Hadoop概念学习系列之关于hadoop-2.2.0和hadoop2.6.0的winutils.exe、hadoop.dll版本混用(易出错)(四十三)
问题详情是
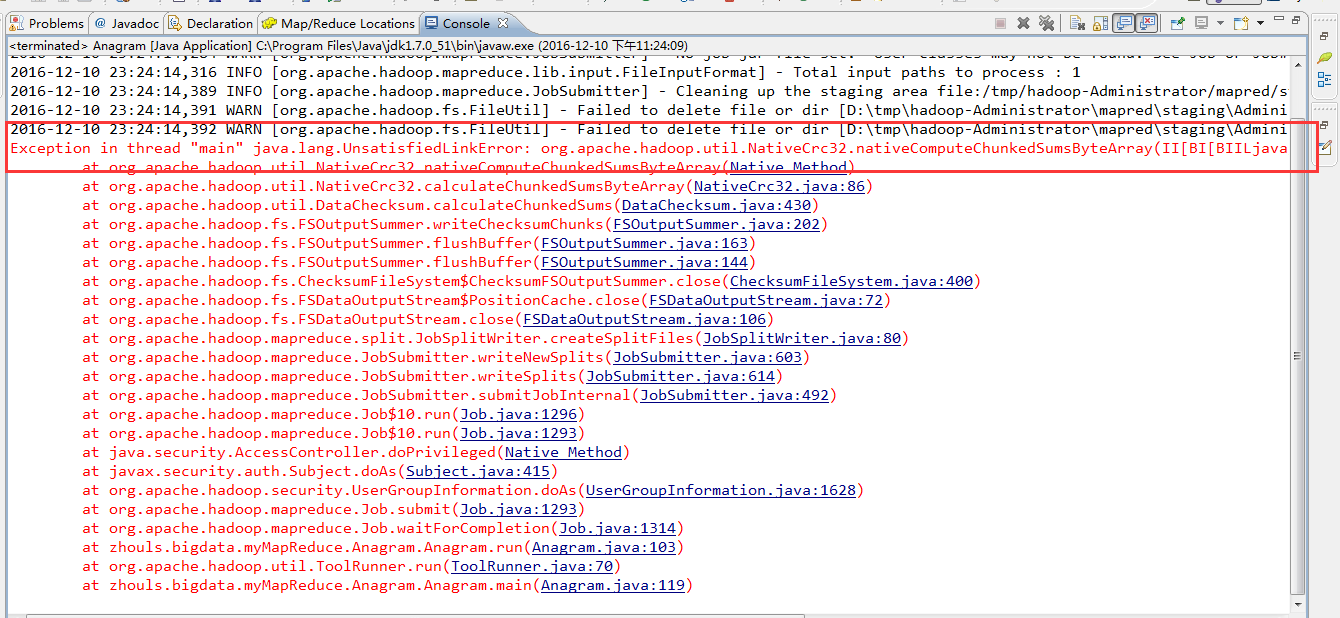
2016-12-10 23:24:13,317 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-10 23:24:14,281 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-10 23:24:14,284 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-10 23:24:14,316 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2016-12-10 23:24:14,389 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Cleaning up the staging area file:/tmp/hadoop-Administrator/mapred/staging/Administrator2004170506/.staging/job_local2004170506_0001
2016-12-10 23:24:14,391 WARN [org.apache.hadoop.fs.FileUtil] - Failed to delete file or dir [D:\tmp\hadoop-Administrator\mapred\staging\Administrator2004170506\.staging\job_local2004170506_0001\.job.split.crc]: it still exists.
2016-12-10 23:24:14,392 WARN [org.apache.hadoop.fs.FileUtil] - Failed to delete file or dir [D:\tmp\hadoop-Administrator\mapred\staging\Administrator2004170506\.staging\job_local2004170506_0001\job.split]: it still exists.
