学习笔记之Python全栈开发/人工智能公开课_腾讯课堂
Python全栈开发/人工智能公开课_腾讯课堂
https://ke.qq.com/course/190378
https://github.com/haoran119/ke.qq.com.python/tree/master/src/python-fullstack
Python — 爬虫、数据分析
python — 数据分析之旅,Numpy
- 数据获取
- 公开数据集(Mnist),爬虫
- 数据存储
- 数据库SQL
- 数据预处理
- 噪声,重复,缺失,空值,异常值,分组,合并,随机取样(pandas)
- 数据建模、分析
- 找一个合适的模型,统计学,概率论,机器学习,聚类,回归(sklearn)
- 数据可视化
- matplotlib
# coding: utf-8 # In[1]: import numpy as np # In[2]: # 创建数组 list1 = [ 1, 3, 5, -2, 0, -9 ]
list2 = [ 2, 4, -3, -7, 1, -7 ]
list3 = [ [2, 5, 0], [11, 3, 4] ]
list4 = [ [3, -1, 8], [9, -3, 9] ] # In[3]: arr1 = np.array( list1 ) #[ 1 3 5 -2 0 -9]
print(arr1) # In[4]: arr4 = np.array( list3 ) #[[ 2 5 0]
# [11 3 4]]
print(arr4) # In[5]: arr2 = np.arange( 1, 10, 2 ) #[1 3 5 7 9]
print(arr2) # In[6]: arr3 = np.linspace( 1, 10, 4 ) #[ 1. 4. 7. 10.]
print(arr3) # In[7]: arr_zero = np.zeros( (3, 4)) # zeros参数是元组() #[[0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]]
print(arr_zero) # In[8]: arr_one = np.ones( (3, 3) ) #[[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]
#[[100. 100. 100.]
# [100. 100. 100.]
# [100. 100. 100.]]
print(arr_one)
print(arr_one * 100) # In[9]: arr_eye = np.eye( 4, 4 ) # 对角线上元素为1,其他为0 #[[1. 0. 0. 0.]
# [0. 1. 0. 0.]
# [0. 0. 1. 0.]
# [0. 0. 0. 1.]]
print(arr_eye) # In[10]: arr_eye2 = np.eye( 4, 5 ) #[[1. 0. 0. 0. 0.]
# [0. 1. 0. 0. 0.]
# [0. 0. 1. 0. 0.]
# [0. 0. 0. 1. 0.]]
print(arr_eye2) # In[11]: # 数组的索引和切片 #[ 5 -2 0]
#[[3 4]]
print(arr1[2:5]) # 左闭右开
print(arr4[1:2, 1:3]) # In[12]: # 通用的函数 #sqrt :
# [[1.41421356 2.23606798 0. ]
# [3.31662479 1.73205081 2. ]]
#exp :
# [[7.38905610e+00 1.48413159e+02 1.00000000e+00]
# [5.98741417e+04 2.00855369e+01 5.45981500e+01]]
print("sqrt : \n", np.sqrt(arr4))
print("exp : \n", np.exp(arr4)) # In[13]: arr2 = np.array( list2 )
new_arr = np.maximum( arr1, arr2 ) #[ 2 4 5 -2 1 -7]
print(new_arr) # In[14]: # ReLU >0 保留原值,<0 取0
new_arr = np.maximum(0, arr1) #[1 3 5 0 0 0]
print(new_arr) # In[15]: #(array([[0.41421356, 0.23606798, 0. ],
# [0.31662479, 0.73205081, 0. ]]), array([[1., 2., 0.],
# [3., 1., 2.]]))
print( np.modf( np.sqrt( arr4 ) ) ) # 把整数部分和小数部分,生成两个独立的数组 # In[16]: new_arr1 = np.where( arr2>0, 'True', 'False' ) # if condition: x, y #['True' 'True' 'False' 'False' 'True' 'False']
print(new_arr1) # In[17]: #[-7 -3 1 2 4]
#[ 0 2 3 4 5 11]
print( np.unique( arr2 ) )
print( np.unique( arr4 ) ) # In[18]: # 数组作为文件来输入和输出 np.save( 'myarr', arr2 ) # 把数组保存为文件 .npy # In[19]: new_arr2 = np.load( 'myarr.npy' ) #[ 2 4 -3 -7 1 -7]
print(new_arr2) # In[20]: np.savez( 'myarrzip', a1=arr1, a2=arr2, a3=arr3 )
arr = np.load( 'myarrzip.npz' ) #[ 1 3 5 -2 0 -9]
print(arr['a1']) # In[21]: # 线性代数 矩阵
# 矩阵的合并 arr5 = np.array( list3 )
arr6 = np.array( list4 ) #[[ 2 5 0 3 -1 8]
# [11 3 4 9 -3 9]]
#[[ 2 5 0]
# [11 3 4]
# [ 3 -1 8]
# [ 9 -3 9]]
print( np.hstack( [arr5, arr6] ) )
print( np.vstack( [arr5, arr6] ) ) # In[22]: # 点乘 arr6 = np.array( list4 ).reshape( 3, 2 ) #[[ 3 -1]
# [ 8 9]
# [-3 9]]
#[[ -5 12 -4]
# [115 67 36]
# [ 93 12 36]]
print( arr6 )
print( arr6.dot( arr5 ) ) # In[23]: #[[ 3 8 -3]
# [-1 9 9]]
print( np.transpose(arr6) ) # 转置
python — 数据分析之旅,pandas
- 数据处理
- 不干净的数据
- 干净数据,随机采样
- 表格数据
- 时间序列数据
- 矩阵数据
- 观测数据
- 统计数据
- 数据清洗
- 空值(缺失值)
- pandas常用操作
- 大小可变
- 数据自动对齐
- Series(一维),Dataframe(二维)
- 分组的功能
- Numpy
- 切片,索引
- 列表和字符串
- 数据集的形状
# coding: utf-8 # In[1]: import pandas as pd
import numpy as np # In[2]: data = pd.DataFrame(pd.read_excel('originalData.xlsx')) # date hour pressure wind_direction temperature
