Apache Hudi重磅特性解读之全局索引
1. 摘要
Hudi表允许多种类型操作,包括非常常用的upsert,当然为支持upsert,Hudi依赖索引机制来定位记录在哪些文件中。
当前,Hudi支持分区和非分区的数据集。分区数据集是将一组文件(数据)放在称为分区的桶中的数据集。一个Hudi数据集可能由N个分区和M个文件组成,这种组织结构也非常方便hive/presto/spark等引擎根据分区字段过滤以返回有限的数据量。而分区的值绝大多数情况下是从数据中得来,这个要求一旦一条记录映射到分区/桶,那么这个映射应该 a) 被Hudi知道;b) 在Hudi数据集生命周期里保持不变。
在一个非分区数据上Hudi需要知道recordKey -> fileId的映射以便对记录进行upsert操作,现有解决方案如下:a) 用户/客户端通过payload提供正确的分区值;b) 实现GlobalBloomIndex索引来扫描指定路径下的所有文件。上述两个场景下,要么需要用户提供映射信息,要么会导致扫描所有文件的性能开销。
这个方案拟实现一种新的索引类型,维护(recordKey <-> partition, fileId) 映射或者((recordKey, partitionPath) → fileId)映射,这种映射由Hudi存储和维护,可以解决上述提到的两个限制。
2. 背景
数据集类型
Hudi存储抽象主要有两部分组成:1) 实际存储的数据;2) 用于定位记录位置(fileId)的索引,如果没有这个信息,Hudi不能处理upserts。我们可以将数据湖中摄取的所有数据集大致分为两类。
插入/事件数据
插入或事件数据表示新写入表的数据和之前写入的数据没有任何交集,更具体点就是表中每一行数据都是新的一行并且和之前写入的数据没有重叠。比如从App中摄取日志到表中,每一行日志都是新的一行,和之前写入的日志没有关系,因此新的写入不需要任何之前写入的上下文来决定新数据应该写入到哪里。
更新/变更日志数据
更新/变更日志处理是另外一个挑战,写入表的数据可能依赖之前写入的数据。更具体点就是表中每一行数据不是新行并且可能和之前写入的行会重叠,在这种场景下,系统需要决定哪一行需要被更新,因此需要找到需要更新哪个fileId。
