[转] COM编程总结
一、Com概念
所谓COM(Componet Object Model,组件对象模型),是一种说明如何建立可动态互变组件的规范,此规范提供了为保证能够互操作,客户和组件应遵循的一些二进制和网络标准。通过这种标准将可以在任意两个组件之间进行通信而不用考虑其所处的操作环境是否相同、使用的开发语言是否一致以及是否运行于同一台计算机。
在COM规范下将能够以高度灵活的编程手段来开发、维护应用程序。可以将一个单独的复杂程序划分为多个独立的模块进行开发,这里的每一个独立模块都是一个自给自足的组件,可以采取不同的开发语言去设计每一个组件。在运行时将这些组件通过接口组装起来以形成所需要的应用程序。构成应用程序的每一个组件都可以在不影响其他组件的前提下被升级。这里所说的组件是特指在二进制级别上进行集成和重用而能够被独立生产获得和配置的软件单元。COM规范所描述的即是如何编写组件,遵循COM标准的任何一个组件都是可以被用来组合成应用程序的。至于对组件采取的是何种编程语言则是无关紧要的,可以自由选取。作为一个真正意义上的组件,应具备如下特征:
1) 实现了对开发语言的封装。
2) 以二进制形式发布。
3) 能够在不妨碍已有用户的情况下被升级。
4) 在网络上的位置必须能够被透明的重新分配。
这些特征使COM组件具有很好的可重用性,这种可重用性与DLL一样都是建立在二进制基础上的代码重用。但是COM在多个方面的表现均要比DLL的重用方式好的多。例如,在DLL中存在的函数重名问题、各编译器对C++函数名称修饰的不兼容问题、路径问题以及与可执行程序的依赖性问题等在COM中通过使用虚函数表、查找注册表等手段均被很好的解决。其实COM组件在发布形式上本身就包扩DLL,只不过通过制订复杂的COM规范,使COM本身的机制改变了重用的方法,能够以一种新的方法来利用DLL并克服DLL本身所固有的一些缺陷,从而实现了更高层次的重用。
(1)函数重名问题
DLL里是一个一个的函数,我们通过函数名来调用函数,那如果两个DLL里有重名的函数怎么办?
(2)各编译器对C++函数的名称修饰不兼容问题
对于C++函数,编译器要根据函数的参数信息为它生成修饰名,DLL库里存的就是这个修饰名,但是不同的编译器产生修饰的方法不一样,所以你在VC里编写的DLL在BC里就可以用不了。不过也可以用extern"C";来强调使用标准的C函数特性,关闭修饰功能,但这样也丧失了C++的重载多态性功能。
(3)路径问题
放在自己的目录下面,别人的程序就找不到,放在系统目录下,就可能有重名的问题。而真正的组件应该可以放在任何地方甚至可以不在本机,用户根本不需考虑这个问题。
(4)DLL与EXE的依赖问题
我们一般都是用隐式连接的方式,就是编程的时侯指明用什么DLL,这种方式很简单,它在编译时就把EXE与DLL绑在一起了。如果DLL发行了一个新版本,我们很有必要重新链接一次,因为DLL里面函数的地址可能已经发生了改变。DLL的缺点就是COM的优点。
二、COM相关的结构、接口
1)、CLSID
CLSID其实就是一个号码,或者说是一个16字节的数。观察注册表,在HKEY_CLASSES_ROOT\CLSID\{......}主键下,LocalServer32(DLL组件使用InprocServer32) 中保存着程序路径名称。CLSID 的结构定义如下:
typedef struct _GUID {
DWORD Data1; // 随机数
WORD Data2; // 和时间相关
WORD Data3; // 和时间相关
BYTE Data4[8]; // 和网卡MAC相关
} GUID;
typedef GUID CLSID; // 组件ID
typedef GUID IID; // 接口ID
#define REFCLSID const CLSID &
// 常见的声明和赋值方法
CLSID CLSID_Excel ={0x00024500,0x0000,0x0000,{0xC0,0x00,0x00,0x00,0x00,0x00,0x00,0x46}};
struct __declspec(uuid("00024500-0000-0000-C000-000000000046"))CLSID_Excel;
class DECLSPEC_UUID("00024500-0000-0000-C000-000000000046")CLSID_Excel;
// 注册表中的表示方法
{00024500-0000-0000-C000-000000000046}
2)、ProgID
每一个COM组件都需要指定一个CLSID,并且不能重名。它之所以使用16个字节,就是要从概率上保证重复是“不可能”的。但是,微软为了使用方便与记忆,也支持另一个字符串名称方式,叫 ProgID。由于 CLSID 和 ProgID 其实是一个概念的两个不同的表示形式,所以我们在程序中可以随便使用任何一种。下面介绍一下 CLSID 和 ProgID 之间的转换方法和相关的函数:
|
函数 |
功能说明 |
|
CLSIDFromProgID()、CLSIDFromProgIDEx() |
由 ProgID 得到 CLSID。没什么好说的,你自己都可以写,查注册表贝 |
|
ProgIDFromCLSID() |
由 CLSID 得到 ProgID,调用者使用完成后要释放 ProgID 的内存(注5) |
|
CoCreateGuid() |
随机生成一个 GUID |
