使用 Apache Atlas 进行数据治理
本文由 网易云发布。
作者:网易/刘勋(本篇文章仅限知乎内部分享,如需转载,请取得作者同意授权。)
面对海量且持续增加的各式各样的数据对象,你是否有信心知道哪些数据从哪里来以及它如何随时间而变化?采用Hadoop必须考虑数据管理的实际情况,元数据与数据治理成为企业级数据湖的重要部分。
为寻求数据治理的开源解决方案,Hortonworks 公司联合其他厂商与用户于2015年发起数据治理倡议,包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理等方面。Apache Atlas 项目就是这个倡议的结果,社区伙伴持续的为该项目提供新的功能和特性。该项目用于管理共享元数据、数据分级、审计、安全性以及数据保护等方面,努力与Apache Ranger整合,用于数据权限控制策略。
Atlas 是一个可扩展和可扩展的核心基础治理服务集 - 使企业能够有效地和高效地满足 Hadoop 中的合规性要求,并允许与整个企业数据生态系统的集成。
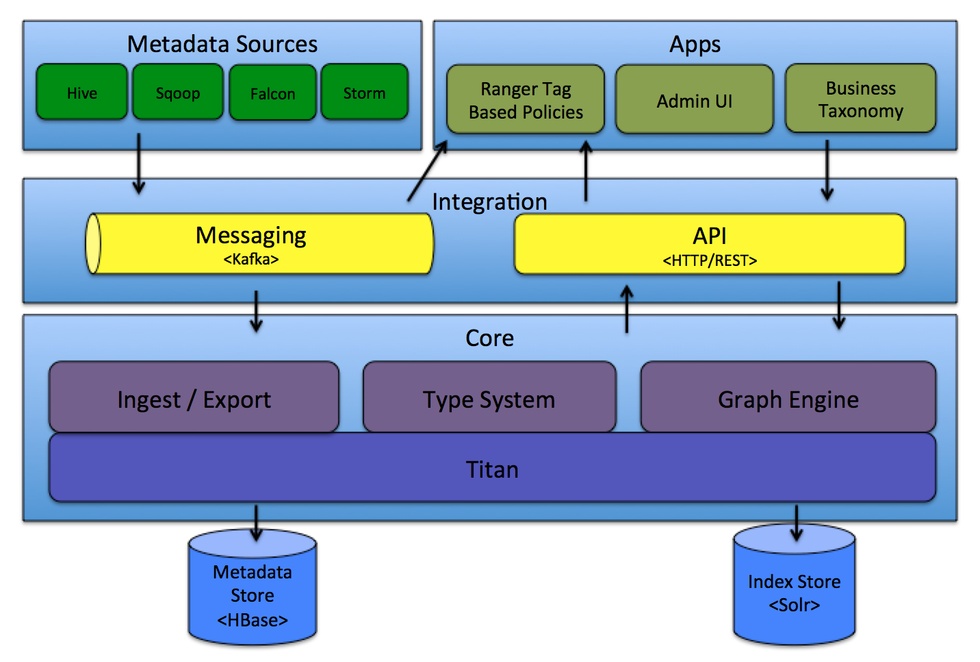
Atlas 的组件可以分为以下主要类别:
Core
此类别包含实现 Atlas 功能核心的组件,包括:
Type System:Atlas 允许用户为他们想要管理的元数据对象定义一个模型。该模型由称为 "类型" 的定义组成。"类型" 的 实例被称为 "实体" 表示被管理的实际元数据对象。类型系统是一个组件,允许用户定义和管理类型和实体。由 Atlas 管理的所有元数据对象(例如Hive表)都使用类型进行建模,并表示为实体。要在 Atlas 中存储新类型的元数据,需要了解类型系统组件的概念。
需要注意的一个关键点是,Atlas 中建模的通用性质允许数据管理员和集成者定义技术元数据和业务元数据。也可以使用 Atlas 的特征来定义两者之间的丰富关系。
Ingest / Export:Ingest 组件允许将元数据添加到 Atlas。类似地,Export 组件暴露由 Atlas 检测到的元数据更改,以作为事件引发,消费者可以使用这些更改事件来实时响应元数据更改。
Graph Engine :在内部,Atlas 通过使用图形模型管理元数据对象。以实现元数据对象之间的巨大灵活性和丰富的关系。图形引擎是负责在类型系统的类型和实体之间进行转换的组件,以及基础图形模型。除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便有效地搜索它们。
Titan:目前,Atlas 使用 Titan 图数据库来存储元数据对象。 Titan 使用两个存储:默认情况下元数据存储配置为 HBase ,索引存储配置为 Solr。也可以通过构建相应的配置文件将元数据存储作为 BerkeleyDB 和 Index 存储使用为 ElasticSearch。元数据存储用于存储元数据对象本身,并且索引存储用于存储元数据属性的索引,其允许高效搜索。
Integration
用户可以使用两种方法管理 Atlas 中的元数据:
API:Atlas 的所有功能通过 REST API 提供给最终用户,允许创建,更新和删除类型和实体。它也是查询和发现通过 Atlas 管理的类型和实体的主要方法。
Messaging:除了 API 之外,用户还可以选择使用基于 Kafka 的消息接口与 Atlas 集成。这对于将元数据对象传输到 Atlas 以及从 Atlas 使用可以构建应用程序的元数据更改事件都非常有用。如果希望使用与 Atlas 更松散耦合的集成,这可以允许更好的可扩展性,可靠性等,消息传递接口是特别有用的。Atlas 使用 Apache Kafka 作为通知服务器用于钩子和元数据通知事件的下游消费者之间的通信。事件由钩子和 Atlas 写到不同的 Kafka 主题。
元数据源
Atlas 支持与许多元数据源的集成。将来还会添加更多集成。目前,Atlas 支持从以下来源获取和管理元数据:
与其它元数据源集成意味着两件事:有一些元数据模型,Atlas 定义本机来表示这些组件的对象。 Atlas 提供了从这些组件中通过实时或批处理模式获取元数据对象的组件。
Apps
由 Atlas 管理的元数据各种应用程序使用,满足许多治理用例。
Atlas Admin UI:该组件是一个基于 Web 的应用程序,允许数据管理员和科学家发现和注释元数据。这里最重要的是搜索界面和 SQL 样的查询语言,可以用来查询由 Atlas 管理的元数据类型和对象。管理 UI 使用 Atlas 的 REST API 来构建其功能。
Tag Based Policies:Apache Ranger 是针对 Hadoop 生态系统的高级安全管理解决方案,与各种 Hadoop 组件具有广泛的集成。通过与 Atlas 集成,Ranger 允许安全管理员定义元数据驱动的安全策略,以实现有效的治理。 Ranger 是由 Atlas 通知的元数据更改事件的消费者。
Business Taxonomy:从元数据源获取到 Atlas 的元数据对象主要是一种技术形式的元数据。为了增强可发现性和治理能力,Atlas 提供了一个业务分类界面,允许用户首先定义一组代表其业务域的业务术语,并将其与 Atlas 管理的元数据实体相关联。业务分类法是一种 Web 应用程序,目前是 Atlas Admin UI 的一部分,并且使用 REST API 与 Atlas 集成。
