内核同步机制-RCU同步机制
转自:https://blog.csdn.net/nevil/article/details/7718375
转自http://www.360doc.com/content/09/0805/00/36491_4675691.shtml
目录[隐藏] |
RCU同步机制
RCU介绍
RCU(Read-Copy Update)是一种极端的非对称读/写同步机制,基本点是允许读操作在没有任何锁及原子操作的情况下进行。这意味着在更新操作进行的时候读操作也可能在运行。读者临界代码不需要承担任何同步开销,不需要锁,不需要原子指令,在大多数平台,还不需要内存屏障指令。因此,仅读的工作负载可以获取近乎理想的执行性能。
写者临界代码必须承担主要的同步开锁,为了适应读者的临界代码要求,写者必须延迟销毁数据结构和维护数据结构的多个版本,必须使用同步机制,如:加锁、提供排序的更新。
读者必须提供信号,让写者决定何时完成数据结构销毁操作是完全的,但该信号可能被延迟,允许一个单信号操作服务多个读者RCU临界代码。RCU通常用非原子操作地增加一个本地计数器的方法发信号给写者,该方法开销很小。
一种特殊的垃圾回收器用于观察读者发给写者的信号,一旦所有护者已发信号表示可以安全销毁时,垃圾回收器才执行销毁操作。垃圾回收器通常以类似于屏障计算的方式实现,或者在NUMA系统用一个联合树的形式实现。
RCU通过延迟写操作来提高同步性能。系统中数据读取操作远多于写操作,而rwlock读写锁机制在SMP对称多处理器环境下随着处理机增多性能会迅速下降,RCU“读拷贝更新”机制改善了这种情况,RCU技术的核心是写操作分为“写”和“更新”两步,允许读操作在任何时候无阻碍访问,当系统有写操作时,更新动作一直延迟到对该数据的所有读操作完成为止。RCU通过延迟写操作来提高同步性能。
下面用一个具体的例子具体的例子说明RCU是如何延迟更新的。
样例:使用RCU机制更新单向链表
有两个线程访问一个单向链表,在线程1对元素B做没有锁的读时线程0将更新元素B。见图1所示。
此时,线程0不能简单地修改元素B,因为这将干扰线程1对元素B的访问。作为代替,线程0拷贝元素B到B’,修改B’,发出内存屏障操作,接着,元素A的next指针指到B’。只要B还指向C,这就不会影响到线程1,并且在释放B之前,线程0等待直到线程1停止对B的引用,见图2中所示。 
图1 链表初始的状态 图2 链表的延迟删除图
线程1不再获得对B的引用,这样,在线程0删除B之前,它等到了一个quiescent时期(见图4),在这个quiescent期间之后,线程0删除B,见图5中显示。 
图4 在quiescent期间后的链表 图5 在删除操作后的链表
线程0必须使用某种更新规则来处理并发的更新,这些规则包括使用锁、原子指令或等待-释放同步机制。如果仅一个线程被允许更新数据,所有锁可以被删除。
下面说明RCU机制相关的几个基本概念:
- 活着变量(Live Variable):一个变量在它被修改前可能被访问到,因此它的当前值可能影响到将来运行状态。如图1中的元素B。
- 死变量(Dead Variable):一个变量在它下一次被访问前将被修改,因此它当前值对将来的运行状态没有影响。如图4中的元素B’。
- 临时变量(Temporary Variable):仅生存在临界部分中的变量,如:当访问一个链表时被用作一个指针的自动变量,如图2中的元素B’。
- 永久变量(Permanent Variable):一个变量在临界部分外的变量,如图1中链表的头A。
- 临界部分(Critical Section):用于访问共享资源、由一些锁机制对外界保护的代码区域,如:自旋锁或RCU。
- 读侧临界部分(Read-Side Critical Section):保护禁止其他CPU修改的代码区域,但允许多个CPU同时读。
- 静止状态(Quiescent State):是一个线程的执行状态,在此期间,线程不持有对任何RCU保护的数据结构的引用。静止状态分为候选静止状态和被观察的静止状态两类。静止状态通常指可被观察的静止状态。当设计读侧RCU算法时,才会用到候选静止状态。
- 候选静止状态(Candidate Quiescent State):它是代码中的一个点,在此点,所有此线程以前使用在临界部分的临时变量都是死的(即为死变量)。在所有RCU读侧临界部分外面任何点是一个候选静止状态。
- 可被观察静止状态(Observed Quiescent State):尽管不可能观察所有的候选静止状态,但还是可以容易地观察部分候选静止状态,因为它们与一个永久操作系统状态的改变相关。这些易被观察的静止状态称为可被观察静止状态。例如:在可抢占的Linux内核,rcu_read_lock()和rcu_read_unlock()为短小读侧临界部分抑制内核抢占,因此,对应于这些读侧临界部分,上下文切换还是一个可被观察静止状态。读侧RCU临界部分不允许含有任何作为可被观察静止状态的操作。
- 宽限期(Grace Period): RCU提供了一个宽限期给并发访问,宽限期是指所有CPU当前正执行的RCU读操作的临界部分完成的时间。在两种情况下执行破坏性的更新:1)为能看见新状态的新操作执行每个更新,同时,允许以前存在的操作在旧状态进行处理。接着 2)在grace期间超期后,完成更新,以便完成所有以前正存在的操作。
在宽限期期间,所有线程经过了至少一个静止状态。宽限期的关键属性是:在宽限期间,在宽限期间开始的读侧临界部分使用的任何临时变量值,在宽限期间至少死一次。因此,这些变量在宽限期间结束后不可能有任何直接影响,并且,它们不可能引用任何元素,这些元素在宽限期开始之前的任何时间被从它的数据结构删除。注意:包含一个宽限期的任何时间间隔它本身是一个宽限期。
图6显示了宽限期的概念,线程A-H在CPU0-3上执行,时间顺序为从左到右。方框表示一个读侧RCU临界部分,在CPU0上标识为A1的方框是线程A的第1号读侧RCU临界部分,A2表示线程A的第2号读侧RCU临界部分,G1表示线程访问第1号读侧临界部分,依此类推。在方框之间的黑线段表示连续的线程执行。该执行在读侧RCU临界部分的外面,因此,这些线段上的每个点表示一个候选静止状态。这意味着无论何时沿其中一个线段运行,所有在读侧RCU临界部分使用的临时变量必须是死的(即死变量)。永久变量可以一直保持活的(即活变量)。黑色圆圈表示上下文切换,并且这些上下文切换是可被观察的静止状态。 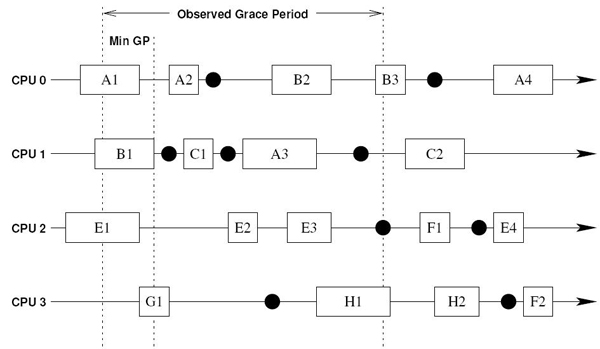
图6在线程运行中的RCU概念描述
在图6中,假定CPU 3在最左边的虚线时刻有一个线程正在更新RCU保护的第1号临界部分数据,它必须等待所有对第1号临界部分数据的读操作完成且执行完上下文切换后,新线程才能执行数据写更新。所有此时刻正处理中的读侧RCU临界部分到中间的虚线时刻已完成,在这两个虚线之间的时间是最小宽限期,在图中用“Min GP”表示。
由于仅观察到上下文切换,因此,宽限期不能完全标识。直到所有的CPU完成了一个上下文切换,才能标识宽限期。最后完成的CPU是CPU 2,在图中由最右边的虚拟标识。此时,写操作的线程才能更新第1号临界部分的数据。虽然通过观察所有可能静止状态,宽限期延迟可能被大大减少,但这样做可能大大增加宽限期检测量。例如:观察每个读侧RCU临界部分的末尾,将只负担检测读/写锁的检测量。
RCU API函数说明
RCU API函数封装了RCU同步机制的实现结节,用户调用RCU API可以实现RCU同步。RCU在读者部分有多簇API函数,表3显示了读者部分API函数的功能说明,每一列为一簇API函数,其中,经典RCU最常用,SRCU有最简单的API;表4显示了出版/预订部分的API函数。
表3 读者部分API函数簇说明
| 属性 | 经典RCU | RCU BH | 调度的RCU | 实时RCU | SRCU | QRCU |
| 目的 | 起始 | 阻止DDoS攻击 | 等待硬件中断和NMI | 实时响应 | 使读者可以睡眠 | 使读者可以睡眠且有较快的宽限期 |
| 可用版本 | 2.5.43 | 2.6.9 | 2.6.12 | 2005年8月,内核选项 -rt | 2.6.19 | - |
| 读侧原语 | rcu_read_lock() rcu_read_unlock() |
rcu_read_lock_bh() rcu_read_unlock_bh() |
preempt_disable() preempt_enable() (以及同类函数) |
rcu_read_lock() rcu_read_unlock() |
srcu_read_lock() srcu_read_unlock() |
qrcu_read_lock() qrcu_read_unlock() |
| 更新侧原训(同步) | synchronize_rcu() synchronize_net() |
- | synchronize_sched() | synchronize_rcu() synchronize_net() |
synchronize_srcu() | synchronize_qrcu() |
