机器学习 Logistic 回归
Logistic regression
适用于二分分类的算法,用于估计某事物的可能性。
logistic分布表达式
$ F(x) = P(X<=x)=\frac{1}{1+e^{\frac{-(x-\mu)}{\gamma}}} $
$ f(x) = F{'}(x)=\frac{e{\frac{-(x-\mu)}{\gamma}}}{\gamma(1+e{\frac{-(x-\mu)}{\gamma}}){2}} $
函数图像
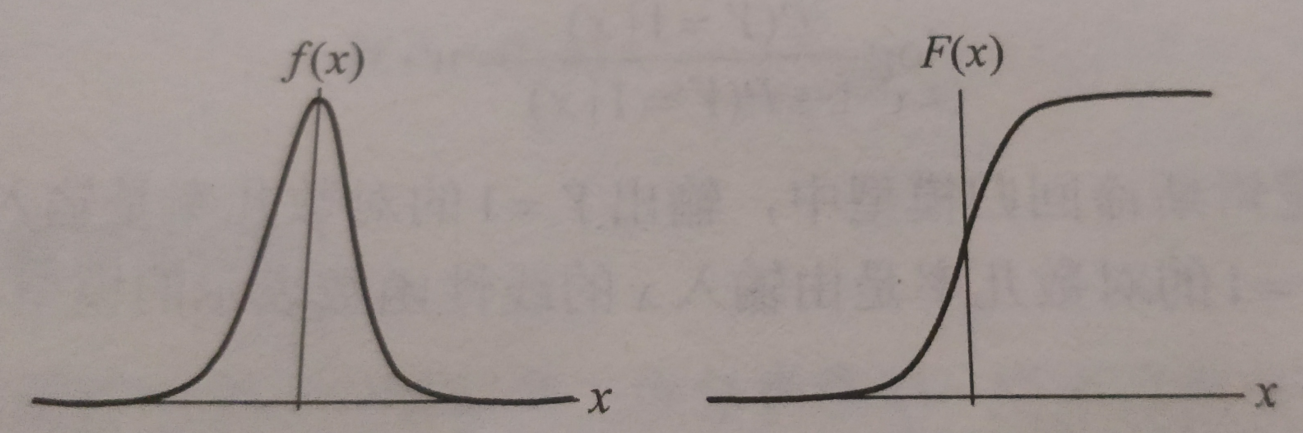
分布函数属于逻辑斯谛函数,以点 \((\mu,\frac{1}{2})\) 为中心对称
逻辑回归是一种学习算法,用于有监督学习问题时,输出y都是0或1。逻辑回归的目标是最小化预测和训练数据之间的误差。
公式推导

代码实现
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
return data[:, :2], data[:, -1]
class LogisticRegressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01, random_state=4):
self.max_iter = max_iter
self.learning_rate = learning_rate
self.weights = None
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]])
print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter))
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
if __name__ == '__main__':
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
lr_clf = LogisticRegressionClassifier()
lr_clf.fit(X_train, y_train)
print('the score = {}'.format(lr_clf.score(X_test, y_test)))
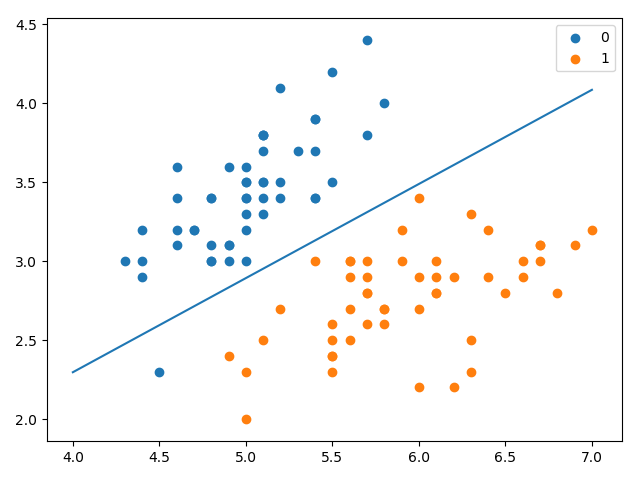
x_ponits = np.arange(4, 8)
y_ = -(lr_clf.weights[1] * x_ponits + lr_clf.weights[0]) / lr_clf.weights[2]
plt.plot(x_ponits, y_)
# lr_clf.show_graph()
plt.scatter(X[:50, 0], X[:50, 1], label='0')
plt.scatter(X[50:, 0], X[50:, 1], label='1')
plt.legend()
plt.show()
LogisticRegression Model(learning_rate=0.01,max_iter=200)
the score = 0.9666666666666667
sklearn中的logistic regression
sklearn.linear_model.LogisticRegression
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=200, multi_class='warn',
n_jobs=None, penalty='l2', random_state=None, solver='liblinear',
tol=0.0001, verbose=0, warm_start=False)
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=200,solver='liblinear')
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
print(clf.coef_, clf.intercept_)
输出
0.9666666666666667
[[ 1.96863514 -3.31358598]] [-0.36853861]
机器学习 Logistic 回归的更多相关文章
- 机器学习——Logistic回归
1.基于Logistic回归和Sigmoid函数的分类 2.基于最优化方法的最佳回归系数确定 2.1 梯度上升法 参考:机器学习--梯度下降算法 2.2 训练算法:使用梯度上升找到最佳参数 Logis ...