#0 2016-07-01 0.0 1000.4 225.0 26.4
#1 2016-07-01 NaN NaN NaN NaN
#2 2016-07-01 6.0 998.9 212.0 31.7
#3 2016-07-01 235.0 998.7 244.0 NaN
#4 2016-07-01 12.0 999.7 222.0 NaN
#5 2016-07-01 15.0 1000.0 102.0 NaN
#6 2016-07-01 NaN 998.8 202.0 26.0
#7 2016-07-01 NaN 1000.2 334.0 25.5
#8 2016-07-01 NaN 1000.2 334.0 25.5
#9 2016-07-02 3.0 1002.4 46.0 30.0
#10 2016-07-02 6.0 1001.3 37.0 29.3
#11 2016-07-02 9.0 1001.9 345.0 25.9
#12 2016-07-02 12.0 1003.6 113.0 25.1
#13 2016-07-02 12.0 1003.6 113.0 25.1
#14 2016-07-02 15.0 1002.4 138.0 25.3
# hour pressure wind_direction temperature
#count 11.000000 14.000000 14.000000 11.000000
#mean 29.545455 1000.864286 190.500000 26.890909
#std 68.313049 1.685963 102.932951 2.311473
#min 0.000000 998.700000 37.000000 25.100000
#25% 6.000000 999.775000 113.000000 25.400000
#50% 12.000000 1000.300000 207.000000 25.900000
#75% 13.500000 1002.275000 239.250000 27.850000
#max 235.000000 1003.600000 345.000000 31.700000
print(data)
print(data.describe()) # In[3]: #RangeIndex(start=0, stop=15, step=1)
#Index(['date', 'hour', 'pressure', 'wind_direction', 'temperature'], dtype='object')
print(data.index)
print(data.columns) # In[4]: # date hour pressure wind_direction temperature
#0 2016-07-01 0.0 1000.4 225.0 26.4
#1 2016-07-01 NaN NaN NaN NaN
#2 2016-07-01 6.0 998.9 212.0 31.7
#3 2016-07-01 235.0 998.7 244.0 NaN
#4 2016-07-01 12.0 999.7 222.0 NaN
#5 2016-07-01 15.0 1000.0 102.0 NaN
# date hour pressure wind_direction temperature
#9 2016-07-02 3.0 1002.4 46.0 30.0
#10 2016-07-02 6.0 1001.3 37.0 29.3
#11 2016-07-02 9.0 1001.9 345.0 25.9
#12 2016-07-02 12.0 1003.6 113.0 25.1
#13 2016-07-02 12.0 1003.6 113.0 25.1
#14 2016-07-02 15.0 1002.4 138.0 25.3
print(data.head(6))
print(data.tail(6)) # In[5]: # 1. 删掉空白值超过3的行
data.dropna(axis=0, thresh=3, inplace=True)
data.reset_index(drop=True, inplace=True) # date hour pressure wind_direction temperature
#0 2016-07-01 0.0 1000.4 225.0 26.4
#1 2016-07-01 6.0 998.9 212.0 31.7
#2 2016-07-01 235.0 998.7 244.0 NaN
#3 2016-07-01 12.0 999.7 222.0 NaN
#4 2016-07-01 15.0 1000.0 102.0 NaN
#5 2016-07-01 NaN 998.8 202.0 26.0
#6 2016-07-01 NaN 1000.2 334.0 25.5
#7 2016-07-01 NaN 1000.2 334.0 25.5
#8 2016-07-02 3.0 1002.4 46.0 30.0
#9 2016-07-02 6.0 1001.3 37.0 29.3
#10 2016-07-02 9.0 1001.9 345.0 25.9
#11 2016-07-02 12.0 1003.6 113.0 25.1
#12 2016-07-02 12.0 1003.6 113.0 25.1
#13 2016-07-02 15.0 1002.4 138.0 25.3
print(data) # In[6]: # 2. 填充空白,hour填充10,temperature填充25.5
data.fillna({'hour':10, 'temperature':25.5}, inplace=True) # date hour pressure wind_direction temperature
#0 2016-07-01 0.0 1000.4 225.0 26.4
#1 2016-07-01 6.0 998.9 212.0 31.7
#2 2016-07-01 235.0 998.7 244.0 25.5
#3 2016-07-01 12.0 999.7 222.0 25.5
#4 2016-07-01 15.0 1000.0 102.0 25.5
#5 2016-07-01 10.0 998.8 202.0 26.0
#6 2016-07-01 10.0 1000.2 334.0 25.5
#7 2016-07-01 10.0 1000.2 334.0 25.5
#8 2016-07-02 3.0 1002.4 46.0 30.0
#9 2016-07-02 6.0 1001.3 37.0 29.3
#10 2016-07-02 9.0 1001.9 345.0 25.9
#11 2016-07-02 12.0 1003.6 113.0 25.1
#12 2016-07-02 12.0 1003.6 113.0 25.1
#13 2016-07-02 15.0 1002.4 138.0 25.3
print(data) # In[7]: # 3. 删掉hour>24的行
num = data.index.max() for i in range(num):
if data.loc[i, 'hour'] > 24:
data.drop([i], inplace=True)
print('hour > 24, deleted') data.reset_index(drop=True, inplace=True) #hour > 24, deleted