| 更新侧原语(异步) | call_rcu() | call_rcu_bh() | - | call_rcu() | N/A | N/A |
| 更新侧原语(等待回调) | rcu_barrier() | - | - | rcu_barrier() | N/A | N/A |
| 读侧限制 | 没有阻塞 | 没有中断打开 | 没有阻塞 | 除了内核抢占和获取锁外没有阻塞 | 不是 synchronize_srcu() | 不是 synchronize_qrcu() |
| 读侧负荷 | 内核抢占关闭/打开(在非抢占内核中为空) | 关闭/打开BH | 内核抢占关闭/打开(在非抢占内核中为空) | 简单指令、开/关中断 | 简单指令、开/关内核抢占 | 共享变量原子地递增或递减 |
| 异步更新侧负荷 (如:call_rcu()) | 在毫秒以下 | 在毫秒以下 | - | 在毫秒以下 | N/A | N/A |
| 宽限期时延 | 数10毫秒 | 数10毫秒 | 数10毫秒 | 数10毫秒 | 数10毫秒 | 在没有读者时为数10纳秒(ns) |
| Non-PREEMPT_RT实现 | 经典RCU | RCU | BH | N/A | SRCU | N/A |
| 经典RCU PREEMPT_RT实现 |
N/A | 实时RCU | 在所有CPU上强制调度 | PREEMPT_RT实现 | 实时RCU SRCU | N/A |
在表3中,“经典RCU”列对应于最初的RCU实现。在经典RCU中,RCU读侧临界部分由rcu_read_lock() 和rcu_read_unlock()界定,它们可以嵌套。对应的同步更新原语为synchronize_rcu(),还有同义的synchronize_net(),等待当前正执行的RCU读侧闻临界部分运行完成。等待的时间称为“宽限期”。异步更新侧原语call_rcu()在宽限期之后触发指定的函数,如:call_rcu(p,f)调用触发回调函数f(p)。有些情况,如:当卸载使用call_rcu()的模块,必须等待所有RCU回调函数完成,原语rcu_barrier()起该作用。
在“RCU BH”列中,rcu_read_lock_bh() 和rcu_read_unlock_bh()界定读侧临界部分,call_rcu_bh()在宽限期后触发指定的函数。注意:RCU BH没有同步接口synchronize_rcu_bh(),如果需要,用户很容易添加同步接口函数。
在“调度RCU”列中,任何关闭内核抢占的操作作为RCU读侧临界部分,synchronize_sched()等待相应的RCU宽限期。它将旧的synchronize_kernel() API分为synchronize_rcu()(用于经典RCU)和synchronize_sched()(用于调度RCU)。注意:调度RCU没有异步的call_rcu_sched()接口。
“实时RCU”列与经典RCU有相同的API,区别仅在于RCU读侧临界部分在获取自旋锁时可被抢占和阻塞。
“SRCU”列显示了特殊的RCU API,在SRCU读侧临界部分允许通用的睡眠。当然,在SRCU读侧临界部分使用synchronize_srcu()可能导致自锁,因此,应避免使用synchronize_srcu()。SRCU不同于早期的RCU的实现,调用者给每个不同的SRCU应用分配一个srcu_struct结构,阻止SRCU读侧临界部分阻塞不相关的synchronize_srcu()调用。还有,srcu_read_lock()返回值必须传递给相应的srcu_read_unlock()。
“QRCU”列与SRCU有同样的API结构,但对没有读者的低延迟宽限期进行了优化。目前还没进入Linux内核。
RCU出版-预订和版本维护原语显示如表4,适应于表3中所有的RCU簇。
表4 出版/预订部分的API函数功能说明
| 目录 | 原语 | 可用版本 | 负荷 |
| 链表遍历 | list_for_each_entry_rcu() | 2.5.59 | 简单指令(在Alpha CPU用内存屏障) |
| 链表更新 | list_add_rcu() | 2.5.44 | 内存屏障 |
| list_add_tail_rcu() | 2.5.44 | 内存屏障 | |
| list_del_rcu() | 2.5.44 | 简单指令 | |
| list_replace_rcu() | 2.6.9 | 内存屏障 | |
| list_splice_init_rcu() | 2.6.21 | 宽限期时延 | |
| 哈希链表遍历 | hlist_for_each_entry_rcu() | 2.6.8 | 简单指令(在Alpha CPU用内存屏障) |
| 哈希链表更新 | hlist_add_after_rcu() | 2.6.14 | 内存屏障 |
| hlist_add_before_rcu() | 2.6.14 | 内存屏障 | |
| hlist_add_head_rcu() | 2.5.64 | 内存屏障 | |
| hlist_del_rcu() | 2.5.64 | 简单指令 | |
| hlist_replace_rcu() | 2.6.15 | 内存屏障 | |
| 指针遍历 | rcu_dereference() | 2.6.9 | 简单指令(在Alpha CPU用内存屏障) |
| 指针更新 | rcu_assign_pointer() | 2.6.10 | 内存屏障 |
Linux内核的双向链表用结构list_head描述,该链表是循环的、双向连接的链表。原语list_for_each_entry_rcu()以安全方式遍历一个RCU保护链表,当遍历时并发新元素插入操作时,它强制内存排序。对于非Alpha平台,该原语与list_for_each_entry()比有很小效率损失。list_add_rcu(), list_add_tail_rcu()和list_replace_rcu()类似于非RCU的相应操作函数,但在弱次序机器上承担附加的内存屏障开销。
原语list_splice_init_rcu()类似于非RCU的相应操作函数,但承担了全部宽限期的延迟。
Linux内核的哈希链表用结构hlist_head描述,它是一个线性连接链表,比结构list_head更好的是:结构hlist_head仅需要一个单个指针的链表头,在大的哈希表中可以明显节约内存。
直接操作指针的原语rcu_assign_pointer()和rcu_dereference()用于创建RCU保护的非链表数据结构,如:数组和树。原语rcu_assign_pointer()确保任何以前初始化操作在赋给指针之前保持排序。类似地,原语rcu_dereference()确保解除引用的随后代码在相应的rcu_assign_pointer()之前在Alpha CPU上看见有效的初始化。在非Alpha CPU上,RCU通过rcu_dereference()保护指针解除引用。
调用RCU API实现RCU同步
传统的锁原语确保并发线程间互斥,不管它们是读者还是写者,读/写锁允许没有写者出现时读者可以并发访问。RCU支持单个写者和多个读者的并发访问。通过维护对象的多个版本、并确保它们不被释放、直到所有以前存在读侧临界部分执行完成,RCU确保读者可以并发访问。RCU定义并使用了有效的、可扩展的机制来出版和读取一个对象的新版本,还延迟了旧版本的收集。
下面以链表为例说明调用经典RCU的API实现RCU同步的方法。
当读者内核路径(如:内核线程)需要读RCU保护的数据结构时,读者执行如下操作:
1)它执行宏rcu_read_lock(),该宏等价于preempt_disable()。
2)读者解除对数据结构指针的引用,并开始读取数据。
3)读者不能睡眠直到它完成对数据结构的读操作。用宏rcu_read_unlock()标识临界区结束,该宏等价于preempt_enable()。
当写者(如:内核线程)需要写RCU保护的数据结构时,写者执行如下操作:
1)当一个写者想更新数据结构,它解除指针的引用并产生整个数据结构的拷贝
2)写者修改拷贝。
3)一旦完成修改,写者修改指向数据结构的指针,让它指向已更新的拷贝。由于改变指针值是一个原子操作,每个读者或写看旧拷贝或新拷贝,在数据结构中不会有崩溃发生。
仅在数据被修改后,应加上内存屏障确保其他CPU能看见更新的指针。如果与RCU成对使用自旋锁阻止写者同时执行,那么隐含地引入了内存屏障。
RCU同步需要解决的问题说明如下:
- 当写者更新指针时,数据结构的旧拷贝不能马上被释放。
- 当写者开始更新时,正访问数据结构的读者可能还在读旧的拷贝。
- 仅所有CPU上的所有读者读完数据、执行完rcu_read_unlock()时,旧的拷贝才能被释放。内核要求每一个潜在的读者在下面的时刻之前执行宏rcu_read_unlock():
- CPU执行进程切换
- CPU开始在用户模式下执行。
- CPU执行空闲循环。
RCU同步由三个基本机制组成,分别说明如下:
1)出版-预订机制,用于插入操作。
2)等待以前存在的RCU读者完成读操作,用于删除操作。
3)维护最近更新对象的多个版本,用于允许读者容忍并发的插入和删除。
下面详细说明这三种机制:
(1)出版-预订机制
RCU最重要的属性是:即使在数据被同时修改时线程也能安全浏览数据。RCU通过出版-预订机制(Publish-Subscribe Mechanism)实现这种并发的插入操作能力。
例如:对于初始值为NULL的全局指针gp,线程将它修改指向一个新分配的初始化结构。相应代码列出如下:
1 struct foo {
2 int a;
3 int b;
4 int c;
5 };
6 struct foo *gp = NULL;
7
8 /* . . . */
9
10 p = kmalloc(sizeof(*p), GFP_KERNEL);
11 p->a = 1;
12 p->b = 2;
13 p->c = 3;
14 gp = p;
上述代码中,没有任何措施强制编译器和CPU依次执行最后4个赋值语句。如果gp的赋值操作(14行)发生在初始化p的域成员(11~13行)之前时,那么,并发的读者可能看见未初始化的值。为了保证执行的排序,必须加内存屏障,但内存屏障很难用,因此,我们将它们包裹在一个原语rcu_assign_pointer()中,该原语具有出版语义。最后4行代码就变为如下代码:
1 p->a = 1;
2 p->b = 2;
3 p->c = 3;
4 rcu_assign_pointer(gp, p);
函数rcu_assign_pointer()将出版新结构,强制编译器和CPU在赋值给p引用的域后,再执行gp赋值操作。
但是,仅强制更新时排序是不够的,读者也必须强制合适的次序。例如:下面的代码片断:
1 p = gp;
2 if (p != NULL) {
3 do_something_with(p->a, p->b, p->c);
4 }
DEC Alpha CPU和值猜测编译器优化可能引起p->a, p->b和p->c值在p值获取之前支取。这种情况在值猜测编译器优化中最容易看见:编译器猜测p的值,支取p->a、p->b和p->c后,再支取p的实际值来检查它的猜测是否正确。此时,需要使用rcu_dereference(),代码变为:
1 rcu_read_lock();
2 p = rcu_dereference(gp);
3 if (p != NULL) {
4 do_something_with(p->a, p->b, p->c);
5 }
6 rcu_read_unlock();
原语rcu_dereference()可看作预订一个指针的给定值,确保随后的解除引用操作将看见初始化发生在相应的出版操作(rcu_assign_pointer())之前。
函数rcu_read_lock()和rcu_read_unlock()调用是需要的:它们用于RCU读侧临界部分关闭内核抢占。
虽然rcu_assign_pointer()和rcu_dereference()在理论上可用于创建任何RCU保护的数据结构,实际上它常更好地用于高层次创建数据结构。
用于连接链表指针的出版操作的样例代码列出如下:
1 struct foo {
2 struct list_head list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head); //初始化链表头head,它是全局变量
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 list_add_rcu(&p->list, &head); /*含有出版操作*/
上述代码第15行必须被一些同步机制保护(通常是锁),阻止多个list_add()实例执行并发操作。但是,这种同步不能阻止list_add()与RCU读者并发执行。双向链表如图1所示。 
图1 双向链表示意图
对RCU保护的链表的预订操作代码列出如下:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, head, list) { /*预订操作*/
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
原语list_add_rcu()出版了一个条目进指定链表,为了保证添加的条目在浏览时有效,调用了原语list_for_each_entry_rcu()确保将正确预订此条目。
Linux的另外一种双向连接的哈希链表hlist是一个线性链表,如图2所示,它仅需要一个头指针,而不是循环链表的双向指针。因此,对于大型hash表的hash-bucket来说,hlist的使用可以节约一半内存消耗。 
图2 哈希链表示意图
出版一个新元素到RCU保护的链表hlist类似于循环链表,代码列出如下:
1 struct foo {
2 struct hlist_node *list;
3 int a;
4 int b;
5 int c;
6 };
7 HLIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 hlist_add_head_rcu(&p->list, &head);
第15行必须被同步机制保护。
预订RCU保护的hlist也类似于循环链表,代码列出如下:
1 rcu_read_lock();
2 hlist_for_each_entry_rcu(p, q, head, list) {
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
RCU出版和预订原语显示在表1中,还包括附加的非出版或回收原语。
表1 RCU出版、预订原语和回收原语说明
| 类型 | 出版函数 | 回收函数 | 预订函数 |
| 指针 | rcu_assign_pointer() | rcu_assign_pointer(..., NULL) | rcu_dereference() |
| 循环链表 | list_add_rcu() list_add_tail_rcu() list_replace_rcu() |
list_del_rcu() | list_for_each_entry_rcu() |
| 链表hlist | hlist_add_after_rcu() hlist_add_before_rcu() hlist_add_head_rcu() hlist_replace_rcu() |
hlist_del_rcu() | hlist_for_each_entry_rcu() |
(2)等待以前存在的RCU读者完成操作
RCU读侧临界部分以rcu_read_lock()原语开始,以rcu_read_unlock()原语结束。RCU读侧临界部分可以嵌套,还可以包括任何代码,只要代码不阻塞或睡眠。另有一种称为SRCU(Special RCU)的特殊形式RCU,允许在SRCU读侧临界部分有通常的睡眠。
如图3所示,RCU等待以前存在的RCU读侧临界部分完全完成,包括该临界部分执行的内存操作。注意:在给定的宽限期开始后才开始的RCU读侧临界部分可在宽限期结束时扩展。

图3 RCU宽限期
使用RCU等待读者的基本算法形式说明如下:
- 有一个改变产生,如:替换连接的链表中一个元素。
- 等待所有以前RCU读侧临界部分完成操作(如:使用synchronize_rcu()原语等待)。这里观察关键是随后的RCU读侧临界部分有没有办法获取对新删除元素的引用。
- 清除,如:释放上面被替换的元素。
下面的代码片断样例说明了上述算法:
1 struct foo {
2 struct list_head list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = search(head, key);
12 if (p == NULL) {
13 /* Take appropriate action, unlock, and return. */
14 }
15 q = kmalloc(sizeof(*p), GFP_KERNEL);
16 *q = *p;
17 q->b = 2;
18 q->c = 3;
19 list_replace_rcu(&p->list, &q->list);
20 synchronize_rcu();
21 kfree(p);
19, 20和21行实际了上面所说的三步。当允许并发读时,16行拷贝,17~19行进行更新。
原语synchronize_rcu()等待所有RCU读侧临界部分完成,并且rcu_read_lock()和rcu_read_unlock()界定RCU读侧临界部分在非抢占内核中不产生任何代码,该读侧临界部分不允许阻塞和睡眠。因此,当给定的CPU执行上下文切换时,可以保证任何以前的RCU读侧临界部分已完成。这意味着只要每个CPU已执行完至少一个上下文切换,所有以前的RCU读侧临界部分可以保证已完成,synchronize_rcu()可完全返回。
古典RCU的synchronize_rcu()能从概念上简化为如下方法:
1 f or_each_online_cpu(cpu)
2 run_on(cpu);
其中,run_on()切换当前线程到指定的CPU,它强迫进行CPU的上下文切换。原语for_each_online_cpu()循环因此强制每个CPU上进行上下文切换,确保所有以前的RCU读侧临界部分已完成。