Hudi提供了3种供用户使用的方案
- 数据组织结构为分区结构,每个分区包含N个文件,客户端维护recordKey<->fileId的映射用于表的更新,在将记录传递至Hudi处理之前需要提供分区信息。HoodieBloomIndex实现会扫描分区下所有文件中的BloomIndex,如果匹配,则继续在文件中确认,这个过程称为
tag,即将记录定位到具体的fileId。 - 数据组织结构为扁平结构,即单个目录包含了表中所有文件。GlobalHoodieBloomIndex实现会扫描所有文件中的BloomIndex,如果匹配,则继续在文件中确认,这个过程同上,但与第一个不同点在于如果文件数据非常大,那么进行
tag的时间会非常耗时。 - 针对append-only的数据集,即不需要更新,只需要使用payload中的分区,如当前的timestamp。
无论是何种类型数据集(append或者append + update),tag过程对写和读的性能影响都非常大。如果我们能够提供记录(record)级别的索引(recordKey -> FileId, partition)而不增加太多延迟的话,这将会让Hudi性能更快。
因此这个RFC旨在提供记录(record)级别的索引来加快Hudi的查找过程。
注意:为方便解释说明,下面我们考虑非分区数据集,因此映射中的键为recordKey,值为(PartitionPath, FileId)。
3. 实现方案
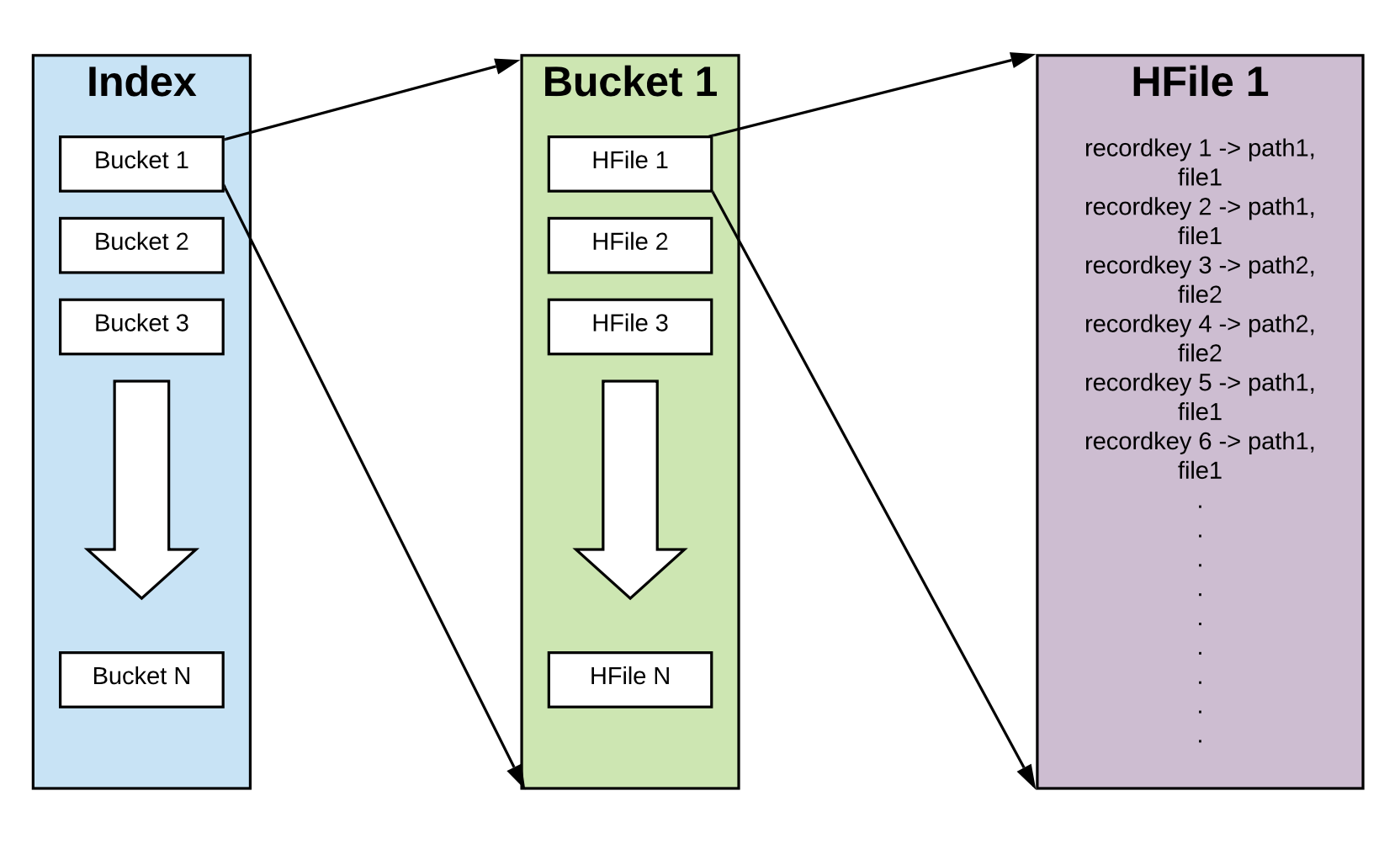
3.1 基于Hash的索引
索引条目被hash至不同的bucket(桶)中,每个桶中存放recordKey -> (PartitionPath, FileId)的映射,桶总数量需提前定义好,并且不能更新,但每个桶可加载不止一个FileGroup,后面会详细介绍FileGroup。1000个桶,每个桶100W个条目,那么可索引10亿个条目,所以只有当独立条目大于10亿个时,才需要在一个桶中放多个FileGroup。
每个桶对外暴露两个API,getRecordLocation(JavaRDD<RecordKeys>) 和insertRecords(JavaPairRDD<RecordKey, Tuple2<PatitionPath, FileId>>)