# date hour pressure wind_direction temperature
#0 2016-07-01 0.0 1000.4 225.0 26.4
#1 2016-07-01 6.0 998.9 212.0 31.7
#2 2016-07-01 12.0 999.7 222.0 25.5
#3 2016-07-01 15.0 1000.0 102.0 25.5
#4 2016-07-01 10.0 998.8 202.0 26.0
#5 2016-07-01 10.0 1000.2 334.0 25.5
#6 2016-07-01 10.0 1000.2 334.0 25.5
#7 2016-07-02 3.0 1002.4 46.0 30.0
#8 2016-07-02 6.0 1001.3 37.0 29.3
#9 2016-07-02 9.0 1001.9 345.0 25.9
#10 2016-07-02 12.0 1003.6 113.0 25.1
#11 2016-07-02 12.0 1003.6 113.0 25.1
#12 2016-07-02 15.0 1002.4 138.0 25.3
print(data) # In[8]: # 4. 删掉重复的数据行,保留出现的第一行(全部删掉?保留最后一行?)
data.drop_duplicates(keep='first', inplace=True)
data.reset_index(drop=True, inplace=True) # date hour pressure wind_direction temperature
#0 2016-07-01 0.0 1000.4 225.0 26.4
#1 2016-07-01 6.0 998.9 212.0 31.7
#2 2016-07-01 12.0 999.7 222.0 25.5
#3 2016-07-01 15.0 1000.0 102.0 25.5
#4 2016-07-01 10.0 998.8 202.0 26.0
#5 2016-07-01 10.0 1000.2 334.0 25.5
#6 2016-07-02 3.0 1002.4 46.0 30.0
#7 2016-07-02 6.0 1001.3 37.0 29.3
#8 2016-07-02 9.0 1001.9 345.0 25.9
#9 2016-07-02 12.0 1003.6 113.0 25.1
#10 2016-07-02 15.0 1002.4 138.0 25.3
print(data) # In[9]: # 5. 数据重排
randnum = np.random.permutation(data.index.size) #[ 4 0 10 3 1 5 8 9 7 2 6]
print(randnum) # In[10]: data2 = data.take(randnum) # date hour pressure wind_direction temperature
#4 2016-07-01 10.0 998.8 202.0 26.0
#0 2016-07-01 0.0 1000.4 225.0 26.4
#10 2016-07-02 15.0 1002.4 138.0 25.3
#3 2016-07-01 15.0 1000.0 102.0 25.5
#1 2016-07-01 6.0 998.9 212.0 31.7
#5 2016-07-01 10.0 1000.2 334.0 25.5
#8 2016-07-02 9.0 1001.9 345.0 25.9
#9 2016-07-02 12.0 1003.6 113.0 25.1
#7 2016-07-02 6.0 1001.3 37.0 29.3
#2 2016-07-01 12.0 999.7 222.0 25.5
#6 2016-07-02 3.0 1002.4 46.0 30.0
print(data2) # In[11]: # 6. 随机采样
data3 = data.sample(8) # date hour pressure wind_direction temperature
#4 2016-07-01 10.0 998.8 202.0 26.0
#0 2016-07-01 0.0 1000.4 225.0 26.4
#2 2016-07-01 12.0 999.7 222.0 25.5
#1 2016-07-01 6.0 998.9 212.0 31.7
#5 2016-07-01 10.0 1000.2 334.0 25.5
#9 2016-07-02 12.0 1003.6 113.0 25.1
#7 2016-07-02 6.0 1001.3 37.0 29.3
#8 2016-07-02 9.0 1001.9 345.0 25.9
print(data3)
data3.to_csv('data3.csv')
python — 数据分析之旅,matplotlib
- Numpy
- 科学计算
- pandas
- 数据清洗 / 去重 / 修改删除异常值 / 随机采样 / 重排
- 数据分析的流程
- 数据建模
- 学习规律,指导将来的决策 - 机器学习
- 数据 图
- 数据可视化
- Python开发
- 语法简洁
- 丰富的库
- 标准库
- 第三方库
- numpy / pandas / matplotlib
- PyPI.org
- 构建快速原型
- AI主流的编程语言
# coding: utf-8 # In[1]: import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D # In[2]: # 1. 线形图 y = ax + b
x = np.linspace(1, 21, 20)
y = 2 * x + 3
y2 = np.sin(x) plt.plot(x, y, 'm^:', x, y2) plt.show() # In[3]: # 2. 散点图
n = 1024
x = np.random.normal(0, 1, n) #1024个符合高斯分布的值
y = np.random.normal(0, 1, n) plt.scatter(x, y, s=np.random.rand(n)*50, c=np.random.rand(n), alpha=0.7) plt.show() # In[4]: # 3. 柱状图
n = 10
x = np.arange(n)
y1 = (1 - x / float(n)) * np.random.uniform(0.5, 1.0, n)
y2 = (1 - x / float(n)) * np.random.uniform(0.5, 1.0, n) plt.bar(x, y1, facecolor='red', edgecolor='white')
plt.bar(x, -y2, facecolor='blue', edgecolor='black') for xx, y in zip(x, y1):
plt.text(xx, y + 0.1, '%0.2f'%y, ha='center', va='bottom') for xx, y in zip(x, -y2):
plt.text(xx, y - 0.1, '%0.2f'%y, ha='center', va='bottom') plt.ylim(-1.5, 1.5) plt.show() # In[5]: # 4. 3D
fig = plt.figure(figsize=(12, 8))
ax = Axes3D(fig)
x = np.arange(-4, 4, 0.25)
y = np.arange(-4, 4, 0.25) x, y = np.meshgrid(x, y)
#[[-4. -3.75 -3.5 ... 3.25 3.5 3.75]