内核在RCU读侧临界部分关闭内核抢占,但对于实时抢占内核来说,这是不行的,作为替换,实时RCU在RCU读侧临界部分使用基于引用计算的方法。
实际的内核实现更为复杂,需要处理中断、NMI、CPU热插拔和其他可能产生的危险。另外,RCU的实时实现还提供良好的实时反应。
(3)维护最近更新对象的多个版本
下面通过2个例子说明RCU如何维护最近更新对象的多个版本。第1个例子显示了删除一个链表元素,第2个例子显示了替换一个元素。
样例1:在删除期间维护多个版本
将以前样例的11~21行修改如下:
1 p = search(head, key);
2 if (p != NULL) {
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }
包括指针p的链表的初始状态如图5所示。每个元素的三个值代表域a、b和c。每个元素的红色边框表示读者可能正持有对它们的引用,并且,由于读者没有直接与更新者同步,读者可能与整个替换进程并行运行。注意:我们省略了向后指针和从链表末尾指向链表头的指针。 
图5 包括指针p的链表的初始状态 图6读才看到旧版本和新版本链表
在第3行的list_del_rcu()已完成后,5,6,7元素已被从链表删除,如图6所示。因为读者不直接与更新者同步,读者可能同时并行扫描此链表。依赖于时间,这些并发的读者可能看见或者没有看见新删除的元素。
然而,被延迟(如:由于中断,ECC内存错误或者实时抢占内核中的抢占)的读者在获取一个指向新删除元素的指针后,可能在删除后的很长时间内看见链表的旧版本。因此,我们有链表的2个版本,如图6所示,一个带有元素“5,6,7”,另一个没有。元素“5,6,7”的边界还是红的,表示读者可能正在引用它。
注意:在从它们的读侧临界部分退出出,读者不被允许维护对元素“5,6,7”的引用。因此,一旦在4行的synchronize_rcu()完成(确保所有以前存在的读者被保证完成)后,不会有更多的读者引用此元素,在图7中用它的黑色边框标识出。这样,我们回到了一个单版本的链表。 
图7 读者不会引用删除元素的新版本链表 图8 释放了删除元素的新版本链表
至此,元素“5,6,7”可被完全地释放,显示如图8所示。
至此,我们已完成了元素“5,6,7”的删除。
样例2:链表在替换期间维护多个版本
链表替换操作的代码列出如下:
1 q = kmalloc(sizeof(*p), GFP_KERNEL);
2 *q = *p;
3 q->b = 2;
4 q->c = 3;
5 list_replace_rcu(&p->list, &q->list);
6 synchronize_rcu();
7 kfree(p);
链表的初始状态包括指针p,与删除操作的样例一样,如图1所示。 
图1 替换链表的初始状态 图2 分配了替换元素的链表
第1行用函数kmalloc()分配了一个替换元素,如图2所示。
第2行拷贝旧元素到新元素,如图3所示。 
图3 拷贝了元素的链表 图4 更新了q->b的链表
第3行,更新q->b 到值“2”,如图4所示。
第4行更新q->c到值“3”,如图5所示。 
图5更新了q->c的链表 图6 替换操作时的链表
现在,第5行进行替换操作,以便新元素最终对读者可见。此时,显示如图6,我们有2个版本的链表。以前存在的读者可能看见元素“5,6,7”,新读者将看见元素“5,2,3”。但可保证任何给定的读者看见定义好的链表。
在第6行的synchronize_rcu()后,宽限期将消失,这时,在list_replace_rcu()之前开始的所有的读者操作已完成。特别是:可能已持有对元素“5,6,7”引用的读者已退出它们的RCU读侧临界部分,并禁止继续持有引用。因此,不可能再有任何读者持有对旧元素的引用,用下围绕元素“5,6,7”的薄黑边框显示。正如读者关心的,链表回到了单个版本,新元素替换了旧元素,如图7所示。 
图 7 宽限期结束时的链表 图8 释放了旧元素的链表
在第7行的kfree()完成后,链表显示如图8所示。
RCU是读/写锁的替换品,两种的用法有些类似,下面以链表的搜索和删除为例,将两个同步机制的实现代码对比列出如下:
1 struct el { 1 struct el {
2 struct list_head list; 2 struct list_head list;
3 long key; 3 long key;
4 spinlock_t mutex; 4 spinlock_t mutex;
5 int data; 5 int data;
6 /* Other data fields */ 6 /* Other data fields */
7 }; 7 };
8 rwlock_t listmutex; 8 spinlock_t listmutex;
9 struct el head; 9 struct el head;
1 int search(long key, int *result) 1 int search(long key, int *result)
2 { 2 {
3 struct list_head *lp; 3 struct list_head *lp;
4 struct el *p; 4 struct el *p;
5 5
6 read_lock(&listmutex); 6 rcu_read_lock();
7 list_for_each_entry(p, head, lp) { 7 list_for_each_entry_rcu(p, head, lp) {
8 if (p->key == key) { 8 if (p->key == key) {
9 *result = p->data; 9 *result = p->data;
10 read_unlock(&listmutex); 10 rcu_read_unlock();
11 return 1; 11 return 1;
12 } 12 }
13 } 13 }
14 read_unlock(&listmutex); 14 rcu_read_unlock();
15 return 0; 15 return 0;
16 } 16 }
1 int delete(long key) 1 int delete(long key)
2 { 2 {
3 struct el *p; 3 struct el *p;
4 4
5 write_lock(&listmutex); 5 spin_lock(&listmutex);
6 list_for_each_entry(p, head, lp) { 6 list_for_each_entry(p, head, lp) {
7 if (p->key == key) { 7 if (p->key == key) {
8 list_del(&p->list); 8 list_del_rcu(&p->list);
9 write_unlock(&listmutex); 9 spin_unlock(&listmutex);
10 synchronize_rcu();
10 kfree(p); 11 kfree(p);
11 return 1; 12 return 1;
12 } 13 }
13 } 14 }
14 write_unlock(&listmutex); 15 spin_unlock(&listmutex);
15 return 0; 16 return 0;
16 } 17 }
RCU基本设计模式
RCU基本设计模式包括纯RCU、RCU存在锁、读-写-锁/RCU模拟和RCU读者/NBS写者,分别说明如下:
(1)纯RCU
纯RCU(Pure RCU)使用RCU加速仅读的访问,应用在可以容忍延迟和不一致数据的情况下。纯RCU模式在这种情况下特别有用:在更新可能进行之前所有已进行处理的中断处理例程必须完成。
纯RCU允许读侧并行,读侧同步负荷为0.在读为大多数的情况下提供优秀的执行效率。读侧代码不需要任何同步原语,除了在DEC Alpha平台需要读侧内存屏障外,这是因为DEC Alpha是极端的弱内存一致性模型。
具有下面的属性的程序可以使用纯RCU:
- 运行在这种环境下,该环境由短的、可快速完成的工作单元组成,如:操作系统内核、服务器应用程序或事件驱动的实时系统。
- 能容忍延迟的数据,可通过高层处理部分丢弃数据。
- 能容忍不一致的数据,要求读者仅引用一次给定的数据条目,并且写者进行原子更新。
大量案例可以接受这些属性,还有很多能少量接收这些属性的算法,可以转换成允许使用纯RCU的算法。可容忍延迟和不一致数据的案例包括:路由表、维护硬件或软件配置信息的数据结构、决策支持启发式(decision-support heuristics)和带有收敛检查的算术算法等。
纯RCU存在中断关闭问题。如:一个网络设备正在操作中,并且设备的中断处理例程使用了大量动态分配的数量结构。设备处理中断时将关闭该中断,不允许再次执行该中断。但在多处理器系统中,来自设备的较早中断的处理例程可能还在执行。在不需要每个中断承担获得锁的开销情况下,怎样才能知道何时释放中断处理例程的数据结构才是安全的?