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
at org.apache.hadoop.util.NativeCrc32.calculateChunkedSumsByteArray(NativeCrc32.java:86)
at org.apache.hadoop.util.DataChecksum.calculateChunkedSums(DataChecksum.java:430)
at org.apache.hadoop.fs.FSOutputSummer.writeChecksumChunks(FSOutputSummer.java:202)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:163)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:144)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSOutputSummer.close(ChecksumFileSystem.java:400)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
at org.apache.hadoop.mapreduce.split.JobSplitWriter.createSplitFiles(JobSplitWriter.java:80)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:603)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:614)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:492)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at zhouls.bigdata.myMapReduce.Anagram.Anagram.run(Anagram.java:103)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at zhouls.bigdata.myMapReduce.Anagram.Anagram.main(Anagram.java:119)

这是hadoop-2.6.0版本的

知识点:
2.4之前的和自后的需要的不一样,需要选择正确的版本(包括操作系统的版本)

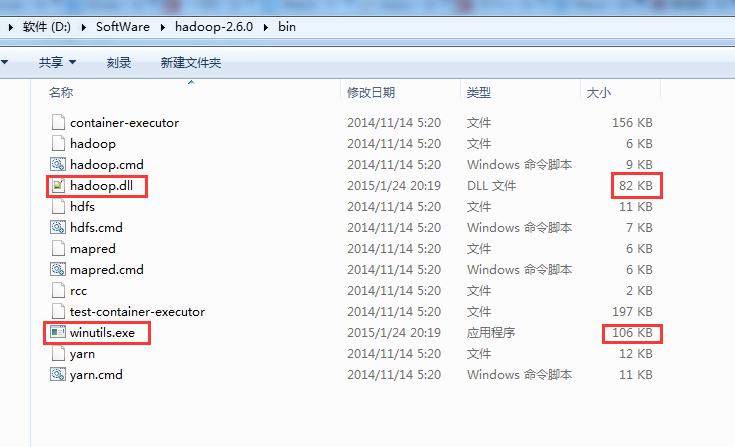
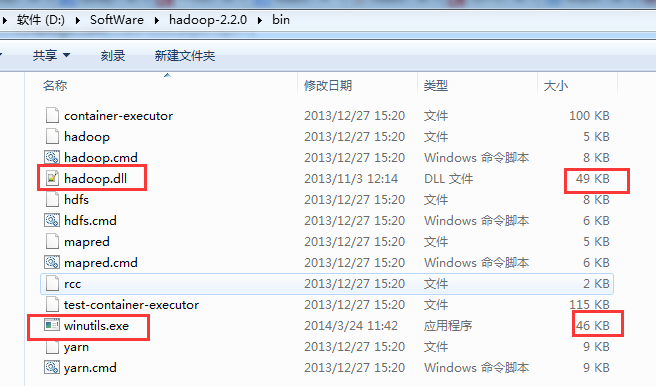
下载地址
http://download.csdn.net/detail/u010106732/9707913
http://download.csdn.net/detail/u010106732/9707915
Hadoop概念学习系列之关于hadoop-2.2.0和hadoop2.6.0的winutils.exe、hadoop.dll版本混用(易出错)(四十三)的更多相关文章
- Hadoop概念学习系列之Hadoop新手学习指导之入门需知(二十)
不多说,直接上干货! 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.从一开始什么都不懂,到能够搭建集群,开发.整个过程,只要有Linux基础,虚拟机化和java基础,其实hadoo ...
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- Hadoop概念学习系列之Hadoop集群动态增加新节点或删除已有某节点及复制策略导向 (四十三)
不多说,直接上干货! hadoop-2.6.0动态添加新节点 https://blog.csdn.net/baidu_25820069/article/details/52225216 Hadoop集 ...
- Hadoop概念学习系列之为什么hadoop/spark执行作业时,输出路径必须要不存在?(三十九)
很多人只会,但没深入体会和想为什么要这样? 拿Hadoop来说,当然,spark也一样的道理. 输出路径由Hadoop自己创建,实际的结果文件遵守part-nnnn的约定. 如何指定一个已有目录作为H ...
