStream(true); Process process = null;
BufferedReader in = null;
int wait;
try {
process = pb.start();
//tesseract.exe xxx.tif 1 -l eng
wait = process.waitFor();
if(wait == 0){
in = new BufferedReader(new InputStreamReader(new FileInputStream(outputFile.getAbsolutePath()+".txt"),"UTF-8"));
String str;
while((str = in.readLine())!=null){
sb.append(str).append(EOL);
}
in.close(); }else{ tempImage.delete();
}
new File(outputFile.getAbsolutePath()+".txt").delete();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if(in != null){
try {
in.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} tempImage.delete();
return sb.toString();
}
}
VcodeExtractor类继承AbstractScopedTestElement抽象类,实现PostProcessor接口的process方法,来处理利用OCR读取验证码信息的逻辑控制,参考代码如下:
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.Serializable; import org.apache.jmeter.processor.PostProcessor;
import org.apache.jmeter.samplers.SampleResult;
import org.apache.jmeter.testelement.AbstractScopedTestElement;
import org.apache.jmeter.threads.JMeterContext;
import org.apache.jmeter.threads.JMeterVariables;
import org.apache.jorphan.logging.LoggingManager;
import org.apache.log.Logger; public class VcodeExtractor extends AbstractScopedTestElement implements PostProcessor, Serializable{
private static final Logger log = LoggingManager.getLoggerForClass();
@Override
public void process() {
// TODO Auto-generated method stub
JMeterContext context = getThreadContext();
SampleResult previousResult = context.getPreviousResult();
if (previousResult == null) {
return;
}
log.debug("VcodeExtractor processing result"); String status = previousResult.getResponseCode();
int id = context.getThreadNum();
String imageName = id + ".jpg"; if(status.equals("200")){
byte[] buffer = previousResult.getResponseData();
FileOutputStream out = null;
File file = null;
try {
file = new File(imageName);
out = new FileOutputStream(file);
out.write(buffer);
out.flush(); } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if(out != null){
try {
out.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} try {
String vcode = new OCR().recognizeText(file, "jpg");
vcode = vcode.replace(" ", "").trim(); JMeterVariables var = context.getVariables();
var.put("vcode", vcode);
var.put("vuser", String.valueOf(id));
} catch (Exception e) {
e.printStackTrace();
}
} } }
代码逻辑非常简洁,即通过getThreadContext()方法获取当前线程(vuser)的上下文,从而从上下文中获取到前一个Sampler所抽样的结果,为保证结果不为空我们做了一个简单的处理,也可以添加一些更为精细的控制,如下代码:
if(context.getPreviousSampler() instanceof HTTPSampler){
return;
}
判断前一个Sampler是否为HTTPSampler,以限定有效使用范围。
将previousResult.getResponseData()保存为文件后,通过前面我们创建的OCR完成识别任务后,将识别结果通过JMeterVariables对象保存下来,在此我们分别建立了两个参数”vcode”和”vuser”,后面我们可以用它们进行测试。
该版本的VcodeExtractorGUI类只是单纯实现一个可视化的界面用于在测试计划Tree中进行操作:
import org.apache.jmeter.processor.gui.AbstractPostProcessorGui;
import org.apache.jmeter.testelement.TestElement; public class VcodeExtractorGUI extends AbstractPostProcessorGui{ @Override
public TestElement createTestElement() {
// TODO Auto-generated method stub
VcodeExtractor extractor = new VcodeExtractor();
modifyTestElement(extractor);
return extractor;
} @Override
public String getLabelResource() {
// TODO Auto-generated method stub
return this.getClass().getName();
} @Override
public String getStaticLabel() {//设置显示名称
// TODO Auto-generated method stub
return "VcodeExtractor";
} @Override
public void modifyTestElement(TestElement extractor) {
// TODO Auto-generated method stub
super.configureTestElement(extractor); }
}
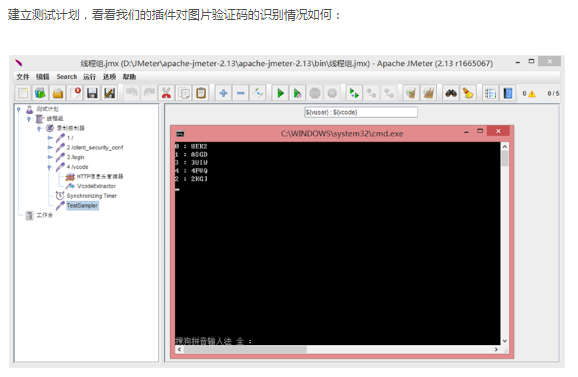

这意味着识别存在错误!
