大数据并行计算框架Spark
Spark2.1. http://dblab.xmu.edu.cn/blog/1689-2/
0+入门:Spark的安装和使用(Python版)
Spark2.1.0+入门:第一个Spark应用程序:WordCount(Python版)
http://dblab.xmu.edu.cn/blog/1692-2/#more-1692
应用:
启动
cd /usr/local/spark
./bin/pyspark
RDD
分布式对象集合,一个只读的分区记录集合。一种数据结构(相当于int、double等)
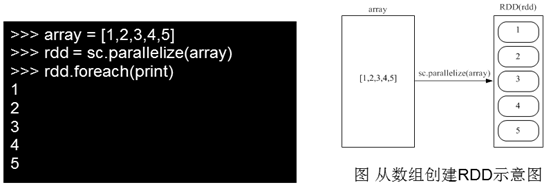
1.RDD创建
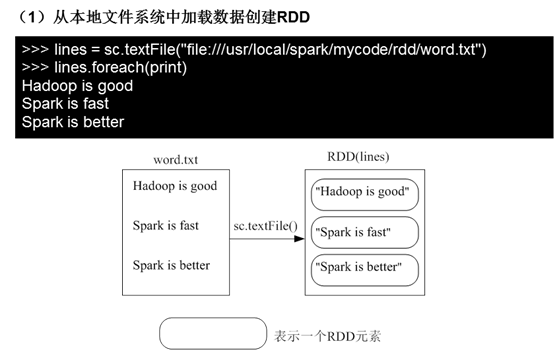
(1)从本地文件系统中加载数据创建RDD
(2)从分布式文件系统HDFS中加载数据

(3)从其他RDD创建。
parallelize:https://blog.csdn.net/wyqwilliam/article/details/84330408
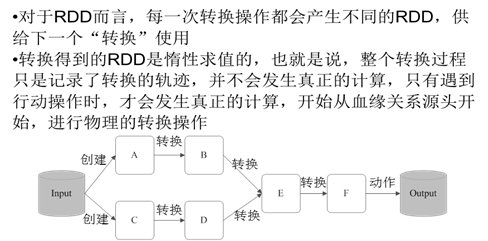
2.RDD操作
Spark API :https://www.csdn.net/gather_26/MtTaYg4sNDQ5MC1ibG9n.html
2.1转换操作

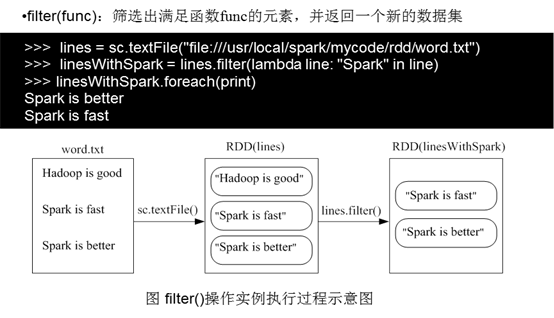
1)fileter(func)
2)map(func)
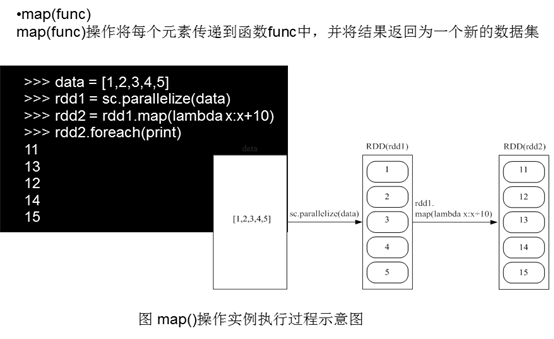
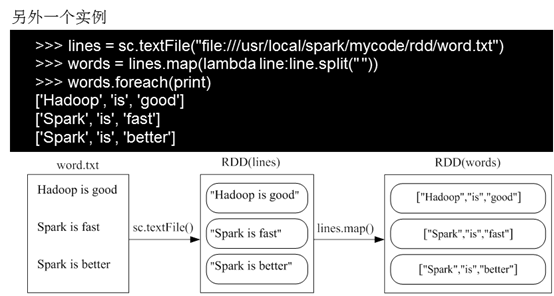
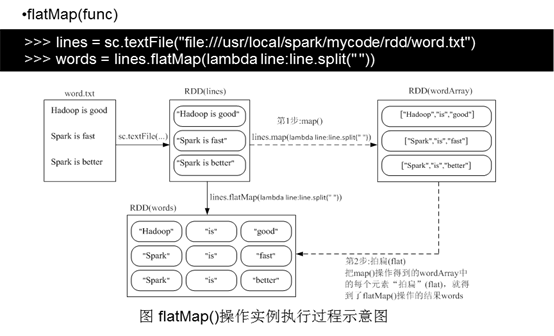
3)flatMap(func)
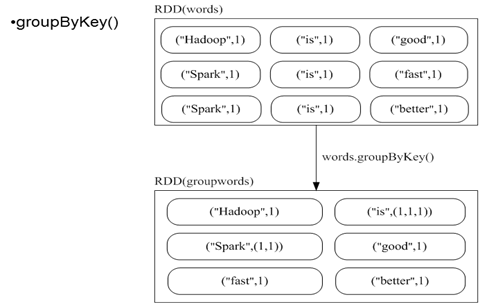
4)groupByKey()