# [-4. -3.75 -3.5 ... 3.25 3.5 3.75]
# [-4. -3.75 -3.5 ... 3.25 3.5 3.75]
# ...
# [-4. -3.75 -3.5 ... 3.25 3.5 3.75]
# [-4. -3.75 -3.5 ... 3.25 3.5 3.75]
# [-4. -3.75 -3.5 ... 3.25 3.5 3.75]]
print(x)
#[[-4. -4. -4. ... -4. -4. -4. ]
# [-3.75 -3.75 -3.75 ... -3.75 -3.75 -3.75]
# [-3.5 -3.5 -3.5 ... -3.5 -3.5 -3.5 ]
# ...
# [ 3.25 3.25 3.25 ... 3.25 3.25 3.25]
# [ 3.5 3.5 3.5 ... 3.5 3.5 3.5 ]
# [ 3.75 3.75 3.75 ... 3.75 3.75 3.75]]
print(y) z = np.sin(np.sqrt(x**2 + y**2)) ax.plot_surface(x, y, z, cmap=plt.get_cmap('autumn')) plt.show() # In[6]: # 5. 一图多画
x = np.linspace(0, 5, 5)
y1 = x**2
y2 = 2 * x
y3 = np.sin(x)
y4 = np.cos(x) ax1 = plt.subplot(221)
plt.plot(x, y1)
ax2 = plt.subplot(2, 2, 2)
plt.plot(x, y2)
ax3 = plt.subplot(223)
plt.plot(x, y3)
ax4 = plt.subplot(2, 2, 4)
#plt.plot(x, y4) plt.show()
Python - 人工智能
全方位认识python
- Python大器晚成原因
- 1990那个年代,计算机性能比现在差很多,程序执行速度和效率更重要,快速开发不是第一要务,压榨机器性能才是。
- Python非大企业出身
- Python语言特点
- 简单易学、明确优雅、开发速度快
- 跨平台、可移植、可扩展、交互式、解释型面向对象的动态语言
- 解释型:Python语言在执行过程中由解释器逐行分析,逐行运行并输出结果
- “自带电池”,大量的标准库和第三方库
- 社区活跃,贡献者多,互帮互助
- 开源语言,发展动力巨大
- Python的缺点
- 运行速度相对慢点。
- GIL(Global Interpreter Lock)全局解释器锁 。
- Python的应用方向
- 常规软件开发
- 科学计算
- WEB开发
- 网络爬虫
- 数据分析
- 人工智能
全面解读人工智能
- 人工智能 / 机器学习 / 深度学习
- 人工智能(Artificial Intelligence)
- 人工智能类型
- 弱人工智能
- 包含基础的、特定场景下角色型的任务,如Siri,ALphaGo等
- 通用人工智能
- 包含人类水平的任务,涉及机器的持续学习
- 强人工智能
- 比人类更聪明的机器
- 弱人工智能
- 手机中的AI
- 智能美图
- 智能搜索排序
- 自动驾驶
- 智能会话
- 机器翻译
- 智能物流
- 新一代AI应用
- 理论与基础技术
- 大数据智能
- 技术研究
- 语言识别
- 自然语言理解
- 图像识别
- 应用研发
- 聊天界面(小冰)
- 语音助手(Siri)
- 语音记录(讯飞)
- 翻译(谷歌)
- 智能音箱(亚马逊Echo)
- 延展性和渗透性:智能音箱
- 理论与基础技术
- 人工智能的技术架构
- 应用层
- 智能产品
- 应用平台
- 技术层
- 通用技术
- 算法模型
- 基础框架
- 基础层
- 数据资源
- 软件设施
- 硬件设施
- 应用层
- 机器学习
- 计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务
- 互联网大数据中挖掘出有用的价值
- 机器学习算法分类、解决什么问题
- 监督学习
- 需要用已知结果的数据做训练
- 输入的数据有相对应的标签
- 分类问题
- 根据数据样本上抽取的特征,判定其属于有限个类别中的哪一个
- 回归问题
- 根据数据样本上抽取的特征,预测一个连续值的结果
- 非监督学习
- 不需要已知标签
- 输入的信息不知道是什么分类,不知道规则,没有输出,结果就是寻找数据中的规则
- 聚类问题
- 根据数据样本上抽取的特征,让样本抱团(相近/相关的样本在一团内)
- 半监督学习
- 近几年新起的介于监督学习与非监督学习之间。先少量标注一部分数据,然后寻找这部分数据的特征,自动给剩下的数据标注标签。
- 强化学习
- 强调如何基于环境而行动,以取得最大化的预期收益。有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。常被应用在机器人、无人机等领域。
- 监督学习
- 机器学习的应用
- 数据挖掘
- 计算机视觉
- 自然语言处理
- 生物特征识别
- 搜索引擎
- 医学诊断
- 检测信用卡欺诈
- 证券市场分析
- 语音和手写识别
- 机器人
- 机器学习的学习路径
- 数学基础
- 微积分
- 机器学习中大多数算法的求解过程的核心
- 线性代数
- 矩阵的各种运算
- 概率与统计
- 朴素贝叶斯
- 隐式马尔可夫
- 微积分
- 机器学习典型方法
- 分类问题
- 决策树、支持向量机(SVM)、随机森林、朴素贝叶斯、深度神经网络
- 回归问题
- 线性回归、普通最小二乘回归、逐步回归
- 聚类问题
- K均值(K-means)、基于密度聚类
- 降维