- 机器学习——Logistic回归
参考<机器学习实战> 利用Logistic回归进行分类的主要思想: 根据现有数据对分类边界线建立回归公式,以此进行分类. 分类借助的Sigmoid函数: Sigmoid函数图: Sigmo ...
- 机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集 鸢尾花数据集作为入门经典数据集.Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理.Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集.数据集包含150个数 ...
- 机器学习--Logistic回归
logistic回归 很多时候我们需要基于一些样本数据去预测某个事件是否发生,如预测某事件成功与失败,某人当选总统是否成功等. 这个时候我们希望得到的结果是 bool型的,即 true or fals ...
- coursera机器学习-logistic回归,正则化
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 机器学习-- Logistic回归 Logistic Regression
转载自:http://blog.csdn.net/linuxcumt/article/details/8572746 1.假设随Tumor Size变化,预测病人的肿瘤是恶性(malignant)还是 ...
- 吴恩达-机器学习+Logistic回归分类方案
- 机器学习简易入门(四)- logistic回归
摘要:使用logistic回归来预测某个人的入学申请是否会被接受 声明:(本文的内容非原创,但经过本人翻译和总结而来,转载请注明出处) 本文内容来源:https://www.dataquest.io/ ...
- 机器学习(4)之Logistic回归
机器学习(4)之Logistic回归 1. 算法推导 与之前学过的梯度下降等不同,Logistic回归是一类分类问题,而前者是回归问题.回归问题中,尝试预测的变量y是连续的变量,而在分类问题中,y是一 ...
随机推荐
- C. Trailing Loves (or L'oeufs?)
题目链接:http://codeforces.com/contest/1114/problem/C 题目大意:给你n和b,让你求n的阶乘,转换成b进制之后,有多少个后置零. 具体思路:首先看n和b,都 ...
- windows cmd相关操作
一:文件夹1. 新建文件夹方式一:md[盘符:\][路径\]新目录例如:md c:\test\newtest 方式二:先使用cmd进入需要新建文件的根目录下,使用md或者mkdir 直接创建文件夹ne ...
- 【tomcat】sessionId学习(未完待续)
这里主要研究tomcat中session的管理方式以及sessionId的原理,下文将研究sessionid存到redis中以及基于redis实现session共享. 平时也就是了解session是基 ...
- GSON中Java对象与JSON互相转换——(一)
json的转换插件是通过java的一些工具,直接将java对象或集合转换成json字符串. 常用的json转换工具有如下几种: 1)jsonlib 2)Gson:google 3)fastjson:阿 ...
- ppt 制作圆角三角形
制作圆角三角形: PART 01 :插入三角形与三个等大的圆形: PART 02 :利用[任意多边形]和[合并形状-剪除]获得缺三角: (先选中大三角形,然后再选中任意多边形,"格式&quo ...
- IAR拷贝工程后,修改工程名的方法
在实际使用过程中,经常基于某个demo进行开发,但是demo的项目名往往不满足新项目的名称,如果重新建立工程,就需要进行一系列的配置,非常麻烦,其实可以直接修改项目名,做法如下; 1. 修改项目目录下 ...
- 【vim】自动补全 Ctrl+n
Vim 默认有自动补全的功能.的确这个功能是很基本的,并且可以通过插件来增强,但它也很有帮助.方法很简单. Vim 尝试通过已经输入的单词来预测单词的结尾. 比如当你在同一个文件中第二次输入 &quo ...
- malloc 函数详解【转】
转自:https://www.cnblogs.com/Commence/p/5785912.html 很多学过C的人对malloc都不是很了解,知道使用malloc要加头文件,知道malloc是分配一 ...
- Python3学习笔记20-获取对象信息
当我们拿到一个对象的引用时,如何知道这个对象是什么类型.有哪些方法呢? 基本类型都可以用type()判断: print(type(123)) print(type('str')) print(type ...
- 20个实用的webApp前端开发技巧
自Iphone和Android这两个牛逼的手机操作系统发布以来,在互联网界从此就多了一个新的名词-WebApp(意为基于WEB形式的应用程序,运行在高端的移动终端设备). 开发者们都知道在高端智能手机 ...