spark环境安装
源码包下载:
http://archive.apache.org/dist/spark/spark-2.1.1/v
集群环境:
master 192.168.1.99
slave1 192.168.1.100
slave2 192.168.1.101
下载安装包:
# Master
wget http://archive.apache.org/dist/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/src
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz -C /usr/local/src
tar -zxvf spark-2.1.-bin-hadoop2..tgz
tar -zxvf scala-2.11.8.tgz
mv spark-2.1.-bin-hadoop2. /usr/local/spark
mv scala-2.11.8 /usr/local/scala
修改配置文件:
cd /usr/local/spark/conf
vim spark-env.sh
export SCALA_HOME=/usr/local/scala
export JAVA_HOME=/usr/local/jdk1.8.0_181
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/spark
SPARK_DRIVER_MEMORY=1G
vim slaves
slave1
salve2
配置环境变量:
#Master slave1 slave2
vim ~/.bashrc
SPARK_HOME=/usr/local/spark
PATH=$PATH:$SPARK_HOME/bin #刷新环境变量
source ~/.bashrc
拷贝安装包:
scp -r /usr/local/spark root@slave1:/usr/local/spark
scp -r /usr/local/spark root@slave2:/usr/local/spark scp -r /usr/local/scala root@slave1:/usr/local/scala
scp -r /usr/local/scala root@slave2:/usr/local/scala
启动集群:
/usr/local/spark/sbin/start-all.sh
集群状态:
#Master
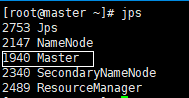
#slave1

#slave2

监控网页:
http://master:8080
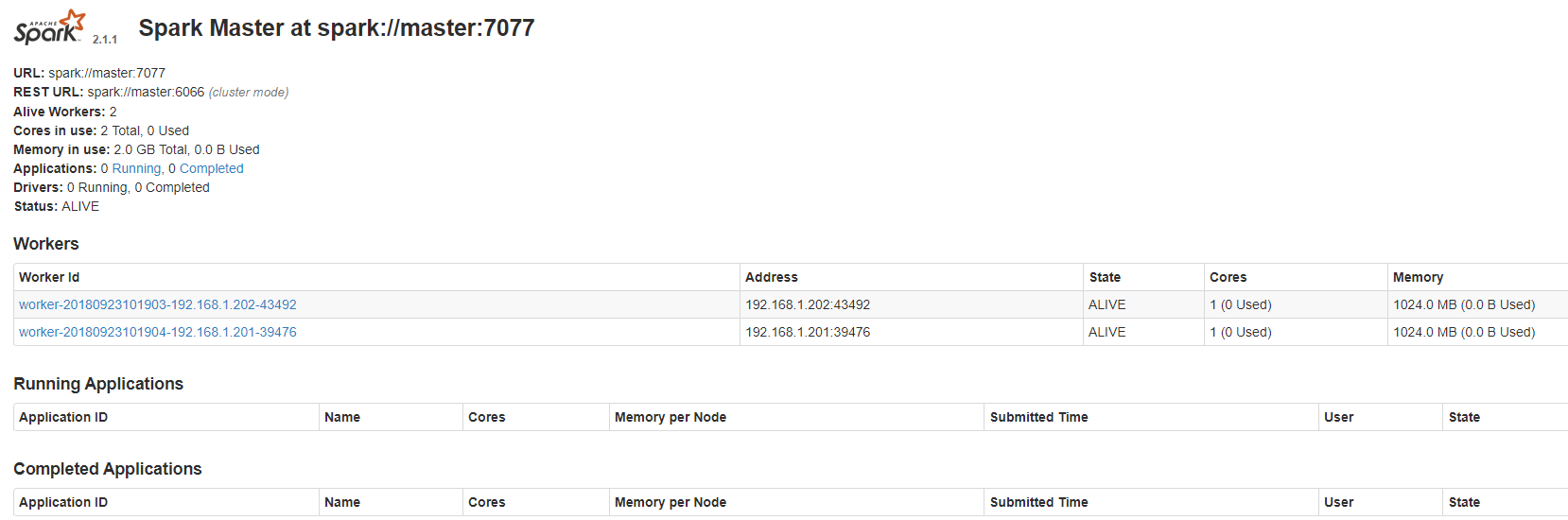
验证:
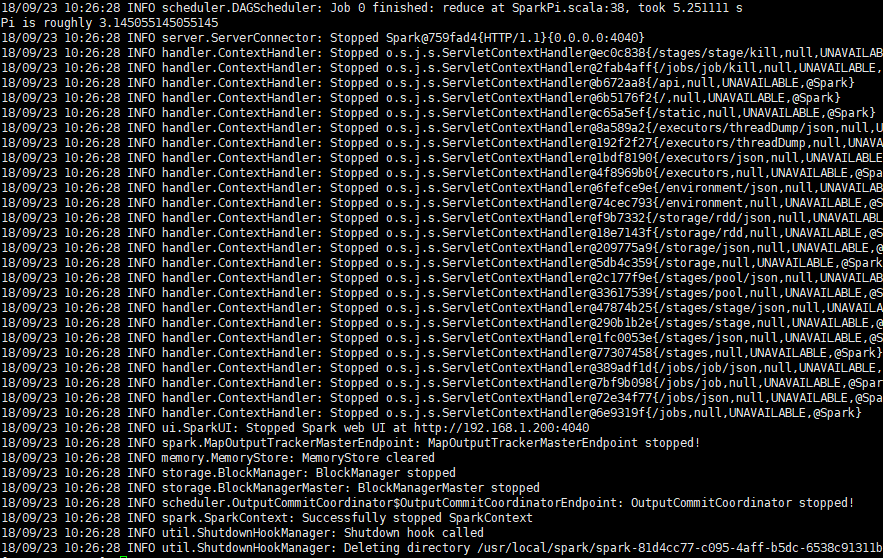
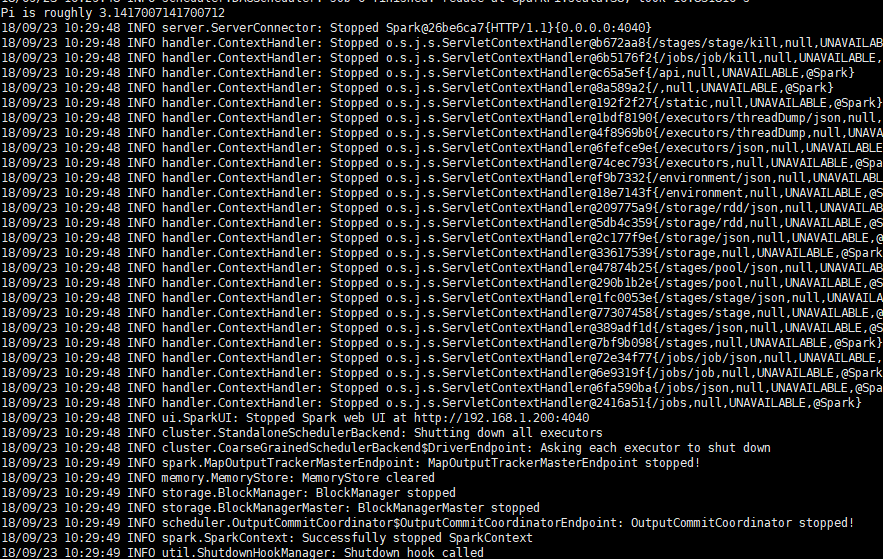
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster /usr/local/spark/examples/jars/spark-examples_2.11-2.1.1.jar 100