- 主成分分析(PCA)、奇异值分解(SVD)
- 其他算法
- Adaboost、EM等
- 分类问题
- 编程基础
- Python有全品类的数据科学工具
- Scrapy:网页爬虫
- Pandas:数据浏览与预处理
- numpy:数组运算
- scipy:高效的科学计算
- matplotlib:非常方便的数据可视化工具
- scikit-learn:远近闻名的机器学习package,接口封装好,几乎所有的机器学习算法输入输出格式都一致。支持文档可以直接当教程来学习。
- libsvm:高效的svm模型实现
- keras/TensorFlow:深度学习,方便搭建自己的神经网络
- nltk:自然语言处理相关功能做的非常全面,有典型语料库,上手容易
- R - 开源,有许多可用的包
- C++ - mlpack,Shark
- Java - WEKA Machine Learning Workbench
- Python有全品类的数据科学工具
- 数学基础
- 机器学习实施过程
- 原始样本集
- 特征提取
- 特征样本集
- 预处理
- 训练集 - 训练 / 验证集 - 预测
- 机器学习算法
- 输出
- 验证集 / 预测目标
- 评价 / 改进
- 深度学习
- 一类算法集合,机器学习的一个分支,尝试为数据的高层次摘要进行建模
- 人工神经网络
- 深度神经网络
- CNN、RNN、FCN
- 人工智能、机器学习、深度学习三者的关系
- 人工智能
- 让机器像人一样思考
- 国际跳棋程序
- 机器学习
- 人工智能的分支,研究机器模拟或实现人类的学习行为,以获取新的知识技能,并改善自身性能
- 垃圾邮件过滤
- 深度学习
- 一种机器学习方法,模拟人脑机制解释数据,通过组合低层特征形成更抽象的高层属性类别或特征
- 谷歌视频寻猫
- 人工智能
- 深度学习必备基础
- Python
- 公开论文 / 代码都是python为主流
- 开源框架基本都是python接口
- 线性代数、微积分
- 矩阵计算和梯度求导运算
- Python
- 主流深度学习框架
- TensorFlow
- Caffe
- Keras
- CNTK
- MXNet
- Torch7
- Theano
- Deeplearning4J
- Leaf
- Lasagne
- Neon
- 深度学习的应用
- 人脸识别
- 通用物体检测
- 图像分割
- 光学字符识别 - OCR
- 语音识别
- 机器翻译
- 情感识别
机器学习实例
KNN分类算法的分类预测过程
对于一个需要预测的输入向量x,只需要在训练数据集中寻找k个与向量x最近的向量的集合,然后把x的类标预测为这k个样本中类标数最多的那一类。
- 机器学习的主要步骤
- 准备数据集(量要大,模型才够精确。数据要全面,模型才全面)
- 数据清洗,数据预处理(噪声,缺失值,乱码,特征的提取,分为训练集和测试集)
- 选择一个模型(算法)
- 训练(训练集训练模型)
- 模型(分类,预测)- 测试集(验证集)
- 评估
- 模型的优化
- 调参,e.g. KNN(k)
- 换模型
- 迭代4-6
- 基于KNN的手写体数字识别
# coding: utf-8 # In[1]: from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn import datasets # In[2]: """
手写体数字,监督学习
1、样本集:一批手写体数字的图片,带标签(0-9),10类
样本数据量为1797,存在sklearn的datasets里。
每一个数据样本都是由image, target两部分组成。
image是一个尺寸为8*8的图像(手写的数字0-9),
target是图像的类别(数字0-9)。
2、划分训练集和测试集
3、选一个算法,构建模型,KNN
4、训练模型
5、预测、验证
6、模型优化(SVM, 决策树)
7、保存模型(.model, load, predict)
8、新建多张手写体图片,让模型来识别新的图片
"""
sample_data = datasets.load_digits()
images = sample_data.data
labels = sample_data.target # In[3]: #划分训练集和测试集
train_data, test_data, train_labels, test_labels = train_test_split(images, labels, test_size=0.1) # In[4]: #选择模型
model_knn = KNeighborsClassifier(n_neighbors=4, algorithm='auto', weights='distance') # In[5]: #训练模型
model_knn.fit(train_data, train_labels)
#KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
# metric_params=None, n_jobs=1, n_neighbors=4, p=2,
# weights='distance') # In[6]: #预测、验证
pred = model_knn.predict(test_data)
print("pred : \n", pred)
print("test_labels : \n", test_labels)
#pred :
