Ubuntu18.04 ElasticSearch7.3.2集群搭建(一)
集群规划:
| Hostname | Elasticsearch | Kibana | Marvel | Marvel Client |
|---|---|---|---|---|
| node01 | √ | √ | √ | √ |
| node02 | √ | √ | ||
| node03 | √ | √ | ||
| node04 | √ | √ | ||
| node05 | √ | √ |
前置准备请参考(主要是jdk 和 免密登录):
https://www.cnblogs.com/ronnieyuan/p/11518913.html
https://www.cnblogs.com/ronnieyuan/p/11461377.html
Elasticsearch 的安装
上传tar包并解压:

tar -zxvf elasticsearch-7.3.2-no-jdk-linux-x86_64.tar.gz -C /opt/ronnie/
修改配置文件
cd /opt/ronnie/elasticsearch-7.3.2/config/ vim elasticsearch.yml
需要修改的配置:
# 集群名
cluster.name: ronnie-es # 节点名 我这是5台虚拟机, 所以分别是node-1 到 node-5
node.name: node-1 # 主机名
network.host: 192.168.180.130 # http连接端口, ps: 9300为集群内部通信端口
http.port: 9200
# 比较新的版本不需要配置多波和防脑裂
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["192.168.180.130","192.168.180.131","192.168.180.132","192.168.180.133","192.168.180.134"]
# 初始主节点
cluster.initial_master_nodes: ["node-1"]将elasticsearch目录发送给其他4台虚拟机
scp -r /opt/ronnie/elasticsearch-7.3.2/ root@192.168.180.131:/opt/ronnie/
scp -r /opt/ronnie/elasticsearch-7.3.2/ root@192.168.180.132:/opt/ronnie/
scp -r /opt/ronnie/elasticsearch-7.3.2/ root@192.168.180.133:/opt/ronnie/
scp -r /opt/ronnie/elasticsearch-7.3.2/ root@192.168.180.134:/opt/ronnie/
修改elasticsearch.yml文件中对应的节点名和主机名
修改系统配置文件
vim ~/.bashrc, 添加ES_HOME路径
# elasticsearch
export ES_HOME=/opt/ronnie/elasticsearch-7.3.2
export PATH=$ES_HOME/bin:$PATH
使修改后的配置生效: source ~/.bashrc, 在命令行下可以tab出elasticsearch即配置成功
这时候启动会报一个错: org.elasticsearch.bootstrap.StartupException:java.lang.RuntimeException: can not run elasticsearch as root
- 原因是es 不允许使用root权限运行, 以前发生过生产事故。
所以我们需要创建一个非root用户来运行es
groupadd es
useradd es -g es -p 123456 cd /opt/ronnie
chown -R es:es elasticsearch-7.3.2/
# 切换为es用户
su es
启动报错
# 说明可控的虚拟内存太小了, 需要调整虚拟内存
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
su root 切换到root用户
执行命令:
sysctl -w vm.max_map_count=262144
再切换回非root用户启动
可以看到一个个节点信息被注册到主节点
[2019-12-19T13:21:33,355][INFO ][o.e.l.LicenseService ] [node-1] license [f1827ea0-c747-4151-98ec-e5db1b56ee14] mode [basic] - valid
[2019-12-19T13:21:33,357][INFO ][o.e.x.s.s.SecurityStatusChangeListener] [node-1] Active license is now [BASIC]; Security is disabled
[2019-12-19T13:21:35,056][INFO ][o.e.c.s.MasterService ] [node-1] node-join[{node-2}{fccTE81jSGyFi6UAqI3pJA}{Ei_BMkwPR1S3P577Oy85yA}{192.168.180.131}{192.168.180.131:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true} join existing leader], term: 1, version: 16, reason: added {{node-2}{fccTE81jSGyFi6UAqI3pJA}{Ei_BMkwPR1S3P577Oy85yA}{192.168.180.131}{192.168.180.131:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}