纯RCU解决中断竞争的方法如下:
1)关闭设备的中断。
2)如果需要,等待任何中断从设备传播到达CPU(通常通过从设备寄存器读操作或设备复位完成)。
3)使用syschronize_kernel()阻塞一个宽限期,在宽限期的末尾,所有早期中断必须已完成。
4)这样,此时释放被设备中断处理例程访问的数据结构,将是安全的。
Linux内核中应用纯RCU的情况说明如下:
1)DYNIX/ptx的LAN驱动程序,用于仲裁LAN设备关闭和来自此设备包接收中断之间的竞争。
2)内核的IPMI和NMI处理例程。
3)内核模块卸载代码。
(2)RCU存在锁
RCU存在锁(RCU Existence Locks)延迟数据结构元素的释放,以便读者可以从一个元素到另一个元素移动指针,而不需要外在持有“存在锁”用来确保目标元素未被过早释放。RCU存在锁能极大地简化锁设计,因为外在的“存在锁”可能复杂,并可能导致死锁。RCU存在锁因为有较少的锁请求和删除了复杂的引用计数,因此,死锁问题极大地减少。
多个读者读将删除的条目时,必须直到所有的并发的读者完成读操作后,才可释放删除条目。通常的方法是使用外在的存在锁或引用计数,强加同步操作给读者。
替代的方法是使用RCU synchronize_kernel()原语,它阻止释放条目,直到所有的竞争读者完成读操作,而在读者侧代码不需要加锁。下面代码显示了使用RCU存在锁的方法:
/*删除一个looktab元素,如果删除成功,返回TRUE,否则,返回FALSE*/
int looktab_delete(int key)
{
struct looktab **p;
struct looktab *q;
spin_lock(&looktab_mutex);
p = &looktab_head[LOOKTAB_HASH(key)];
while (*p != NULL) {
if((*p)->key==key){
q = *p;
*p = (*p)->next;
spin_unlock(&looktab_mutex);
synchronize_kernel(); /*延迟释放,直到并发的读者完成操作,读侧不用加锁*/
kfree(q);
return(TRUE);
}
p=&(*p)->next;
}
spin_unlock(&looktab_mutex);
return(NULL);
}
(3)读-写-锁/RCU模拟
读-写-锁/RCU模拟(Reader-Writer_Lock/RCU Analogy)用于转换一个基于读/写锁的法则到RCU,仅适用于可容忍数据延迟和不致的场合。RCU最直接的应用就是对读/写锁的替代。
下面列出读-写-锁/RCU模拟模式的典型代码。
RCU读者侧代码列出如下:
/*查找looktab元素并检查它*/
rcu_read_lock()
p = looktab_rearch(mykey);
/*省略了检查元素的代码*/
……
rcu_read_unlock()
RCU写者侧代码列出如下:
/*处理结构looktab的全局的锁*/
spinlock_t looktab_mutex;
/*查找一个looktab元素并更新它*/
spinlock(&looktab_mutex)
p = looktab_search(mykey);
/*省略了更新元素的代码*/
……
spin_unlock(&looktab_mutex);
上述代码还应注意读者与写者之间的竞争。
替换读/写锁的RCU原语与读/写锁原语函数对应函数列出如表3所示。对于已使用读/写锁的代码来说,只需要将对应的原语用RCU原语替换,就可以实现RCU了。
表3 读/写锁原语与RCU原语的对应关系
| 读者-写者锁 | RCU |
| rwlock_t spinlock_t read_lock() |
rcu_read_lock() |
| read_unlock() | rcu_read_unlock() |
| write_lock() | spin_lock() |
| write_unlock() | spin_unlock() |
| list_add() | list_add_rcu() |
| list_add_tail() | list_add_tail_rcu() |
| list_del() | list_del_rcu() |
| list_for_each() | list_for_each_rcu() |
| kfree() | call_rcu(kfree) |
(4)RCU读者/NBS写者
非阻塞性同步(Non-blocking synchronization,NBS)是线性化的同步机制,在这种同步机制下,系统中每个线程在没有其他线程干扰情况下采取有限步骤后确保完成一个操作。线性化同步机制是一种机制,保证所有CPU将观察到数据结构的同样值。例如:不需要锁的原子递增指令符合NBS定义。
RCU读者/NBS写者使用非阻塞同步而非锁住进行更新。RCU简化更新代码:当读者持有对删除元素的引用时,更新代码将延迟删除,直到读者完成操作。
变换RCU运算法则后的RCU模式
基本的RCU构架限制了RCU的应用,可通过改变容忍RCU数据延迟和不一致的运算法则来扩展RCU的应用。这些变换模式使用RCU可用于各种实际问题。通常的变换方法列出如下:
- 标识删除对象(Mark Obsolete Objects)。
- 初始对象的替代拷贝(Substitute Copy For Original)。
- 间接强制级(Impose Level Of Indirection)。
- 排序读/排序更新(Order Update With Ordered Read)。
- 全局版本号(Global Version Number)。
- 延迟更新(Stall Updates)。
下面分别对这些变换方法进行说明。
(1)标识删除对象
标识删除对象通过标识删除元素来适应不能容忍数据延迟的情况。读者将忽略这些被标识的元素。如果读者发现一个元素标识为删除,它必须看作搜索失败,这样,不会受RCU的数据延迟的影响。
但是,标识删除对象模式加入了标识变量,为了解决对标识变量的访问竞争,并且不能有数据延迟,它引入了互斥锁保护标识变量,这增加了同步负荷。
样例:标识删除对象模式的实现
下面以Hash表为例,说明标识删除对象模式的实现,样例包括读侧和写侧的代码。
读侧代码列出如下:
/*结构looktab更新的全局的锁*/
spinlock_t my_looktab_mutex;
struct looktab *my_looktab[LOOKTAB_NHASH];
……
/*查找一个looktab元素并检查它*/
p = looktab_search(my_looktab,mykey); /*如果找到元素且非删除状态时,执行spin_lock(&p->mutex)*/
if (p == NULL) {
/*省略处理搜索失败的代码*/
} else {
/ *省略检查或更新元素的代码*/
}
spin_unlock(&p->mutex):
读侧访问需要函数looktab_search()获得元素的互斥锁,这增加的负荷通常超过用锁保护结构进行删除引起的负荷。函数looktab_search()列出如下:
struct looktab* looktab_search(int key)
{
p = looktab_head[LOOKTAB_HASH(key)];
while (p!=NULL) {
if((p->key==key) && !p->obsolete) {
spin_lock(&p->mutex);
return(p);
}
p=p->next;
}
return(NULL);
}
删除元素时,必须先标识状态,为了确保所有并发的读者对删除元素的访问,必须调用函数synchronize_kernel()延迟释放。删除元素的函数looktab_delete列出如下:
/*删除一个looktab元素,如果删除成功,返回TRUE,否则,返回FALSE*/
int looktab_delete(int key)
{
struct looktab **p;
struct looktab *q;
spin_lock(&looktab_mutex);
p = &looktab_head[LOOKTAB_HASH(key)];
while (*p != NULL) {
if((*p)->key==key){
q = *p;
*p = (*p)->next;
spin_lock(&p->mutex);
q->obsolete = TRUE; /*标识删除元素*/
spin_unlock(&p->mutex);
spin_unlock(&looktab_mutex);
synchronize_kernel(); /*延迟释放,直到并发的读者完成操作,读侧不用加锁*/
kfree(q);
return(TRUE);
}
p=&(*p)->next;
}
spin_unlock(&looktab_mutex);
return(NULL);
}
(2)初始元素替代拷贝
初始对象的替代拷贝(Substitute Copy For Original)是RCU的一种变形算法,用于不能容忍数据不一致的场合。方法是:将非原子更新隐藏在一个原子替代后面。
该模式的工作原理是:分配一个新元素,拷贝旧元素到新元素中,在新元素上执行更新,执行需要的内存屏障,将旧元素替换为新元素。最后,在一个宽限期之后,旧元素被释放。读将看见旧元素或新元素。读者不需要互斥机制。
初始元素替代拷贝模式的更新代码列出如下:
/*全局的指针,作为提交点使用*/
struct foo *foop;
……
/*首先分配对象并从旧的对象进行拷贝*/
p = kmalloc(sizeof(*p));
*p = *foop; /*将旧元素foop的对象拷贝到新元素p中*/
/*在新元素上更新需要修改的域*/
p->field1 = value1;
p->field2 = value2;
/*更新:发出内存屏障,保证更新完成*/
smp_wmb();
/*更新:更新指针*/
spin_lock(&looktab_mutex); /*加锁进行元素更新*/
q = foop; /*保存旧元素*/
foop = p; /*将旧元素更新为新元素*/
spin_unlock(&looktab_mutex);
synchronize_kernel(); /*延迟一个宽限期*/
kfree(q); /*释放旧元素*/