Type System
Overview
Atlas 允许用户为他们想要管理的元数据对象定义一个模型。该模型由称为 "类型" 的定义组成。被称为 "实体" 的 "类型" 实例表示被管理的实际元数据对象。类型系统是一个组件,允许用户定义和管理类型和实体。由 Atlas 管理的所有元数据对象(例如Hive表)都使用类型进行建模,并表示为实体。要在Atlas中存储新类型的元数据,需要了解类型系统组件的概念。
Types
Atlas中的 "类型" 定义了如何存储和访问特定类型的元数据对象。类型表示了所定义元数据对象的一个或多个属性集合。具有开发背景的用户可以将 "类型" 理解成面向对象的编程语言的 "类" 定义的或关系数据库的 "表模式"。
与 Atlas 本地定义的类型的示例是 Hive 表。 Hive 表用这些属性定义:
Name: hive_table
MetaType: Class
SuperTypes: DataSet
Attributes:
name: String (name of the table)
db: Database object of type hive_db
owner: String
createTime: Date
lastAccessTime: Date
comment: String
retention: int
sd: Storage Description object of type hive_storagedesc
partitionKeys: Array of objects of type hive_column
aliases: Array of strings
columns: Array of objects of type hive_column
parameters: Map of String keys to String values
viewOriginalText: String
viewExpandedText: String
tableType: String
temporary: Boolean
从上面的例子可以注意到以下几点:
Atlas中的类型由 "name" 唯一标识,
类型具有元类型。元类型表示 Atlas 中此模型的类型。 Atlas 有以下几种类型:
基本元类型: Int,String,Boolean等。
枚举元类型
集合元类型:例如Array,Map
复合元类型:Class,Struct,Trait
类型可以从称为 "supertype" 的父类型 "extend" - 凭借这一点,它将包含在 "supertype" 中定义的属性。这允许模型在一组相关类型等之间定义公共属性。这再次类似于面向对象语言如何定义类的超类的概念。 Atlas 中的类型也可以从多个超类型扩展。
在该示例中,每个 hive 表从预定义的超类型(称为 "DataSet")扩展。稍后将提供关于此预定义类型的更多细节。
具有 "Class","Struct" 或 "Trait" 的元类型的类型可以具有属性集合。每个属性都有一个名称(例如 "name")和一些其他关联的属性。可以使用表达式 type_name.attribute_name 来引用属性。还要注意,属性本身是使用 Atlas 元类型定义的。
在这个例子中,hive_table.name 是一个字符串,hive_table.aliases 是一个字符串数组,hive_table.db 引用一个类型的实例称为 hive_db 等等。
在属性中键入引用(如hive_table.db)。使用这样的属性,我们可以在 Atlas 中定义的两种类型之间的任意关系,从而构建丰富的模型。注意,也可以收集一个引用列表作为属性类型(例如 hive_table.cols,它表示从 hive_table 到 hive_column 类型的引用列表)
Entities
Atlas中的 "实体" 是类 "类型" 的特定值或实例,因此表示真实世界中的特定元数据对象。 回顾我们的面向对象编程语言的类比,"实例" 是某个 "类" 的 "对象"。
实体的示例将是特定的 Hive 表。 说 "Hive" 在 "默认" 数据库中有一个名为 "customers" 的表。 此表将是类型为 hive_table 的 Atlas 中的 "实体"。 通过作为类类型的实例,它将具有作为 Hive 表 "类型" 的一部分的每个属性的值,例如:
id: "9ba387dd-fa76-429c-b791-ffc338d3c91f"
typeName: “hive_table”
values:
name: "customers"
db: "b42c6cfc-c1e7-42fd-a9e6-890e0adf33bc"
owner: "admin"
createTime: "2016-06-20T06:13:28.000Z"
lastAccessTime: "2016-06-20T06:13:28.000Z"
comment: null
retention: 0
sd: "ff58025f-6854-4195-9f75-3a3058dd8dcf"
partitionKeys: null
aliases: null
columns: ["65e2204f-6a23-4130-934a-9679af6a211f", "d726de70-faca-46fb-9c99-cf04f6b579a6", ...]
