SQLSVR 之 EXISTS
来个实例看看
CREATE TABLE #temp(
id BIGINT,
name VARCHAR(max),
age INT
) CREATE TABLE #tempmain(
id BIGINT,
name VARCHAR(max)
) INSERT #temp VALUES(1,'a',1)
INSERT #temp VALUES(2,'b',10)
INSERT #temp VALUES(3,'c',10)
INSERT #temp VALUES(4,'d',10)
INSERT #temp VALUES(5,'e',10)
INSERT #tempmain VALUES(1,'a')
INSERT #tempmain VALUES(2,'b')
INSERT #tempmain VALUES(3,'c')
INSERT #tempmain VALUES(4,'d')
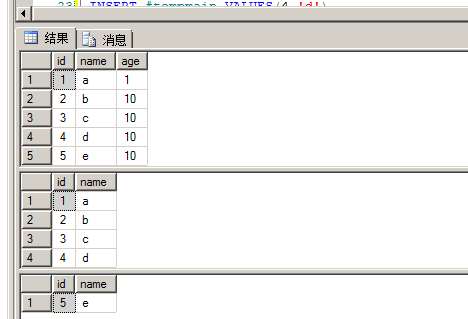
新建两张表并插入数据
现在我想查出来 #temp中有而#tempmain没有的数据
该数据应该是
5,'e',10
SELECT id,name FROM #temp a
WHERE NOT EXISTS (
SELECT id, name FROM #tempmain b
WHERE a.id=b.id
)
同样你也可以使用 not in
但是not in的效率实在太低,因为全表扫描速度相当之慢
关于全表扫描:
原文:http://itindex.net/detail/50380-sql-%E4%BC%98%E5%8C%96?utm_source=tuicool&utm_medium=referral
对查询进行优化,应尽量避免全表扫描,首先应考虑在where 及order by 涉及的列上建立索引:
.尝试下面的技巧以避免优化器错选了表扫描:
· 使用ANALYZE TABLE tbl_name为扫描的表更新关键字分布。
· 对扫描的表使用FORCE INDEX告知MySQL,相对于使用给定的索引表扫描将非常耗时。
SELECT * FROM t1, t2 FORCE INDEX (index_for_column)
WHERE t1.col_name=t2.col_name;
· 用--max-seeks-for-key=1000选项启动mysqld或使用SET max_seeks_for_key=1000告知优化器假设关键字扫描不会超过1,000次关键字搜索。
1. 应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,
如:
select id from t where num is null
NULL对于大多数数据库都需要特殊处理,MySQL也不例外,它需要更多的代码,更多的检查和特殊的索引逻辑,有些开发人员完全没有意识到,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默 认值。
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列 就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。 任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
此例可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
2. 应尽量避免在where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。 可以在LIKE操作中使用索引的情形是指另一个操作数不是以通配符(%或者_)开头的情形。例如,“SELECT id FROM t WHERE col LIKE 'Mich%';”这个查询将使用索引,但“SELECT id FROM t WHERE col LIKE '%ike';”这个查询不会使用索引。
3. 应尽量避免在where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,
如:
select id from t where num=10 or num=20
可以这样查询:select id from t where num=10 union all select id from t where num=20
4 .in 和not in 也要慎用,否则会导致全表扫描,
如:
select id from t where num in(1,2,3)
对于连续的数值,能用between 就不要用in 了:
select id from t where num between 1 and 3
5.下面的查询也将导致全表扫描:
select id from t where name like '%abc%' 或者
select id from t where name like '%abc' 或者
若要提高效率,可以考虑全文检索。
而select id from t where name like 'abc%' 才用到索引
7. 如果在where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推 迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:select id from t with(index(索引名)) where num=@num
8.应尽量避免在where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9. 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
如:
select id from t where substring(name,1,3)='abc'--name
select id from t where datediff(day,createdate,'2005-11-30')=0--‘2005-11-30’生成的id 应改为:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
10.不要在where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,
如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:create table #t(...)
13.很多时候用exists 代替in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15.索引并不是越多越好,索引固然可以提高相应的select 的效率,但同时也降低了insert 及update 的效率,因为insert 或update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
16.应尽可能的避免更新clustered 索引数据列,因为clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新clustered 索引数据列,那么需要考虑是否应将该索引建为clustered 索引。
17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18.尽可能的使用varchar/nvarchar 代替char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要使用select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。21.避免频繁创建和删除临时表,以减少系统表资源的消耗。
22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用select into 代替create table,避免造成大量log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先truncate table ,然后drop table ,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置SET NOCOUNT ON ,在结束时设置SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送DONE_IN_PROC 消息。
29.尽量避免大事务操作,提高系统并发能力。
30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
SQLSVR 之 EXISTS的更多相关文章
- SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)
前言 本节我们开始讲讲这一系列性能比较的终极篇IN VS EXISTS VS JOIN的性能分析,前面系列有人一直在说场景不够,这里我们结合查询索引列.非索引列.查询小表.查询大表来综合分析,简短的内 ...
