『MXNet』第八弹_数据处理API_下_Image IO专题
想学习MXNet的同学建议看一看这位博主的博客,受益良多。
在本节中,我们将学习如何在MXNet中预处理和加载图像数据。
在MXNet中加载图像数据有4种方式。
- 使用 mx.image.imdecode 加载原始数据文件
- 使用在Python中实现的mx.img.ImageIter ,很方便自定义。 它可以从.rec(RecordIO)文件和原始图像文件读取。
- 使用C ++实现的MXNet后端的mx.io.ImageRecordIter 。 对于自定义不太灵活,但提供了多种语言绑定。
- 创建自定义的迭代器,继承mx.io.DataIter
预处理图像的方式有多种,我们列举其中的几种:
- 使用mx.io.ImageRecordIter ,快速但不是很灵活。 对于像图像识别这样的简单任务来说,这是非常好的,但是对于更复杂的任务(如检测和分割)来说,不是很有用
- 使用mx.recordio.unpack_img(或cv2.imread,skimage等)+ numpy。由于Python 全局解析锁(GIL),灵活但是缓慢。
- 使用MXNet提供的mx.image 包。它以NDArray 格式存储图像,并利用MXNet的依赖引擎来自动并行化处理并规避GIL。
一、mx.image 包常用预处理
import matplotlib.pyplot as plt
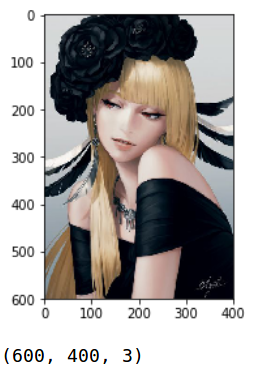
img = mx.image.imdecode(open('test.jpeg', 'rb').read())
plt.imshow(img.asnumpy()); plt.show()
img.shape
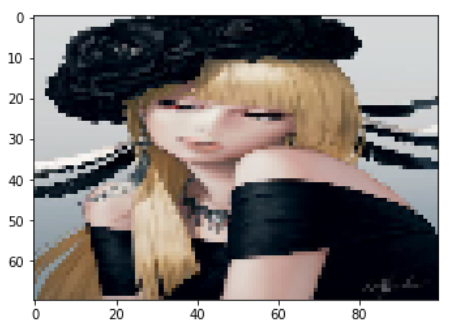
# resize to w x h
tmp = mx.image.imresize(img, 100, 70)
plt.imshow(tmp.asnumpy()); plt.show()
# crop a random w x h region from image
tmp, coord = mx.image.random_crop(img, (150, 200))
print(coord)
plt.imshow(tmp.asnumpy()); plt.show()

二、MXNet存储格式转换工具:im2rec
MXNet框架用于做图像相关的项目时,读取图像主要有两种方式:
- 第一种是读.rec格式的文件,类似Caffe框架中LMDB,优点是.rec文件比较稳定,移植到别的电脑上也能复现,缺点是占空间(.rec文件的大小基本上和图像的存储大小差不多),而且增删数据不大灵活。需要idx搭配使用,下面脚本会一并生成。
- 第二种是.lst和图像结合的方式,首先在前面生成.rec文件的过程中也会生成.lst文件,这个.lst文件就是图像路径和标签的对应列表,也就是说通过维护这个列表来控制你训练集和测试集的变化,优点是灵活且不占空间,缺点是如果图像格式不符合要求的话容易出错而且如果列表中的某些图像路径对应的图像文件夹中图像被删除,就寻找不到,另外如果你不是从固态硬盘上读取图像的话,速度会很慢。
1.生成.lst
需要准备的就是你的图像。假设你的图像数据放在/home/image文件夹下,一共有10个类别,那么在/home/image文件夹下应该有10个子文件夹,每个子文件夹放属于这个类的图像文件,你可以用英文名命名这些子文件夹来表达类别,这个都无所谓,即便用1到10这10个数字来分别命名这10个子文件夹也没什么,只不过用英文名会方便你记忆这个文件夹包含的图像是属于哪个类别的。另外假设你要将生成的.lst文件放在/home/lst文件夹下,你的mxnet项目的路径是~/incubator-mxnet,那么运行下面的命令就可以生成.lst文件:
python ~/incubator-mxnet/tools/im2rec.py
--list True // list参数必须要是True,说明你是要生成.lst文件
--recursive True // recursive参数必须为True,表示要将所有图像路径写进成.lst文件
