大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword
Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图。
这里写一个简单的拓扑:
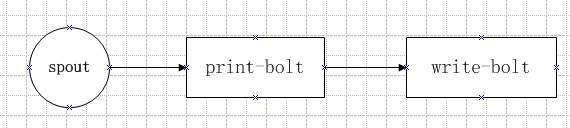
第一步:创建一个拓扑类
含有main方法的类型,作为程序入口:
package bhz.topology; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
import bhz.bolt.PrintBolt;
import bhz.bolt.WriteBolt;
import bhz.spout.PWSpout; public class PWTopology1 { public static void main(String[] args) throws Exception { //拓扑配置类Config
Config cfg = new Config();
//启动两个Worker进程
cfg.setNumWorkers(2);
cfg.setDebug(true); //TopologyBuilder 组装拓扑的类
TopologyBuilder builder = new TopologyBuilder();
//设置数据源
builder.setSpout("spout", new PWSpout());
//设置第一个处理bolt,并指定该bolt属于spout分组
builder.setBolt("print-bolt", new PrintBolt()).shuffleGrouping("spout");
//设置第二个bolt,并指定该bolt属于print-bolt分组
builder.setBolt("write-bolt", new WriteBolt()).shuffleGrouping("print-bolt");
//创建拓扑
StormTopology top1 = builder.createTopology(); //1 本地集群
LocalCluster cluster = new LocalCluster();
//拓扑的名字-top1
cluster.submitTopology("top1", cfg, top1);
Thread.sleep(10000);
//10s后关闭该拓扑
cluster.killTopology("top1");
//关闭本地集群
cluster.shutdown(); //2 集群模式提交拓扑 (与本地模式不能共用)
//StormSubmitter.submitTopology("top1", cfg, top1); }
}
第二步:创建数据源类
方式一:继承backtype.storm.topology.base.BaseRichSpout类
方式二:实现backtype.storm.topology.IRichSpout接口
package bhz.spout; import java.util.HashMap;
import java.util.Map;
import java.util.Random; import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values; public class PWSpout extends BaseRichSpout{ private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector; private static final Map<Integer, String> map = new HashMap<Integer, String>(); static {
map.put(0, "java");
map.put(1, "php");
map.put(2, "groovy");
map.put(3, "python");
map.put(4, "ruby");
} /**
* 重写初始化方法 open
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//对spout进行初始化
this.collector = collector;
//System.out.println(this.collector);
} /**
* 轮询tuple
* 一直不间断的从数据源取出数据
*/
@Override
public void nextTuple() {
//随机发送一个单词
final Random r = new Random();
int num = r.nextInt(5);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
//emit 发送数据
this.collector.emit(new Values(map.get(num)));
} /**
* declarer声明发送数据的field
* 下一个bolt会根据声明的field取值
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//进行声明
declarer.declare(new Fields("print"));
} }
第三步:创建数据处理类
方式一:继承backtype.storm.topology.base.BaseBasicBolt类
方式二:实现backtype.storm.topology.IRichBolt接口
package bhz.bolt; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory; import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class PrintBolt extends BaseBasicBolt { private static final Log log = LogFactory.getLog(PrintBolt.class); private static final long serialVersionUID = 1L; /**
* bolt处理类执行方法
* 在这里可以写具体业务逻辑,对数据进行怎样的处理...
* 如果后面还有bolt 需要再使用emit发送数据了
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
String print = input.getStringByField("print");
log.info("【print】: " + print);
//进行传递给下一个bolt
collector.emit(new Values(print)); } /**
* declarer声明发送数据的field
* 下一个bolt会根据声明的field取值
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("write"));
} }
package bhz.bolt; import java.io.FileWriter; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory; import clojure.main;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple; public class WriteBolt extends BaseBasicBolt { private static final long serialVersionUID = 1L; private static final Log log = LogFactory.getLog(WriteBolt.class); private FileWriter writer ; /**
* bolt处理类执行方法
* 在这里可以写具体业务逻辑,对数据进行怎样的处理...