parameters: {"transient_lastDdlTime": "1466403208"}
viewOriginalText: null
viewExpandedText: null
tableType: "MANAGED_TABLE"
temporary: false
从上面的例子可以注意到以下几点:
作为 Class Type 实例的每个实体都由唯一标识符 GUID 标识。此 GUID 由 Atlas 服务器在定义对象时生成,并在实体的整个生命周期内保持不变。在任何时间点,可以使用其 GUID 来访问该特定实体。
在本示例中,默认数据库中的 "customers" 表由GUID "9ba387dd-fa76-429c-b791-ffc338d3c91f" 唯一标识
实体具有给定类型,并且类型的名称与实体定义一起提供。
在这个例子中,"customers" 表是一个 "hive_table"。
此实体的值是所有属性名称及其在 hive_table 类型定义中定义的属性的值的映射。
属性值将根据属性的元类型。
基本元类型:整数,字符串,布尔值。例如。 'name'='customers','Temporary'='false'
集合元类型:包含元类型的值的数组或映射。例如。 parameters = {"transient_lastDdlTime":"1466403208"}
复合元类型:对于类,值将是与该特定实体具有关系的实体。例如。hive 表 "customers" 存在于称为 "default" 的数据库中。
表和数据库之间的关系通过 "db" 属性捕获。因此,"db" 属性的值将是一个唯一标识 hive_db 实体的 GUID,称为 "default"对于实体的这个想法,我们现在可以看到 Class 和 Struct 元类型之间的区别。类和结构体都组成其他类型的属性。但是,类类型的实体具有 Id 属性(具有GUID值)并且可以从其他实体引用(如 hive_db 实体从 hive_table 实体引用)。 Struct 类型的实例没有自己的身份,Struct 类型的值是在实体本身内嵌入的属性的集合。
Attributes
我们已经看到属性在复合元类型(如 Class 和 Struct)中定义。 但是我们简单地将属性称为具有名称和元类型值。 然而, Atlas 中的属性还有一些属性,定义了与类型系统相关的更多概念。
属性具有以下属性:
name: string,
dataTypeName: string,
isComposite: boolean,
isIndexable: boolean,
isUnique: boolean,
multiplicity: enum,
reverseAttributeName: string
以上属性具有以下含义:
name - 属性的名称
dataTypeName - 属性的元类型名称(本机,集合或复合)
isComposite - 是否复合
此标志指示建模的一个方面。如果一个属性被定义为复合,它意味着它不能有一个生命周期与它所包含的实体无关。这个概念的一个很好的例子是构成 hive 表一部分的一组列。由于列在 hive 表之外没有意义,它们被定义为组合属性。
必须在 Atlas 中创建复合属性及其所包含的实体。即,必须与 hive 表一起创建 hive 列。
isIndexable - 是否索引
此标志指示此属性是否应该索引,以便可以使用属性值作为谓词来执行查找,并且可以有效地执行查找。
isUnique - 是否唯一
此标志再次与索引相关。如果指定为唯一,这意味着为 Titan 中的此属性创建一个特殊索引,允许基于等式的查找。
具有此标志的真实值的任何属性都被视为主键,以将此实体与其他实体区分开。因此,应注意确保此属性在现实世界中模拟独特的属性。
例如,考虑 hive_table 的 name 属性。孤立地,名称不是 hive_table 的唯一属性,因为具有相同名称的表可以存在于多个数据库中。如果 Atlas 在多个集群中存储 hive 表的元数据,即使一对(数据库名称,表名称)也不是唯一的。只有集群位置,数据库名称和表名称可以在物理世界中被视为唯一。
multiplicity - 指示此属性是(必需的/可选的/还是可以是多值)的。如果实体的属性值的定义与类型定义中的多重性声明不匹配,则这将是一个约束违反,并且实体添加将失败。因此,该字段可以用于定义元数据信息上的一些约束。
使用上面的内容,让我们扩展下面的 hive 表的属性之一的属性定义。让我们看看称为 "db" 的属性,它表示 hive 表所属的数据库:
db:
"dataTypeName": "hive_db",
"isComposite": false,
"isIndexable": true,
"isUnique": false,
"multiplicity": "required",
"name": "db",
"reverseAttributeName": null
注意多重性的 "multiplicity" = "required" 约束。 如果没有 db 引用,则不能发送表实体。
columns:
"dataTypeName": "array<hive_column>",
"isComposite": true,
"isIndexable": true,
“isUnique": false,
"multiplicity": "optional",
"name": "columns",
"reverseAttributeName": null
请注意列的 "isComposite" = true 值。通过这样做,我们指示定义的列实体应该始终绑定到它们定义的表实体。
从这个描述和示例中,您将能够意识到属性定义可以用于影响 Atlas 系统要执行的特定建模行为(约束,索引等)。
系统特定类型及其意义
Atlas 提供了一些预定义的系统类型。我们在前面的章节中看到了一个例子(DataSet)。在本节中,我们将看到所有这些类型并了解它们的意义。
Referenceable:此类型表示可使用名为 qualifiedName 的唯一属性搜索的所有实体。
Asset:此类型包含名称,说明和所有者等属性。名称是必需属性(multiplicity = required),其他是可选的。可引用和资源的目的是为定型器提供在定义和查询其自身类型的实体时强制一致性的方法。拥有这些固定的属性集允许应用程序和用户界面基于约定基于默认情况下他们可以期望的属性的假设。
Infrastructure:此类型扩展了可引用和资产,通常可用于基础设施元数据对象(如群集,主机等)的常用超类型。
DataSet:此类型扩展了可引用和资产。在概念上,它可以用于表示存储数据的类型。在 Atlas 中,hive表,Sqoop RDBMS表等都是从 DataSet 扩展的类型。扩展 DataSet 的类型可以期望具有模式,它们将具有定义该数据集的属性的属性。例如, hive_table 中的 columns 属性。另外,扩展 DataSet 的实体类型的实体参与数据转换,这种转换可以由 Atlas 通过 lineage(或 provenance)生成图形。
Process:此类型扩展了可引用和资产。在概念上,它可以用于表示任何数据变换操作。例如,将原始数据的 hive 表转换为存储某个聚合的另一个 hive 表的 ETL 过程可以是扩展过程类型的特定类型。流程类型有两个特定的属性,输入和输出。输入和输出都是 DataSet 实体的数组。因此,Process 类型的实例可以使用这些输入和输出来捕获 DataSet 的 lineage 如何演变。
Search
Atlas 支持以下 2 种方式搜索元数据:
Search using DSL
Full-text search
Hive Model
默认 hive 建模在 org.apache.atlas.hive.model.HiveDataModelGenerator 中可用。 它定义以下类型:
hive_db(ClassType) - super types [Referenceable] - attributes [name, clusterName, description, locationUri, parameters, ownerName, ownerType]
hive_storagedesc(ClassType) - super types [Referenceable] - attributes [cols, location, inputFormat, outputFormat, compressed, numBuckets, serdeInfo, bucketCols, sortCols, parameters, storedAsSubDirectories]
hive_column(ClassType) - super types [Referenceable] - attributes [name, type, comment, table]
hive_table(ClassType) - super types [DataSet] - attributes [name, db, owner, createTime, lastAccessTime, comment, retention, sd, partitionKeys, columns, aliases, parameters, viewOriginalText, viewExpandedText, tableType, temporary]
hive_process(ClassType) - super types [Process] - attributes [name, startTime, endTime, userName, operationType, queryText, queryPlan, queryId]
hive_principal_type(EnumType) - values [USER, ROLE, GROUP]
hive_order(StructType) - attributes [col, order]
hive_serde(StructType) - attributes [name, serializationLib, parameters]
使用唯一的限定名称创建和去重复实体。它们提供命名空间,也可以用于 query/lineage。请注意,dbName,tableName 和 columnName 应为小写。 clusterName 解释如下。
