python爬虫基本原理及入门
爬虫:请求目标网站并获得数据的程序
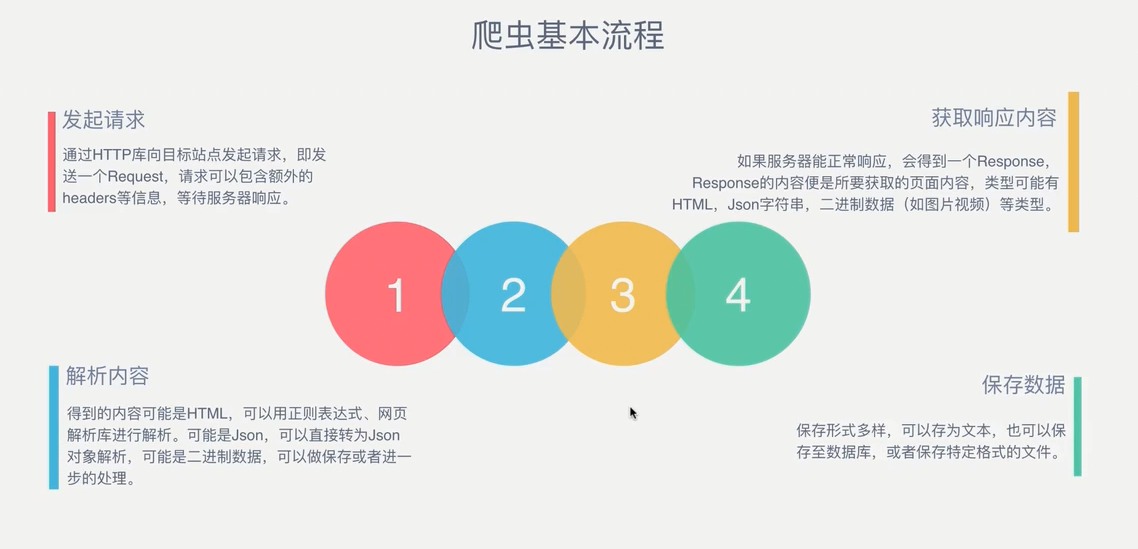
爬虫的基本步骤:
使用python自带的urllib库请求百度:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(type(response))
#打印结果
<class 'http.client.HTTPResponse'>
可以从类型上看出来,response是一个HTTP响应
请求:

请求的方式以GET和POST最为常用,一般的GET方法将请求参数放在URL中。如在百度中搜索一个关键词,这就形成了以GET在URL中更改参数的方法。
而POST将参数放在表单内进行请求。如请求登陆百度,需要向百度服务器发送你的账号密码这些东西。
请求头是一个很重要的请求内容,在一般的浏览器请求中,网站会返回一个你的浏览器信息,如果在代码不伪装程浏览器的情况下,你的IP地址会迅速的被网站封掉,每个爬虫库的伪装方式都是不同的,如urllib库
import urllib.request
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
req = urllib.request.Request(url=url, data=data, method='POST', headers=heads)
response = urllib.request.urlopen(req)
print(response.getheaders()) #getheaders()方法将会返回给你一些请求信息,如时间,服务器信息等,包含user-agent
响应:

响应就是请求之后浏览器所呈现的东西,最重要的就是响应体,包含了网页的源文件
在代码的情况下查看响应状态:
import urllib.request
response = urllib.requset.urlopen('http://www.baidu.com')
print(response.getcode())
#返回200表示成功
解析方式:
当想要获得网页中某些元素应该怎样去解析?