--train-ratio 0.9 /home/lst/data /home/image // train-ratio参数表示将train和val以多少比例划分,默认为1,表示都是train的数据
这样在/home/lst文件夹下就会生成data_train.lst和data_val.lst两个文件。
.lst文件样例:第一列是index,第二列是label,第三列是图像路径
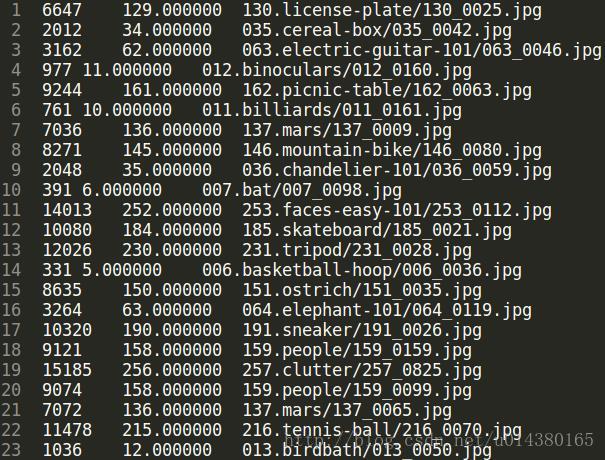
当然有时候可能你的数据图像不是按照一个类别放在一个文件夹这种方式,那么就要考虑修改这个脚本来生成相同格式的.lst文件才能用于后续生成.rec文件。
2.生成.rec
python ~/incubator-mxnet/tools/im2rec.py
--num-thread 4 /home/lst /home/image
需要准备的就是第一步生成的.lst文件和你的图像。
倒数第二个参数:/home/lst是你的.lst文件所放的路径,可以不用指明.lst文件名称,因为代码会自动搜索/home/lst文件夹下所有以.lst结尾的文件。
最后一个参数:/home/image是你的图像所放的路径。
–num-thread 4 这个参数是表示用4个线程来执行,当你数据量较大的时候,生成.rec的过程会比较慢,所以这样可以加速。
3.使用python脚本完成数据生成
假设你要将生成的.rec文件放在.lst文件相同的/home/lst文件夹下(一般都会这样操作),那么运行下面的命令就可以生成.rec文件:
在了解如何使用两个内置Image迭代器读取数据之前,需要将其转换为记录rec格式。
mxnet提供工具im2rec.py
import subprocess im2rec_path = mx.test_utils.get_im2rec_path() # im2rec脚本路径
data_path = os.path.join('data','101_ObjectCategories') # 图像加载路径(里面是不同类别的文件夹)
prefix_path = os.path.join('data','caltech') # 文件生成路径 with open(os.devnull, 'wb') as devnull:
subprocess.check_call(['python', im2rec_path, '--list', '--recursive', '--test-ratio=0.2', prefix_path, data_path],
stdout=devnull) print(im2rec_path, '\n', data_path, '\n', prefix_path)
/home/hellcat/anaconda3/lib/python3.6/site-packages/mxnet/tools/im2rec.py
data/101_ObjectCategories
data/caltech
三、图像数据读取
MXNet的图像数据导入模块主要有mxnet.io.ImageRecordIter和mxnet.image.ImageIter两个类,前者主要用来读取.rec格式的数据,后者既可以读.rec格式文件,也可以读原图像数据。
Using ImageRecordIter
ImageRecordIter can be used for loading image data saved in record io format. To use ImageRecordIter, simply create an instance by loading your record file:
# ImageRecordIter 可用于加载以io格式保存的图像数据 data_iter = mx.io.ImageRecordIter(
path_imgrec="./data/caltech.rec", # the target record file
data_shape=(3, 227, 227), # output data shape. An 227x227 region will be cropped from the original image.