hive_db - attribute qualifiedName - <dbName>@<clusterName>
hive_table - attribute qualifiedName - <dbName>.<tableName>@<clusterName>
hive_column - attribute qualifiedName - <dbName>.<tableName>.<columnName>@<clusterName>
hive_process - attribute name - <queryString> - 小写的修剪查询字符串
导入 Hive Metadata
org.apache.atlas.hive.bridge.HiveMetaStoreBridge 使用 org.apache.atlas.hive.model.HiveDataModelGenerator 中定义的模型将 Hive 元数据导入 Atlas。 import-hive.sh 命令可以用来方便这一点。脚本需要 Hadoop 和 Hive 类路径 jar。 对于 Hadoop jar,请确保环境变量 HADOOP_CLASSPATH 已设置。另一种方法是将 HADOOP_HOME 设置为指向 Hadoop 安装的根目录同样,对于 Hive jar,将 HIVE_HOME 设置为 Hive 安装的根目录将环境变量 HIVE_CONF_DIR 设置为 Hive 配置目录复制 ${atlas-conf}/atlas-application.properties 到 hive conf 目录
Usage: <atlas package>/hook-bin/import-hive.sh
日志位于 ${atlas package}/logs/import-hive.log
如果要在 kerberized 集群中导入元数据,则需要运行以下命令:
<atlas package>/hook-bin/import-hive.sh -Dsun.security.jgss.debug=true -Djavax.security.auth.useSubjectCredsOnly=false -Djava.security.krb5.conf=[krb5.conf location] -Djava.security.auth.login.config=[jaas.conf location]
krb5.conf is typically found at /etc/krb5.conf
for details about jaas.conf and a suggested location see the atlas security documentation
Hive Hook
Hive 在使用 hive hook 的 hive 命令执行上支持侦听器。 这用于在 Atlas 中使用 org.apache.atlas.hive.model.HiveDataModelGenerator 中定义的模型添加/更新/删除实体。 hive hook 将请求提交给线程池执行器,以避免阻塞命令执行。 线程将实体作为消息提交给通知服务器,并且服务器读取这些消息并注册实体。 按照 hive 设置中的这些说明为 Atlas 添加 hive hook :
Set-up atlas hook in hive-site.xml of your hive configuration:
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
<property>
<name>atlas.cluster.name</name>
<value>primary</value>
</property>
Add 'export HIVE_AUX_JARS_PATH=<atlas package>/hook/hive' in hive-env.sh of your hive configuration
Copy <atlas-conf>/atlas-application.properties to the hive conf directory.
在<atlas-conf> /atlas-application.properties中的以下属性控制线程池和通知详细信息:
atlas.hook.hive.synchronous - boolean,true来同步运行钩子。 默认false。 建议设置为false,以避免 hive 查询完成中的延迟。
atlas.hook.hive.numRetries - 通知失败的重试次数。 默认值 3
atlas.hook.hive.minThreads - 核心线程数。 默认值 5
atlas.hook.hive.maxThreads - 最大线程数。 默认值 5
atlas.hook.hive.keepAliveTime - 保持活动时间以毫秒为单位。 默认 10
atlas.hook.hive.queueSize - 线程池的队列大小。 默认 10000
参考 Configuration 通知相关配置
Column Level Lineage
从 atlas-0.8-incubating 版本开始,在 Atlas 中捕获列 lineage
Model
ColumnLineageProcess 类型是 Process 的子类
这将输出列与一组输入列或输入表相关联
Lineage 还捕获 Dependency 的类型:当前的值是 SIMPLE,EXPRESSION,SCRIPT
SIMPLE依赖: 意味着输出列具有与输入相同的值
EXPRESSION依赖: 意味着输出列被输入列上的运行时中的一些表达式(例如Hive SQL表达式)转换。
SCRIPT依赖: 表示输出列由用户提供的脚本转换。
在 EXPRESSION 依赖的情况下,表达式属性包含字符串形式的表达式
由于 Process 链接输入和输出 DataSet,我们使 Column 成为 DataSet 的子类
Examples
对于下面的简单 CTAS:
create table t2 as select id, name from T1
lineage 为
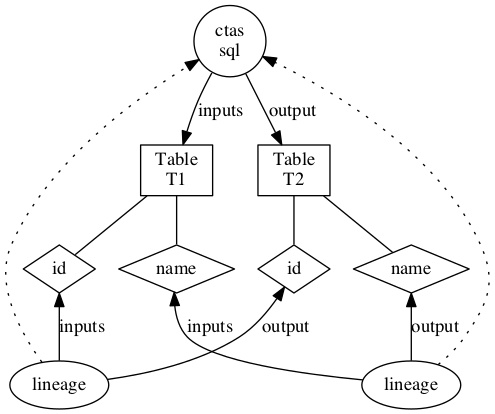
Extracting Lineage from Hive commands
HiveHook 将 HookContext 中的 LineageInfo 映射到 Column lineage 实例
Hive 中的 LineageInfo 为最终的 FileSinkOperator 提供 Column lineage ,将它们链接到 Hive 查询中的输入列
NOTE
在将 HIVE-13112 的补丁应用于 Hive 源之后,列级别 lineage 与 Hive 版本1.2.1配合使用
Limitations
由于数据库名,表名和列名在 hive 中不区分大小写,因此实体中的对应名称为小写。 因此,任何搜索 API 都应该在查询实体名称时使用小写
以下 hive 操作由 hive hook 当前捕获
create database
create table/view, create table as select
load, import, export
DMLs (insert)
alter database
alter table (skewed table information, stored as, protection is not supported)
alter view
Sqoop Atlas Bridge
Sqoop Model
默认的 Sqoop 建模在 org.apache.atlas.sqoop.model.SqoopDataModelGenerator 中可用。 它定义以下类型:
sqoop_operation_type(EnumType) - values [IMPORT, EXPORT, EVAL]
sqoop_dbstore_usage(EnumType) - values [TABLE, QUERY, PROCEDURE, OTHER]
sqoop_process(ClassType) - super types [Process] - attributes [name, operation, dbStore, hiveTable, commandlineOpts, startTime, endTime, userName]
sqoop_dbdatastore(ClassType) - super types [DataSet] - attributes [name, dbStoreType, storeUse, storeUri, source, description, ownerName]
使用唯一的限定名称创建和去重复实体。 它们提供命名空间,也可以用于查询:sqoop_process - attribute name - sqoop-dbStoreType-storeUri-endTime sqoop_dbdatastore - attribute name - dbStoreType-connectorUrl-source
Sqoop Hook
Sqoop 添加了一个 SqoopJobDataPublisher,在完成导入作业后将数据发布到 Atlas。 现在 sqoopHook 只支持hiveImport。 这用于使用 org.apache.atlas.sqoop.model.SqoopDataModelGenerator 中定义的模型在 Atlas 中添加实体。 按照 sqoop 设置中的以下说明在 ${sqoop-conf}/sqoop-site.xml 中为 Atlas 添加 sqoop 钩子:
Sqoop Job publisher class. Currently only one publishing class is supported
sqoop.job.data.publish.class org.apache.atlas.sqoop.hook.SqoopHook
Atlas cluster name
atlas.cluster.name
复制 ${atlas-conf}/atlas-application.properties 到 sqoop 的配置文件夹 ${sqoop-conf}/
