Solr5.5.1 IK中文分词配置与使用
前言
用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词。其中包含一个词典。 那么既然用到了这种国际化的框架,那么就避免不了中文分词。尤其是国内特殊行业比较多。比如油田系统从勘探、打井、投产等若干环节都涉及一些专业词汇。 再像电商,手机、手机配件、笔记本、笔记本配件之类。汽车,品牌、车系、车型等等,这一系列数据背后都涉及各自领域的专业名次,所以中文分词就最终的目的还是为了解决搜索结果的精确度和匹配度的问题。
IK搜索预览
我的univeral Core里包含两条数据,第二条数据的title和author都是中文的。 然后我用关键字q=title:平凡来搜索,搜索出来第二条数据。 如果你在你的索引库里没搜索出来也不要奇怪,配置下IK中文分词就可以了。
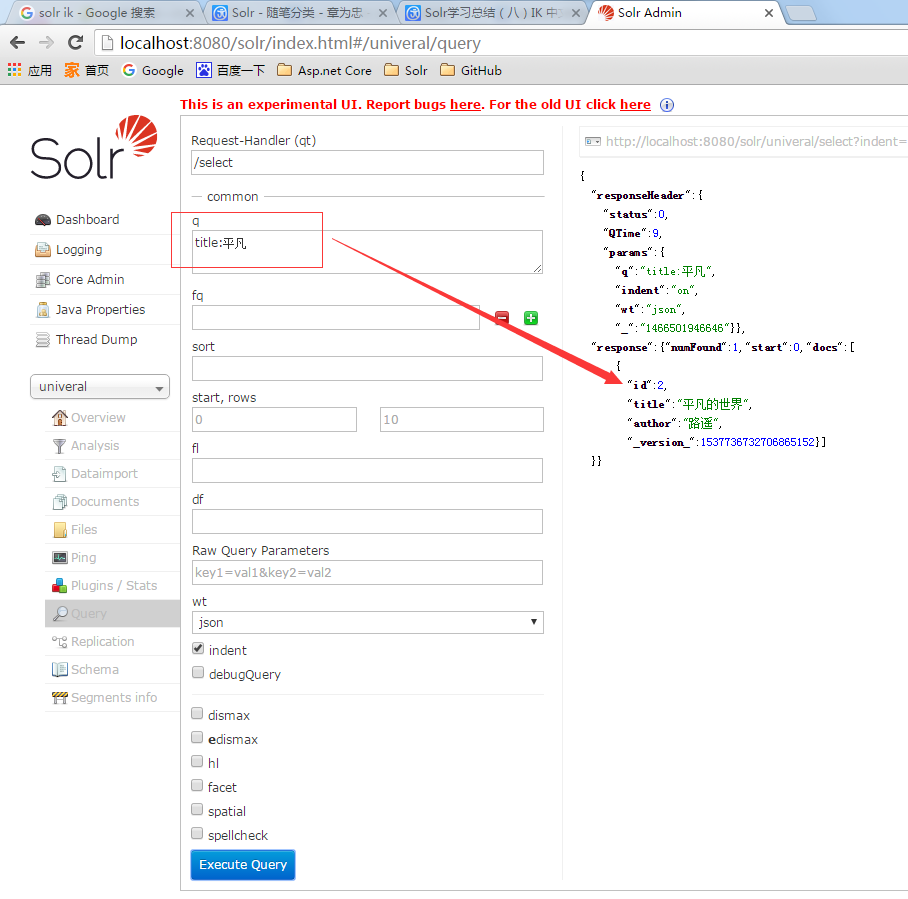
中文语义分析
在索引库Core左侧菜单Analysis中,你可以输入复杂的查询【关键字】,选择对应字段,点击【Analysis Values】会帮你分析出当前这个复杂的词组都会分解出那几个搜索关键字或关键词来。如果这里满足不了你的专业词汇,那就该从词典下手了。我这里输入了:平凡的世界。分析后得出两个词:平凡、世界。 也就是我在上一张图中用平凡搜索的结果。

中文分词的配置和使用
1、下载对应IK版本。我本地部署的Solr5.5.1。 所以就下载最新版本。
2、把ik目录下的文件复制到tomcat/webapps/solr/WEB-INF/lib目录下。 ik目录里有一个ext.dic、stopword.dic。 可以打开看一看里面内容。
3、修改schema.xml。我本地是univeral/conf/managed-schema。 增加中文分词配置节点,内容如下
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4、修改对应field的类型。我修改了两个字段
<field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
<field name="author" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
参考教程:http://www.cnblogs.com/zhangweizhong/p/5593909.html
备注
如果之前你已经创建了索引,那么配置IK中文分词后先修改schema.xml中的field对应类型。 清空索引后重新创建索引。 OK。大功搞成。
Solr5.5.1 IK中文分词配置与使用的更多相关文章
- Solr学习总结(八)IK 中文分词的配置和使用
最近,很多朋友问我solr 中文分词配置的问题,都不知道怎么配置,怎么使用,原以为很简单,没想到这么多朋友都有问题,所以今天就总结总结中文分词的配置吧. 有的时候,用户搜索的关键字,可能是一句话,不是 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器 安装环境:Jdk 1.8. windows 10 安装包准备: solr 各种版本集合下载:http://archive.apache.org/dist ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- Elasticsearch 5 Ik+pinyin分词配置详解
版权声明:本文为博主原创文章,地址:http://blog.csdn.net/napoay,转载请留言. 一.拼音分词的应用 拼音分词在日常生活中其实很常见,也许你每天都在用.打开淘宝看一看吧,输入拼 ...