batch_size=4, # number of samples per batch
resize=256 # resize the shorter edge to 256 before cropping
# ... you can add more augumentation options as defined in ImageRecordIter.
)
data_iter.reset()
batch = data_iter.next()
data = batch.data[0]
for i in range(4):
plt.subplot(1,4,i+1)
plt.imshow(data[i].asnumpy().astype(np.uint8).transpose((1,2,0)))
plt.show()

dataiter = mx.io.ImageRecordIter(
#rec文件所在位置
path_imgrec="MNIST.rec",
#rec文件中图像大小以及通道数量
data_shape=(3,28,28),
#每个batch中图像的数量
batch_size=100,
#平均图像,如果设置了平均图像,则输入图像将减去该平均图像
mean_img="data/cifar/cifar10_mean.bin",
#随机对图像进行裁剪
rand_crop=True,
#随机对图像进行镜像
rand_mirror=True,
#从rec文件中随机取出图像
shuffle=False,
#预处理线程数
preprocess_threads=4,
#预取缓存
prefetch_buffer=1)
Using ImageIter
ImageIter is a flexible interface that supports loading of images in both RecordIO and Raw format.
# ImageIter 是一个灵活的界面,支持以RecordIO和Raw格式加载图像 data_iter = mx.image.ImageIter(batch_size=4, data_shape=(3, 227, 227),
path_imgrec="./data/caltech.rec",
path_imgidx="./data/caltech.idx" )
data_iter.reset()
batch = data_iter.next()
data = batch.data[0]
for i in range(4):
plt.subplot(1,4,i+1)
plt.imshow(data[i].asnumpy().astype(np.uint8).transpose((1,2,0)))
plt.show()

脚本image.py可以在~/mxnet/python/mxnet/image.py找到,里面是各个函数和类的具体实现细节。另外,这个包的各个函数的介绍可以看官网地址:http://mxnet.io/api/python/io.html#api-reference
这里先提另外一个函数:mxnet.image.imdecode(buf, **kwargs) # 将图像编码成NDArray格式,我们知道在MXNet框架中,数据存储为NDArray格式,图像数据也是如此,因此mxnet.image中的很多函数的输入输出都是NDArray格式。
mxnet.image.ImageIter是一个非常重要的类。在MXNet中,当你要读入图像数据时,可以用im2rec.py生成lst和rec文件,然后用mxnet.io.ImageRecordIter类来读取rec文件或者用这个mxnet.image.ImageIter类来读取rec文件,但是这个函数和前者相比还能直接读取图像文件,这样就可以不用生成占内存的rec文件了,只需要原图像文件和lst文件即可。另外,在mxnet.io.ImageRecordIter中对于数据的预处理操作都是固定的,不好修改,但是mxnet.image.ImageIter却可以非常灵活地添加各种预处理操作。接下来看看这个类。
mxnet.image.ImageIter(batch_size, data_shape, label_width=1,
path_imgrec=None, path_imglist=None,
path_root=None, path_imgidx=None, shuffle=False,
part_index=0, num_parts=1, aug_list=None, imglist=None,
data_name='data', label_name='softmax_label', **kwargs)
参数:
● batch_size (int) – Number of examples per batch.
● data_shape (tuple) – Data shape in (channels, height, width) format. For now, only RGB image with 3 channels is supported.
● label_width (int, optional) – Number of labels per example. The default label width is 1.
● path_imgrec (str) – Path to image record file (.rec). Created with tools/im2rec.py or bin/im2rec.
● path_imglist (str) – Path to image list (.lst). Created with tools/im2rec.py or with custom script. Format: Tab separated record of index, one or more labels and relative_path_from_root.
● imglist (list) – A list of images with the label(s). Each item is a list [imagelabel: float or list of float, imgpath].
● path_root (str) – Root folder of image files.