读者侧代码用do循环再次尝试访问检测到的延迟或不一致的数据。循环主体首先获取指针foop的快照。接着执行仅在Alpha平台才有的内存屏障,在其他CPU上,解除指针foop引用看作一个隐含的内存屏障,smp_read_barrier_depends()在其他CPU上只是空函数。接着,跟随另一个内存屏障,不管访问是否需要它。该内存屏障确保直到访问完成后才评估do-while的循环条件。读者侧代码列出如下:
do {
/*快照指针*/
p = foop;
/*在Alpah平台上的内存屏障,在其他CPU上为空操作*/
smp_read_barrier_depends();
/*访问域*/
/*内存屏障*/
smp_rmb();
/*更新:更新指针*/
}while (p != foop):
此技术可应用于大型多链接的结构,尽管更新的开销随着结构尺寸的增大而增大。如果有多个指向结构的指针被替换,那么所有这些指针必须更新到指向新的拷贝。如果一个读者能移动多个指针指向正被替代的结构,那么读者可能在移动元素上看见不同版本。此模式最适应于链接数据结构执行非循环指针移动的运算法则。
(3)间接强制级
间接强制级(Impose Level Of Indirection)是初始元素替代拷贝模式的一种应用,它将相关联的数据分组为一个数据元素,这样将容易被替代。
该模式的工作原理是:将更新的域分组为一个动态分配的数据结构或数据结构组,接着,应用初始元素替代拷贝模式,使更新以原子操作形式出现。
(4)排序更新/排序读
排序读/排序更新(Order Update With Ordered Read)限制更新和读操作的排序,使用读者总是看见一致的数据。
该模式的工作原理是:通过使用内存屏障,强制更新和读操作排序。
样例:更新/排序读模式的实现
下面以数组的更新和读为例说明排序更新/排序读模式的实现。
数组更新时,将数组进行拷贝,然后对数组拷贝进行更新,加内存屏障,使更新在内存屏障之前完成。这时,才将数组拷贝替换数组,从而让读者看到一致的新数据。数组更新的代码列出如下:
/*数组更新*/
newarray = kmalloc(sizeof(*newarray) * newsize);
spin_lock(&array_lock);
oldarray = array; /*保存旧数组的地址*/
for(i=0;i<size;i++){
newarray[i] = array[i]; /*将旧数组拷贝到新数组*/
}
for(i = size; i < newsize; i++) {
initialize(&newarray[i]); /*初始化新数组*/
}
smp_wmb(); /*加内存屏障,确保新数组初始化完成*/
array = newarray; /*新数组初始化完成后,才可以给读者侧使用*/
smp_wmb();
size = newsize;
spin_unlock(&array_lock);
……
读者对数组进行读操作,更新完成后,才会对新数组进行读操作。读者代码列出如下:
/*数组查找*/
cursize = size;
smb_rmb();
curarray = array;
if(idx >= cursize){
/*处理超出范围的序号*/
} else {
/*访问元素*/
}
(5)全局版本号
全局版本号(Global Version Number)模式通过维护一个全局版本号,并将版本号与每个元素相关联,读者在访问前后对全局版本号进行采样,如果有任何干扰引起的变化,读者将再次尝试访问。这样,该模式能容忍数据延迟和不一致。
该模式的工作原理是:当每次原子更新时,递增全局的版本号。
样例:全局版本号模式在链表中的实现
下面以一个链表的删除操作为例说明全局版本号模式的实现。链表删除操作时,它先从链表中查找删除的元素,然后再进行删除操作。
为了实现该模式,链表头加入了全局版本号,可用来检查链表是否在更新。链表读操作在元素指针为空时,检查版本号是否与读操作之前一致,如果不一致,说明其他线程可能在修改此元素,重新尝试读取该元素。每次一时更新链表时,将版本号加1。
链表删除操作的代码列出如下:
/*在链表头中加入全局版本号*/
struct lookhead{
struct looktab *lh_head;
int lh_version; /*存放版本号*/
} lookhead_t
struct looktab* delete(lookhead_t *list, struct looktab *elt)
{
struct looktab *p;
int version;
/*尝试删除直到成功*/
do {
retry: /*在版本号不匹配时重新尝试*/
backoffIfNeeded(); /*在高竞争时,提供backoff算法,即通过反馈,成倍地降低进程速率*/
version = list->lh_version; /*获取当前版本号的快照*/
smp_mb();
p = list->lh_head;
/*搜索链表,查找将被删除的元素elt*/
while (p->next != elt) {
if (p == NULL) { /*指针为空,说明到链表末尾或者其他线程正在删除此元素*/
smp_mb(); /*阻止检查重排序*/
/*版本号不一致,说明链表发生变化,重新读取*/
if (version != list->lh_version) {
goto retry;
}
return NULL;
}
p = p->next;
}
/*原子地删除元素并增加版本号,如果失败,再尝试*/
} while (!DCAS(&(list->lh_version), &(p->next),
version, elt,
version+1, elt->next));
return (elt); /*返回指向刚删除元素的指针*/
}
注意:此模式容易被滥用,独立更新数据和版本号可能是不充分的,如:在数据被更新但版本号还未更新时,线程可能将访问数据的不一致的拷贝。使用时,需要修正这种bug。
(6)延迟更新
延迟更新(Stall Updates)模式是一种全局版本号模式的应用,它阻止在全局版本号模式中因过度的更新操作使读者处于饥饿状态,方法是:当在读侧过度的读尝试发生时,它进行延迟更新。
该模式的工作原理是:当重复失败时,读者用一个标识使更新延迟。另一个延迟更新的方法是在任何一对连续更新之间等待一个宽限期过期。
样例: 延迟更新模式的实现
下面的代码是延迟更新模式的实现例子,它由更新代码和读者代码两部分组成。当读者无法获取元素地址时,表示读者处于饥饿状态,读者设置标识,让更新者忙等待。更新者在标识清除后,即读者已摆脱饥饿状态时,才可以进行更新,更新后延迟释放旧元素。
可延迟的更新代码列出如下:
/*服务作版本号的全局指针*/
struct foo *foop;
……
/*更新:第一次分配并填充新值*/
while (stall_updates); /*如果需要延迟更新,就循环等待*/
p = kmalloc(sizeof(*p));
p->field1 = value1;
p->field2 = value2;
/*更新:发出内存屏障*/
smp_wmb();
/*更新: 更新指针*/
q = foop; /*保持旧元素*/
foop = p; /*更新新元素*/
synchronize_kernel(); /*延迟一个宽限期*/
kfree(q); /*释放旧元素*/
在读侧读者饥饿时设置延迟标识的代码列出如下:
stalled_by_me = FASLE;
for(;;) {
/*快照指针/版本号*/
p = foop;
/*在Alpha上的内存屏障*/
smp_read_barrier_depends();
/*访问域*/
/*内存屏障*/
smp_rmb();
/*更新:更新指针*/
if (p == foop) { /*
break;
}
if (!stalled_by_me) {
atomic_inc($stall_updates);
stalled_by_me = TRUE;
}
}
if(stalled_by_me) {
stall_updates = FALSE;
atomic_dec(&stall_updates);
}
RCU相关数据结构
结构rcu_head是RCU使用的回调结构,列出如下(在include/linux/rcupdate.h):
struct rcu_head {
struct rcu_head *next;//一个链表中的下一个更新请求
void (*func)(struct rcu_head *head);//在一个合适期间调用的实际更新函数
};
与链表rcu_head相关的宏定义如下:
#define RCU_HEAD_INIT(head) { .next = NULL, .func = NULL }
#define RCU_HEAD(head) struct rcu_head head = RCU_HEAD_INIT(head)
#define INIT_RCU_HEAD(ptr) do { \
(ptr)->next = NULL; (ptr)->func = NULL; \
} while (0)
RCU回调机制中全局控制变量结构rcu_ctrlblk如下:
struct rcu_ctrlblk {
long cur; //当前的批次号
long completed; //最后完成批次号
int next_pending; //是下一个批次已在等待
seqcount_t lock; //为当前和下一个悬挂的原子性的读而加的锁
} ____cacheline_maxaligned_in_smp;
读-拷贝更新的每个CPU的数据结构rcu_data列出如下:
struct rcu_data {
// quiescent状态处理
long quiescbatch; //grace周期的批次号
long qsctr; //用户模式/空闲循环等
long last_qsctr; //rcu在grace周期开始时qsctr的值
int qs_pending; //等待quiesc状态
//批次处理
long batch; //当前RCU批次的批次号
struct rcu_head *nxtlist; //新的回调函数队列
struct rcu_head **nxttail;
struct rcu_head *curlist; //quiescent循环开始的当前批次