3. 提高识别成功率
识别成功率是成败的关键,提升成功率可以采取以下方案:
训练Tesseract
提供大量样本来训练Tesseract对特定图形的识别成功率。
修正错误的识别结果
有些识别错误是这样的,如:
将J识别为[,将M识别为|\/|,将N识别为||,这种识别错误是机器识别离散一些的像素点产生的,人眼是可以修正的,因此,我们可以建立映射表方式将错误字符进行修正。
避免混淆形状接近的图形字符
有些识别错误是这样的,如:
将5识别为S,将1识别为I,将0识别为O,这种识别错误是纯的图形混淆产生的,人眼也可能犯此类错误,我们管它叫“看不清”。
4. 看不清,换一张(第一个Controller插件)
“看不清,换一张”无论对人眼或机器识别都是一种弥补方案,我们对于“看不清”的字符需要模拟换一张重新识别的操作,这里我们引入一个新的插件Controller(逻辑控制器),照例我们先来回顾一下该插件的一些功能,下图显示了JMeter为我们默认提供的逻辑控制器: 
前面的章节曾经介绍过所谓逻辑控制器主要就是用来控制线程行为的,当然也包括一些用于划分Sampler或功能边界的控制器如事务控制器和录制控制器,主要是依靠一些限定的条件或阈值的判断,按想要的方式控制总体线程或单独线程行为。
好了,我们的需求很明确“看不清,换一张”,在此可以完全照搬循环控制器的源代码,参考LoopController类和LoopControlPanel类,只需要对LoopController在每次循环结束后判断是否退出的函数中增加我们对于图片是否看清的逻辑,代码如下:
private final static String PATTERN = "34789ABCEFHKLPRTUVWXY"
private boolean isVerify(String vcode){
int length = vcode.length();
//对长度进行判断
if(length != 4){
return false;
}
//对内容进行判断
for(int i = 0; i < length; i++){
if(PATTERN.indexOf(vcode.toCharArray()[i]) < 0){
return false;
}
} return true;
}
@Override
public Sampler next() {
JMeterContext context = getThreadContext();
JMeterVariables var = context.getVariables();