|
IsEqualGUID()、IsEqualCLSID()、IsEqualIID() |
比较2个ID是否相等 |
|
StringFromCLSID()、StringFromGUID2()、StringFromIID() |
由 CLSID,IID 得到注册表中CLSID样式的字符串,注意释放内存 |
3)、接口
3.1、函数是通过 VTAB 虚函数表提供其地址, 从另一个角度来看,不管用什么语言开发,编译器产生的代码都能生成这个表。这样就实现了组件的“二进制特性”轻松实现了组件的跨语言要求。
3.2、假设有一个指针型变量保存着 VTAB 的首地址,则这个变量就叫“接口指针, 变量命名的时候,习惯上加上"I"开头。另外为了区分不同的接口,每个接口 也都要有一个名字,该名字就和 CLSID 一样,使用 GUID 方式,叫 IID。
3.3、接口一经发表,就不能再修改了。不然就会出现向前兼容的问题。这个性质叫“接口不变性”。
3.4、组件中必须有3个函数,QueryInterface、AddRef、Release,它们3个函数也组成一个接口,叫"IUnknown"。
3.5、任何接口,其实都包含了 IUnknown 接口。随着你接触到更多的接口就会了更体会解到接口的另一个性质“继承性”。
3.6、在任何接口上,调用表中的第一个函数,其实就是调用 QueryInterface()函数,就得到你想要的另外一个接口指针。这个性质叫“接口的传递性”
3.7、C/C++语言中需要事先对函数声明,那么就 会要求组件也必须提供C语言的头文件。不行!为了能使COM具有跨语言的能力,决定不再为任何语言提供对应的函数接口声明,而是独立地提供一个叫类型库(TLB)的声明。每个语言的IDE环境自己去根据TLB生成自己语言需要的包装。这个性质叫“接口声明的独立性”。
4)COM组件数据类型
HRESULT 函数返回值
HRESULT Add( long n1, long n2, long *pSum)
{
*pSum = n1 + n2;
return S_OK;
}
如果函数正常执行,则返回 S_OK,同时真正的函数运行结果则通过参数指针返回。如果遇到了异常情况,则COM系统经过判断,会返回相应的错误值。常见的返回值有:
|
HRESULT |
值 |
含义 |
|
S_OK |
0x00000000 |
成功 |
|
S_FALSE |
0x00000001 |
函数成功执行完成,但返回时出现错误 |
|
E_INVALIDARG |
0x80070057 |
参数有错误 |
|
E_OUTOFMEMORY |
0x8007000E |
内存申请错误 |
|
E_UNEXPECTED |
0x8000FFFF |
未知的异常 |
|
E_NOTIMPL |
0x80004001 |
未实现功能 |
|
E_FAIL |
0x80004005 |
没有详细说明的错误。一般需要取得 Rich Error 错误信息(注1) |
|
E_POINTER |
0x80004003 |
无效的指针 |
|
E_HANDLE |
0x80070006 |
无效的句柄 |
|
E_ABORT |
0x80004004 |
终止操作 |
|
E_ACCESSDENIED |
0x80070005 |
访问被拒绝 |
|
E_NOINTERFACE |
0x80004002 |
不支持接口 |

(图:HRESULT 的结构)
HRESULT 其实是一个双字节的值,其最高位(bit)如果是0表示成功,1表示错误。具体参见 MSDN 之"Structureof COM Error Codes"说明。我们在程序中如果需要判断返回值,则可以使用比较运算符号;switch开关语句;也可以使用VC提供的宏:
HRESULT hr = 调用组件函数;
if( SUCCEEDED( hr ) ){...} // 如果成功
......
if( FAILED( hr ) ){...} // 如果失败
BSTR
COM 中除了使用一些简单标准的数据类型外(注2),字符串类型需要特别重点地说明一下。还记得原则吗?COM 组件是运行在分布式环境中的。通俗地说,你不能直接把一个内存指针直接作为参数传递给COM函数。你想想,系统需要把这块内存的内容传递到“地球另一 边”的计算机上,因此,我至少需要知道你这块内存的尺寸吧?不然让我如何传递呀?传递多少字节呀?!而字符串又是非常常用的一种类型,因此 COM 设计者引入了 BASIC 中字符串类型的表示方式---BSTR。BSTR 其实是一个指针类型,它的内存结构是:(输入程序片段 BSTR p = ::SysAllocString(L"Hello,你好");断点执行,然后观察p的内存)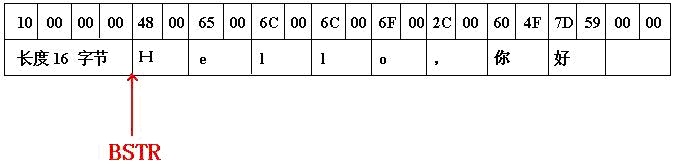
(图:BSTR 内存结构)、
BSTR 是一个指向 UNICODE 字符串的指针,且 BSTR 向前的4个字节中,使用DWORD保存着这个字符串的字节长度( 没有含字符串的结束符)。
有关 BSTR 的处理函数:
|
API 函数 |
说明 |
|
SysAllocString() |
申请一个 BSTR 指针,并初始化为一个字符串 |
|
SysFreeString() |
释放 BSTR 内存 |
|
SysAllocStringLen() |
申请一个指定字符长度的 BSTR 指针,并初始化为一个字符串 |
|