# [3 4 1 4 4 0 0 8 2 9 8 9 6 1 3 3 7 8 5 1 3 2 1 2 7 4 8 5 7 1 0 2 4 0 7 3 1
# 5 3 4 6 2 5 1 6 3 4 5 4 9 3 6 5 0 0 4 5 2 0 7 7 6 5 1 2 9 9 2 7 6 3 2 3 8
# 6 7 6 4 0 2 2 8 8 8 5 0 2 0 4 2 2 0 6 6 6 0 9 8 9 5 3 8 5 7 9 6 3 0 3 9 5
# 1 0 9 6 7 0 1 5 3 0 3 4 9 2 3 8 2 2 5 7 2 6 2 7 3 1 4 5 9 9 6 6 9 7 1 3 7
# 1 9 8 6 9 9 6 5 0 5 6 9 7 7 5 0 3 8 5 9 2 0 9 3 1 2 9 3 7 6 9 6]
#test_labels :
# [3 4 1 4 4 0 0 8 2 9 8 9 6 1 3 3 7 8 5 1 3 2 1 2 7 4 8 5 7 1 0 2 4 0 7 3 1
# 5 3 4 6 2 5 1 6 3 4 5 4 9 3 6 5 0 0 4 5 2 0 7 7 6 5 1 2 9 9 2 7 6 3 2 3 8
# 6 7 6 4 0 2 2 8 8 8 5 0 2 0 4 2 2 0 6 6 6 0 9 8 7 5 3 8 5 7 9 6 3 0 3 9 5
# 1 0 9 6 7 0 1 5 3 0 3 4 9 2 3 8 2 2 5 7 2 6 2 7 3 1 4 5 9 9 6 6 9 7 1 3 7
# 1 9 8 6 9 9 6 5 0 5 6 9 7 7 5 0 3 8 5 9 2 0 9 3 1 2 9 3 7 6 9 6] # In[7]: #查看准确率
acc = accuracy_score(pred, test_labels)
print("Accuracy rate : %.3f" % acc)
#Accuracy rate : 0.994
基于CNN的手写体数字识别
- 手写体数字识别 - 机器学习的HelloWorld
- MNIST数据集
- MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
- http://yann.lecun.com/exdb/mnist/
- MNIST数据集
- Keras
- 纯python编写的基于theano/tensorflow的深度学习框架。一个高度模块化的神经网络库,支持GPU和CPU。
- 一致而简洁的API,极大减少一般应用下用户的工作量
- Keras搭建神经网络的过程
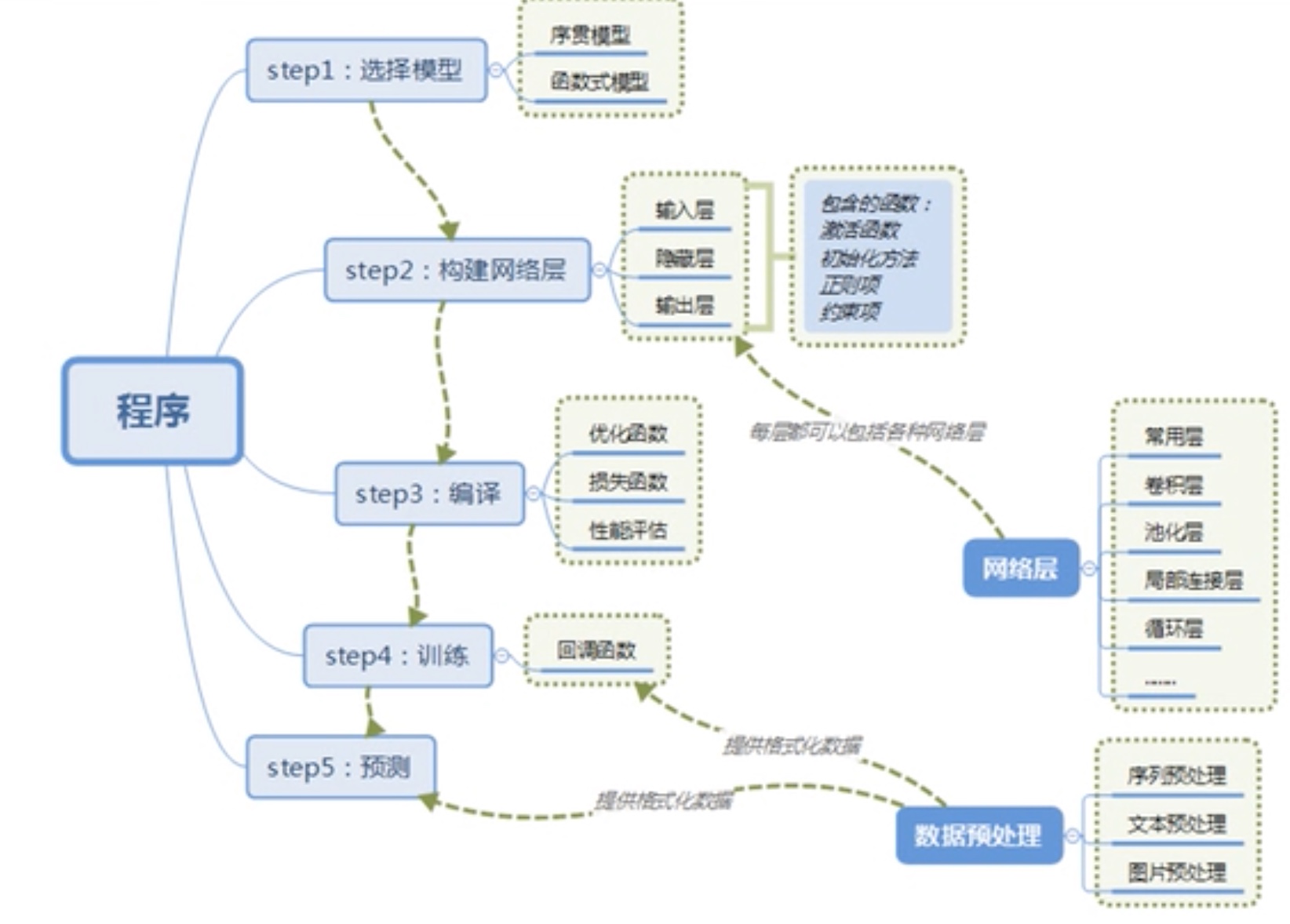
- CNN - 卷积神经网络
- CNN的建造灵感来自于人类对视觉信息的识别过程:点 -> 线 -> 面。
- 卷积层
- 卷是席卷,积为乘积。卷积实质上是用一个叫kernel的矩阵,从图像的小块上一一贴过去,每次和图像块的每一个像素乘积得到一个output值,扫过之后就得到一个新图像。
- 池化层
- 下采样(subsampling),分为最大值池化和平均值池化。
- 为什么池化
- 图像经过下采样尺寸缩小
- 增强了旋转不定性,池化操作可以看作是一种强制性的模糊策略
- 核的大小 / 步长
- CNN的过程

- 我们将输入图像传递到第一个卷积层,卷积后以激活图形式输出。图片在卷积层中过滤后的特征会被输出,并传递下去。
- 每个过滤器都会给出不同的特征,以帮助进行正确的类预测。
- 随后加入池化层进一步减少参数的数量。
- 在预测最终提出前,数据会经过多个卷积层和池化层的处理。卷积层会帮助提取特征,越深的卷积神经网络会提取越具体的特征,越浅的神经网络提取越浅显的特征。
- CNN中的输出层是全连接层,其中来自其他层的输入在这里被平化和发送,以便将输出转换为网络所需的参数。
- 随后输出层会产生输出,这些信息会互相比较排除错误。损失函数是全连接输出层计算的均方根损失。随后我们会计算梯度错误。
- 错误会进行反向传播,以不断改进过滤器(权重)和偏差值。
- 一个训练周期由单次正向和反向传递完成。
# coding: utf-8 # In[1]: """
基于CNN的手写体数字识别 迭代一轮 80s
"""
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K # In[2]: # 设置初始参数
batch_size = 128 # 一批喂给模型多少张图片 60000
num_classes = 10 # 分类 0 - 9
epochs = 12 # 迭代次数 img_rows, img_cols = 28, 28 # 28 * 28 # In[3]: # 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 加载数据集,第一次运行慢 # 判断backend theano, tensorflow
# 彩色图片 RGB 3 通道,灰度图 1 通道
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) # (60000, 1, 28, 28)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
intput_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1) # In[4]: # 数据处理 # image处理
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255 #x_train shape: (60000, 28, 28, 1)
#60000 train samples
#10000 test samples