struct rcu_head **curtail;
struct rcu_head *donelist;
struct rcu_head **donetail;
int cpu;
};
RCU初始化分析
函数rcu_init初始化rcu机制,如果是SMP时,在本地定时器建立之前调用,如果是单CPU时,在jiffier定时器建立之前调用。在选择RCU_CTR_INVALID时,rcu_qsctr及相关的隐含地被初始化了。函数rcu_init的函数调用层次图如图1、图2和图3,下面按层次调用图说明所调用的函数。 
图1 函数rcu_init的调用层次图 
图2 函数rcu_online_cpu的函数调用层次图 
函数rcu_offline_cpu函数调用层次图
函数rcu_init列出如下(在kernel/rcupdate.c中):
void __init rcu_init(void)
{
rcu_cpu_notify(&rcu_nb, CPU_UP_PREPARE,
(void *)(long)smp_processor_id());
//给非启动CPU注册notifier函数
register_cpu_notifier(&rcu_nb);
}
所有SMP系统中都需要函数smp_processor_id,它得到当前进程所在CPU,这个函数列出如下(在include/asm-i386/smp.h中):
#define smp_processor_id() (current_thread_info()->cpu)
static int __devinit rcu_cpu_notify(struct notifier_block *self,
unsigned long action, void *hcpu)
{
long cpu = (long)hcpu;
switch (action) {
case CPU_UP_PREPARE:
rcu_online_cpu(cpu);
break;
case CPU_DEAD:
rcu_offline_cpu(cpu);
break;
default:
break;
}
return NOTIFY_OK;
}
static struct notifier_block __devinitdata rcu_nb = {
.notifier_call = rcu_cpu_notify,
};
下面是每个CPU的rcu_data 结构和rcu_bh_data 结构的声明(在include/linux/rcupdate.h中):
DECLARE_PER_CPU(struct rcu_data, rcu_data);
DECLARE_PER_CPU(struct rcu_data, rcu_bh_data);
函数__devinit rcu_online_cpu初始化在线的CPU对应的rcu_data结构和rcu_bh_data结构,函数分析如下(在kernel/rcupdate.c中):
extern struct rcu_ctrlblk rcu_ctrlblk;
extern struct rcu_ctrlblk rcu_bh_ctrlblk;
static void __devinit rcu_online_cpu(int cpu)
{
//取得cpu序号对应的rcu_data结构,
struct rcu_data *rdp = &per_cpu(rcu_data, cpu);
//取得cpu序号对应的rcu_bh_data结构
struct rcu_data *bh_rdp = &per_cpu(rcu_bh_data, cpu);
//将rdp及cpu序号填充给rcu_ctrlblk
rcu_init_percpu_data(cpu, &rcu_ctrlblk, rdp);
rcu_init_percpu_data(cpu, &rcu_bh_ctrlblk, bh_rdp);
// 将rcu_process_callbacks初始化成一个tasklet软中断
tasklet_init(&per_cpu(rcu_tasklet, cpu), rcu_process_callbacks, 0UL);
}
函数rcu_process_callbacks从tasklet上下文做RCU处理工作。函数分析如下:
static void rcu_process_callbacks(unsigned long unused)
{
__rcu_process_callbacks(&rcu_ctrlblk, &rcu_state, &__get_cpu_var(rcu_data));
__rcu_process_callbacks(&rcu_bh_ctrlblk, &rcu_bh_state, &__get_cpu_var(rcu_bh_data));
}
static void __rcu_process_callbacks(struct rcu_ctrlblk *rcp, struct rcu_state *rsp, struct rcu_data *rdp)
{
// rcp->completed批次不在 rdp->batch批次之前?
if (rdp->curlist && !rcu_batch_before(rcp->completed, rdp->batch)) {
*rdp->donetail = rdp->curlist;
rdp->donetail = rdp->curtail;
rdp->curlist = NULL;
rdp->curtail = &rdp->curlist;
}
local_irq_disable();
if (rdp->nxtlist && !rdp->curlist) {
int next_pending, seq;
rdp->curlist = rdp->nxtlist;
rdp->curtail = rdp->nxttail;
rdp->nxtlist = NULL;
rdp->nxttail = &rdp->nxtlist;
local_irq_enable();
//开始回调函数的下一个批次
do {
seq = read_seqcount_begin(&rcp->lock);
//决定批次数量
rdp->batch = rcp->cur + 1;
next_pending = rcp->next_pending;
} while (read_seqcount_retry(&rcp->lock, seq));
if (!next_pending) {
//如果它是一个新批次就开始/调度开始
spin_lock(&rsp->lock);
rcu_start_batch(rcp, rsp, 1);
spin_unlock(&rsp->lock);
}
} else {
local_irq_enable();
}
rcu_check_quiescent_state(rcp, rsp, rdp);
if (rdp->donelist)
rcu_do_batch(rdp);
}
函数read_seqcount_begin读取s->sequence 计数,函数列出如下(在include/linux/seqlock.h中):
static inline unsigned read_seqcount_begin(const seqcount_t *s)
{
unsigned ret = s->sequence;
smp_rmb();
return ret;
}
宏定义smp_rmb强制严格的CPU处理顺序,现在wmb()实际上没做任何事,因为intel的cpu遵从intel的Processor Order处理顺序,即所写程序的顺序。
宏定义smp_rmb列出如下(在include/asm-i386/system.h中):
#define smp_wmb() rmb()
#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
宏定义alternative(oldinstr, newinstr, feature)选择使用优化的指令。不同的CPU类型有选择性的指令。这允许在通过二进制内核使用优化的指令。参数oldinstr是指旧指令,参数newinstr是指新指令,参数feature是指指令特征宏定义。参数oldinst的长度必须长于或等于参数newinstr的长度。
rcu_start_batch 函数开始grace周期处理的工作,grace周期工作分两步:
(1)rcu_start_batch函数开始一个新的grace周期,这个开始并没有广播到所有的CPU,通过将rcp->cur与rdp->quiescbatch相比较来指出哪个CPU,所有CPU的情况被记录进了rcu_state.cpumask位图表中。
(2)所有CPU必须经过一个quiescent(静止)的状态。因为grace周期的开始不是广播的,因而至少对rcu_check_quiescent_state的两个调用是要求的。第一个调用仅仅提醒一个新的grace周期在运行。接着的调用检查从grace周期开始以来是否有一个quiescent状态。如果有,就更新rcu_state.cpumask,如果这个位图表是空的,那么grace周期是完成的,如果需要的话,rcu_check_quiescent_state调用rcu_start_batch(0)来开始下一个grace周期。
注册一批新的回调函数,如果当前没有激活的批次并且被注册的这个批次还没有发生时,就开始这个新的批次。
函数rcu_start_batch分析如下:
static void rcu_start_batch(struct rcu_ctrlblk *rcp, struct rcu_state *rsp, int next_pending)
{
if (next_pending)
rcp->next_pending = 1;
if (rcp->next_pending && rcp->completed == rcp->cur) {
// cpu_online_map与nohz_cpu_mask进行位与非所得值给rsp->cpumask
cpus_andnot(rsp->cpumask, cpu_online_map, nohz_cpu_mask);
write_seqcount_begin(&rcp->lock);