SysAllocStringByteLen() |
申请一个指定字节长度的 BSTR 指针,并初始化为一个字符串 |
|
SysReAllocStringLen() |
重新申请 BSTR 指针 |
|
CString 函数 |
说明 |
|
AllocSysString() |
从 CString 得到 BSTR |
|
SetSysString() |
重新申请 BSTR 指针,并复制到 CString 中 |
|
CComBSTR 函数 ATL 的 BSTR 包装类。在 atlbase.h 中定义 |
|
|
Append()、AppendBSTR()、AppendBytes()、ArrayToBSTR()、BSTRToArray()、AssignBSTR()、Attach()、Detach()、Copy()、CopyTo()、Empty()、Length()、ByteLength()、ReadFromStream()、WriteToStream()、LoadString()、ToLower()、ToUpper() 运算符重载:!,!=,==,<,>,&,+=,+,=,BSTR |
太多了,但从函数名称不能看出其基本功能。详细资料,查看MSDN 吧。另外,左侧函数,有很多是 ATL 7.0 提供的,VC6.0 下所带的 ATL 3.0 不支持。 |
各种字符串类型之间的转换
函数 WideCharToMultiByte(),转换 UNICODE 到MBCS。使用范例:
LPCOLESTR lpw = L"Hello,你好";
size_t wLen = wcslen( lpw ) + 1; // 宽字符字符长度,+1表示包含字符串结束符
int aLen=WideCharToMultiByte( // 第一次调用,计算所需 MBCS 字符串字节长度
CP_ACP,
0,
lpw, // 宽字符串指针
wLen, // 字符长度
NULL,
0, // 参数0表示计算转换后的字符空间
NULL,
NULL);
LPSTR lpa = new char [aLen];
WideCharToMultiByte(
CP_ACP,
0,
lpw,
wLen,
lpa, // 转换后的字符串指针
aLen, // 给出空间大小
NULL,
NULL);
// 此时,lpa 中保存着转换后的 MBCS 字符串
... ... ... ...
delete [] lpa;
函数 MultiByteToWideChar(),转换MBCS 到 UNICODE。使用范例:
LPCSTR lpa = "Hello,你好";
size_t aLen = strlen( lpa ) + 1;
int wLen = MultiByteToWideChar(
CP_ACP,
0,
lpa,
aLen,
NULL,
0);
LPOLESTR lpw = new WCHAR [wLen];
MultiByteToWideChar(
CP_ACP,
0,
lpa,
aLen,
lpw,
wLen);
... ... ... ...
delete [] lpw;
使用 ATL 提供的转换宏。
|
A2BSTR |
OLE2A |
T2A |
W2A |
|
A2COLE |
OLE2BSTR |
T2BSTR |
W2BSTR |
|
A2CT |
OLE2CA |
T2CA |
W2CA |
|
A2CW |
OLE2CT |
T2COLE |
W2COLE |
|
A2OLE |
OLE2CW |
T2CW |
W2CT |
|
A2T |
OLE2T |
T2OLE |
W2OLE |
|
A2W |
OLE2W |
T2W |
W2T |
上表中的宏函数,其实非常容易记忆:
|
2 |
好搞笑的缩写,to 的发音和 2 一样,所以借用来表示“转换为、转换到”的含义。 |
|
A |
ANSI 字符串,也就是 MBCS。 |
|
W、OLE |
宽字符串,也就是 UNICODE。 |
|
T |
中间类型T。如果定义了 _UNICODE,则T表示W;如果定义了 _MBCS,则T表示A |
|
C |
const 的缩写 |
使用范例:
#include<atlconv.h>
void fun()
{
USES_CONVERSION; // 只需要调用一次,就可以在函数中进行多次转换
LPCTSTR lp = OLE2CT( L"Hello,你好"));
... ... ... ...
// 不用显式释放 lp 的内存,因为
// 由于 ATL 转换宏使用栈作为临时空间,函数结束后会自动释放栈空间。
}
VARIANT
C++、BASIC、Java、Pascal、Script......计算机语言多种多样,而它们各自又都有自己的数据类型,COM 产生目的,其中之一就是要跨语言(注3)。而 VARIANT 数据类型就具有跨语言的特性,同时它可以表示(存储)任意类型的数据。从C语言的角度来讲,VARIANT 其实是一个结构,结构中用一个域(vt)表示------该变量到底表示的是什么类型数据,同时真正的数据则存贮在 union 空间中。结构的定义太长了(虽然长,但其实很简单)大家去看 MSDN 的描述吧,这里给出如何使用的简单示例:
学生:我想用 VARIANT 表示一个4字节长的整数,如何做?
老师:VARIANT v;v.vt=VT_I4; v.lVal=100;
学生:我想用 VARIANT 表示布尔值“真”,如何做?
