关于svm
svm的研究一下,越研究越发现深入。下面谈一些我个人一些拙见。
svm计算基础是逻辑回归(logistic regression),其实一切二元分类的鼻祖我觉得都是logistic regress。

公式如下:

那么当我们谋求一个超平面(在二维里面超"线")y = w.T * x + b来实现分类,其实就是g(w.T *x + b),注意这里有点反人类,在前者y是因变量,但是在g(z)中,y变成了自变量,是一个层级关系;后者意义就是我作为一个函数,函数的意义满足某个计算规则的点,扔到里面去,可以用于做分类;从下图可以看到,下面的三条线(超平面),都符合函数w.T + b的模式,但是扔到g(z)里面的结果预期是不一样,相当于将g(1)和g(-1),g(0)(注意这里的-1和1都是极值,为了保证最大间隔的极值,其实y是连续的,可以取任意实数);那么就是可以实现基于sigmoid函数的分类。当然g的取值也是二元的-1,和+1。

那么下面就是重点讨论w.T*x + b这个超平面。在讨论这个公式之前,我们首先确定一下概念,有了上图之后,可以简单的解释一下这个问题,所谓的支持向量机,就是实现查找到实现可分间隔最大化的边缘平面的算法;那么支持向量就是分布在变换平面上面的点,之所以称之为支持向量就是因为他么支撑了边缘平面,那么支持向量后面的那些点都不需要关心了,他们的位置对于分类没有任何帮助,所以就属于非支撑(骨干)的点。到此简单讲解了一下支持向量机的概念。
那么如何来搞掂这个最大化边缘平面呢?我在刚开始接触的时候其实并不是特别理解最大化间距,但是看到上图之后,其实你会发现如果不断的旋转移动这三条线,你会发现为了实现分类,三条线的相对位置其实是在不断变化的,svm的算法的目的就是实现让分类边缘线1)平行,2)间隔最大;那么为什么要最大呢?这样分类倾向性会更加明显一些,一些个似是而非的点可能性将会非常小;极端情况,在逻辑回归的场景下,就是一条线,如果点在这条线上面了,你说怎么分?所以svm通过"宽带"这种分割模式,在很大程度上加强的分类的倾向性。
关于最大化边缘平面距离就是最大化间隔问题,那么间隔,就要提到两种间隔,分别是函数间隔和几何间隔,函数间隔:

点x到超平面的间隔,或者说距离就是w.T *x + b,但是因为分类,所以距离有正负,为了获知分类正确性,前面乘以y,y就是分类,只有-1和1两个值,之所以这样处理,如果分类正确,说明y和f(x)的符号一致,距离必然正值,反之负值,所以通过符号就可以判断来准确性。我们让边缘平面的y值取-1和1,所以在边缘超平面的点一定是=1或者=-1,那么y的取值范围是大于1,小于-1的;通过函数间隔,其实我们目标是求出这些点到超平面的距离的最小值:

这样人为的定义的距离有一个问题,就是如果等比例放大w和b,将会导致距离也变化,但是我们知道等比例改变w和b将会导致距离变化(对应的y值也等比例增加),但是此时超平面并没有变化,但是距离却不再和之前相等;所以此时引入了几何距离:

下面的是推导过程,可以得出几何距离。

处于同样的理由,我们让y*r,这个就是最终的几何距离公式:

这样我们求解最大间隔问题,其实就是求:

约束条件(s.t)为

这样,我们其实设r^值为1,并不影响优化效果,来简化处理公式(为什么改成1可以?):

那么如何求解呢?
这里有一个非常美妙的变化,就是上面的公式可以变型为min函数:
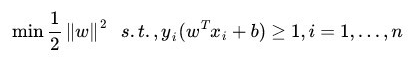
更加精妙的变形在于通过下式将约束和min函数包容起来了:
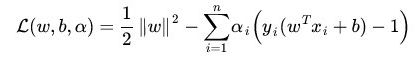
其实为什么可以把约束和主题函数放在一起?看下面的公式:

ai是大于0的,yi(w.T*xi+b)一定是>=1,因为为了实现L(w,b,a)的最大化,一定是||w||**2/2的后面部分一定是等于0,才能够实现最大化,所谓约束,拉格朗日对偶的公式里面已经成为了一种前置假设。这个是我之前的理解,但是这里其实牵涉到凸优化的问题,并不是简单的极值。比如下面的变形,其实使用的凸优化的知识:
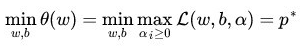
然后进行max和min位置交换:

这种等价交换是有条件的(正常情况下d*<=p*),这种转换使得计算变得简单,但是,为什么变得简单了,为什么先min后max就会简化运算?不懂。
数学最优化模型是下图所示,f(x)是要求最小化的函数,hj是等式约束,gk是不等式约束。

有了有了优化模型的描述,我们再来看看min-max等价交换的KKT条件:
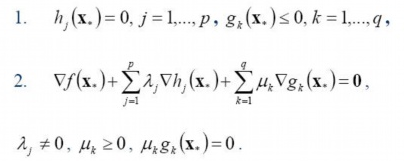
求对偶问题三个步骤:
1)对w和b求对偶:

带入到上面L(w,b,a)公式中,可得:

最后经过推到:
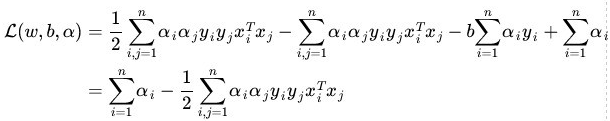
这里注意,早期全部都是i但是到了推倒的最后几步出现了i,j的分割:
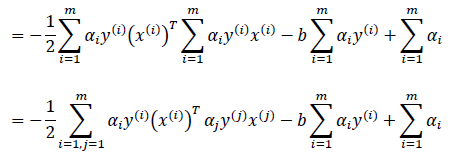
这里的其实是一个两层循环,外层循环是i,里层循环是j;这个两层循环的累加完成了矩阵间的乘法运算。
第二步,根据上一步推导出来的公式进行求a值;

有了a之后,根据偏导数求出的公式可以解出w,然后通过下面的公式可以求出b,从公式上面来看应该是f(x)的最大值和最小值的均值,但是为什么是这个求b值呢?
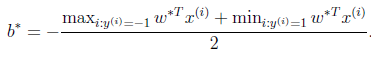
第三步,即最后一步,通过SMO算法求解a;但是到这里我懵逼了,在第二步的时候,不是已经把a值给求出来了吗,怎么又求了一遍?
核函数
其实数据大多数场景都是线性不可分的,就是无法采用一条直线进行分类,需要曲线,曲线就是多项式,计算比较复杂,这个时候,如果是升维,那么很多时候可以简化问题,这个时候,核函数就出现了。
在讲核函数之前,我们先看一个前置知识:向量内积。
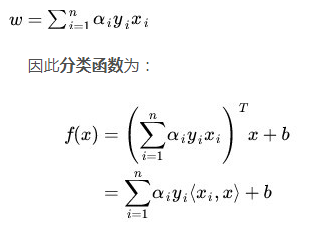
通过上面公式,可以很清晰的看到转置被处理成了内积,OK,核函数的本质其实就是把低维数据映射高维数据,怎么映射?
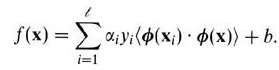
简单讲就是将原来x->φ(x),那么核函数的高明之处在于他的计算并不是在映射到高维之后,再计算,如果那样的话,求解可能会有"维度灾难"。比如:
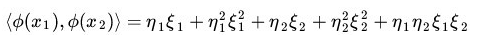
这是一个五维空间,计算量比较大了,但是核函数不是对于分解之后在计算,而是找到了一种等价的形式:

来对其进行计算,这样的话,你会发现计算简单很多。而且核函数的形式和咱么上面提到公式中内积的形式是一致的(注意,核函数可并不是为了svm的内积而生的,而是有气自己数学应用场景的)。所以,你可以指定一些核函数来进行提升维度处理,同时还避免了高维的海量特征的计算。
常用的核函数包括:
1. 多项式;上面举例(<x1,x2> + 1)**2就是一个多项式核函数的例子;
2. 高斯核函数,这个可能是应用最广泛的一种和函数了。
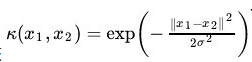
3. 线性核函数,这个主要就是用于兼容,当不需要提高维度,但是为了计算的统一性,采用这个核函数可以保证计算逻辑的一致性。
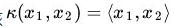
关于松弛变量
svm中对于离群点有专门的处理,所谓离群点是指下图中的蓝色部分。所谓离群点是指貌似对方,但是其实是自己人那些点,但是因为位置比较尴尬,所以svm设置了一个松弛变量,就是允许在一定范围内的离群点,这样可以这样讲,其实允许在"宽带"之间有一些点,这些点将会基于到宽带两边的距离来进行划分。避免宽带间点无法被处理。
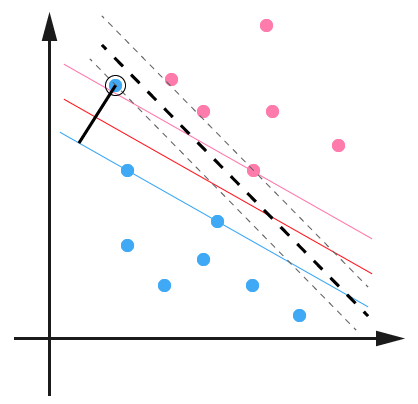
我们继续拿函数距离来做表达(为什么这里又采用了函数距离,而不是集合距离),此时距离赢不再是1,而是减去一个变量。

ξi不可以任意大的,于是添加了一个C作为限制

于是我们有了新的L(w,b,a):

