Andrew Ng机器学习公开课笔记 -- Generative Learning algorithms
网易公开课,第5课
notes,http://cs229.stanford.edu/notes/cs229-notes2.pdf
学习算法有两种,一种是前面一直看到的,直接对p(y|x; θ)进行建模,比如前面说的线性回归或逻辑回归,这种称为判别学习算法(discriminative learning algorithms)
另外一种思路,就是这里要谈的,称为生成学习算法(generative learning algorithms),区别在于不会直接对p(y|x; θ)进行建模,而是对p(x|y) (and p(y))进行建模,然后用bayes定理算出p(y|x) 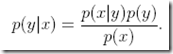
不像判别方法,给定x就能通过训练的模型算出结果
比如逻辑回归中,通过 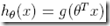
而生成学习算法的思路是这样的,由于需要对p(x|y)进行建模,x是连续的,但对于分类问题y是离散的,比如取值0或1
我们做的是,分别对每种y的情况进行建模,比如判断垃圾邮件,那么分别对垃圾和正常邮件进行建模,得到
p(x|y = 0) models 和 p(x|y = 1) models
而p(y) (called the class priors)往往是比较容易算出的
当来一个新的x时,需要计算每个y的p(y|x),并且取概率最大的那个y
这里由于只需要比较大小,p(x)对于大家都是一样的,不需要算
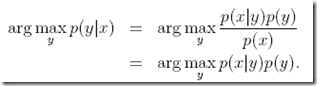
所以对于任意生成学习算法,关键就是要学习出
p(x|y = 0) models 和 p(x|y = 1) models
Gaussian discriminant analysis
首先学习的一个生成算法就是GDA,高斯判别分析
不解为何生成算法要叫判别。。。
多项高斯分布
对于这个算法,首先要假设p(x|y)符合多项高斯分布(multivariate normal distribution),区别于一般的高斯分布,参数μ是一维的,而多项高斯分布参数是n维的 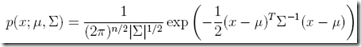
其中, 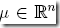 ,mean vector,是个n维的向量
,mean vector,是个n维的向量  ,covariance matrix,是个n×n的矩阵
,covariance matrix,是个n×n的矩阵
关于这个分布,课件里面讲的很详细,还有很多图,参考课件吧
其实只要知道这个分布也是一个bell-shape curve,μ会影响bell的位置(平移)
而covariance matrix会影响bell的高矮,扁圆的形状
The Gaussian Discriminant Analysis model
继续讲这个模型
前面说了对于生成学习算法,关键就是要找出p(x|y = 0),p(x|y = 1)和p(y) 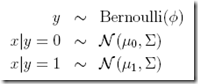
好理解吗,y取值0或1,一定是伯努利分布,而p(x|y)根据前面假设一定是符合多项高斯分布,所以有 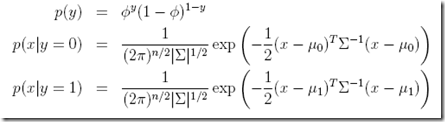
现在问题是要根据训练集,学习出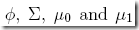
怎么学?最大似然估计
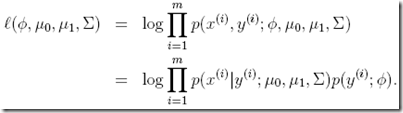
这里和判别学习算法不同,
判别学习算法,对p(y|x; θ)进行建模,所以称为conditional似然估计
而生成学习算法,是对于p(x|y)*p(y),即p(x,y)进行建模,所以称为joint似然估计
使用最优化算法计算maximizing ℓ,得到参数如下(计算过程略去) 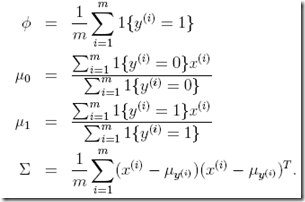
虽然没有写计算过程,但是得到的这个结果是reasonable的
φ就是y=1的概率,算出的结果就是在训练集中y=1的比例
μ0,μ1,结果是训练集中y=0(或y=1)时x的均值,都很合理
计算出这些参数,我们就得到p(x|y = 0),p(x|y = 1)和p(y),然后可以使用上面的方法就行预测
Discussion: GDA and logistic regression
这里有个很有趣的结论
We just argued that if p(x|y) is multivariate gaussian (with shared ), then p(y|x) necessarily follows a logistic function. The converse, however, is not true;
当p(x|y)满足multivariate gaussian的时候,p(y|x)一定是logistic function,但反之不成立。
使用视频中的截图,更容易理解 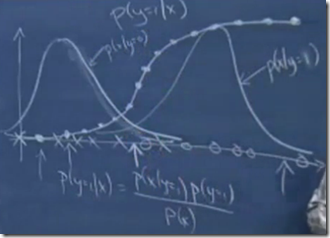
图中,叉表示y=0的点,圈表示y=1的点
所以对于y=0和y=1分别建模,就得到两边的两个bell-shaped的高斯曲线
这时如果要画出p(y=1|x),就得到中间的sigmod曲线
越靠左y=1的概率越小,越靠右y=1的概率越接近1,在中间两个曲线交界的地方,y=1的概率为0.5
非常形象的说明为什么p(y|x)会是一个logistic function
更酷的是,这个结论可以推广到任何指数族分布,即任何广义线性模型的分布
那么这里产生的问题就是,我们为什么需要GDA,直接使用逻辑回归不可以吗?