老师:VARIANT v;v.vt=VT_BOOL; v.boolVal=VARIANT_TRUE;
在我们写程序的时候到比较简单,请大家遵守几个原则:
1、启动组件得到一个接口指针(Interface)后,不要调用AddRef()。因为系统知道你得到了一个指针,所以它已经帮你调用了AddRef()函数;
2、通过QueryInterface()得到另一个接口指针后,不要调用AddRef()。因为......和上面的道理一样;
3、当你把接口指针赋值给(保存到)另一个变量中的时候,请调用AddRef();
4、当不需要再使用接口指针的时候,务必执行Release()释放;
5、当使用智能指针的时候,可以省略指针的维护工作;
内存分配和释放
|
C语言 |
C++语言 |
Windows 平台 |
COM |
IMalloc 接口 |
BSTR |
|
|
申请 |
malloc() |
new |
GlobalAlloc() |
CoTaskMemAlloc() |
Alloc() |
SysAllocString() |
|
重新申请 |
realloc() |
GlobalReAlloc() |
CoTaskRealloc() |
Realloc() |
SysReAllocString() |
|
|
释放 |
free() |
delete |
GlobalFree() |
CoTaskMemFree() |
Free() |
SysFreeString() |
以上这些函数必须要按类型配合使用(比如:new 申请的内存,则必须用delete 释放)。
三、VC进行COM编程
VC进行COM编程,必须要掌握哪些COM理论知识。要学COM的基本原理,我推荐的书是《COM技术内幕》。但仅看这样的书是远远不够的,我们最终的目的是要学会怎么用COM去编程序,而不是拼命的研究COM本身的机制。所以我个人觉得对COM的基本原理不需要花大量的时间去追根问底,没有必要,是吃力不讨好的事。其实我们只需要掌握几个关键概念就够了。这里用VC编程所必需掌握的几个关键概念。
1) COM组件实际上是一个C++类,而接口都是纯虚类。组件从接口派生而来我们可以简单的用纯粹的C++的语法形式来描述COM是个什么东西:
class IObject
{
public:
virtual Function1(...) = 0;
virtual Function2(...) = 0;
....
};
class MyObject : public IObject
{
public:
virtual Function1(...){...}
virtual Function2(...){...}
....
};
看清楚了吗?IObject就是我们常说的接口,MyObject就是所谓的COM组件。切记接口都纯虚类,它所包含的函数都是纯虚函数,而且它没有成员变量。而COM组件就是从这些纯虚类继承下来的派生类,它实现了这些虚函数,仅此而已。从上面也可以看出,COM组件是以C++为基础的,特别重要的是虚函数和多态性的概念,COM中所有函数都是虚函数,都必须通过虚函数表VTable来调用,这一点是无比重要的,必需时刻牢记在心。
2) COM组件有三个最基本的接口类,分别是IUnknown、IClassFactory、IDispatchCOM规范规定任何组件、任何接口都必须从IUnknown继承,IUnknown包含三个函数,分别是QueryInterface、AddRef、Release。这三个函数是无比重要的,而且它们的排列顺序也是不可改变的。QueryInterface用于查询组件实现的其它接口,说白了也就是看看这个组件的父类中还有哪些接口类,AddRef用于增加引用计数,Release用于减少引用计数。引用计数也是COM中的一个非常重要的概念。大体上简单的说来可以这么理解,COM 组件是个DLL,当客户程序要用它时就要把它装到内存里。
另一方面,一个组件也不是只给你一个人用的,可能会有很多个程序同时都要用到它。但实际上DLL只装载了一次,即内存中只有一个COM组件,那COM组件由谁来释放?由客户程序吗?不可能,因为如果你释放了组件,那别人怎么用,所以只能由COM组件自己来负责。所以出现了引用计数的概念,COM维持一个计数,记录当前有多少人在用它,每多一次调用计数就加一,少一个客户用它就减一,当最后一个客户释放它的时侯,COM知道已经没有人用它了,它的使用已经结束了,那它就把它自己给释放了。
引用计数是COM编程里非常容易出错的一个地方,但所幸VC的各种各种的类库里已经基本上把AddRef的调用给隐含了,在我的印象里,我编程的时侯还从来没有调用过AddRef,我们只需在适当的时侯调用Release。至少有两个时侯要记住调用Release,第一个是调用了QueryInterface以后,第二个是调用了任何得到一个接口的指针的函数以后,记住多查MSDN以确定某个函数内部是否调用了AddRef,如果是的话那调用Release的责任就要归你了。
IUnknown的这三个函数的实现非常规范但也非常烦琐,容易出错,所幸的事我们可能永远也不需要自己来实现它们。