解析的方式多种多样,目前还只是使用正则来做解析,听说xpath是最简单解析方式,不过我觉得每个库还是要使用一下试试的,看看哪个更适合你。
为什么有的网页请求源码和在浏览器中查看到的不一样?
这是因为动态网站使用了JS渲染,元素都是经过js动态加载出来的,所以想要获得源码还要去模拟浏览器的行为,像selenium驱动browser,PhantomJS等工具。
python爬虫基本原理及入门的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Python爬虫的简单入门(一)
Python爬虫的简单入门(一) 简介 这一系列教学是基于Python的爬虫教学在此之前请确保你的电脑已经成功安装了Python(本教程使用的是Python3).爬虫想要学的精通是有点难度的,尤其是遇 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫基础知识入门一
一.什么是爬虫,爬虫能做什么 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.比如它在抓取一个网 ...
- Python爬虫基本原理
爬虫基本原理 1. 什么是爬虫 请求网站并提取数据的自动化程序. 2. 爬虫基本流程 发起请求 通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待 ...
- Python爬虫三年没入门,传授一下绝世神功,经理唏嘘不已!
长期枯燥的生活,敲代码的时间三天两头往吸烟室跑,被项目经理抓去训话. "入门"是学习Python最重要的阶段,虽然这个过程也许会非常缓慢.当你心里有一个目标时,那么你学习起来就不会 ...
- 这个Python爬虫的简单入门及实用的实例,你会吗?
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:HOT_and_COOl 利用爬虫可以进行数据挖掘,比如可以爬取别人的网 ...
- Python爬虫零基础入门(系列)
一.前言上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. update ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
随机推荐
- 测试常用的sql语句总结
测试中常用的sql语句,排名部分先后 1. 查询 SELECT * FROM 表名称 SELECT COUNT(DISTINCT column_name) FROM table_name 指定列的不同 ...
- MVC ---- 去掉HTML过滤
在方法头上添加特效 [ValidateInput(false)] 富文本框提交的内容就可以顺利提交到后台了.
- RN酷炫组件圆形加载
地址:https://js.coach/react-native/react-native-circular-progress?search=react-native 别谢我 点个赞就行 ## Use ...
- BZOJ 4591 【SHOI2015】 超能粒子炮·改
题目链接:超能粒子炮·改 这道题的大体思路就是用\(lucas\)定理,然后合并同类项,就可以得到一个可以递归算的式子了. 我们用\(S(n,k)\)表示答案,\(p\)表示模数(\(2333\)是一 ...
- 学习笔记39—笑谈FireFox标签不同步(IOS和Wiindows)
为了解决国内用户连接 全球同步服务器 困难的问题,火狐中国版推出了 全球服务 和 本地服务 两套服务. 这两套服务的账号和数据并不通用,并且只有中国版提供了切换功能,因此当你在同步过程中遇到“未知账号 ...
- git分支错误提交导致代码丢失--窗口提示HEAD detached错误
今天开发时git 检出分支到本地时操作错误,导致在一个临时分支上开发,且把代码提交了,结果代码未提交到任何分支,提交时还报了个错: HEAD detached at 4d927fa4 后来把代码重新检 ...
- JS client(X,Y)、screen(X,Y)、page(X,Y)的区别
clientX:光标相对于当前窗口的水平位置: clientY :光标相对于当前窗口的垂直位置: screenX :光标相对于该屏幕的水平位置: screenY:光标相对于该屏幕的垂直位置: page ...
- svn上传和下载项目
上传:到项目文件的svn文件夹下——>右键——>SVN Commit...——>输入提交代码备注信息,以便同事查看时,是属于什么内容.这里可以选择哪些文件是要提交到代码仓库上, 下载 ...
- h5调用手机相册摄像头以及文件夹
在之前一家公司的时候要做一个app里面有上传头像的功能,当时研究了好久,找到了一篇文章关于h5摄像头以及相册的调用的,所以就解决了这个问题了!!我这里记录一下以便后面有人需要,可以参考一下!!!! 下 ...
- (转)UCOSII源代码剖析
启动工作原理 刚接触操作系统的时候觉得这个最神秘,到底里面做了什么,怎么就成了个操作系统,它到底有什么用,为什么要引进来着个东东.学了之后才知道,原来最根本的思想还是源于汇编里面的跳转和压栈,以调用一 ...