3.2 存储
使用HFile(link1, link2) 进行存储,因为HFile有非常好的随机读取性能,这里有关于HFile的基准测试,简要概括如下,如果HFile包含100W个条目,查询10W个目标在95%情况下只需要~600ms,如果在实际中可以达到这个性能,那么将会进一步提升Hudi性能。
3.3 索引写路径
对于写路径,一旦确定所有写入记录的HoodieRecordLocation,那么这些记录就被映射为(RecordKey, <PartitionPath, FileId>)。基于RecordKey进行hash,并映射到桶。桶和RecordKey的映射一旦确定后就不会变化。每个Bucket包含N个HFile,另外,所有写入单个HFile的记录需要进行排序,每批新写入会在对应桶中创建新的HFile,因此每个桶会包含N个HFile。同时为限制HFile的数目,也会对HFile做Compaction。因为Hudi中Record对应的FileId永远不变,因此索引的值也不会再变化,这个特性也会在读路径起到作用。
并行度:写入时并行度最好等于分区总数,每个批次在一个桶中最多创建一个HFile。
需要注意的是数据写入和索引写入过程是绑定的,需要在一个ACID内完成,即要么一起提交,要么一起回滚。
3.3.1 更新
现在Hudi中记录的位置信息是不可变的,但是不能确保之后一直是不可变的,因此索引应该能处理映射的更新,在这种情况下,多个值将会被返回(例如,如果HFile1为Record1返回FileId1,HFile3为Record1返回FileId5,我们会选取HFile5的值,因此Record1的位置就是FileId5)。对于提交时间戳,我们要么依赖文件名要么依赖提交元数据,而不是值里包含的时间,因为这样会让索引的大小爆炸。
3.4 索引读路径
对于读和更新路径,在读或写之前需要知道每条记录的位置,所以getRecordLocations(JavaRDD<RecordKeys>)方法将会被调用,这些记录将会被hash到对应的桶,对应的桶将会在HFile中查找记录。