IClassFactory的作用是创建COM组件。我们已经知道COM组件实际上就是一个类,那我们平常是怎么实例化一个类对象的?是用‘new’命令!很简单吧,COM组件也一样如此。但是谁来new它呢?不可能是客户程序,因为客户程序不可能知道组件的类名字,如果客户知道组件的类名字那组件的可重用性就要打个大大的折扣了,事实上客户程序只不过知道一个代表着组件的128位的数字串而已,这个等会再介绍。所以客户无法自己创建组件,而且考虑一下,如果组件是在远程的机器上,你还能new出一个对象吗?所以创建组件的责任交给了一个单独的对象,这个对象就是类厂。
每个组件都必须有一个与之相关的类厂,这个类厂知道怎么样创建组件,当客户请求一个组件对象的实例时,实际上这个请求交给了类厂,由类厂创建组件实例,然后把实例指针交给客户程序。这个过程在跨进程及远程创建组件时特别有用,因为这时就不是一个简单的new操作就可以的了,它必须要经过调度,而这些复杂的操作都交给类厂对象去做了。
IClassFactory最重要的一个函数就是CreateInstance,顾名思议就是创建组件实例,一般情况下我们不会直接调用它,API函数都为我们封装好它了,只有某些特殊情况下才会由我们自己来调用它,这也是VC编写COM组件的好处,使我们有了更多的控制机会,而VB给我们这样的机会则是太少太少了。
IDispatch叫做调度接口。它的作用何在呢?这个世上除了C++还有很多别的语言,比如VB、VJ、VBScript、JavaScript等等。可以这么说,如果这世上没有这么多乱七八糟的语言,那就不会有IDispatch。:-) 我们知道COM组件是C++类,是靠虚函数表来调用函数的,对于VC来说毫无问题,这本来就是针对C++而设计的,以前VB不行,现在VB也可以用指针了,也可以通过VTable来调用函数了,VJ也可以,但还是有些语言不行,那就是脚本语言,典型的如VBScript、JavaScript。不行的原因在于它们并不支持指针,连指针都不能用还怎么用多态性啊,还怎么调这些虚函数啊。唉,没办法,也不能置这些脚本语言于不顾吧,现在网页上用的都是这些脚本语言,而分布式应用也是COM组件的一个主要市场,它不得不被这些脚本语言所调用,既然虚函数表的方式行不通,我们只能另寻他法了。时势造英雄,IDispatch应运而生。:-)
调度接口把每一个函数每一个属性都编上号,客户程序要调用这些函数属性的时侯就把这些编号传给IDispatch接口就行了,IDispatch再根据这些编号调用相应的函数,仅此而已。当然实际的过程远比这复杂,当给一个编号就能让别人知道怎么调用一个函数那不是天方夜潭吗,你总得让别人知道你要调用的函数要带什么参数,参数类型什么以及返回什东西吧,而要以一种统一的方式来处理这些问题是件很头疼的事。IDispatch接口的主要函数是Invoke,客户程序都调用它,然后Invoke再调用相应的函数,如果看一看MS的类库里实现Invoke的代码就会惊叹它实现的复杂了,因为你必须考虑各种参数类型的情况,所幸我们不需要自己来做这件事,而且可能永远也没这样的机会。
IUnknown接口的三个函数就是QueryInterface,AddRef和Release。
IDispatch接口有4个函数,解释语言的执行器就通过这仅有的4个函数来执行组件所提供的功能。IDispatch 接口用 IDL 形式说明如下:
[
object,
uuid(00020400-0000-0000-C000-000000000046), // IDispatch 接口的 IID =IID_IDispatch
pointer_default(unique)
]
interface IDispatch : IUnknown
{
typedef [unique] IDispatch *LPDISPATCH; // 转定义 IDispatch * 为 LPDISPATCH
HRESULT GetTypeInfoCount([out]UINT * pctinfo); // 有关类型库的这两个函数,咱们以后再说
HRESULT GetTypeInfo([in] UINTiTInfo,[in] LCID lcid,[out] ITypeInfo ** ppTInfo);
HRESULT GetIDsOfNames( // 根据函数名字,取得函数序号(DISPID)
[in] REFIID riid,
[in,size_is(cNames)] LPOLESTR * rgszNames,
[in] UINT cNames,
[in] LCID lcid,
[out,size_is(cNames)] DISPID * rgDispId
);
[local] // 本地版函数
HRESULT Invoke( // 根据函数序号,解释执行函数功能
[in] DISPIDdispIdMember,
[in] REFIID riid,
[in] LCID lcid,
[in] WORD wFlags,
[in, out] DISPPARAMS* pDispParams,
[out] VARIANT *pVarResult,
[out] EXCEPINFO *pExcepInfo,
[out] UINT *puArgErr
);
[call_as(Invoke)] // 远程版函数
HRESULT RemoteInvoke(
[in] DISPIDdispIdMember,
[in] REFIID riid,
[in] LCID lcid,
[in] DWORD dwFlags,
[in] DISPPARAMS *pDispParams,
[out] VARIANT * pVarResult,