* 如果后面没有bolt 就不需要再使用emit发送数据了
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
String text = input.getStringByField("write");
try {
if(writer == null){
if(System.getProperty("os.name").equals("Windows 10")){
writer = new FileWriter("D:\\stormtest\\" + this);
} else if(System.getProperty("os.name").equals("Windows 8.1")){
writer = new FileWriter("D:\\stormtest\\" + this);
} else if(System.getProperty("os.name").equals("Windows 7")){
writer = new FileWriter("D:\\stormtest\\" + this);
} else if(System.getProperty("os.name").equals("Linux")){
System.out.println("----:" + System.getProperty("os.name"));
writer = new FileWriter("/usr/local/temp/" + this);
}
}
log.info("【write】: 写入文件");
writer.write(text);
writer.write("\n");
writer.flush(); } catch (Exception e) {
e.printStackTrace();
}
} /**
* 如果后面没有bolt 就不需要再声明filed了 这里写一个空方法
*
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
第四步:写完代码,运行
两种运行方式:
本地运行:
//1 本地集群
LocalCluster cluster = new LocalCluster();
//拓扑的名字-top1
cluster.submitTopology("top1", cfg, top1);
Thread.sleep(10000);
//10s后关闭该拓扑
cluster.killTopology("top1");
//关闭本地集群
cluster.shutdown();
集群运行:
//2 集群模式提交拓扑 (与本地模式不能共用)
StormSubmitter.submitTopology("top1", cfg, top1);
来看一下 集群运行模式:
将以上代码打包成storm01.jar 上传到集群 Nimbus主节点上
运行命令:storm jar jar包名 拓扑类全路径名
[cluster@PCS101 tempjar]$ storm jar storm01.jar bhz.topology.PWTopology1
会打印一些东西 看最后两行:
[main] INFO backtype.storm.StormSubmitter - Submitting topology top1 in distributed mode with conf {"topology.workers":,"topology.debug":true}
[main] INFO backtype.storm.StormSubmitter - Finished submitting topology: top1
查看任务命令:storm list
[cluster@PCS101 tempjar]$ storm list
Topology_name Status Num_tasks Num_workers Uptime_secs
-------------------------------------------------------------------
top1 ACTIVE
supervisor节点,使用jps查看 多了worker进程
[cluster@PCS103 ~]$ jps
worker
QuorumPeerMain
Jps
supervisor
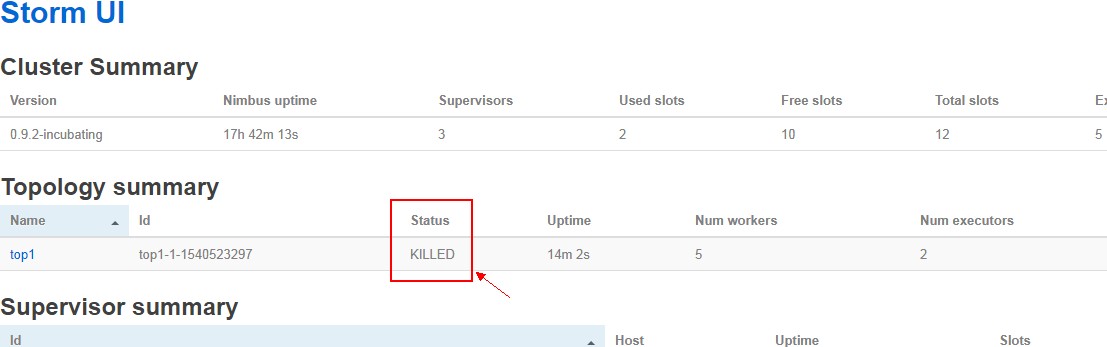
UI界面查看:
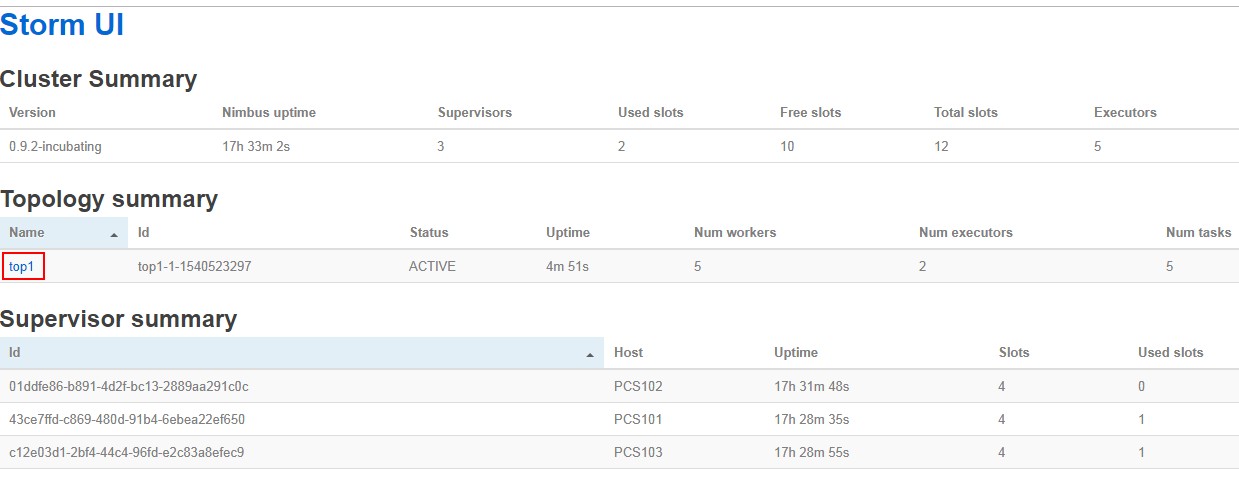
查看worker日志:
[cluster@PCS101 apache-storm-0.9.]$ cd logs
[cluster@PCS101 logs]$ ls
access.log logviewer.log metrics.log nimbus.log supervisor.log ui.log worker-.log
[cluster@PCS101 logs]$ tail -f worker-.log
-- :: b.s.d.task [INFO] Emitting: spout default [groovy]
