HTML解析库Gumbo简单使用记录
Gumbo简介
Gumbo是谷歌开源的一个纯C编写的HTML解析库,性能很好,就是用起来比较麻烦。
github地址https://github.com/google/gumbo-parser
还有一个C++封装的版本https://github.com/lazytiger/gumbo-query.git
关于HTML的参考,可见https://developer.mozilla.org/zh-CN/docs/Web/HTML
最近准备写一个爬虫,用于爬取epsg.io上的数据,所以找了这个库用于HTML的解析。其实我这个简单的爬取固定位置的内容,用这个实在是有点杀鸡用牛刀了,直接做字符串搜索会更方便。
使用记录
关于这个的使用,网上找不到太多的资料。
这里有一个https://blog.csdn.net/fjb2080/article/details/78992851
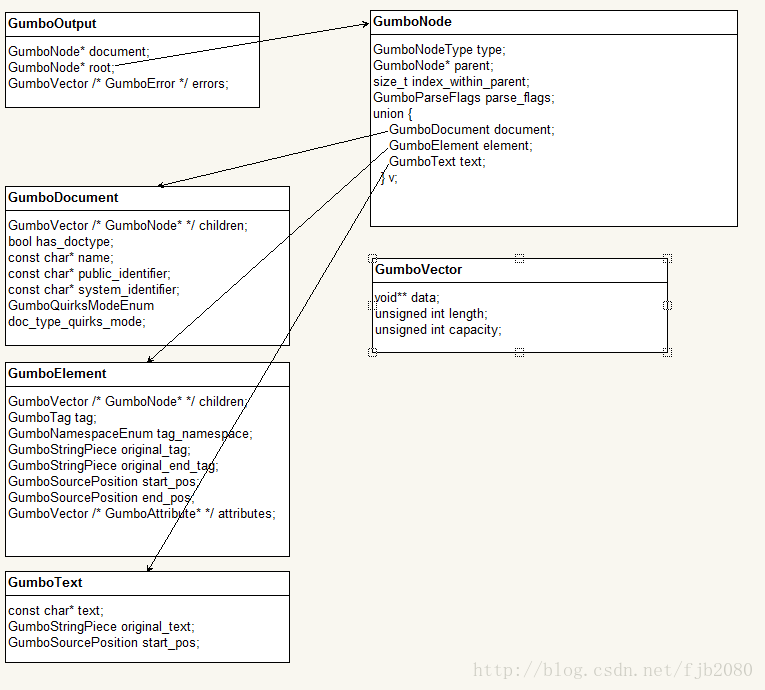
这个图片上实际已经把相关的关系描述清楚了,我这里只做简单的补充。
1、GumboNode的类型
对于一个GumboNode结构体对象,需要通过它的GumboNodeType type字段判断其类型后,可根据类型对成员v进行操作。
v是一个union对象,它可以是GumboDocument、GumboElement、GumboText三种类型之一。
1、GUMBO_NODE_DOCUMENT 文档节点
文档节点表示的是一个完整的html文档,就是从<html>到</html>之间的全部信息。对于v可取GumboDocument类型的成员document。
对于文档节点,其内部包含的元素节点都在GumboVector children中。
2、GUMBO_NODE_ELEMENT 元素节点
只要是含有标签tag的部分,都是元素节点。这个可以简单的理解为,只要是<标签名>到</标签名>之间的就是一个元素节点的内容(有的元素是单标签的),元素节点可以有包含嵌套关系,子节点都在GumboVector children中。
/**
* 用于表示所有HTML元素的结构。 它包含有关标记,属性和子节点的信息。
*/
typedef struct {
/**
* GumboNodes数组,包含此元素的子元素。 保存的是GumboNode的指针。
*/
GumboVector /* GumboNode* */ children;
/** 这个元素的GumboTag(标签,HTML的标签是定义好的)枚举值 */
GumboTag tag;
/** 此元素的GumboNamespaceEnum值(表示这个是HTML、SVG还是MATHML)*/
GumboNamespaceEnum tag_namespace;
/**
* 指向此元素的原始标记文本的GumboStringPiece,直接指向源缓冲区。
* 如果标记是通过算法插入的(例如,<head>或<tbody>插入),则这将是一个零长度字符串。
*/
GumboStringPiece original_tag;
/**
* 指向此元素的原始结束标记文本的GumboStringPiece。
* 如果以算法方式插入结束标记(例如,关闭自闭标记),则这将是一个零长度字符串。
*/
GumboStringPiece original_end_tag;
/** 记录元素开始标签在来源字符串中的起始位置。 */
GumboSourcePosition start_pos;
/** 记录元素结束标签在来源字符串中的起始位置。 */
GumboSourcePosition end_pos;
/**
* GumboAttributes数组,按照解析顺序包含此元素标签的属性
* 数组保存的是GumboAttribute的指针
*/
GumboVector /* GumboAttribute* */ attributes;
} GumboElement;
3、GUMBO_NODE_TEXT 文本节点
文本节点,对于v可取GumboText类型的成员text。
Gumbo在解析的时候,对于\r\n这种都会解析为一个独立的文件节点。
4、GUMBO_NODE_CDATA
CDATA节点是一个比较特殊的节点,这个节点用于传输需要浏览器不做解析,原封不动的当做文本的内容。所以对于v也是取GumboText类型的成员text。
5、GUMBO_NODE_COMMENT
注释节点,这个用于保存html中的注释,对于这个节点,对于v也是取GumboText类型的成员text。取出来的GumboText对象中的text成员不包含注释分隔符。
