OpenCV-Python OpenCV中的K-Means聚类 | 五十八
目标
- 了解如何在OpenCV中使用cv.kmeans()函数进行数据聚类
理解参数
输入参数
sample:它应该是np.float32数据类型,并且每个功能都应该放在单个列中。
nclusters(K):结束条件所需的簇数
criteria:这是迭代终止条件。满足此条件后,算法迭代将停止。实际上,它应该是3个参数的元组。它们是
(type,max_iter,epsilon):
a. 终止条件的类型。它具有3个标志,如下所示:- cv.TERM_CRITERIA_EPS-如果达到指定的精度epsilon,则停止算法迭代。
- cv.TERM_CRITERIA_MAX_ITER-在指定的迭代次数max_iter之后停止算法。
- cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER-当满足上述任何条件时,停止迭代。
b. max_iter-一个整数,指定最大迭代次数。
c. epsilon-要求的精度attempts:该标志用于指定使用不同的初始标签执行算法的次数。该算法返回产生最佳紧密度的标签。该紧凑性作为输出返回。
flags:此标志用于指定初始中心的获取方式。通常,为此使用两个标志:cv.KMEANS_PP_CENTERS和cv.KMEANS_RANDOM_CENTERS。
输出参数
- 紧凑度:它是每个点到其相应中心的平方距离的总和。
- 标签:这是标签数组(与上一篇文章中的“代码”相同),其中每个元素标记为“0”,“ 1” .....
- 中心:这是群集中心的阵列。
现在,我们将通过三个示例了解如何应用K-Means算法。
1. 单特征数据
考虑一下,你有一组仅具有一个特征(即一维)的数据。例如,我们可以解决我们的T恤问题,你只用身高来决定T恤的尺寸。因此,我们首先创建数据并将其绘制在Matplotlib中
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
x = np.random.randint(25,100,25)
y = np.random.randint(175,255,25)
z = np.hstack((x,y))
z = z.reshape((50,1))
z = np.float32(z)
plt.hist(z,256,[0,256]),plt.show()
因此,我们有了“ z”,它是一个大小为50的数组,值的范围是0到255。我将“z”重塑为列向量。
如果存在多个功能,它将更加有用。然后我制作了np.float32类型的数据。
我们得到以下图像:
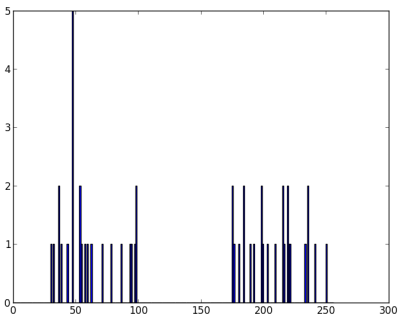
现在我们应用KMeans函数。在此之前,我们需要指定标准。我的标准是,每当运行10次算法迭代或达到epsilon = 1.0的精度时,就停止算法并返回答案。
# 定义终止标准 = ( type, max_iter = 10 , epsilon = 1.0 )
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 设置标志
flags = cv.KMEANS_RANDOM_CENTERS
# 应用K均值
compactness,labels,centers = cv.kmeans(z,2,None,criteria,10,flags)
这为我们提供了紧凑性,标签和中心。在这种情况下,我得到的中心分别为60和207。标签的大小将与测试数据的大小相同,其中每个数据的质心都将标记为“ 0”,“ 1”,“ 2”等。现在,我们根据标签将数据分为不同的群集。
A = z[labels==0]
B = z[labels==1]
现在我们以红色绘制A,以蓝色绘制B,以黄色绘制其质心。
# 现在绘制用红色'A',用蓝色绘制'B',用黄色绘制中心
plt.hist(A,256,[0,256],color = 'r')
plt.hist(B,256,[0,256],color = 'b')
plt.hist(centers,32,[0,256],color = 'y')