后面处理的流程和上面很类似,首先是求导获取极值取值:
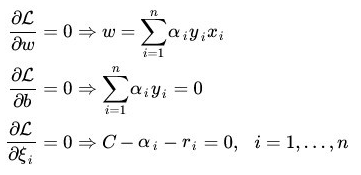
带入到拉格朗日的公式中,可以求得:
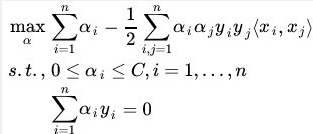
结果函数和之前是一样的,但是增加了一项约束:ai<=C(因为C-ai-ri=0,所以C必然大于等于ai)
最后是SMO算法,其实smo算法才是向量机的核心,他解决了如何求解a的关键,但是讲真,我看的资料并没有把smo算法讲明白。下一轮再研究吧。
参考
https://blog.csdn.net/v_JULY_v/article/details/7624837
关于svm的更多相关文章
- EasyPR--开发详解(6)SVM开发详解
在前面的几篇文章中,我们介绍了EasyPR中车牌定位模块的相关内容.本文开始分析车牌定位模块后续步骤的车牌判断模块.车牌判断模块是EasyPR中的基于机器学习模型的一个模块,这个模型就是作者前文中从机 ...
- 8.SVM用于多分类
从前面SVM学习中可以看出来,SVM是一种典型的两类分类器.而现实中要解决的问题,往往是多类的问题.如何由两类分类器得到多类分类器,就是一个值得研究的问题. 以文本分类为例,现成的方法有很多,其中一劳 ...
- 5.SVM核函数
核函数(Kernels) 定义 1.1 (核或正定核) 设是中的一个子集,称定义在上的函数是核函数,如果存在一个从到Hilbert空间的映射 使得对任意的,都成立.其中表示Hilbert空间中的内积. ...
- 4. SVM分类器求解(2)
最优间隔分类器(optimal margin classifier) 重新回到SVM的优化问题: 我们将约束条件改写为: 从KKT条件得知只有函数间隔是1(离超平面最近的点)的线性约束式前面的系数,也 ...
- 2. SVM线性分类器
在一个线性分类器中,可以看到SVM形成的思路,并接触很多SVM的核心概念.用一个二维空间里仅有两类样本的分类问题来举个小例子.如图所示 和是要区分的两个类别,在二维平面中它们的样本如上图所示.中间的直 ...
- 1. SVM简介
从这一部分开始,将陆续介绍SVM的相关知识,主要是整理以前学习的一些笔记内容,梳理思路,形成一套SVM的学习体系. 支持向量机(Support Vector Machine)是Cortes和Vapni ...
- SVM分类与回归
SVM(支撑向量机模型)是二(多)分类问题中经常使用的方法,思想比较简单,但是具体实现与求解细节对工程人员来说比较复杂,如需了解SVM的入门知识和中级进阶可点此下载.本文从应用的角度出发,使用Libs ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 卷积神经网络提取特征并用于SVM
模式识别课程的一次作业.其目标是对UCI的手写数字数据集进行识别,样本数量大约是1600个.图片大小为16x16.要求必须使用SVM作为二分类的分类器. 本文重点是如何使用卷积神经网络(CNN)来提取 ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- Python 基础day4
整体大纲关于占位符 tpl = "i am %s" % "alex" tpl = "i am %s age %d" % ("a ...
- Python 字符串操作方法大全
Python 字符串操作方法大全 1.去空格及特殊符号复制代码代码如下:s.strip().lstrip().rstrip(',') 2.复制字符串复制代码代码如下:#strcpy(sStr1,sSt ...
- FileInputStream类与FileOutputStream类
FileInputStream类是InputStream类的子类.他实现了文件的读取,是文件字节输入流.该类适用于比较简单的文件读取,其所有方法都是从InputStream类继承并重写的.创建文件字节 ...
- SQL注入之Sqli-labs系列第十七关(UPDATA– 基于错误– 单引号– 字符型)
开始挑战第十七关(Update Query- Error based - String) 首先介绍下update的用法: 作用:Update 语句用于修改表中的数据. 语法:UPDATE 表名称SET ...
- [转] Haproxy、Keepalived双主高可用负载均衡
http://blog.chinaunix.net/uid-25266990-id-3989321.html 在测试了Nginx+Keepalived的负载均衡后,也对Haproxy+Keepaliv ...
- e与复利
e≍2.718 计算一个复利例子,设本金p,年利率为r,每月计算一次利息,月利息为r/12,则一年的本息一共: p(1+r/12)12=pq 当计算复利的时间间隔越来越小,根据上面极限公式,本金所乘的 ...
- cetos7最小化安装设置网络启动和更新yum源
1. 使用静态 IP 地址配置网络 你第一件要做的事情就是为你的 CentOS 服务器配置静态 IP 地址.路由以及 DNS.我们会使用 ip 命令代替 ifconfig 命令.当然,ifconfig ...
- tumblr热度
- group_concat的使用以及乱码
1.group_concat子查询返回数字是乱码,既不是utf8也不是gbk,后来看了下子表的字段编码是gbk的,但sql整体返回的是utf8,group_concat前 把字段转换成utf8的,运行 ...
- Blender 精确建模3D打印注意事项
首先参照前面的<Blender的单位:一图弄懂Blender的单位>设置好自己环境的长度单位. 下面的注意事项,没有先后关系,遇到的就会补充. 1. 模型需要进行布尔计算前,在物件我是下, ...