● path_imgidx (str) – Path to image index file. Needed for partition and shuffling when using .rec source.
● shuffle (bool) – Whether to shuffle all images at the start of each iteration or not. Can be slow for HDD.
● part_index (int) – Partition index.
● num_parts (int) – Total number of partitions.
● data_name (str) – Data name for provided symbols.
● label_name (str) – Label name for provided symbols.
● kwargs – More arguments for creating augmenter. See mx.image.CreateAugmenter.
使用.lst和图像时,示意如下:
train = mx.image.ImageIter(
batch_size = args.batch_size,
data_shape = (3,224,224),
label_width = 1,
path_imglist = args.data_train,
path_root = args.image_train,
part_index = rank,
shuffle = True,
data_name = 'data',
label_name = 'softmax_label',
aug_list = mx.image.CreateAugmenter((3,224,224),resize=224,rand_crop=True,rand_mirror=True,mean=True))
这里的path_imglist参数和path_root参数是这个类特有的,分别表示.lst文件和图像的路
只是一个列表文件,大大节省了存储空间,也方便以后对数据的增删改变,因为只要重新生成.lst文件即可,而不需要花时间生成占空间的.rec文件。
参数aug_list,表示所有预处理的列表,在image.py脚本中ImageIter类的init()函数的这几行代码:
if aug_list is None:
self.auglist = CreateAugmenter(data_shape, **kwargs)
else:
self.auglist = aug_list
如果aug_list这个参数没有赋值(默认是None),那么就不对图像做预处理;如果这个参数有值,那么就调用CreateAugmenter()函数生成预处理列表。CreateAugmenter()函数相关见第四部分。
Using ImageDetIter
目标检测用,示意见SSD教程
标号的形状是batch_size x num_object_per_image x 5。每个标号由长为5的数组表示,第一个元素是其对用物体的标号,其中-1表示非法物体,仅做填充使用。后面4个元素表示边框。
四、附录:CreateAugmenter
def CreateAugmenter(data_shape, resize=0, rand_crop=False, rand_resize=False, rand_mirror=False,mean=None,
std=None, brightness=0, contrast=0, saturation=0,
pca_noise=0, inter_method=2):
"""Creates an augmenter list."""
auglist = [] # resize这个参数很重要,一般都要做resize,如果你的resize参数设置为224,你的原图像是350*300,那么最后resize的大小就是
# (350*300/224)*224。这里ResizeAug()函数调用resize_short()函数,resize_short()函数调用OpenCV的imresize()函数完成resize
# ,interp参数为2表示采用双三次插值做resize,可以参考:http://docs.opencv.org/master/da/d54/group__imgproc__transform.html。
if resize > 0:
auglist.append(ResizeAug(resize, inter_method)) crop_size = (data_shape[2], data_shape[1]) # 如果rand_resize参数是true,那么会调用RandomSizedCropAug()函数,输入是size,min_area,retio,interp,
# 这个函数既做resize又做crop,因此这边才会写成if elif的语句。RandomSizedCropAug()函数调用random_size_crop()函数,
# 这个函数会先生成随机的坐标点和长宽值,然后调用fixed_crop()函数做crop。
#这里还有一个语句是assert rand_crop,python的assert语句是用来声明其布尔值必须为真,如果表达式为假,就会触发异常。
# 也就是说要调用RandomSizedCropAug()函数的前提是rand_crop是True。
if rand_resize:
assert rand_crop
auglist.append(RandomSizedCropAug(crop_size, 0.3, (3.0 / 4.0, 4.0 / 3.0), inter_method)) #如果rand_crop参数是true,表示随机裁剪,randomCropAug()函数的输入之一是crop_size,