[2019-12-19T13:21:35,781][INFO ][o.e.c.s.ClusterApplierService] [node-1] added {{node-2}{fccTE81jSGyFi6UAqI3pJA}{Ei_BMkwPR1S3P577Oy85yA}{192.168.180.131}{192.168.180.131:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 16, reason: Publication{term=1, version=16}
[2019-12-19T13:21:36,120][INFO ][o.e.c.s.MasterService ] [node-1] node-join[{node-3}{iYSKZYruQziDaukE38R9Hg}{731BcyNzTfmLsxoLUkVcsA}{192.168.180.132}{192.168.180.132:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true} join existing leader], term: 1, version: 17, reason: added {{node-3}{iYSKZYruQziDaukE38R9Hg}{731BcyNzTfmLsxoLUkVcsA}{192.168.180.132}{192.168.180.132:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}
[2019-12-19T13:21:36,645][INFO ][o.e.c.s.ClusterApplierService] [node-1] added {{node-3}{iYSKZYruQziDaukE38R9Hg}{731BcyNzTfmLsxoLUkVcsA}{192.168.180.132}{192.168.180.132:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 17, reason: Publication{term=1, version=17}
[2019-12-19T13:21:37,385][INFO ][o.e.c.s.MasterService ] [node-1] node-join[{node-4}{qgdThjgcS02z55uB6RAXJg}{TVdEG16wSA-8r9HNfjMrjg}{192.168.180.133}{192.168.180.133:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true} join existing leader], term: 1, version: 19, reason: added {{node-4}{qgdThjgcS02z55uB6RAXJg}{TVdEG16wSA-8r9HNfjMrjg}{192.168.180.133}{192.168.180.133:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}
[2019-12-19T13:21:37,844][INFO ][o.e.c.s.ClusterApplierService] [node-1] added {{node-4}{qgdThjgcS02z55uB6RAXJg}{TVdEG16wSA-8r9HNfjMrjg}{192.168.180.133}{192.168.180.133:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 19, reason: Publication{term=1, version=19}
[2019-12-19T13:21:37,848][INFO ][o.e.c.s.MasterService ] [node-1] node-join[{node-5}{3LkyJBolQAK-MQ9msg60ow}{AB15qo9QQJCi3smFB4WhnQ}{192.168.180.134}{192.168.180.134:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true} join existing leader], term: 1, version: 20, reason: added {{node-5}{3LkyJBolQAK-MQ9msg60ow}{AB15qo9QQJCi3smFB4WhnQ}{192.168.180.134}{192.168.180.134:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}
[2019-12-19T13:21:38,257][INFO ][o.e.c.s.ClusterApplierService] [node-1] added {{node-5}{3LkyJBolQAK-MQ9msg60ow}{AB15qo9QQJCi3smFB4WhnQ}{192.168.180.134}{192.168.180.134:9300}{dim}{ml.machine_memory=3781853184, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 20, reason: Publication{term=1, version=20}
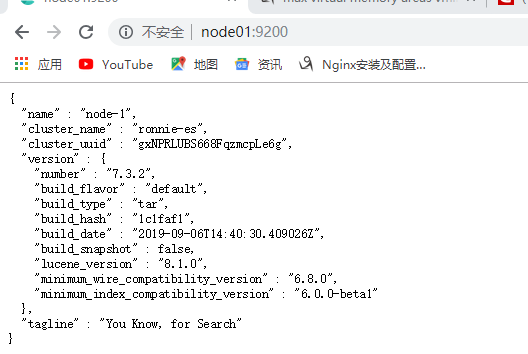
通过浏览器访问9200端口:
Ubuntu18.04 ElasticSearch7.3.2集群搭建(一)的更多相关文章
- ubuntu18.04.2 Hadoop伪集群搭建
准备工作: 若没有下载vim请下载vim 若出现 Could not get lock /var/lib/dpkg/lock 问题请参考: https://jingyan.baidu.com/arti ...
- 04、Spark Standalone集群搭建
04.Spark Standalone集群搭建 4.1 集群概述 独立模式是Spark集群模式之一,需要在多台节点上安装spark软件包,并分别启动master节点和worker节点.master节点 ...