[out] EXCEPINFO *pExcepInfo,
[out] UINT *pArgErr,
[in] UINT cVarRef,
[in,size_is(cVarRef)] UINT * rgVarRefIdx,
[in, out,size_is(cVarRef)] VARIANTARG * rgVarRef
);
}
3) dispinterface接口、Dual接口以及Custom接口
这是在ATL编程时用到的术语。在这里主要是想谈一下自动化接口的好处及缺点,用这三个术语来解释可能会更好一些,而且以后迟早会遇上它们,我将以一种通俗的方式来解释它们,可能并非那么精确,就好象用伪代码来描述算法一样。
所谓的自动化接口就是用IDispatch实现的接口。我们已经讲解过IDispatch的作用了,它的好处就是脚本语言象VBScript、JavaScript也能用COM组件了,从而基本上做到了与语言无关它的缺点主要有两个,第一个就是速度慢效率低。这是显而易见的,通过虚函数表一下子就可以调用函数了,而通过Invoke则等于中间转了道手续,尤其是需要把函数参数转换成一种规范的格式才去调用函数,耽误了很多时间。所以一般若非是迫不得已我们都想用VTable的方式调用函数以获得高效率。第二个缺点就是只能使用规定好的所谓的自动化数据类型。如果不用IDispatch我们可以想用什么数据类型就用什么类型,VC会自动给我们生成相应的调度代码。而用自动化接口就不行了,因为Invoke的实现代码是VC事先写好的,而它不能事先预料到我们要用到的所有类型,它只能根据一些常用的数据类型来写它的处理代码,而且它也要考虑不同语言之间的数据类型转换问题。所以VC自动化接口生成的调度代码只适用于它所规定好的那些数据类型,当然这些数据类型已经足够丰富了,但不能满足自定义数据结构的要求。你也可以自己写调度代码来处理你的自定义数据结构,但这并不是一件容易的事。
考虑到IDispatch的种种缺点(现在一般都推荐写双接口组件,称为dual接口,实际上就是从IDispatch继承的接口。我们知道任何接口都必须从IUnknown继承,IDispatch接口也不例外。那从IDispatch继承的接口实际上就等于有两个基类,一个是IUnknown,一个是IDispatch,所以它可以以两种方式来调用组件,可以通过IUnknown用虚函数表的方式调用接口方法,也可以通过IDispatch::Invoke自动化调度来调用这就有了很大的灵活性,这个组件既可以用于C++的环境也可以用于脚本语言中,同时满足了各方面的需要。
相对比的,dispinterface是一种纯粹的自动化接口,可以简单的就把它看作是IDispatch接口(虽然它实际上不是的),这种接口就只能通过自动化的方式来调用,COM组件的事件一般都用的是这种形式的接口。
Custom接口就是从IUnknown接口派生的类,显然它就只能用虚函数表的方式来调用接口了。
4) COM组件有三种,进程内、本地、远程。对于后两者情况必须调度接口指针及函数参数。
COM是一个DLL,它有三种运行模式。它可以是进程内的,即和调用者在同一个进程内,也可以和调用者在同一个机器上但在不同的进程内,还可以根本就和调用者在两台机器上。
这里有一个根本点需要牢记,就是COM组件它只是一个DLL,它自己是运行不起来的,必须有一个进程象父亲般照顾它才行,即COM组件必须在一个进程内.那谁充当看护人的责任呢?
先说说调度的问题。调度是个复杂的问题,以我的知识还讲不清楚这个问题,我只是一般性的谈谈几个最基本的概念。我们知道对于WIN32程序,每个进程都拥有4GB的虚拟地址空间,每个进程都有其各自的编址,同一个数据块在不同的进程里的编址很可能就是不一样的,所以存在着进程间的地址转换问题。这就是调度问题。对于本地和远程进程来说,DLL和客户程序在不同的编址空间,所以要传递接口指针到客户程序必须要经过调度。Windows经提供了现成的调度函数,就不需要我们自己来做这个复杂的事情了。对远程组件来说函数的参数传递是另外一种调度。
DCOM是以RPC为基础的,要在网络间传递数据必须遵守标准的网上数据传输协议,数据传递前要先打包,传递到目的地后要解包,这个过程就是调度,这个过程很复杂,不过Windows已经把一切都给我们做好了,一般情况下我们不需要自己来编写调度DLL。
我们刚说过一个COM组件必须在一个进程内。对于本地模式的组件一般是以EXE的形式出现,所以它本身就已经是一个进程。对于远程DLL,我们必须找一个进程,这个进程必须包含了调度代码以实现基本的调度。这个进程就是dllhost.exe。这是COM默认的DLL代理。实际上在分布式应用中,我们应该用MTS来作为DLL代理,因为MTS有着很强大的功能,是专门的用于管理分布式DLL组件的工具。
调度离我们很近又似乎很远,我们编程时很少关注到它,这也是COM的一个优点之一,既平台无关性,无论你是远程的、本地的还是进程内的,编程是一样的,一切细节都由COM自己处理好了,所以我们也不用深究这个问题,只要有个概念就可以了,当然如果你对调度有自己特殊的要求就需要深入了解调度的整个过程了,这里推荐一本《COM+技术内幕》,这绝对是一本讲调度的好书。
5) COM组件的核心是IDL。