print('x_train shape: ', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples') # labels处理
# 5 -> [0000010000] 2 -> [0010000000]
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes) # In[5]: # 1. 选择模型
model = Sequential() # 序贯模型 # In[6]: # 2. 构建网络层
# CNN的参数 权重(卷积核的构成),卷积核大小,数量,池化大小,步长,dropout rate
model.add(Conv2D(32,
kernel_size=(3, 3),
activation='relu',
input_shape=input_shape)) # 卷积层1 model.add(Conv2D(64,
(3, 3),
activation='relu')) # 卷积层2 model.add(MaxPooling2D(pool_size=(2, 2))) # 池化, 默认步长1 model.add(Dropout(0.25)) # 防止过拟合:训练集特征提取太细致,不适用于测试集 model.add(Flatten()) # 压平 model.add(Dense(128,
activation='relu')) # 全连接:所有神经元之间都是互相连接的 model.add(Dropout(0.5)) # 扔掉50% model.add(Dense(num_classes,
activation='softmax')) # 全连接,多分类 # In[7]: # 3. 编译
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']) # In[8]: # 4. 训练
model.fit(x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test)) # 开始训练 #Train on 60000 samples, validate on 10000 samples
#Epoch 1/12
#60000/60000 [==============================] - 79s 1ms/step - loss: 0.2630 - acc: 0.9195 - val_loss: 0.0574 - val_acc: 0.9825
#Epoch 2/12
#60000/60000 [==============================] - 77s 1ms/step - loss: 0.0900 - acc: 0.9730 - val_loss: 0.0437 - val_acc: 0.9855
#Epoch 3/12
#60000/60000 [==============================] - 78s 1ms/step - loss: 0.0663 - acc: 0.9810 - val_loss: 0.0387 - val_acc: 0.9874
#Epoch 4/12
#60000/60000 [==============================] - 76s 1ms/step - loss: 0.0555 - acc: 0.9836 - val_loss: 0.0321 - val_acc: 0.9881
#Epoch 5/12
#60000/60000 [==============================] - 76s 1ms/step - loss: 0.0462 - acc: 0.9862 - val_loss: 0.0287 - val_acc: 0.9907
#Epoch 6/12
#60000/60000 [==============================] - 81s 1ms/step - loss: 0.0418 - acc: 0.9873 - val_loss: 0.0318 - val_acc: 0.9893
#Epoch 7/12
#60000/60000 [==============================] - 81s 1ms/step - loss: 0.0364 - acc: 0.9885 - val_loss: 0.0291 - val_acc: 0.9907
#Epoch 8/12
#60000/60000 [==============================] - 80s 1ms/step - loss: 0.0338 - acc: 0.9898 - val_loss: 0.0260 - val_acc: 0.9922
#Epoch 9/12
#60000/60000 [==============================] - 80s 1ms/step - loss: 0.0319 - acc: 0.9903 - val_loss: 0.0266 - val_acc: 0.9918
#Epoch 10/12
#60000/60000 [==============================] - 79s 1ms/step - loss: 0.0290 - acc: 0.9908 - val_loss: 0.0271 - val_acc: 0.9919
#Epoch 11/12
#60000/60000 [==============================] - 79s 1ms/step - loss: 0.0281 - acc: 0.9911 - val_loss: 0.0247 - val_acc: 0.9928