String vcode = var.get("vcode");
if(vcode != null){
if(isVerify(vcode)){
setDone(true);
return null;
}
} if(endOfLoop()) {
if (!getContinueForever()) {
setDone(true);
}
return null;
}
return super.next();
}
如果通过isVerify函数校验(看得清楚)就直接退出循环,否则(看不清楚)就接着重新请求图片验证码进行校验(换一张),创建此逻辑控制器VcodeVerifyController。
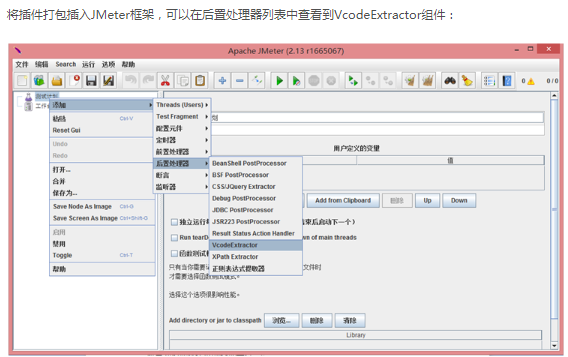
将插件打包插入JMeter框架,可以在逻辑控制器列表中查看到VcodeVerifyController组件: 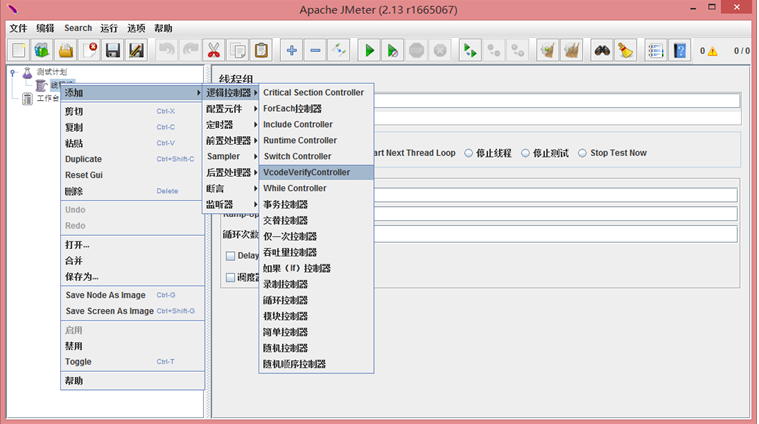
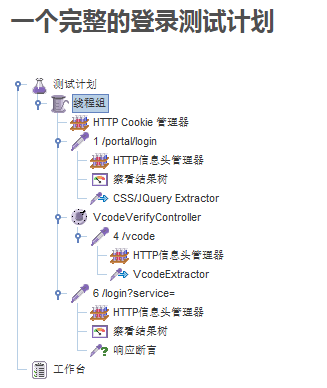
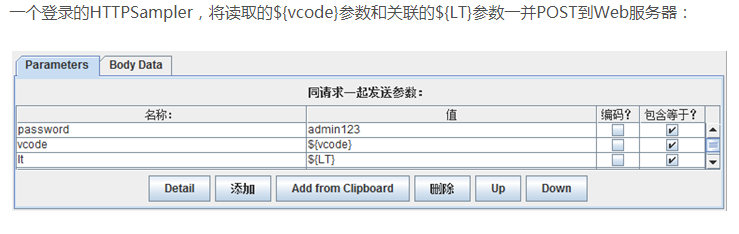
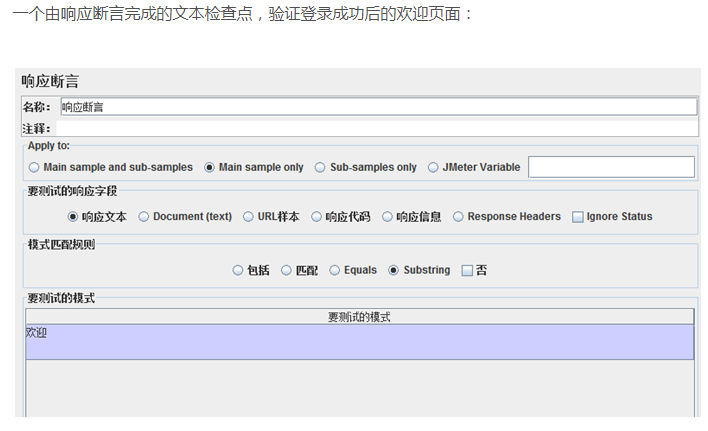
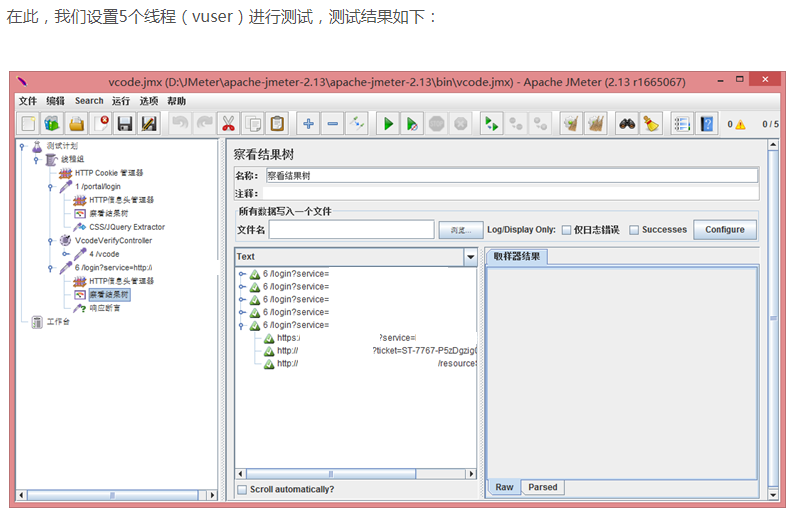
全部通过了登录验证,但根据测试发现识别率成功基本在75%左右,因此,还需要进一步完善,第一是通过改进识别逻辑,第二是增加一个验证码如果识别错误重新进行识别提交登录事务的过程控制。
原文地址https://blog.csdn.net/xreztento/article/details/48682923
大量jmeter二次开发文章地址https://blog.csdn.net/xreztento/article/category/2551407
JMeter开发插件——图片验证码识别的更多相关文章
- 字符型图片验证码识别完整过程及Python实现
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- 字符识别Python实现 图片验证码识别
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- python3图片验证码识别
http://my.cnki.net/elibregister/CheckCode.aspx每次刷新该网页可以得到新的验证码进行测试 以我本次查看的验证码图片为例,右键保存图片为image.jpg 下 ...