我们希望软件是一块块拼装出来的,但不可能是没有规定的胡乱拼接,总是要遵守一定的标准,各个模块之间如何才能亲密无间的合作,必须要事先共同制订好它们之间交互的规范,这个规范就是接口。我们知道接口实际上都是纯虚类,它里面定义好了很多的纯虚函数,等着某个组件去实现它,这个接口就是两个完全不相关的模块能够组合在一起的关键试想一下如果我们是一个应用软件厂商,我们的软件中需要用到某个模块,我们没有时间自己开发,所以我们想到市场上找一找看有没有这样的模块,我们怎么去找呢?也许我们需要的这个模块在业界已经有了标准,已经有人制订好了标准的接口,有很多组件工具厂商已经在自己的组件中实现了这个接口,那我们寻找的目标就是这些已经实现了接口的组件,我们不关心组件从哪来,它有什么其它的功能,我们只关心它是否很好的实现了我们制订好的接口。这种接口可能是业界的标准,也可能只是你和几个厂商之间内部制订的协议,但总之它是一个标准,是你的软件和别人的模块能够组合在一起的基础,是COM组件通信的标准。
COM具有语言无关性,它可以用任何语言编写,也可以在任何语言平台上被调用。但至今为止我们一直是以C++的环境中谈COM,那它的语言无关性是怎么体现出来的呢?或者换句话说,我们怎样才能以语言无关的方式来定义接口呢?前面我们是直接用纯虚类的方式定义的,但显然是不行的,除了C++谁还认它呢?正是出于这种考虑,微软决定采用IDL来定义接口。说白了,IDL实际上就是一种大家都认识的语言,用它来定义接口,不论放到哪个语言平台上都认识它。我们可以想象一下理想的标准的组件模式,我们总是从IDL开始,先用IDL制订好各个接口,然后把实现接口的任务分配不同的人,有的人可能善长用VC,有的人可能善长用VB,这没关系,作为项目负责人我不关心这些,我只关心你最后把DLL拿给我。这是一种多么好的开发模式,可以用任何语言来开发,也可以用任何语言也欣赏你的开发成果。
6) COM组件的运行机制,即COM是怎么跑起来的。
这部分我们将构造一个创建COM组件的最小框架结构,然后看一看其内部处理流程是怎样的。
IUnknown *pUnk=NULL;
IObject *pObject=NULL;
CoInitialize(NULL);
CoCreateInstance(CLSID_Object, CLSCTX_INPROC_SERVER, NULL, IID_IUnknown,
(void**)&pUnk);
pUnk->QueryInterface(IID_IOjbect, (void**)&pObject);
pUnk->Release();
pObject->Func();
pObject->Release();
CoUninitialize();
CoCreateInstance身上,让我们来看看它内部做了一些什么事情。以下是它内部实现的一个伪代码:
CoCreateInstance(....)
{
.......
IClassFactory *pClassFactory=NULL;
CoGetClassObject(CLSID_Object, CLSCTX_INPROC_SERVER, NULL, IID_IClassFactory,(void**)&pClassFactory);
pClassFactory->CreateInstance(NULL, IID_IUnknown, (void**)&pUnk);
pClassFactory->Release();
........
}
这段话的意思就是先得到类厂对象,再通过类厂创建组件从而得到IUnknown指针。
继续深入一步,看看CoGetClassObject的内部伪码:
CoGetClassObject(.....)
{
//通过查注册表CLSID_Object,得知组件DLL的位置、文件名
//装入DLL库
//使用函数GetProcAddress(...)得到DLL库中函数DllGetClassObject的函数指针。
//调用DllGetClassObject
}
DllGetClassObject是干什么的,它是用来获得类厂对象的。只有先得到类厂才能去创建组件.
下面是DllGetClassObject的伪码:
DllGetClassObject(...)
{
......
CFactory* pFactory= new CFactory; //类厂对象
pFactory->QueryInterface(IID_IClassFactory, (void**)&pClassFactory);
//查询IClassFactory指针
pFactory->Release();
......
}
CoGetClassObject的流程已经到此为止,现在返回CoCreateInstance,看看CreateInstance的伪码:
CFactory::CreateInstance(.....)
{
...........
CObject *pObject = new CObject; //组件对象
pObject->QueryInterface(IID_IUnknown, (void**)&pUnk);
pObject->Release();
...........
}
上面是从COM+技术内幕中COPY来的一个例图,从图中可以清楚的看到CoCreateInstance的整个流程。
7) 一个典型的自注册的COMDLL所必有的四个函数
DllGetClassObject:用于获得类厂指针
DllRegisterServer:注册一些必要的信息到注册表中