spark环境安装的更多相关文章
- 详解 jupyter notebook 集成 spark 环境安装
来自: 代码大湿 代码大湿 1 相关介绍 jupyter notebook是一个Web应用程序,允许你创建和分享,包含活的代码,方程的文件,可视化和解释性文字.用途包括:数据的清洗和转换.数值模拟.统 ...
- 手工命令行 搭建 hadoop 和 spark 环境
环境准备:3台CentOS7,64位,Hadoop2.7需要64位Linux 192.168.20.161 192.168.20.162 192.168.20.163 三台机器分别叫host01. ...
- Windows下安装Spark环境
根据博客总结 https://blog.csdn.net/nxw_tsp/article/details/78281533 需要的安装软件可以在网盘下载: 链接:https://pan.baidu.c ...
- hadoop环境的安装 和 spark环境的安装
hadoop环境的安装1.前提:安装了java spark环境的安装1.前提:安装了java,python2.直接pip install pyspark就可以安装完成.(pip是python的软件安装 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- Spark——Standalone 环境安装及简单使用
Standalone 环境安装 将 spark-3.0.0-bin-hadoop3.2.tgz 文件解压缩在指定位置(/opt/module) tar -zxvf spark-3.0.0-bin-ha ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- 在MacOs上配置Hadoop和Spark环境
在MacOs上配置hadoop和spark环境 Setting up Hadoop with Spark on MacOs Instructions 准备环境 如果没有brew,先google怎样安装 ...
随机推荐
- socket网络编程【python】
转自:http://www.jb51.net/article/19751.htm socket 是网络连接端点. 一.网络知识的一些介绍 socket 是网络连接端点.例如当你的Web浏览器请求www ...
- jquery获取父级元素、子级元素、兄弟元素的方法
jQuery.parent(expr) 找父亲节点,可以传入expr进行过滤,比如$("span").parent()或者$("span").parent(&q ...
- Solr服务搭建
1.1. Solr的环境 Solr是java开发. 需要安装jdk. 安装环境Linux. 需要安装Tomcat. 1.2. 搭建步骤 第一步:把solr 的压缩包上传到Linux系统 第二步:解压s ...
- 【Mysql】解决插入数据出现 Incorrect string value: '\xF0\x9F\x92\x8BTi...'错误
背景: 用户输入的表单里边.存在 手机自带的表情, 在执行插入时候报错 Incorrect string value: '\xF0\x9F\x92\x8BTi...' 错误原因:我们在设置mysql ...
- java基础---->Base64算法的使用
Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,可用于在HTTP环境下传递较长的标识信息.详细的Base64信息,可以参见维基百科:https://en.wikipedia.org ...
- Android Framewrork资源类型有哪些?
1. Google Framework res frameworks/base/core/res/res/values <public type="attr" name=&q ...
- CHMOD命令怎么用?
文件/目录权限设置命令:chmod 这是Linux系统管理员最常用到的命令之一,它用于改变文件或目录的访问权限.该命令有两种用法: 用包含字母和操作符表达式的文字设定法 其语法格式为:chmod [w ...
- go http 文件下载
package main import ( "fmt" "net/http" "os" ) func DownFile() { userFi ...
- 利用aspose-words 实现 java中word转pdf文件
利用aspose-words 实现 java中word转pdf文件 首先下载aspose-words-15.8.0-jdk16.jar包 引入jar包,编写Java代码 package test; ...
- 基于JDK1.8的LinkedList源码学习笔记
LinkedList作为一种常用的List,是除了ArrayList之外最有用的List.其同样实现了List接口,但是除此之外它同样实现了Deque接口,而Deque是一个双端队列接口,其继承自Qu ...