- Elasticsearch入门和查询语法分析(ik中文分词)
全文搜索现在已经是很常见的功能了,当然你也可以用mysql加Sphinx实现.但开源的Elasticsearch(简称ES)目前是全文搜索引擎的首选.目前像GitHub.维基百科都使用的是ES,它可以 ...
随机推荐
- 在WPF中使用依赖注入的方式创建视图
在WPF中使用依赖注入的方式创建视图 0x00 问题的产生 互联网时代桌面开发真是越来越少了,很多应用都转到了浏览器端和移动智能终端,相应的软件开发上的新技术应用到桌面开发的文章也很少.我之前主要做W ...
- macOS 我的装机
最近多次配置 Mac 的开发环境,稍微记录一下 1 创建无付费信息的Apple ID 2 Xcode gem 源更改 3 Alfred 4 微信 5 SourceTree 6 Sublime Te ...
- Concepts:Request 和 Task
当SQL Server Engine 接收到Session发出的Request时,SQL Server OS将Request和Task绑定,并为Task分配一个Workder.在TSQL Query执 ...
- 【声明】前方不设坑位,不收费!~ 我为NET狂官方学习计划
发个通知,过段时间学习计划相关的东西就出来了,上次写了篇指引文章后有些好奇心颇重的人跟我说:“发现最近群知识库和技能库更新的频率有点大,这是要放大招的节奏啊!” 很多想学习却不知道如何规划的人想要一个 ...
- Unity3D 5.3 新版AssetBundle使用方案及策略
1.概览 Unity3D 5.0版本之后的AssetBundle机制和之前的4.x版本已经发生了很大的变化,一些曾经常用的流程已经不再使用,甚至一些老的API已经被新的API所取代. 因此,本文的主要 ...
- 开源一款简单清爽的日历组件,JavaScript版的
源码会在最后给出地址,需要的朋友自己去下载.最近项目需要做一个日程安排的功能,就是点击日历的某一天弹出一个录入页面,填完信息后保存当天的日程安排.有日程的日期会有不同的标记(比如加一个背景色啥的).网 ...
- 【云知道】究极秒杀Loadrunner乱码
Loadrunner乱码一击必杀 之前有介绍一些简单的针对Loadrunner脚本或者调试输出内容中乱码的一些设置,但是并没能完全解决一些小伙伴的问题,因为那些设置实在能力有限,还是有很多做不到的事情 ...
- 在centos7中添加一个新用户,并授权
前言 笔记本装了一个centos,想要让别人也可以登录访问,用自己的账号确实不太好,于是准备新建一个用户给他. 创建新用户 创建一个用户名为:zhangbiao [root@localhost ~]# ...
- Asp.Net Core + Dapper + Repository 模式 + TDD 学习笔记
0x00 前言 之前一直使用的是 EF ,做了一个简单的小项目后发现 EF 的表现并不是很好,就比如联表查询,因为现在的 EF Core 也没有啥好用的分析工具,所以也不知道该怎么写 Linq 生成出 ...
- linux下 lvm 磁盘扩容
打算给系统装一个oracle,发现磁盘空间不足.在安装系统的时候我选择的是自动分区,系统就会自动以LVM的方式分区.为了保证系统后期的可用性,建议所有新系统安装都采用LVM,之后生产上的设备我也打算这 ...