Link ${atlas-home}/hook/sqoop/*.jar in sqoop libRefer Configuration for notification related configurations
Limitations
目前 sqoop hook 只支持 hiveImport 这一种 sqoop 操作
Falcon Atlas Bridge
Falcon Model
默认的falcon建模在 org.apache.atlas.falcon.model.FalconDataModelGenerator. 它可以定义以下类型:
falcon_cluster(ClassType) - super types [Infrastructure] - attributes [timestamp, colo, owner, tags]
falcon_feed(ClassType) - super types [DataSet] - attributes [timestamp, stored-in, owner, groups, tags]
falcon_feed_creation(ClassType) - super types [Process] - attributes [timestamp, stored-in, owner]
falcon_feed_replication(ClassType) - super types [Process] - attributes [timestamp, owner]
falcon_process(ClassType) - super types [Process] - attributes [timestamp, runs-on, owner, tags, pipelines, workflow-properties]
为 falcon 进程定义的每个集群创建一个 falcon_process 实体。
使用唯一的 qualifiedName 属性创建和去重复实体。 它们提供命名空间,也可以用于查询/沿袭。 唯一的属性是:
falcon_process - <process name>@<cluster name>
falcon_cluster - <cluster name>
falcon_feed - <feed name>@<cluster name>
falcon_feed_creation - <feed name>
falcon_feed_replication - <feed name>
Falcon Hook
Falcon 支持在 falcon 实体提交上的侦听器。 这用于在 Atlas 中使用 org.apache.atlas.falcon.model.FalconDataModelGenerator 中定义的模型添加实体。 hook 将请求提交给线程池执行器,以避免阻塞命令执行。 线程将实体作为消息提交给通知服务器,并且服务器读取这些消息并注册实体。
Add 'org.apache.atlas.falcon.service.AtlasService' to application.services in ${falcon-conf}/startup.properties
Link falcon hook jars in falcon classpath - 'ln -s atlas−home/hook/falcon/∗{falcon-home}/server/webapp/falcon/WEB-INF/lib/'
In ${falcon_conf}/falcon-env.sh, set an environment variable as follows:
export FALCON_SERVER_OPTS="<atlas_home>/hook/falcon/*:$FALCON_SERVER_OPTS"
The following properties in ${atlas-conf}/atlas-application.properties control the thread pool and notification details:
atlas.hook.falcon.synchronous - boolean, true to run the hook synchronously. default false
atlas.hook.falcon.numRetries - number of retries for notification failure. default 3
atlas.hook.falcon.minThreads - core number of threads. default 5
atlas.hook.falcon.maxThreads - maximum number of threads. default 5
atlas.hook.falcon.keepAliveTime - keep alive time in msecs. default 10
atlas.hook.falcon.queueSize - queue size for the threadpool. default 10000
Refer Configuration for notification related configurations
Limitations
在 falcon 集群实体中,使用的集群名称应该跨诸如 hive,falcon,sqoop 等组件是统一的。如果与 ambari 一起使用,则应该使用 ambari 集群名称用于集群实体
Storm Atlas Bridge
Introduction
Apache Storm 是一个分布式实时计算系统。 Storm 使得容易可靠地处理无界的数据流,为实时处理 Hadoop 对批处理所做的工作。 该过程实质上是节点的 DAG,其被称为 topology。
Apache Atlas 是一个元数据存储库,支持端到端数据沿袭,搜索和关联业务分类。
这种集成的目的是推动操作 topology 元数据以及基础数据源,目标,推导过程和任何可用的业务上下文,以便 Atlas 可以捕获此 topology 的 lineage。
在此过程中有2个部分详述如下:
Data model to represent the concepts in Storm
Storm Atlas Hook to update metadata in Atlas
Storm Data Model
数据模型在 Atlas 中表示为 Types。 它包含 topology 图中各种节点的描述,例如 spouts 和 bolts 以及相应的生产者和消费者类型。
在Atlas中添加以下类型。
storm_topology - 表示粗粒度拓扑。storm_topology 来自于 Atlas 过程类型,因此可用于通知 Atlas 关于 lineage。
添加以下数据集 - kafka_topic,jms_topic,hbase_table,hdfs_data_set。 这些都来自Atlas Dataset类型,因此形成谱系图的端点。
storm_spout - 具有输出的数据生产者,通常为Kafka,JMS
storm_bolt - 具有输入和输出的数据使用者,通常为Hive,HBase,HDFS等。
Storm Atlas hook自动注册依赖模型,如Hive数据模型,如果它发现这些是不为Atlas服务器所知。
每个类型的数据模型在类定义org.apache.atlas.storm.model.StormDataModel中描述。
Storm Atlas Hook
当在 Storm 中成功注册新 topology 时,通知 Atlas。 Storm 在 Storm 客户端提供了一个钩子,backtype.storm.ISubmitterHook,用于提交一个 Storm topology。
Storm Atlas hook 拦截 hook 后执行,并从 topology 中提取元数据,并使用定义的类型更新 Atlas。 Atlas 在org.apache.atlas.storm.hook.StormAtlasHook 中实现了 Storm 客户端 hook 接口。
Limitations
以下内容适用于集成的第一个版本。
只有新的 topology 提交已注册到 Atlas,任何生命周期变化都不会反映在 Atlas 中。
当为要捕获的元数据提交 Storm topology 时,Atlas 服务器需要在线。
hook 目前不支持捕获自定义 spouts 和 bolts 的 lineage。
Installation
Storm Atlas Hook 需要在客户端手动安装在 Storm 在:$ATLAS_PACKAGE/hook/storm
Storm Atlas Hook 需要复制到 $STORM_HOME/extlib。 使用 storm 安装路径替换 STORM_HOME。
在将安装了 atlas hook 到 Storm 后重新启动所有守护进程。
Configuration
Storm Configuration
Storm Atlas Hook 需要在 Storm 客户端 $STORM_HOME/conf/storm.yaml 进行配置:
storm.topology.submission.notifier.plugin.class: "org.apache.atlas.storm.hook.StormAtlasHook"
还设置一个 "集群名称",将用作在 Atlas 中注册的对象的命名空间。 此名称将用于命名 Storm topology,spouts 和 bolts。
其他对象(如 Dataset)应该理想地用生成它们的组件的集群名称来标识。 例如, Hive 表和数据库应该使用在 Hive 中设置的集群名称来标识。 如果 Hive 配置在客户端上提交的 Storm topology jar 中可用,并且在那里定义了集群名称,Storm Atlas hook 将选择此选项。 对于 HBase 数据集,这种情况类似。 如果此配置不可用,将使用在 Storm 配置中设置的集群名称。
atlas.cluster.name: "cluster_name"
在 $STORM_HOME/conf/storm_env.ini 中, 设置以下环境变量:
STORM_JAR_JVM_OPTS:"-Datlas.conf=$ATLAS_HOME/conf/"
将 ATLAS_HOME 指向 ATLAS 的安装目录.