并行度:如前所述,因为暂时不存在对索引的更新,单条记录在一个Bucket中只能存在于一个HFile,所以所有的HFile可并行查找,例如如果我们有100个桶,每个桶有10个HFile,那么可以设置并行度为1000。
3.5 索引删除
可以使用特殊值,如添加一个对应null值的条目,所以在索引查找时,可以继续使用相同的并发度,但是如果返回多个值时选择最新的值,例如HFile1为Record1返回FileId1,HFile3为Record1返回null,那么会选取HFile3的值并且知道Record1已经被删除了。对于提交时间戳,我们要么依赖文件名要么依赖提交元数据,而不是值里包含的时间,因为这样会让索引的大小爆炸。
支持删除会让Compaction变得相对复杂,由于删除操作存在,在Compaction写入新文件时 ,可能需要读取所有待进行Compaction的HFile的所有内容,以便找到最新的值,这可能不会带来太多的开销。另外,Compaction也会忽略被删除的条目以便节省空间。所以可能无法判定一条记录是否从来都未被插入,或者在插入后被删除。
注意:对于删除的条目,还需要支持重新插入。上面介绍的工作流即可支持而无需任何修改。
3.6 Hashing
作为默认实现,我们可以使用Java原生的Hash算法对RecordKey进行Hash,但是可支持开发者自定义Hash算法。
3.7 HFile scan vs seek
通过benchmark可知,对于包含100W个条目的HFile,随机seek在30W ~ 40W的查找时表现较好,否则全文件scan(读取整个HFile到内存进行查找)表现更好。所以在查找时可以利用这个实验结果。我们可以存储每个HFile的所有条目,在查找时,如果查找 < 30%条目,可以使用随机seek,否则进行全表扫描。我们可以引入两个配置,record.level.index.dynamically.choose.scan.vs.seek 和 record.level.index.do.random.lookups,如果第一个配置设置为true,那么会动态选择scan和seek,如果设置为false,对于流式应用,会考虑第二个配置。
3.8 未来扩展