plt.show()
得到了以下结果:
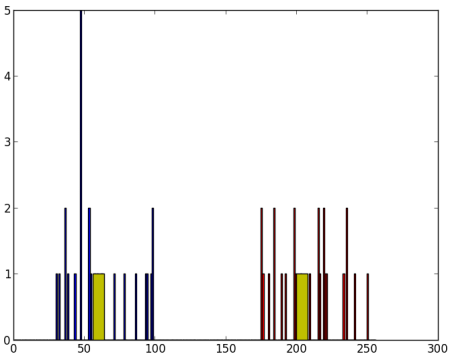
2. 多特征数据
在前面的示例中,我们仅考虑了T恤问题的身高。在这里,我们将同时考虑身高和体重,即两个特征。
请记住,在以前的情况下,我们将数据制作为单个列向量。每个特征排列在一列中,而每一行对应于一个输入测试样本。
例如,在这种情况下,我们设置了一个大小为50x2的测试数据,即50人的身高和体重。第一列对应于全部50个人的身高,第二列对应于他们的体重。第一行包含两个元素,其中第一个是第一人称的身高,第二个是他的体重。类似地,剩余的行对应于其他人的身高和体重。查看下面的图片:
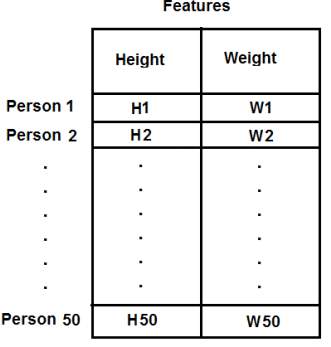
现在,我直接转到代码:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
X = np.random.randint(25,50,(25,2))
Y = np.random.randint(60,85,(25,2))
Z = np.vstack((X,Y))
# 将数据转换未 np.float32
Z = np.float32(Z)
# 定义停止标准,应用K均值
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=cv.kmeans(Z,2,None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
# 现在分离数据, Note the flatten()
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# 绘制数据
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Height'),plt.ylabel('Weight')
plt.show()
我们得到如下结果:
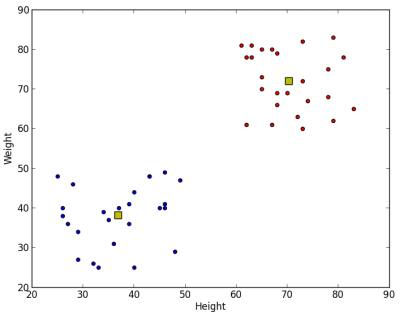
3.颜色量化
颜色量化是减少图像中颜色数量的过程。这样做的原因之一是减少内存。有时,某些设备可能会受到限制,因此只能产生有限数量的颜色。同样在那些情况下,执行颜色量化。在这里,我们使用k均值聚类进行颜色量化。
这里没有新内容要解释。有3个特征,例如R,G,B。因此,我们需要将图像重塑为Mx3大小的数组(M是图像中的像素数)。在聚类之后,我们将质心值(也是R,G,B)应用于所有像素,以使生成的图像具有指定数量的颜色。再一次,我们需要将其重塑为原始图像的形状。下面是代码:
import numpy as np
import cv2 as cv
img = cv.imread('home.jpg')
Z = img.reshape((-1,3))
# 将数据转化为np.float32
Z = np.float32(Z)
# 定义终止标准 聚类数并应用k均值
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret,label,center=cv.kmeans(Z,K,None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
# 现在将数据转化为uint8, 并绘制原图像
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
cv.imshow('res2',res2)
cv.waitKey(0)
cv.destroyAllWindows()
我们可以看的K=8的结果

OpenCV-Python OpenCV中的K-Means聚类 | 五十八的更多相关文章
- .NET + OpenCV & Python + OpenCV 配置
最近需要做一个图像识别的GUI应用,权衡了Opencv+ 1)QT,2)Python GUI,3).NET后选择了.NET... 本文给出C#+Opencv和Python+Opencv的相应参考,节省 ...