- 在Ubuntu18.04下配置hadoop集群
服务器准备 启动hadoop最小集群的典型配置是3台服务器, 一台作为Master, NameNode, 两台作为Slave, DataNode. 操作系统使用的Ubuntu18.04 Server, ...
- Ubuntu 16.04下Redis Cluster集群搭建(官方原始方案)
前提:先安装好Redis,参考:http://www.cnblogs.com/EasonJim/p/7599941.html 说明:Redis Cluster集群模式可以做到动态增加节点和下线节点,使 ...
- Ubuntu16.04下,rabbimq集群搭建
rabbitmq作为企业级的消息队列,功能很齐全,既可以作为单一的部署模式,又可以做集群的部署模式 单一部署就不说了,就是在一台服务器上部署rabbitmq消息队列,可以参考我的博客:Ubuntu16 ...
- Ubuntu 16.04 下Redis Cluster集群搭建
实际操作如下: 准备工作 版本:4.0.2 下载地址:https://redis.io/download 离线版本:(链接: https://pan.baidu.com/s/1bpwDtOr 密码: ...
- ubuntu18.04 基于Hadoop3.1.2集群的Hbase2.0.6集群搭建
前置条件: 之前已经搭好了带有HDFS, MapReduce,Yarn 的 Hadoop 集群 链接: ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式 ...
- ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建 集群规划: hostname NameNode DataNode JournalNode Re ...
- ubuntu18.04 flink-1.9.0 Standalone集群搭建
集群规划 Master JobManager Standby JobManager Task Manager Zookeeper flink01 √ √ flink02 √ √ flink03 √ √ ...
随机推荐
- 安装Ubuntu后的一些配置
Ubuntu安装的一些配置 搜狗拼音的安装 卸载ibus和它的配置, 卸载顶部面板的键盘指示 sudo apt remove ibus sudo apt purge ibus sudo apt rem ...
- 【原】centos安装django
一.更新系统软件包yum update -y 二.安装软件管理包和可能使用的依赖 yum -y groupinstall "Development tools" yum insta ...
- LeetCode 234. Palindrome Linked List(判断是否为回文链表)
题意:判断是否为回文链表,要求时间复杂度O(n),空间复杂度O(1). 分析: (1)利用快慢指针找到链表的中心 (2)进行步骤(1)的过程中,对前半部分链表进行反转 (3)如果链表长是偶数,首先比较 ...
- 【PAT甲级】1050 String Subtraction (20 分)
题意: 输入两个串,长度小于10000,输出第一个串去掉第二个串含有的字符的余串. trick: ascii码为0的是NULL,减去'0','a','A',均会导致可能减成负数. AAAAAccept ...
- 九、web.xml理解
1.web.xml文件在每个web工程不是必须要有的: web.xml文件是用来初始化配置信息:比如Welcome页面.servlet.servlet-mapping.filter.liste ...
- python2.7 安装 Scipy
Numpy.scikit-learn可以直接 pip install xxx 但Scipy不能,在官网找到了安装方法: python -m pip install --user numpy scipy ...
- redhat 7.6 流量监控命令、软件(2) iftop 监控网络IP实时流量
1.安装iftop,先要安装flex.bison.libpcap编译安装 解压红箭头的两个文件 tar -zxvpf iftop-0.16.tar.gz tar -zxvpf libpcap ...
- Python - 工具
Anaconda - 自带Conda,可以自定义环境 Pycharm zeal - API离线查看,类似于Dash
- 文件目录T位
场景: 共享目录设置T标志 可以看别人的文件,但不可以删除.修改别人的文件 除非是ROOT,目录的拥有者
- Assign the task-HDU3974 dfs序+线段树
题意: 一个公司有n个员工,每个员工都有一个上司,一个人下属的下属也是这个人的下属,因此可将他们的关系看成一棵树, 然后给定两种操作,C操作是查询当前员工的工作,T操作是将y工作分配给x员工,当一个人 ...