通常,一个好的做法是留出30%的Buffer,以避免超出初始存储桶数。因为在尝试扩展到超出初始化的存储桶的初始数量时,会有一些权衡或开销。第一个实现版本可能不会考虑这个问题,希望由用户自行处理。
3.8.1 选项1-桶中添加多个FileGroup
在一个Bucket中创建多个FileGroup,一个FileGroup代表多个HFile,多个HFile构成一个Group,这些HFile可以被压缩成一个基础HFile,所以一个FileGroup拥有一个基础HFile文件。
若预先分配1000个桶,每个桶100W个条目。对于压缩而言,一个FileGroup中的所有HFile将会被压缩成一个HFile,所以如果不扩展到其他FileGroup,那么同一时间一个HFile文件中可能包含200W个条目,这会导致性能下降,所以当达到100W大小时,应该新建一个FileGroup,这意味着一个桶的权重等于两个虚拟桶,所以hash和桶个数保持相同,但是索引能够扩展多个条目。但新的FileGroup被创建时,老的FileGroup将会被密封(sealed),即不再写入新的条目。新的写入将写入新的FileGroup,读取也不会变化,可以并发查找所有HFile文件。
3.8.2 选项2-多个hash查找和桶组
第一个hash可索引到1 ~ 1000的桶(称为一个桶组),一旦达到桶组的80%时,需要选取一个新的hash,新的hash可索引到1001 ~ 2000,所以在索引查找时,所有记录会进行两次查询,如果查找存在,那么每个桶组只会返回一个值,新的写入将进入桶1001 ~ 2000。
4. 实现说明
如上面章节所述,我们需要对给定桶中的所有HFile进行Compaction(压缩)。为了复用现在代码中的Compaction逻辑,我们引入了 Inline FileSystem ,可以在给定文件中Inline(内联)任何类型(Parquet、HFIle等),有了Inline FileSystem,我们可以在任何通用文件中内联HFile。会为每个内联的HFile生成一个URL路径,这个URL路径可被HFile Reader作为单独的HFile读取里面的内容,下面展示文件中内联HFile的结构。