# 这个crop_size就是CreateAugmenter()函数的输入data_shape的图像大小,然后randomCropAug()函数调用random_crop()函数,
# random_crop()函数会先生成新的长宽值和坐标点,然后以此调用fixed_crop()函数做crop,
# 最后返回crop后的图像和坐标即长宽值,因为生成中心坐标点的时候是随机的,所以还是random crop。
elif rand_crop:
auglist.append(RandomCropAug(crop_size, inter_method)) # 如果前面两个if条件都不满足,就调用CenterCropAug()函数做crop,这个函数的输入也包括了crop_size,也就是你的输入data_shape,
# 所以这个参数是很有用的。CenterCropAug()函数调用center_crop()函数,这个函数的输入输出都是NDArray格式。
# center_crop()函数和random_crop()函数的区别在于前者坐标点的生成不是随机的,而是和原图像一样,
# 然后再将坐标点和新的长宽作为fixed_crop()函数的输入。
else:
auglist.append(CenterCropAug(crop_size, inter_method))
#可以看出不管你是否要做crop,只要你给定了data_shape参数,就默认要将输入图像做crop操作。
# 因此如果你不想在test的时候做crop,可以在这修改源码。 # 随机镜像处理,参数是0.5,HorizontalFlipAug()函数调用nd.flip()函数做水平翻转
if rand_mirror:
auglist.append(HorizontalFlipAug(0.5)) # CastAug()函数主要是将数据格式转化为float32
auglist.append(CastAug()) # 这三个参数分别是亮度,对比度,饱和度。当你对这三个参数设置了值,
# 就会调用ColorJitterAug()函数对其相应的亮度或对比度或饱和度做改变
if brightness or contrast or saturation:
auglist.append(ColorJitterAug(brightness, contrast, saturation)) # 这个部分主要是添加pca噪声的,具体可以看LightingAug()函数
if pca_noise > 0:
eigval = np.array([55.46, 4.794, 1.148])
eigvec = np.array([[-0.5675, 0.7192, 0.4009],
[-0.5808, -0.0045, -0.8140],
[-0.5836, -0.6948, 0.4203]])
auglist.append(LightingAug(pca_noise, eigval, eigvec)) # mean这个参数主要是和归一化相关。这里的assert语句前面已经介绍过了。mean参数默认是None,这种情况下是不会进入下面的if elif条件函数的。
# 如果想进行均值操作,可以设置mean为True,那么就会进入第一个if条件,如果你设置为其他值,就会进入elif条件,
# 这个时候如果你的mean不符合要求,比如isinstance函数用来判断类型,就会触发异常。
if mean is True:
mean = np.array([123.68, 116.28, 103.53])
elif mean is not None:
assert isinstance(mean, np.ndarray) and mean.shape[0] in [1, 3] # std与mean同理
if std is True:
std = np.array([58.395, 57.12, 57.375])
elif std is not None:
assert isinstance(std, np.ndarray) and std.shape[0] in [1, 3] # 这里需要mean和std同时都设置正确才能进行预处理,如果你只设置了mean,没有设置std,那么还是没有启动归一化的预处理。
# 这里主要调用ColorNormalizeAug()函数,这个函数调用color_normalize()函数,这个函数的实现很简单,
# 就是将原图像的像素值减去均值mean,然后除以标准差std得到返回值。
if mean is not None and std is not None:
auglist.append(ColorNormalizeAug(mean, std)) # 最后返回预处理的列表
return auglist
『MXNet』第八弹_数据处理API_下_Image IO专题的更多相关文章
- 『MXNet』第八弹_数据处理API_上
一.Gluon数据加载 下面的两个dataset处理类一般会成对出现,两个都可做预处理,但是由于后面还可能用到原始图片,.ImageFolderDataset不加预处理的话可以满足,所以建议在.Dat ...
- 『MXNet』第十弹_物体检测SSD
全流程地址 一.辅助API介绍 mxnet.image.ImageDetIter 图像检测迭代器, from mxnet import image from mxnet import nd data_ ...
- 『MXNet』第十一弹_符号式编程初探
一.符号分类 符号对我们想要进行的计算进行了描述, 下图展示了符号如何对计算进行描述. 我们定义了符号变量A, 符号变量B, 生成了符号变量C, 其中, A, B为参数节点, C为内部节点! mxne ...