两者区别在于,
GDA比逻辑回归做出更强的假设,因为前面的结论是不可逆的
所以当数据p(x|y)确实或近似符合高斯分布时,GDA更有效,并且需要更少的训练数据就可以达到很好的效果
但是在实际中,其实你很难确定这点,
这时逻辑回归有更好的鲁棒性,比如如果p(x|y)符合泊松分布,而你误认为符合高斯分布,而使用GDA,那么效果就会不太好
而逻辑回归,对数据做出的假设比较少,只要p(x|y)指数族分布,都会有比较好的效果,当然逻辑回归需要的训练数据也是比较多的
这里其实就是一个balance
模型假设强弱和训练数据量之间的权衡
如果你明确知道符合高斯分布,那么用比较少的训练数据,使用GDA就很好
如果不确定,就使用逻辑回归,用比较多的训练数据
Andrew Ng机器学习公开课笔记 -- Generative Learning algorithms的更多相关文章
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
- Andrew Ng机器学习公开课笔记 -- Online Learning
网易公开课,第11课 notes,http://cs229.stanford.edu/notes/cs229-notes6.pdf 和之前看到的batch learning算法不一样,batch ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Andrew Ng机器学习公开课笔记 -- 支持向量机
网易公开课,第6,7,8课 notes,http://cs229.stanford.edu/notes/cs229-notes3.pdf SVM-支持向量机算法概述, 这篇讲的挺好,可以参考 先继 ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降
网易公开课,监督学习应用.梯度下降 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 线性回归(Linear Regression) 先看个 ...
- Andrew Ng机器学习公开课笔记 -- Logistic Regression
网易公开课,第3,4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面讨论了线性回归问题, 符合高斯分布,使用最小二乘来作为损失函数 ...
随机推荐
- C#控件方法及属性大全,望补充
C#控件及常用设计整理 1.窗体 常用属性 (1)Name属性:用来获取或设置窗体的名称,在应用程序中可通过Name属性来引用窗体. (2) WindowState属性: 用来获取或设置窗体的窗口状态 ...
- linux中nmcli命令详解
https://www.iyunv.com/thread-269695-1-1.html http://www.178linux.com/44668
- 第三章 Spring.Net 环境准备和搭建
在前面一章我们介绍了依赖注入,控制反转的概念.接下来我们来真正动手搭建一下Spring.Net的环境,看一下Spring.Net 中的控制反转和依赖注入是什么样子. 3.1 Spring.Net 下 ...
- Effective C++ Item 35 Consider alternatives to virtual functions
考虑你正在为游戏人物设计一个继承体系, 人物有一个函数叫做 healthValue, 他会返回一个整数, 表示人物的健康程度. 由于不同的人物拥有不同的方式计算他们的健康指数, 将 healthVal ...
- java中Date的使用情况
在开发中常使用情况. 1.将String转为date 例如"201604131630" //设置日期格式 public SimpleDateFormat sdf = new Si ...
- 怎么下载tomcat的其他版本
下载地址: http://archive.apache.org/dist/tomcat/ 里面包含tomcat的各个版本,windows版本.linux版本,tomcat7.0.x等.
- Android使用百度定位API时获取的地址信息为null
option.setAddrType("all"); //加上这个配置后才可以取到详细地址信息
- Android中开发习惯
我觉得首先是命名规范.命名规范这种东西每个人都有自己的风格,Google 也有自己的一套规范(多看看 Android 系统源码就明白了).好的规范可以有效地提高代码的可读性,对于将来接手代码的小伙伴也 ...
- NUC970 U-Boot 使用說明
U-Boot 使用說明U-Boot 是一個主要用於嵌入式系統的開機載入程式, 可以支援多種不同的計算機系統結構, 包括ARM.MIPS.x86與 68K. 這也是一套在GNU通用公共許可證之下發布的自 ...
- COM组件技术名称解释
GUID:全局唯一标识. CLSID 或 ProgID :唯一地表示一个组件服务程序,那么根据这些ID,就可以加载运行组件,并为客户端程序提供服务了. IID :唯一的表示接口ID. COM 组件是运 ...