你也可以通过程序对 Storm 进行如下配置:
Config stormConf = new Config();
...
stormConf.put(Config.STORM_TOPOLOGY_SUBMISSION_NOTIFIER_PLUGIN,
org.apache.atlas.storm.hook.StormAtlasHook.class.getName());
容错和高可用
简介
Apache Atlas 使用各种系统并与其交互,为数据管理员提供元数据管理和数据 lineage。 通过适当地选择和配置这些依赖关系,可以使用 Atlas 实现高度的服务可用性。 本文档介绍了 Atlas 的高可用性支持状态,包括其功能和当前限制,以及实现此级别高可用性所需的配置。
Atlas Web Service
目前,Atlas Web 服务有一个限制,它一次只能有一个活动实例。在早期版本的 Atlas 中,可以配置和保持备份实例。但是,需要手动故障转移才能使此备份实例处于活动状态。
从这个版本开始,Atlas 将支持带有自动故障转移的 主动/被动 配置中的 Atlas Web 服务的多个实例。这意味着用户可以在不同的物理主机上同时部署和启动 Atlas Web 服务的多个实例。其中一个实例将被自动选择为 "活动" 实例来为用户请求提供服务。其他人将自动被视为 "被动"。如果 "活动" 实例由于故意停止或由于意外故障而变得不可用,则其他实例之一将自动选为 "活动" 实例,并开始为用户请求提供服务。
"活动" 实例是能够正确响应用户请求的唯一实例。它可以创建,删除,修改或响应元数据对象上的查询。 "被动" 实例将接受用户请求,但会使用 HTTP 重定向将其重定向到当前已知的 "活动" 实例。具体来说,被动实例本身不会响应对元数据对象的任何查询。但是,所有实例(包括主动和被动)都将响应返回有关该实例的信息的管理请求。
当配置为高可用性模式时,用户可以获得以下操作优势:
在维护间隔期间不间断服务:如果需要停用 Atlas Web 服务的活动实例进行维护,则另一个实例将自动变为活动状态并可以为请求提供服务。
在意外故障事件中的不间断服务:如果由于软件或硬件错误,Atlas Web 服务的活动实例失败,另一个实例将自动变为活动状态并可以为请求提供服务。
在以下小节中,我们将介绍为 Atlas Web 服务设置高可用性所需的步骤。 我们还描述了如何设计部署和客户端以利用此功能。 最后,我们描述一些底层实现的细节。
Setting up the High Availability feature in Atlas
设置高可用性功能必须满足以下先决条件。
确保在一组计算机上安装 Apache Zookeeper(建议至少使用3台服务器进行生产)。
选择 2 个或更多物理机以在其上运行 Atlas Web Service 实例。这些机器定义了我们称为 Atlas 的 "服务器集合"。
要在 Atlas 中设置高可用性,必须在 atlas-application.properties 文件中定义一些配置选项。虽然配置项的完整列表在配置页中定义,但本节列出了几个主要选项。
高可用性是 Atlas 的可选功能。因此,必须通过将配置选项 atlas.server.ha.enabled 设置为 true 来启用。
接下来,定义标识符列表,为您为 Atlas Web Service 实例选择的每个物理机器分配一个标识符。这些标识符可以是简单的字符串,如id1,id2等。它们应该是唯一的,不应包含逗号。
将这些标识符的逗号分隔列表定义为选项 atlas.server.ids 的值。
对于每个物理机,请列出IP地址/主机名和端口作为配置 atlas.server.address.id 的值,其中 id 指的是此物理机的标识符字符串。
例如,如果您选择了 2 台主机名为 http://host1.company.com 和 http://host2.company.com 的计算机,则可以如下定义配置选项:
atlas.server.ids=id1,id2
atlas.server.address.id1=host1.company.com:21000
atlas.server.address.id2=host2.company.com:21000
定义使用的 Zookeeper 为 Atlas 提供高可用性功能
atlas.server.ha.zookeeper.connect=zk1.company.com:2181,zk2.company.com:2181,zk3.company.com:2181
您可以查看为高可用性功能定义的其他配置选项,并根据需要在 atlas-application.properties 文件中进行设置。
对于生产环境,Atlas 所依赖的组件也必须在高可用性模式下设置。 这将在以下部分中详细描述。 按照这些说明设置和配置它们。
在选定的物理机器上安装 Atlas 软件。
将使用上述步骤创建的 atlas-application.properties 文件复制到所有计算机的配置目录。
启动相关组件。
启动 Atlas Web 服务的每个实例。
要验证高可用性是否正常工作,请在安装了 Atlas Web Service 的每个实例上运行以下脚本。
$ATLAS_HOME/bin/atlas_admin.py -status
此脚本可以打印以下值之一作为响应:
ACTIVE:此实例处于活动状态,可以响应用户请求。
PASSIVE:此实例为 PASSIVE。它会将它收到的任何用户请求重定向到当前活动实例。
BECOMING_ACTIVE:如果服务器正在转换为 ACTIVE 实例,则将打印此消息。在此状态下,服务器无法处理任何元数据用户请求。
BECOMING_PASSIVE:如果服务器正在转换为 PASSIVE 实例,则将打印此消息。在此状态下,服务器无法处理任何元数据用户请求。
在正常操作情况下,只有其中一个实例应该打印 ACTIVE 值作为对脚本的响应,而其他实例将打印 PASSIVE。
配置客户端以使用高可用性功能
Atlas Web 服务可以通过两种方式访问:
使用 Atlas Web UI:这是一个基于浏览器的客户端,可用于查询存储在Atlas中的元数据。
使用 Atlas REST API:由于 Atlas 公开了一个 RESTful API,因此可以使用任何标准的 REST 客户端,包括其他应用程序中的库。事实上,Atlas 附带了一个名为 AtlasClient 的客户端,可以用作创建 REST 客户端访问的示例。
为了利用客户端中的高可用性功能,可以有两个选项。
使用中间代理
启用高可用性访问 Atlas 的最简单的解决方案是安装和配置一些中间代理,其具有基于状态透明地切换服务的能力。一个这样的代理解决方案是 HAProxy。
下面是一个可以使用的 HAProxy 配置示例。注意,这只是为了说明,而不是作为推荐的生产配置。为此,请参阅 HAProxy文档以获取相应的说明。
frontend atlas_fe