-- :: b.s.d.task [INFO] Emitting: spout default [php]
-- :: b.s.d.task [INFO] Emitting: spout default [groovy]
-- :: b.s.d.task [INFO] Emitting: spout default [groovy]
-- :: b.s.d.task [INFO] Emitting: spout default [java]
-- :: b.s.d.task [INFO] Emitting: spout default [groovy]
关闭拓扑任务:
使用命令:storm kill top1
[cluster@PCS101 logs]$ storm kill top1
[main] INFO backtype.storm.command.kill-topology - Killed topology: top1
UI界面:点击kill
另外案例:wordCount

大数据处理框架之Strom: Storm----helloword的更多相关文章
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- 大数据处理框架之Strom:redis storm 整合
storm 引入redis ,主要是使用redis缓存库暂存storm的计算结果,然后redis供其他应用调用取出数据. 新建maven工程 pom.xml <project xmlns=&qu ...
- 大数据处理框架之Strom:kafka storm 整合
storm 使用kafka做数据源,还可以使用文件.redis.jdbc.hive.HDFS.hbase.netty做数据源. 新建一个maven 工程: pom.xml <project xm ...
- 大数据处理框架之Strom:DRPC
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 一.DRPC DRPC:Distri ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
- 大数据处理框架之Strom:事务
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
随机推荐
- python中的list以及list与array相互转换
python中的list是一种有序集合,可以随时增删元素: # -*- coding: utf-8 -*- frameID = 1 frameID_list = [] frameID_list.app ...
- C#-1-2-C#基础
1-注释符 1).单行注释符:// 2).多行注释符:/**/ 3).文档注释符:// 2-常用快捷键 3-变量类型 4-转义字符 5-语句 1.将相应内容打印到控制台:Console.WriteLi ...
- Http服务基础原理
http服务相关解释 http : Hyper Text Transfer Protocol, 80/tcp 超文本传输协议,基于tcp传输协议的80端口传输 html: Hyper Text M ...
- Linux命令实例功能笔记
ls命令 ls对文件mtime时间进行排序 降序: ls -lt | grep '^-' 升序: ls -ltr | grep '^-' seq命令 求1000以内所有偶数的和 ech ...
- 类属性"get"必须声明主体,因为它未标记为 abstract 或 extern[解决方法]
当在页面cs文件中,写类属性时,运行会碰到以下问题:CS0501: “ASP.default_aspx.Person.Level.get”必须声明主体,因为它未标记为 abstract 或 exter ...
- chkdsk 命令对Raid盘检测和查错、修复
C:\Documents and Settings\Administrator>chkdsk /?检查磁盘并显示状态报告. CHKDSK [volume[[path]filename]]] [/ ...
- PinyinUtil
import java.util.HashSet;import java.util.Set;import java.util.regex.Matcher;import java.util.regex. ...
- log4j。日志输出
log4j.rootLogger = debug , stdout , D , E log4j.appender.stdout = org.apache.log4j.ConsoleAppender l ...
- awesome vue
https://blog.csdn.net/caijunfen/article/details/78216868
- 构造器初始化(static)
package demo; /* * 在类 的内部,变量定义的先后顺序决定了初始化的顺序.即使变量定义散布于方法定义之间, * 它们仍旧会在任何方法(包括构造器)被调用之前得到初始化. */ publ ...