6、GUMBO_NODE_WHITESPACE
这是一个文本节点的特例,文本的内容都是空白字符(空格、TAB、回车)。v也是取GumboText。
7、GUMBO_NODE_TEMPLATE
模板节点。就是标签<template>包含的部分。
这与GUMBO_NODE_ELEMENT是分开的,因为许多客户端库都希望忽略模板节点的内容,如规范所示。 在GUMBO_NODE_ELEMENT上递归会在这里做正确的事情,而想要包含模板内容的客户端也应该检查GUMBO_NODE_TEMPLATE。 v将是一个GumboElement。
2、简单的使用
为了方便使用,我简单的封装了两个函数,对于我的使用已经足够了。如果需要更方便的使用,可以考虑https://github.com/lazytiger/gumbo-query.git
1、用于方便一点的查找子节点的
std::vector<GumboNode*> find_sub_node(const GumboNode* parentNode,
GumboNodeType type, GumboTag tag, int attrCount, ...)
{
std::vector<GumboNode*> subNode;
const GumboVector* vec = &(parentNode->v.element.children);
for (int i = 0; i < vec->length; ++i) {
GumboNode* node = (GumboNode*)vec->data[i];
if (node->type != type || (type == GUMBO_NODE_ELEMENT && node->v.element.tag != tag)) {
continue;
}
int pattend = 0;
va_list vl;
va_start(vl, attrCount);
for (int ai = 0; ai < attrCount; ++ai) {
const char* name = va_arg(vl, char*);
const char* value = va_arg(vl, char*);
GumboAttribute* attr = gumbo_get_attribute(&(node->v.element.attributes), name);
if (attr == NULL || strcmp(value, attr->value) != 0) { continue; }
pattend += 1;
}
va_end(vl);
if (pattend == attrCount) {
subNode.push_back(node);
}
}
return subNode;
}
2、用于方便的查找文本子节点的
std::vector<std::string> find_sub_text(const GumboNode* parentNode)
{
std::vector<std::string> subText;
const GumboVector* vec = &(parentNode->v.element.children);
for (int i = 0; i < vec->length; ++i) {
GumboNode* node = (GumboNode*)vec->data[i];
if (GUMBO_NODE_TEXT == node->type) {
subText.push_back(node->v.text.text);
continue;
}
}
return subText;
}
HTML解析库Gumbo简单使用记录的更多相关文章
- 企业库连接形式简单例子记录 EnterpriseLibrary.Data
结构图 webconfig 配置正确的连接字符串 <connectionStrings> <add name="DBConnection" connectionS ...
- python3解析库BeautifulSoup4
Beautiful Soup是python的一个HTML或XML的解析库,我们可以用它来方便的从网页中提取数据,它拥有强大的API和多样的解析方式. Beautiful Soup的三个特点: Beau ...
- 数据的查找和提取[2]——xpath解析库的使用
xpath解析库的使用 在上一节,我们介绍了正则表达式的使用,但是当我们提取数据的限制条件增多的时候,正则表达式会变的十分的复杂,出一丁点错就提取不出来东西了.但python已经为我们提供了许多用于解 ...