bind *:41000
default_backend atlas_be
backend atlas_be
mode http
option httpchk get /api/atlas/admin/status
http-check expect string ACTIVE
balance roundrobin
server host1_21000 host1:21000 check
server host2_21000 host2:21000 check backup
listen atlas
bind localhost:42000
以上配置绑定 HAProxy 侦听端口 41000 传入客户端连接。然后根据 HTTP 状态检查将连接路由到主机 host1 或 host2 中的任一个。状态检查是使用 REST URL / api / atlas / admin / status 上的 HTTP GET 完成的,只有当 HTTP 响应包含字符串ACTIVE 时,才认为成功。
使用活动实例的自动检测
如果不想设置和管理单独的代理,则使用高可用性功能的另一个选项是构建能够检测状态和重试操作的客户端应用程序。在这样的设置中,可以使用形成集合的所有 Atlas Web 服务实例的 URL 启动客户端应用程序。然后,客户端应调用其中每一个上的 REST URL / api / atlas / admin / status,以确定哪个是活动实例。来自 Active 实例的响应将具有 {Status:ACTIVE}的形式。此外,当客户端在操作过程中遇到任何异常时,它应该再次确定哪些剩余的URL是活动的并重试该操作。
Atlas 附带的 AtlasClient 类可以用作一个示例客户端库,它实现了使用集合并选择正确的Active服务器实例的逻辑。
Atlas 中的实用程序(如quick_start.py和import-hive.sh)可以配置为使用多个服务器URL运行。当在此模式下启动时,AtlasClient 自动选择并使用当前活动实例。如果在之间设置了代理,则可以在运行 quick_start.py 或 import-hive.sh 时使用其地址。
实现 Atlas 高可用
Atlas 高可用性工作在主 JIRA ATLAS-510 下进行跟踪。根据其提交的 JIRA 具有关于高可用性功能如何实现的详细信息。在高级别可以调出以下几点:
活动实例的自动选择以及到新的活动实例的自动故障转移通过领导者选择算法发生。
对于领导选举,我们使用 Apache Curator 的 Leader Latch Recipe。
Active 实例是唯一一个在后端存储中初始化,修改或读取状态以保持它们一致的实例。
此外,当实例被选为活动时,它会刷新后端存储中的任何缓存信息以获取最新信息。
servlet 过滤器确保只有活动的实例服务用户请求。如果被动实例接收到这些请求,它会自动将它们重定向到当前活动实例。
Metadata Store
如上所述,Atlas 使用 Titan 来存储它管理的元数据。默认情况下,Atlas 使用独立的 HBase 实例作为 Titan 的后备存储。为了为元数据存储提供 HA,我们建议将 Atlas 配置为使用分布式 HBase 作为 Titan 的后备存储。这意味着您可以从 HBase 提供的 HA 保证中受益。为了将 Atlas 配置为在 HA 模式下使用 HBase,请执行以下操作:
选择在HA模式中设置的现有 HBase 集群以在 Atlas(OR)中配置在 HA模式 下设置新的 HBase 集群。
如果为 Atlas 设置 HBase,请按照 Installation Steps 中列出的用于设置 HBase 的说明进行操作。
我们建议在使用 Zookeeper 协调的不同物理主机上的集群中使用多个 HBase 主机(至少2个),以提供 HBase的 冗余和高可用性。
有关在 atlas.properties 中配置的选项的 Configuration page ,请参考配置页面,以便使用 HBase 设置 Atlas。
Index Store
如上所述,Atlas 通过 Titan 索引元数据以支持全文搜索查询。 为了为索引存储提供 HA,我们建议将 Atlas 配置为使用 Solr作为 Titan 的后备索引存储。 为了将 Atlas 配置为在 HA 模式下使用 Solr,请执行以下操作:
在 HA 模式下选择现有的 SolrCloud 群集设置以在 Atlas(OR)中配置设置新的 SolrCloud 群集。
确保 Solr 在至少 2 个物理主机上启动以实现冗余,并且每个主机运行 Solr 节点。
我们建议将冗余数设置为至少 2。
创建 Atlas 所需的 SolrCloud 集合,如安装步骤中所述
请参阅配置页面以了解在 atlas.properties 中配置的选项,以使用 Solr 设置 Atlas。
Notification Server
来自 Hook 的元数据通知事件通过写入到名为 ATLAS_HOOK 的 Kafka topic 发送到 Atlas 。类似地,从 Atlas 到其他集成组件(如Ranger)的事件写入名为 ATLAS_ENTITIES 的 Kafka topic。由于 Kafka 会保留这些消息,即使消费者在发送事件时失败,事件也不会丢失。此外,我们建议 Kafka 也设置容错,以便它具有更高的可用性保证。为了配置 Atlas 在 HA 模式下使用 Kafka,请执行以下操作:
选择在 HA 模式中设置的现有 Kafka 集群以在 Atlas(OR)中配置设置新的 Kafka 集群。
我们建议在不同物理主机上的群集中有多个 Kafka 代理,它们使用 Zookeeper 协调,以提供 Kafka 的冗余和高可用性。
设置至少 2 个物理主机以实现冗余,每个托管一个 Kafka 代理。
为 Atlas 使用设置 Kafka 主题:
ATLAS 主题的分区数应设置为1(numPartitions)
确定 Kafka 主题的副本数量:将此值设置为至少 2 以进行冗余。
运行以下命令:
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper <list of zookeeper host:port entries> --topic ATLAS_HOOK --replication-factor <numReplicas> --partitions 1
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper <list of zookeeper host:port entries> --topic ATLAS_ENTITIES --replication-factor <numReplicas> --partitions 1
Here KAFKA_HOME points to the Kafka installation directory.