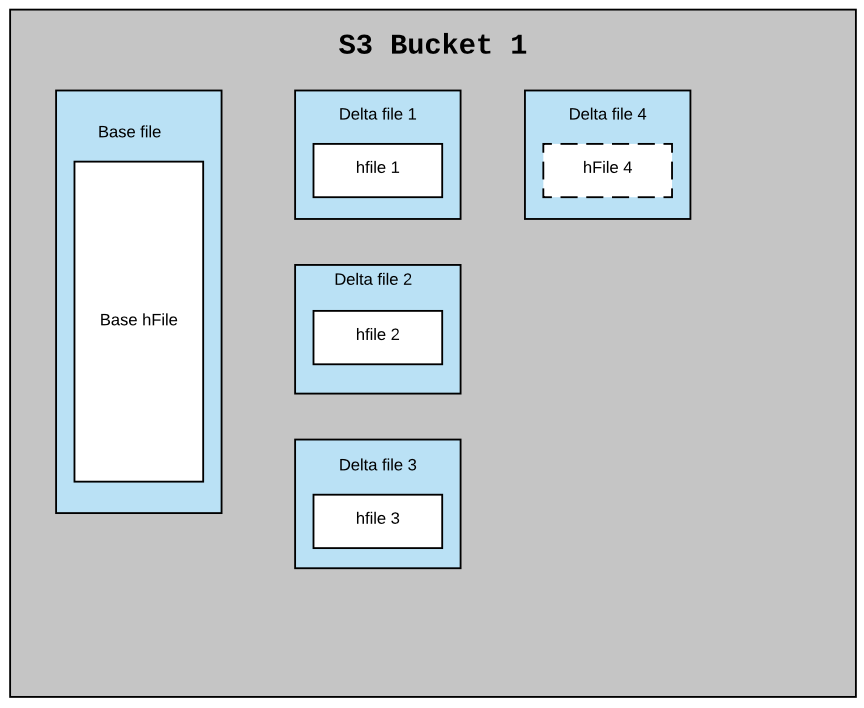
对于云上对象存储,如OSS、S3(不支持append),那么一个数据文件中只会内联一个HFile。
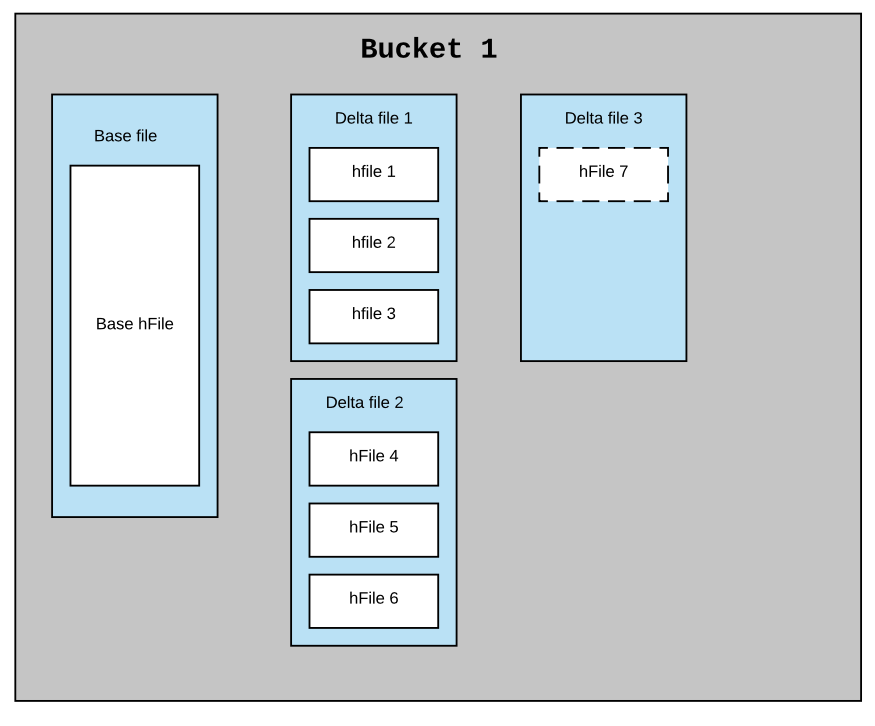
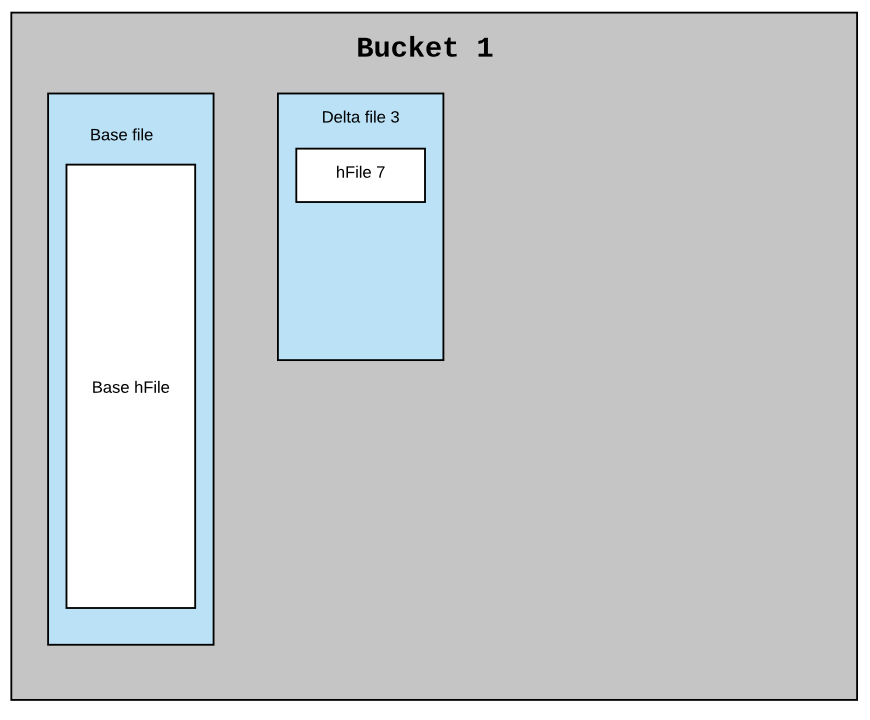
考虑索引方案中的每个桶都是Hudi分区中的一个文件组(包含实际数据)。MOR数据集中的典型分区可能有一个基础文件和N个小增量文件,假设在这个索引中每个桶都有一个相似的结构。每个桶应该有一个基本文件和N个较小的delta文件,每个文件都有一个内联HFile。每一批新的摄取要么将新的HFile作为新的数据块附加到现有的delta文件中,要么创建一个新的增量文件并将新的HFile作为第一个数据块写入。每隔一段时间,压缩将提取基础HFile和所有delta HFile文件,以创建一个新的基本文件(内联HFile)作为压缩版本。
下面是一个例子,说明在压缩前和压缩后,索引在单个桶中的结构
在对象存储上的结构如下
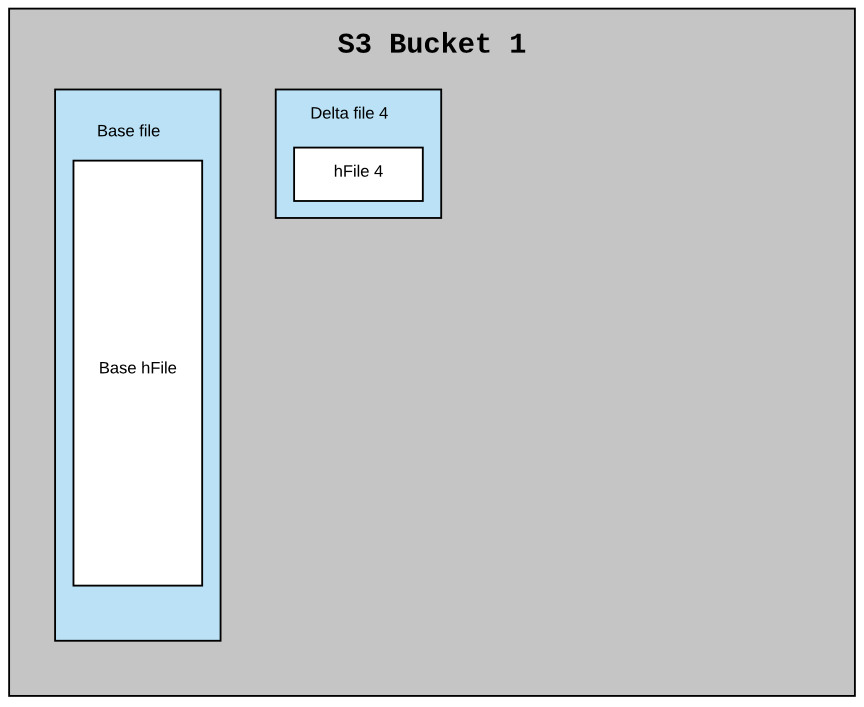
上述结构会带来很多好处。由于异步压缩已经进行过非常多的测试,只需做一些小的变更就可以重用Compaction。在本例中,它不是数据文件,而是内联的HFile文件。使用这种布局,回滚和提交也很容易处理。上面结构得到与Hudi分区相同的文件系统视图(基础HFile和增量HFile)。基于上面结构也很容易读取所有在给定提交时间后的索引,在两个时间间隔内提交的索引等。
5. 总结
记录级别全局索引将极大提升Hudi的写入性能,有望在0.6.0版本释出。
Apache Hudi重磅特性解读之全局索引的更多相关文章
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要 在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力. 增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台 事件流的无限 ...