- SQL Server-聚焦NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL性能分析(十八)
前言 本节我们来综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL的性能,简短的内容,深入的理解,Always to review the basics. ...
- 如何区别exists与not exists?
1.exists:sql返回结果集为真:not exists:sql不返回结果集为真.详解过程如图: exists not exists
- LINQ to SQL语句(7)之Exists/In/Any/All/Contains
适用场景:用于判断集合中元素,进一步缩小范围. Any 说明:用于判断集合中是否有元素满足某一条件:不延迟.(若条件为空,则集合只要不为空就返回True,否则为False).有2种形式,分别为简单形式 ...
- NOT IN 和NOT EXISTS
今天写了一个简单的NOT IN语句,结果跟预期大相径庭,百度之发现深坑一个,遂录之. 登陆账户表logins code name status a admin N b guest N c member ...
- windows 部署 git 服务器报 Please make sure you have the correct access rights and the repository exists.错误
这两天在阿里云上弄windows 服务器,顺便部署了一个git服务.根据网上教程一步步操作下来,最后在 remote远程仓库的时候提示 fatal: 'yourpath/test.git' does ...
- MySql中in和exists效率
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询.一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的 ...
- SQL Server-聚焦LEFT JOIN...IS NULL AND NOT EXISTS性能分析(十七)
前言 本节我们来分析LEFT JOIN和NOT EXISTS,简短的内容,深入的理解,Always to review the basics. LEFT JOIN...IS NULL和NOT EXIS ...
- SQL Server-聚焦EXISTS AND IN性能分析(十六)
前言 前面我们学习了NOT EXISTS和NOT IN的比较,当然少不了EXISTS和IN的比较,所以本节我们来学习EXISTS和IN的比较,简短的内容,深入的理解,Always to review ...
随机推荐
- kubeadm安装kubernetes V1.11.1 集群
之前测试了离线环境下使用二进制方法安装配置Kubernetes集群的方法,安装的过程中听说 kubeadm 安装配置集群更加方便,因此试着折腾了一下.安装过程中,也有一些坑,相对来说操作上要比二进制方 ...
- Android Studio中Run按钮是灰色的问题解决
打开一个Android Studio工程,发现Run按钮是灰色的 看了网上的一些解决方法,都是说要配置Configuration :比如链接:http://blog.csdn.net/purple ...
- centos7下安装gcc7
之前写过在linux下升级gcc 4.8至gcc 4.9的过程,现在gcc最新的版本是8,有些软件必须是gcc 7或者以上的版本才可以编译,比如clickhouse,gcc 7的安装过程和之前基本上一 ...
- 树莓派3中没有/dev/video0的解决方法(使用OpenCV编程调用树莓派摄像头的方法)
一.问题 使用下列方法调用OpenCV编程调用树莓派摄像头时总是失败,提示调用Grabber的start()时失败. import org.bytedeco.javacpp.opencv_core; ...
- EntityFramework CodeFirst反向工程工具
EntityFramework Reverse POCO Generator https://marketplace.visualstudio.com/items?itemName=SimonHugh ...
- Linux编译步骤概述
Linux,一切皆文件! linux环境下,编译源码文件步骤总结 01.下载解压 一遍在开源网站有download/下载页面 02.安装基本编译环境 yum install -y gcc gcc-c+ ...
- linux达人养成计划学习笔记(七)—— 用户登录查看命令
一.查看用户登录信息 1.命令格式 w 2.命令结果 第一行信息是:系统当前时间 系统运行总时间 登录用户数量 一分钟/五分钟/十分钟的系统负载(越大越差) 二.who命令 1 ...
- 在SharePoint 2013 场中移除服务器,提示 cacheHostInfo is null 错误
Problem 在SharePoint 2013 场中移除服务器,提示 cacheHostInfo is null 错误 Resolution 这是由于SharePoint 2013中分布式缓存实例( ...
- jQuery Address全站 AJAX 完整案例详解
本文详细介绍如何利用 jQuery 框架以及 jQuery Address 插件实现最基本的全站 AJAX 动态加载页面内容的功能的方法. 案例目标 以常见基本结构的网站为案例,实现全站链接 AJAX ...
- intellij idea (Android studio )外部程序 打开某扩展名(格式)
最近在为项目开发写思维导图, 为了留下思考的过程和业务逻辑. 本人使用的工具是很可怜的freemind,所以“脑图”的扩展名是“.mm” 情景: 在intellij idea (Android stu ...