- 『MXNet』第七弹_多GPU并行程序设计
资料原文 一.概述思路 假设一台机器上有个GPU.给定需要训练的模型,每个GPU将分别独立维护一份完整的模型参数. 在模型训练的任意一次迭代中,给定一个小批量,我们将该批量中的样本划分成份并分给每个G ...
- 『TensorFlow』第七弹_保存&载入会话_霸王回马
首更: 由于TensorFlow的奇怪形式,所以载入保存的是sess,把会话中当前激活的变量保存下来,所以必须保证(其他网络也要求这个)保存网络和载入网络的结构一致,且变量名称必须一致,这是caffe ...
- 『MXNet』第四弹_Gluon自定义层
一.不含参数层 通过继承Block自定义了一个将输入减掉均值的层:CenteredLayer类,并将层的计算放在forward函数里, from mxnet import nd, gluon from ...
- 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_下
『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上 # Author : Hellcat # Time : 2018/2/11 import torch as t import t ...
- 『PyTorch x TensorFlow』第八弹_基本nn.Module层函数
『TensorFlow』网络操作API_上 『TensorFlow』网络操作API_中 『TensorFlow』网络操作API_下 之前也说过,tf 和 t 的层本质区别就是 tf 的是层函数,调用即 ...
- 『PyTorch』第十弹_循环神经网络
RNN基础: 『cs231n』作业3问题1选讲_通过代码理解RNN&图像标注训练 TensorFlow RNN: 『TensotFlow』基础RNN网络分类问题 『TensotFlow』基础R ...
随机推荐
- 【问题解决】连接mysql 8错误:authentication plugin 'caching_sha2_password
在刚安装好mysql8,使用native连接的时候报错 authentication plugin 'caching_sha2_password'... 首先确保服务已开启,然后通过cmd命令进入my ...
- NOIP队内凉心互测总结(8.22update)
8.22(结束后一天) __stdcall讲题qwq 全是CF原题 D1T1 一看像是结论题,打了下表,水过 没错就是结论题,直接暴力就好 D1T2 看起来不好做,没有AC思路 打了暴力 40分 T2 ...
- HashMap 和 HashTable 的区别
1. 存储结构 HashMap HashTable 数组 + 链表/红黑树 数组 + 链表 HashMap的存储规则: 优先使用数组存储, 如果出现Hash冲突, 将在数组的该位置拉伸出链表进行存储( ...
- Latex: 添加IEEE论文keywords
参考: How to use \IEEEkeywords Latex: 添加IEEE论文keywords 方法: \begin{IEEEkeywords} keyword1, keyword2. \e ...
- R语言通过loess去除某个变量对数据的影响--CNV分析
当我们想研究不同sample的某个变量A之间的差异时,往往会因为其它一些变量B对该变量的固有影响,而影响不同sample变量A的比较,这个时候需要对sample变量A进行标准化之后才能进行比较.标准化 ...
- pyqt 不规则形状窗口显示
#coding=utf- import sys from PyQt5.QtCore import Qt from PyQt5.QtWidgets import QWidget, QApplicatio ...
- eclipse创建web项目web.xml配置文件笔记
1.使用eclipse创建web项目时,如果直接finish的话就没有默认生成web.xml配置文件,此时在你的项目下是看不到web.xml配置文件的,如果要查看的话可以如下操作: 右键你的项目,然后 ...
- js,java时间处理
1.JS获取时间格式为“yyyy-MM-dd HH:mm:ss”的字符串 function getTimeStr(){ var myDate = new Date(); var year = myDa ...
- Python 数字(Number)
Python 数字(Number) Python 数字数据类型用于存储数值. 数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间. 以下实例在变量赋值时 Number 对象 ...
- jq 折面板+tab切换(自己封装的插件哦!!)
如上图所示的一个折面板效果+tab切换:最重要的js代码如下: 对于布局简单介绍下: hot_wrap_li 这个是带箭头的横条: Arrow 这个是箭头的div:hot_wrap_li_wrap 这 ...