- 超级重磅!Apache Hudi多模索引对查询优化高达30倍
与许多其他事务数据系统一样,索引一直是 Apache Hudi 不可或缺的一部分,并且与普通表格式抽象不同. 在这篇博客中,我们讨论了我们如何重新构想索引并在 Apache Hudi 0.11.0 版 ...
- Apache Hudi 设计与架构最强解读
感谢 Apache Hudi contributor:王祥虎 翻译&供稿. 欢迎关注微信公众号:ApacheHudi 本文将介绍Apache Hudi的基本概念.设计以及总体基础架构. 1.简 ...
- Apache Hudi 0.8.0版本重磅发布
1. 重点特性 1.1 Flink集成 自从Hudi 0.7.0版本支持Flink写入后,Hudi社区又进一步完善了Flink和Hudi的集成.包括重新设计性能更好.扩展性更好.基于Flink状态索引 ...
- Apache Hudi 0.5.1版本重磅发布
历经大约3个月时间,Apache Hudi 社区终于发布了0.5.1版本,这是Apache Hudi发布的第二个Apache版本,该版本中一些关键点如下 版本升级 将Spark版本从2.1.0升级到2 ...
- Apache Hudi 0.6.0版本重磅发布
1. 下载信息 源码:Apache Hudi 0.6.0 Source Release (asc, sha512) 二进制Jar包:nexus 2. 迁移指南 如果您从0.5.3以前的版本迁移至0.6 ...
- 特性速览| Apache Hudi 0.5.3版本正式发布
1. 下载连接 源代码下载:Apache Hudi 0.5.3 Source Release (asc, sha512) 0.5.3版本相关jar包地址:https://repository.apac ...
随机推荐
- 从windows到Mac的那些坑
今年入职一家新公司 公司办公统一使用Mac pro,所有国产软件不允许使用,只允许装国外的.开源的软件,,,,(这对一个从来没用过Mac的人来说,可真是头疼了一阵子) 经过几天的摸索,作一个简单的小总 ...
- CSS清除浮动&内容居中&文字溢出
学习! 1.CSS清除浮动的方法 (1)添加标签清除浮动: 在浮动元素结尾处,并列的添加标签<div style="clear:both;"></div>. ...
- tensorflow2.0学习笔记第一章第二节
1.2常用函数 本节目标:掌握在建立和操作神经网络过程中常用的函数 # 常用函数 import tensorflow as tf import numpy as np # 强制Tensor的数据类型转 ...
- 实验二 Linux系统简单文件操作命令
项目 内容 这个作业属于哪个课程 班级课程的主页链接 这个作业的要求在哪里 作业要求链接接地址 学号-姓名 17041428-朱槐健 作业学习目标 1.学习在Linux系统终端下进行命令行操作 2.掌 ...
- ubuntu12.04 dnw2 fl2440 配置
1.安装libusb-dev sudo apt-get install libusb-dev 2.dnw2编译配置 源码如下,将其保存为dnw2.c 编译命令 gcc dnw2.c -o dnw2 - ...
- 【Java】利用反射执行Spring容器Bean指定的方法,支持多种参数自动调用
目录 使用情景 目的 实现方式 前提: 思路 核心类 测试方法 源码分享 使用情景 将定时任务录入数据库(这样做的好处是定时任务可视化,也可以动态修改各个任务的执行时间),通过反射执行对应的方法: 配 ...
- 利用java从docx文档中提取文本内容
利用java从docx文档中提取文本内容 使用Apache的第三方jar包,地址为https://poi.apache.org/ docx文档内容如图: 目录结构: 每个文件夹的名称为日期加上来源,例 ...
- 【loj - 6516】「雅礼集训 2018 Day11」进攻!
目录 description solution accepted code details description 你将向敌方发起进攻!敌方的防御阵地可以用一个 \(N\times M\) 的 \(0 ...
- nodejs 换源
解决npm install安装慢的问题国外镜像会很慢 可用 get命令查看registry npm config get registry 原版结果为 http://registry.npmjs.or ...
- 关于GridView的横向合并数据信息
此为asp.net 运行展示: 前端代码: <%@ Page Language="C#" AutoEventWireup="true" CodeBehin ...