5)reduceBykey(func)

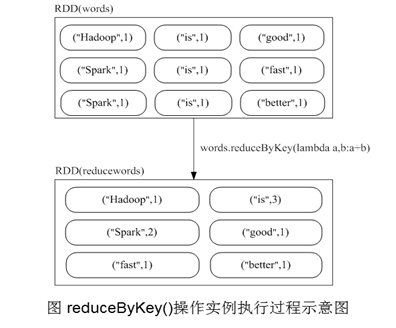
groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义

6)keys()

7)values()

8)mapValues(func)

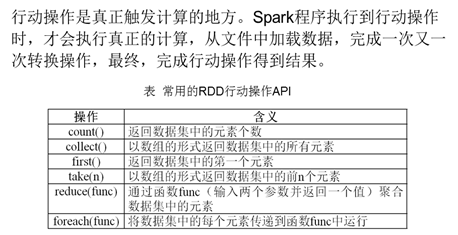
4.2行动操作




4.3惰性机制

持久化




分区


练习:
1给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
2 有两个文件,file1.txt,file2.txt,字段含义如下orderid,userid,payment,productid。求top 5个payment值。
file1.txt
1,1768,50,155
2,1218, 600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
file2.txt
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
大数据并行计算框架Spark的更多相关文章
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- 大数据篇:Spark
大数据篇:Spark Spark是什么 Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写.2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验 ...
- [转帖]大数据hadoop与spark的区别
大数据hadoop与spark的区别 https://www.cnblogs.com/adnb34g/p/9233906.html Posted on 2018-06-27 14:43 左手中倒影 阅 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
随机推荐
- 【LeetCode】141.环形链表
题目描述 141.环形链表 给定一个链表,判断链表中是否有环. 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始). 如果 pos 是 -1,则在该链表中 ...
- [vijos1162]波浪数
题目链接:https://www.vijos.org/p/1162 这题的解法我觉得可能是模拟吧,但是题的分类又是构造QAQ..... 不是很懂,所以我们把这个方法叫做奇技淫巧吧 这题的暴力思路就是针 ...
- Spring Boot整合Servlet,Filter,Listener,访问静态资源
目录 Spring Boot整合Servlet(两种方式) 第一种方式(通过注解扫描方式完成Servlet组件的注册): 第二种方式(通过方法完成Servlet组件的注册) Springboot整合F ...
- Java并发基础05. 传统线程同步通信技术
先看一个问题: 有两个线程,子线程先执行10次,然后主线程执行5次,然后再切换到子线程执行10,再主线程执行5次--如此往返执行50次. 看完这个问题,很明显要用到线程间的通信了, 先分析一下思路:首 ...
- SpringMVC知识大览
SpringMVC大览 springMVC的基础知识 什么是SpringMVC? springmvc框架原理(掌握) 前端控制器.'处理映射器.处理适配器.视图解析器 springmvc的入门程序 目 ...
- javascript原生 实现数字字母混合验证码
实现4位数 数字字母混合验证码(数字+大写字母+小写字母) ASCII 字符集中得到3个范围: 1. 48-57 表示数字0-9 2. 65-90 表示大写字母 3. 97-122 表示小写字母 范围 ...
- Netty 中的 handler 和 ChannelPipeline 分析
上一节我们讲了 Netty 的启动流程,从启动流程入手分析了 Reactor 模型的第一步:channel 如何绑定 Selector.然后讲到了 EventLoop 在启动的时候发挥了什么作用.整个 ...
- 11. SpringCloud实战项目-初始化数据库和表
SpringCloud实战项目全套学习教程连载中 PassJava 学习教程 简介 PassJava-Learning项目是PassJava(佳必过)项目的学习教程.对架构.业务.技术要点进行讲解. ...
- 家庭版记账本app进度之关于listview显示账单,并为其添加点击事件
这个主要学习是关于listview的学习. 怎样去自定义adapter,以及使用.自己创建文件,还有就是为listview的每一个子控件添加点击事件. 在整个过程中收获到的知识点如下: 一.对于数据库 ...
- 【python实现卷积神经网络】损失函数的定义(均方误差损失、交叉熵损失)
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...