在 atlas-application.properties 中进行如下配置:
atlas.notification.embedded=false
atlas.kafka.zookeeper.connect=<comma separated list of servers forming Zookeeper quorum used by Kafka>
atlas.kafka.bootstrap.servers=<comma separated list of Kafka broker endpoints in host:port form> - Give at least 2 for redundancy.
Known Issues
如果托管 Atlas 'titan' HTable 的 HBase region servers 停机,Atlas 将无法在 HBase 恢复联机之前从 HBase 存储或检索元数据。
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
使用 Apache Atlas 进行数据治理的更多相关文章
- 数据治理的王者——Apache Atlas
一.Atlas是什么? 在当今大数据的应用越来越广泛的情况下,数据治理一直是企业面临的巨大问题. 大部分公司只是单纯的对数据进行了处理,而数据的血缘,分类等等却很难实现,市场上也急需要一个专注于数据治 ...
- 数据治理方案技术调研 Atlas VS Datahub VS Amundsen
数据治理意义重大,传统的数据治理采用文档的形式进行管理,已经无法满足大数据下的数据治理需要.而适合于Hadoop大数据生态体系的数据治理就非常的重要了. 大数据下的数据治理作为很多企业的一个巨大的 ...
- 数据治理之元数据管理的利器——Atlas入门宝典
随着数字化转型的工作推进,数据治理的工作已经被越来越多的公司提上了日程.作为Hadoop生态最紧密的元数据管理与发现工具,Atlas在其中扮演着重要的位置.但是其官方文档不是很丰富,也不够详细.所以整 ...
- Apache 首次亚洲在线峰会: Workflow & 数据治理专场
背景 大数据发展到今天已有 10 年时间,早已渗透到各个行业,数据需 求越来越多,这使得大数据 业务间的依赖关系也越来越复杂,另外也相信做数据的伙伴肯定对如何治理数据也是痛苦之至,再加上现今云原生时代 ...
- 元数据治理利器 - Apache Atlas
一.功能简介 Atlas 是一组可扩展的核心基础治理服务,使企业能够高效地满足其在 Hadoop 中的合规性要求,并允许与整个企业数据生态系统集成.Apache Atlas 为组织提供开放的元数据管理 ...
- Apache Atlas元数据管理从入门到实战(1)
一.前言 元数据管理是数据治理非常重要的一个方向,元数据的一致性,可追溯性,是实现数据治理非常重要的一个环节.传统数据情况下,有过多种相对成熟的元数据管理工具,而大数据时代,基于hadoop,最为 ...
- Apache Atlas
atlas英 [ˈætləs] 阿特拉斯. 美 [ˈætləs] n.地图集;〈比喻〉身负重担的人 == Apache Atlas Version: 1.1.0 Last Published: 201 ...
- Apache Atlas是什么?
不多说,直接上干货! Apache Atlas是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括数据分类.集中策略引擎.数据血缘.安全和生命周 ...
- DataHub——实时数据治理平台
DataHub 首先,阿里云也有一款名为DataHub的产品,是一个流式处理平台,本文所述DataHub与其无关. 数据治理是大佬们最近谈的一个火热的话题.不管国家层面,还是企业层面现在对这个问题是越 ...
随机推荐
- 迷你MVVM框架 avalonjs 0.84发布
本版本只要做了如下改进 重构ui绑定 fix scanTag bug ms-include 的值必须不为空值,否则不做任何操作.
- 设置 UILabel 和 UITextField 的 Padding 或 Insets (理解UIEdgeInsets)
转自http://unmi.cc/uilable-uitextfield-padding-insets 主要是理解下UIEdgeInsets在IOS UI里的意义. 靠,这货其实就是间隔,起个名字这么 ...
- EL 和 JSTL
EL 什么是EL表达式 EL(Express Lanuage) 表达式可以嵌入在jsp页面内部 减少jsp脚本的编写 EL出现的目的是要替代jsp页面中脚本的编写 作用区间 EL最主要的作用是获取四大 ...
- 前端开发之jQuery篇--选择器
主要内容: 1.jQuery简介 2.jQuery文件的引入 3.jQuery选择器 4.jQuery对象与DOM对象的转换 一.jQuery简介 1.介绍 jQuery是一个JavaScript库: ...
- Python_08-常用模块
1 常用模块介绍 1.1 os模块 1.2 sys模块 1.3 built-in内置模块 1.4 time模块 1.5 re模块 2 ...
- Thrift 实现 JAVA,PHP,C#,Python 互相通信
Thrift介绍 https://www.ibm.com/developerworks/cn/java/j-lo-apachethrift/index.html 首先需要下载 Thrift.exe ...
- ORA-01795: maximum number of expressions in a list is 1000
今天发现查询Oracle用In查询In的元素不可以超过1000个还需要分成多个1000查询记录博客备忘!! Load Test的时候发现这么如下这个错误.... ORA-01795: maximum ...
- 把二叉搜索树转化成更大的树 · Convert BST to Greater Tree
[抄题]: 给定二叉搜索树(BST),将其转换为更大的树,使原始BST上每个节点的值都更改为在原始树中大于等于该节点值的节点值之和(包括该节点). Given a binary search Tree ...
- js中with 用法
with 语句用于设置代码在特定对象中的作用域. 它的语法: with (expression) statement例如: var sMessage = "hello"; with ...
- Zookeeper 源码(二)序列化组件 Jute
Zookeeper 源码(二)序列化组件 Jute 一.序列化组件 Jute 对于一个网络通信,首先需要解决的就是对数据的序列化和反序列化处理,在 ZooKeeper 中,使用了Jute 这一序列化组 ...