rcp->next_pending = 0;
rcp->cur++;
write_seqcount_end(&rcp->lock);
}
}
函数rcu_do_batch触发完成RCU的回调函数,这些回调函数在每CPU的链表里。函数rcu_do_batch列出如下:
static void rcu_do_batch(struct rcu_data *rdp)
{
struct rcu_head *next, *list;
int count = 0;
list = rdp->donelist;
while (list) {
next = rdp->donelist = list->next;
list->func(list);
list = next;
if (++count >= maxbatch)
break;
}
if (!rdp->donelist)
rdp->donetail = &rdp->donelist;
else
tasklet_schedule(&per_cpu(rcu_tasklet, rdp->cpu));
}
RCU回调处理分析
函数call_rcu与synchronize_kernel常被其杝函数调用来作更新处理,如删除对象等,下面对这两个函数分别进行分析。
(1)函数call_rcu
写者触发函数call_rcu()除去数据结构的旧拷贝。一旦执行,回调函数通常释放旧的数据结构的拷贝。
函数call_rcu()存放回调函数的地址和它的参数到rcu_head描述子,接着将描述子插入到回调函数的每CPU链表中。内核周期地、每ticker一次执行此函数,内核检查本地CPU是否已经过一个静止状态。当所有CPU已经过一个静止状态时,一个描述子存放在rcu_tasklet每CPU变量中的本地tasklet执行所有在链表中的回调函数。
函数call_rcu将RCU回调函数排队以便在一段grace周期之后调用。其中参数head是用来将RCU更新进行排队的结构,参数func是指在一段grace周期后被调用的实际更新函数。
在一个完全的grace周期消失后的某个时间将调用更新函数。换句话说,即在所有当前正执行的RCU读操作的临界部分完成之后调用更新函数。RCU读操作临界部分是由rcu_read_lock()和rcu_read_unlock()函数之间界定的执行代码部分。
函数call_rcu列出如下(在kernel/rcupate.c中):
void fastcall call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu))
{
unsigned long flags;
struct rcu_data *rdp;
head->func = func;//加上回调函数
head->next = NULL;
local_irq_save(flags);
rdp = &__get_cpu_var(rcu_data);//得到每cpu的rcu_data结构
*rdp->nxttail = head;//将回调函数加入到相应的链表中去
rdp->nxttail = &head->next;
local_irq_restore(flags);
}
函数synchronize_kernel 等待直到一个grace周期完成后,将控制返回到调用者,换句话说,在所有当前执行的RCU读临界部分完成后,控制返回到调用者。RCU读临界部分是指rcu_read_lock()和 rcu_read_unlock()之间的代码。这个函数调用call_rcu来完成对回调函数的调用。函数synchronize_kernel列出如下:
void synchronize_kernel(void)
{
struct rcu_synchronize rcu;
init_completion(&rcu.completion);
//在RCU完成后唤醒执行wakeme_after_rcu函数
call_rcu(&rcu.head, wakeme_after_rcu);
/* Wait for it */
wait_for_completion(&rcu.completion);
}
/* Because of FASTCALL declaration of complete, we use this wrapper */
static void wakeme_after_rcu(struct rcu_head *head)
{
struct rcu_synchronize *rcu;
rcu = container_of(head, struct rcu_synchronize, head);
complete(&rcu->completion);
}
内核同步机制-RCU同步机制的更多相关文章
- Linux 2.6内核中新的锁机制--RCU
转自:http://www.ibm.com/developerworks/cn/linux/l-rcu/ 一. 引言 众所周知,为了保护共享数据,需要一些同步机制,如自旋锁(spinlock),读写锁 ...
- 内核中的锁机制--RCU
一. 引言 众所周知,为了保护共享数据,需要一些同步机制,如自旋锁(spinlock),读写锁(rwlock),它们使用起来非常简单,而且是一种很有效的同步机制,在UNIX系统和Linux系统中得到了 ...
- Linux内核同步:RCU
linux内核 RCU机制详解 简介 RCU(Read-Copy Update)是数据同步的一种方式,在当前的Linux内核中发挥着重要的作用.RCU主要针对的数据对象是链表,目的是提高遍历读取数据的 ...
- Linux内核同步 - sleepable RCU的实现
一.前言 由于曾经在Linux2.6.23上工作了多年,我对这个版本还是非常有感情的(抛开感情因素,本来应该选择longterm的2.6.32版本来分析的,^_^),本文主要就是描述Linux2.6. ...
- Java多线程02(线程安全、线程同步、等待唤醒机制)
Java多线程2(线程安全.线程同步.等待唤醒机制.单例设计模式) 1.线程安全 如果有多个线程在同时运行,而这些线程可能会同时运行这段代码.程序每次运行结果和单线程运行的结果是一样的,而且其他的变量 ...
- Java多线程的同步方式和锁机制
Object.wait(miliSec)/notify()/notifyAll() 线程调用wait()之后可以由notify()唤醒,如果指定了miliSec的话也可超时后自动唤醒.wait方法的调 ...
- ios的notification机制是同步的还是异步的
与javascript中的事件机制不同.ios里的事件广播机制是同步的,默认情况下.广播一个通知,会堵塞后面的代码: -(void) clicked { NSNotificationCenter *c ...
- java基础(27):线程安全、线程同步、等待唤醒机制
1. 多线程 如果有多个线程在同时运行,而这些线程可能会同时运行这段代码.程序每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的. 我们通过一个案例,演示线程 ...
- Linux 内核的文件 Cache 管理机制介绍
Linux 内核的文件 Cache 管理机制介绍 http://www.ibm.com/developerworks/cn/linux/l-cache/ 1 前言 自从诞生以来,Linux 就被不断完 ...
随机推荐
- PYTHON-操作系统基础
预习:操作系统基础1,编程语言的分类2,多版本共存3,执行python程序的两种方式4,变量5,输入输出6,运算符7,基本数据类型8,流程控制之if ------------------------- ...
- PYTHON-模块-time&datetime-练习 +目录规范
# 作业# 1.请写出规范目录# 并解释各文件夹的作用bin 可执行文件conf 配置文件core 主要业务逻辑db 数据文件lib 库(公共代码 第三方模块)log 日志文件 # 2.改造atm + ...
- CentOS7图形界面与命令行界面切换
1.如果在命令行模式,按Ctrl+Alt+F1,可以进入图形界面: 2.如果在图形界面下,按:Ctrl+Alt+F2,可以进入命令行模式:
- VIM 报错
syntax error: unexpected end of file if 没配对 在最后加 fi 试试 环境变量用不了 export PATH=/usr/bin:/usr/sbin:/bin:/ ...
- Sony笔记本
关机的情况下按键盘 f2键.进菜单选更改 bios设置 修改 3个地方 进bios右移 boot上 第一项 ufei改成 legacy external device改成enabled 下面启动顺序改 ...
- 委托----Func和Action
平时我们如果要用到委托一般都是先声明一个委托类型,比如: private delegate string Say(); string说明适用于这个委托的方法的返回类型是string类型,委托名Say后 ...
- DailyWallpaper v1.03 released
根据这一段时间的使用发现了一些问题,重新修正一下. 修正电脑从休眠状态中恢复时如果没有网络连接程序报错的bug. 添加了异常处理语句,防止抓取网页数据时的错误. 这个版本将是最后一个bug fix版本 ...
- 图解 VS2015 如何打包winform 安装程序
http://learn.flexerasoftware.com/content/IS-EVAL-InstallShield-Limited-Edition-Visual-Studio?lang=10 ...
- Oracle 11.2.0.4 For Windows 64bit+32bit 数据库
1.Oracle11G 32BIT介质官方链接 适用于Windows 32bit的Oracle Database 11G 第2版U4(11.2.0.4)Oracle11.2.0.4 Windows3 ...
- 「2017 山东一轮集训 Day7」逆序对
题解: 满满的套路题.. 首先显然从大到小枚举 然后每次生成的逆序对是1----(i-1)的 这样做dp是nk的 复杂度太高了 那我们转化一下问题 变成sigma(ai (ai<i) )= ...