- Hadoop概念学习系列之Java调用Shell命令和脚本,致力于hadoop/spark集群(三十六)
前言 说明的是,本博文,是在以下的博文基础上,立足于它们,致力于我的大数据领域! http://kongcodecenter.iteye.com/blog/1231177 http://blog.cs ...
- Hadoop概念学习系列之搭建(windows)Eclipse/MyEclipse远程操作(Linux上)hadoop2.2.0/hadoop2.6.0 出错集(三十五)
本博文,是在http://blog.csdn.net/u010911997/article/details/44099165 的基础上.感谢原博主! 问题1:在DFS Lcation 上不能多文件进 ...
- Hadoop概念学习系列之Hadoop 生态系统(十二)
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Hadoop概念学习系列之常见的分布式文件系统(二十六)
常见的分布式文件系统有,GFS.HDFS.Lustre .Ceph .GridFS .mogileFS.TFS.FastDFS等.各自适用于不同的领域.它们都不是系统级的分布式文件系统,而是应用级的分 ...
- Hadoop概念学习系列之Hadoop HA进一步深入(二十八)
对于Hadoop里的HA,有hdfs HA和resourcemanger HA之分. 1.hdfs HA 为什么引入federation? 因为,这样能达到允许在一个集群里,有多对namenode.通 ...
随机推荐
- linux cent os 6 的安装
目前,只有图片,没有仔细写,这是在虚拟机内的安装:
- java错误:找不到或无法加载主类
问题: 在 windows cmd 中编译后,运行 java 文件时,出现此错误 分析: 源文件 ClientDemo.java: package netdemo; public class Clie ...
- C++学习(二十)(C语言部分)之 函数1
函数 printf 输出的函数 scanf 输入的函数函数是什么 怎么写 是一组一起执行一个任务的语句 一个程序的基本组成单位是函数 只需要知道函数名字和括号里面要填的内容 就可以调用函数 1.如果代 ...
- python time模块使用笔记(更新)
import time 添加time模块 关于时间和时间戳: 时间是指日常生活中用的,如某年某月某日 时间戳是一个时间长度,是时间关于一个初始时间(好像是1970.1.1)的秒数 localtime方 ...
- 快速挂载iso文件到虚拟机系统
在vm软件菜单栏那里选择vm,再选择弹出菜单最下面的设置,如图,找到实体机上的iso文件,保存. 这时候,在虚拟机ls /dev会发现有一个cdrom,这个就是我们的iso文件,不过我们还需要把它挂载 ...
- 人教版高中数学(A版)
必修1 (已看) 第一章 集合与函数概念 1.1 集合 1.2 函数及其表示 1.3 函数的基本性质 第二章 基本初等函数(1) 2.1 指数函数 2.2 对数函数 2.3 幂函数 第三章 函数的应用 ...
- JavaScript Closures 闭包
在一些编程语言中, 当我们执行完成function中的局部代码仅在函数执行期间可运行. 但是JS 事不一样的 闭包总结来说, 就是innerFunction 总是有使用outer function 的 ...
- 分享一篇 Git Web 开发流程
分享一篇 Git Web 开发流程 web 项目如何进行 git 多人协作开发 https://segmentfault.com/a/1190000018165757
- k8s-YAML配置文件
一.YAML基础 YAML是专门用来写配置文件的语言,非常简洁和强大,使用比json更方便.它实质上是一种通用的数据串行化格式. YAML语法规则: 大小写敏感 使用缩进表示层级关系 缩进时不允许使用 ...
- 标 题: JavaScript真的要一统江湖了
http://www.newsmth.net/nForum/#!article/Python/125347?p=4 标 题: JavaScript真的要一统江湖了 发信站: 水木社区 (Fri Se ...