- Python脚本控制的WebDriver 常用操作 <二十八> 超时设置和cookie操作
超时设置 测试用例场景 webdriver中可以设置很多的超时时间 implicit_wait.识别对象时的超时时间.过了这个时间如果对象还没找到的话就会抛出异常 Python脚本 ff = webd ...
- Python全栈开发之路 【第十八篇】:Ajax技术
Ajax技术 Ajax = 异步 JavaScript 和 XML. Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. 1.jQuery的load()方法 jQuery loa ...
- python五十八课——正则表达式(切割)
切割:split(regex,string):返回一个列表对象 import re str1='i love shenzhen so much' regex=r' +?' lt=re.split(re ...
- python五十八课——正则表达式(分组)
演示正则中的替换和切割操作:在这之前我们先学习一个分组的概念: 分组:在正则中定义(...)就可以进行分组,理解为得到了一个子组好处:1).如果正则中的逻辑比较复杂,使用分组就可以优化代码的阅读性(更 ...
- 五十八、SAP中常用预定义数据类型
一.SAP中常用预定义数据类型 注意事项如下: 1.默认的定义数据类型是CHAR. 2.取值的时候C型默认从左取,N型从右取,超过定义长度则截断. 3.C类型,可以赋值数值,也可以赋值字符,还可以混合 ...
- python五十八课——正则表达式(替换)
替换:sub(regex,repl,string,count,[flags=0]): 替换数据,返回字符串(已经被替换完成后的内容)subn(regex,repl,string,count,[flag ...
- opencv python实用操作
画多边形 fillConvexPloy与fillConvexPloy的区别 fillConvexPloy 用来画单个凸多边形: 如果点集的连线不是凹多边形,则会找一个最小的凸多边形把该凹多边形包住画出 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
随机推荐
- K8S实战-构建Django项目-03-使用共享存储
上篇博文,发布之后,正好跟着双十一,不知道大家剁手了没~~.好啦,言归正传先声明一下,每周1,3,5更新教程,大家如果想要了解更多的教程可以重温一下之前的教程或者,关注崔格拉斯 公众号,大家想要源码的 ...
- C++走向远洋——63(项目二2、两个成员的类模板)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- FPGA小白学习之路(4)PLL中的locked信号解析(转)
ALTPLL中的areset,locked的使用 转自:http://www.360doc.com/content/13/0509/20/9072830_284220258.shtml 今天对PLL中 ...
- TOMCAT封装DBCP
## 数据源 ## #Tomcat封装的DBCP: >> 基本知识: tomcat在默认情况下已经集成了DBCP: >> JNDI: |-- 基本概念: 在tomcat启动的时 ...
- leetcode 1365. How Many Numbers Are Smaller Than the Current Number
Given the array nums, for each nums[i] find out how many numbers in the array are smaller than it. T ...
- 使用纯粹的JS构建 Web Component
原文链接:https://ayushgp.github.io/htm...译者:阿里云 - 也树 Web Component 出现有一阵子了. Google 费了很大力气去推动它更广泛的应用,但是除 ...
- JS 获取一段时间内的工作时长小时数
本来想是想找轮子的,但是并没有找到能用的,多数都是问题很大,所以就自己写了一个 需求说明 支持自选时间段,即开始时间与结束时间根据用户的上班及下班时间判定返回小时数 技术栈 moment.js 思考过 ...
- HTML5中form的新增属性或元素
1.新增的表单元素 1.1 progress表示任务的完成情况,常用于进度条. max 定义进度元素所要求的任务的工作量,默认值为1 value 定义已经完成的工作量,如果max值为1,该值必须是介于 ...
- moment太重? 那就试试miment--一个超轻量级的js时间库
介绍 Miment 是一个轻量级的时间库(打包压缩后只有1K),没有太多的方法,Miment的设计理念就是让你以几乎为零的成本快速上手,无需一遍一遍的撸文档 由来 首先 致敬一下Moment,非常好用 ...
- java异常和throw和throws的区别
之前在编程中编译完成后,运行时,会遇见一些常见的错误,如NullPointerException,ArrayIndexOutOfBoundsException等等 在今天重新回顾学习了java异常,总 ...