- Pugixml一种快速解析XML文件的开源解析库
Pugixml是一个轻量级的C++ XML开源解析库,DOM形式的解析器.接口和丰富的遍历和修改操作,快速的解析,此外支持XPath1.0实现数据查询,支持unicode编码: 使用Pugixml可通 ...
- Tomjson - 一个"短小精悍"的 json 解析库
Tomjson,一个"短小精悍"的 json 解析库,tomjson使用Java语言编写,主要作用是把Java对象(JavaBean)序列化为json格式字符串,将json格式字符 ...
- ACEXML解析XML文件——简单示例程序
掌握了ACMXML库解析XML文件的方法后,下面来实现一个比较完整的程序. 定义基本结构 xml文件格式如下 <?xml version="1.0"?> <roo ...
- 如果简单的记录,就可以为这个世界创造更多的财富,那么还有什么理由不去写博客呢? — 读<<黑客与画家>> 有感
上一次博文发文时间是2016.1.15,7个月已经过去了.最近读了一本<>的书,对我触动挺大的!里面有关于技术趋势的探讨,也有关于人生和财富的思考! 开始更新iOS122的文章的初衷是,聚 ...
- go的markdown解析库和session库
最近学习go,就决定做一个博客来练练手,一下是用到的一些不错的库 markdown解析库 使用markdown来写博客文章,我用的是"github.com/russross/blackfri ...
- 【转】编译quickfast解析库(沪深level2行情转码库)
转自http://blog.csdn.net/hacode/article/details/7065889 编译quickfast解析库(沪深level2行情转码库) 目录(?)[-] 1 下载源代 ...
随机推荐
- Docker+Jenkins持续集成环境(1)使用Docker搭建Jenkins+Docker持续集成环境
本文介绍如何通过Jenkins的docker镜像从零开始构建一个基于docker镜像的持续集成环境,包含自动化构建.发布到仓库\并部署上线. 0. 前置条件 服务器安装docker,并启动docker ...
- Codeforces Round #395 (Div. 2)
今天自己模拟了一套题,只写出两道来,第三道时间到了过了几分钟才写出来,啊,太菜了. A. Taymyr is calling you 水题,问你在z范围内 两个序列 n,2*n,3*n...... ...
- 洛谷2973 [USACO10HOL]赶小猪Driving Out the Piggi… 概率 高斯消元
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - 洛谷2973 题意概括 有N个城市,M条双向道路组成的地图,城市标号为1到N.“西瓜炸弹”放在1号城市,保证城 ...
- SQL Server 限定删除一行
with t as ( )* from testtest where aa='aa' order by bb ) delete from t
- iOS 11开发教程(十九)iOS11应用视图美化按钮之设置按钮的外观
iOS 11开发教程(十九)iOS11应用视图美化按钮之设置按钮的外观 美化按钮说白了就是对按钮的属性进行设置,设置按钮的属性有两种方法:一种是使用编辑界面中的属性检查器:另一种是使用代码进行设置.以 ...
- 前端必备HTTP技能之HTTP请求头响应头中常用字段详解(转)
作为一名前端开发人员,肯定少不了要和网络打交道,因为要从服务器端拉取数据,从服务端获取数据最常用的方式还是通过HTTP请求.给服务器发请求的时候有请求头,接受服务器响应的时候有响应头,客户端和服务器端 ...
- gbdt xgboost 贼难理解!
https://www.zybuluo.com/yxd/note/611571 https://zhuanlan.zhihu.com/p/29765582 gbdt 在看统计学习方法的时候 理解很吃力 ...
- Web前端性能优化进阶——完结篇
前言 在之前的文章 如何优化网站性能,提高页面加载速度 中,我们简单介绍了网站性能优化的重要性以及几种网站性能优化的方法(没有看过的可以狂戳 链接 移步过去看一下),那么今天我们深入讨论如何进一步优化 ...
- IT常用英文术语解释发音
associations 联系; 协会( association的名词复数 ); 联合; (思想.感觉.记忆等的) 联想; 按色赛诶神 == desktop ˈdesktɒp 的思克头铺 英[ˈde ...
- bzoj1722: [Usaco2006 Mar] Milk Team Select 产奶比赛 树形dp
题目链接 bzoj1722: [Usaco2006 Mar] Milk Team Select 产奶比赛 题解 dp[i][j][0 / 1] 以i为根的子数中 相邻点对选了j个的最大价值 代码 #i ...