#Epoch 12/12
#60000/60000 [==============================] - 82s 1ms/step - loss: 0.0256 - acc: 0.9920 - val_loss: 0.0251 - val_acc: 0.9926
#<keras.callbacks.History at 0x182f48b128> # In[9]: # 5. 预测
score = model.evaluate(x_test, y_test, verbose=0) # 在测试集上测试 #Test loss: 0.025120523367086936
#Test accuracy: 0.9926
print('Test loss: ', score[0])
print('Test accuracy: ', score[1]) # In[10]: model.save('.\model\HandwritingRecUsingCNN.model') # 保存模型
学习笔记之Python全栈开发/人工智能公开课_腾讯课堂的更多相关文章
- python学习之老男孩python全栈第九期_day015作业_老男孩Python全9期练习题(面试真题模拟)
一. 选择题(32分) 1. python不支持的数据类型有:AA. charB. intC. floatD. list 2. Ex = ‘foo’y = 2print(x + y)A. fooB. ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- 自学Python全栈开发第一次笔记
我已经跟着视频自学好几天Python全栈开发了,今天决定听老师的,开始写blog,听说大神都回来写blog来记录自己的成长. 我特别认真的跟着这个视频来学习,(他们开课前的保证书,我也写 ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
- python全栈开发学习_内容目录及链接
python全栈开发学习_day1_计算机五大组成部分及操作系统 python全栈开发学习_day2_语言种类及变量 python全栈开发_day3_数据类型,输入输出及运算符 python全栈开发_ ...
- 老男孩最新Python全栈开发视频教程(92天全)重点内容梳理笔记 看完就是全栈开发工程师
为什么要写这个系列博客呢? 说来讽刺,91年生人的我,同龄人大多有一份事业,或者有一个家庭了.而我,念了次985大学,年少轻狂,在大学期间迷信创业,觉得大学里的许多课程如同吃翔一样学了几乎一辈子都用不 ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
随机推荐
- Linux中查看显卡硬件信息
Linux中查看显卡硬件信息 https://ywnz.com/linuxjc/67.html lspci -vnn | grep VGA -A 12lshw -C display 查看当前使用的显卡 ...
- hdu3338 Kakuro Extension 最大流
If you solved problem like this, forget it.Because you need to use a completely different algorithm ...
- RPC简介及框架选择
简单介绍RPC协议及常见框架,对比传统restful api和RPC方式的优缺点.常见RPC框架,gRPC及序列化方式Protobuf等 HTTP协议 http协议是基于tcp协议的,tcp协议是流式 ...
- <--------------------------构造方法------------------------------>
1 构造方法 初始化阶段 给对象的属性进行赋值 构造方法 什么是构造方法 : 字面 方法构建时 就使用的方法 对象创建的时候就使用的方法 作用:对象的属性值初始化2 如何用构造方法 修饰符 构造方法名 ...
- oracle-sql模式匹配
下面是条件 like与regexp_like条件 下面是函数 regexp_instr regexp_replace regexp_substr select * from tis_ft_user_i ...
- oracle-sql分析练习
http://blog.chinaunix.net/uid-13552913-id-3028644.html Oracle 修改字段顺序的两种方法 一 如果要修改字段顺序,一般情况可以使用以下步骤: ...
- Web-Business-Application-Solution
项目地址 : https://github.com/kelin-xycs/Web-Business-Application-Solution Web-Business-Application-Sol ...
- kafka 学习资料
kafka 学习资料 kafka 学习资料 网址 kafka 中文教程 http://orchome.com/kafka/index
- taro refs引用
创建 Refs Taro 支持使用字符串和函数两种方式创建 Ref: 使用字符串创建 ref 通过函数创建 ref(推荐) 你也可以通过传递一个函数创建 ref, 在函数中被引用的组件会作为函数的第一 ...
- ubuntu忘记登录密码解决方法
1.重启系统,长按Shift键,直到出现下面菜单.选择recovery mode(恢复模式).2.接下来会进入如下界面,选择Drop to root shell prompt ,也就是获取root权限 ...