- 如何为Apache JMeter开发插件(二)—第一个JMeter插件
文章内容转载于:http://lib.csdn.net/article/softwaretest/25700,并且加上个人一些截图 本篇将开启为JMeter开发插件之旅,我们选择以Function(函 ...
- python3爬虫图片验证码识别
# 图片验证码识别 环境安装# sudo apt-get install -y tesseract-ocr libtesseract-dev libleptonica-dev# pip install ...
- 使用.Net Core 2.1开发Captcha图片验证码服务
更新后续篇:Captcha服务(后续1) 使用.Net Core 2.1开发Captcha验证码服务 开发工具:Visual Studio 2017 15.7.3 开发平台:64位 Windows 1 ...
- 如何为Apache JMeter开发插件(一)
本文转载于http://blog.csdn.net/column/details/12925.html,作者:xreztento 作者写的很精华,我打算在此系列操作一遍后,加多点截图,便于更多人更快上 ...
- 第二十三节:scrapy爬虫识别验证码(二)图片验证码识别
图片验证码基本上是有数字和字母或者数字或者字母组成的字符串,然后通过一些干扰线的绘制而形成图片验证码. 例如:知网的注册就有图片验证码 首先我们需要获取验证码图片,通过开发者工具我们可以得到验证码ur ...
- UI自动化关于图片验证码识别的解决方法
def __save_screenshot(self): self.driver.save_screenshot('full_snap.png') self.page_snap_obj = Image ...
随机推荐
- Docker容器集群管理之Swarm
Docker容器集群管理主流方案 Swarm Docker公司自研发的集群管理系统. Kubernetes Google开源的一个容器集群管理系统,用于自动化部署.扩展和管理容器应用.也称为K8S ...
- Oracle数据库版本10.2.0.1升级到10.2.0.3(转)
Oracle数据库版本10.2.0.1升级到10.2.0.3 1.停止OEM/isqlplus/监听/DB实例 $ emctl stop dbconsole $ isqlplusctl stop $ ...
- 转发一篇好文:36氪翻译自medium的文章: 读书没有 KPI:为什么坚持“一年读 100 本书”没用?
你只是为了达成所谓的数量目标而读书. 编者按:读书本是一项安静.缓慢的活动,但随着现代社会节奏的加快,信息技术的广泛普及,读书这一行为模式也开始发生了变化.越来越多的人开始碎片化阅读,并且越来越多的文 ...
- Power BI 可视化交互/视觉对象交互
xx Power BI的官方文档特别好,但是具体到自己使用的时候,有些知识点,可能看完文档忘了,导致有些功能做不出来...网络上资料还比较匮乏... 自己没事还是多总结下吧... 比如: 文档上写的很 ...
- [No0000CA]什么是“普瑞马法则”?以及 如何利用“普瑞马法则”,三步克服惰性
一般在学习和生活中,我们都可能有这样的经验,就是当说想要作某件事情的时候,但过了好久发现还是没有做:或者觉得有力气使不出来:或者总觉得生活是灰色和抑郁的等等. 这类情况反映在生活中,就是生活好像总是被 ...
- 【插头dp】 hdu4285 找bug
打模板的经验: 1.变量名取一样,换行也一样,不要宏定义 2.大小写,少写,大括号 #include<algorithm> #include<iostream> #includ ...
- [ovs] openvswitch 入门
https://www.sdnlab.com/sdn-guide/14747.html http://sdnhub.cn/index.php/openv-switch-full-guide/ http ...
- [development][endian] 字节序
首先字节序很不好理解, 其次,理解了又不好记住. 除了字节序, 还有位序. 那么到底怎么记住呢? 大端序,小端序还有另一个名字, 大尾序,小尾序. 这样就记住了, 我们以16进制打印一个数之后, 尾部 ...
- zookeeper 杂记
Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M.
- LoadRunner录制脚本-基础
1.启动LoadRunner.没有脚本则创建脚本,有脚本则可以运行压力测试 2.点击Create/Edit Scripts,如下图,可新建或打开已有脚本 3.选择要测系统的协议 4.生成脚本分四步 5 ...