DllUnregisterServer:卸载注册信息
DllCanUnloadNow:系统空闲时会调用这个函数,以确定是否可以卸载DLL
DLL还有一个函数是DllMain,这个函数在COM中并不要求一定要实现它,但是在VC生成的组件中自动都包含了它,它的作用主要是得到一个全局的实例对象。
8) 注册表在COM中的重要作用
首先要知道GUID的概念,COM中所有的类、接口、类型库都用GUID来唯一标识,GUID是一个128位的字串,根据特制算法生成的GUID可以保证是全世界唯一的。
COM组件的创建,查询接口都是通过注册表进行的。有了注册表,应用程序就不需要知道组件的DLL文件名、位置,只需要根据CLSID查就可以了。当版本升级的时侯,只要改一下注册表信息就可以神不知鬼不觉的转到新版本的DLL。
9)事件和通知
在实际开发中,COM 组件用线程方式下载网络上的一个文件,当我完成任务后,需要通知调用者。
|
通知方式 |
简单说明 |
|
|
直接消息 |
PostMessage() |
向窗口或线程发个消息 |
|
SendMessage() |
马上执行消息响应函数 |
|
|
SendMessage(WM_COPYDATA...) |
发消息的同时,还可以带过去一些自定义的数据 |
|
|
间接消息 |
InvalidateRect() |
被调用的函数会发送相关的一些消息 |
|
回调函数 |
GetOpenFileName()...... |
当用户改变文件选择的时候,执行回调函数 |
回调函数的方式,是设计 COM 通知方法的基础。回调函数,本质上是预先把某一函数的指针告诉我,当我有必要的时候,就直接呼叫该函数了,而这个回调函数做了什么,怎么做的,我是根本不关心的。好了,问你个问题:啥是 COM 的接口?接口其实就是一组相关函数的集合(这个定义不严谨,但你可以这么理解哈)。因此,在COM中不使用“回调函数”而是使用“回调接口”(说的再清楚一些,就是使用一大堆包装好的“回调函数”集) ,回调接口,我们也叫“接收器接口”。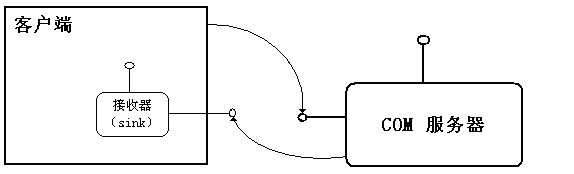
(图:客户端传递接收器接口指针给COM。当发生事件时,COM调用接收器接口函数完成通知)
连接点,通过连接点可以实现事件的回调。
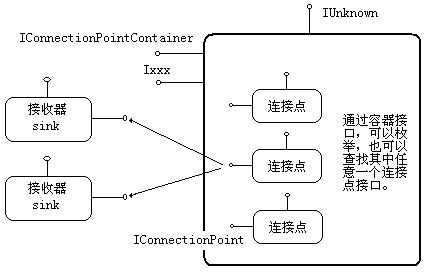
(图:连接点组件原理图。左侧为客户端,右侧为服务端(组件对象))
1、一个 COM 组件,允许有多个连接点对象(IConnectionPoint)。也就是说可以有多个发生“事件”的源头。上图就有3个连接点;
2、管理这些连接点的接口叫“连接点容器”(IConnectionPointContainer)。连接点容器接口特别简单,因为只有2个函数,一个是 FindConnectionPoint(),表示查找你想要的连接点;另一个是 EnumConnectionPoints(),表示列出所有的连接点,然后你去选择使用哪个。在实际的应用中,查找法使用最多,占90%,而枚举法使用只占 10%,一般在支持第三方的插件(Plug in)时才使用。
3、每一个连接点,可以被多个客户端的接收器(Sink)连接
10)代理和存根
COM两个组件之间不是直接通信,而是通过代理和存根来之间的通信来间接实现的。图中的channel是com库的一部分。 COM里,只有进程外组件才会用到代理(proxy)和存根(stub)。 代理在客户的进程内创建,存根在组件com对象的进程中创建。 每个接口的每个函数都有自己的代理和存根。
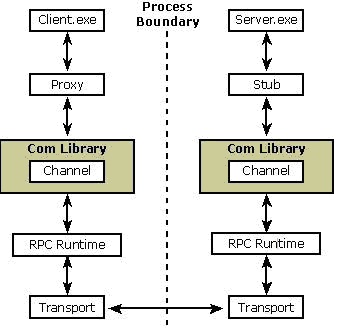
为什么要用代理和存根 ?
客 户为什么要用代理和存根,而不直接同对象连接呢?给你一个理由,对客户来说,他与所有com对象的连接都是通过指针来调用的, 而对服务来说,调用对象的接口函数也是通过指针来完成的,然而,指针只有在同一进程内才会有效。这样,代理和存根为了完成这个使命也就产生了。
代理和存根的作用不只这些,他还要打包所有的参数(包括接口指针),产生 RPC(远程进程调用),通向另一个进程,或者对象运行所在的另一台机器。
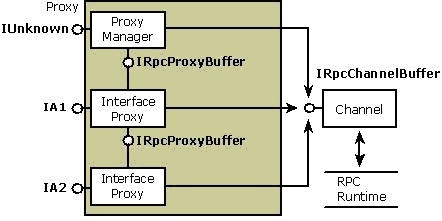
图: 代理的结构
上图所显示的代理结构支持参数的标准列集。每个接口的代理实现了IRpcProxyBuffer接口,用于内聚各个部分之间的相互通信。当代理准备把已列集的参数传递过进程边界时,他调用IRpcChannelBuffer 接口的方法(该接口由channel实现)。channel调用RPC运行库使数据传输到目的地。
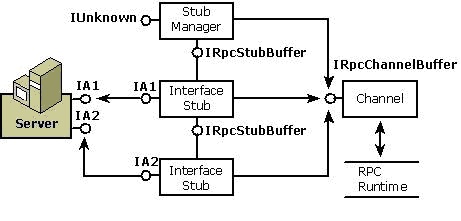
图: 存根的结构
如上图所示,每个接口的存根被连接到对象的相应接口上。chnnel分发传入的消息到适当的接口的存根。所有的组件通过IRpcChannelBuffer接口与chnnel交流,这个接口提供了与RPC运行库的连接。
列集(marshalling)
说到代理和存根,自然少不了列集,什么是列集?
列集,对函数参数进行打包处理得过程,因为指针等数据,必须通过一定得转换,才能被另一组件所理解,列集完成后,RPC调用就会产生。可以说列集是一种数据格式的转换方法。
列集有3种方式:
1. 类型库列集
它可以列集与OLEAUTOMATION兼容的任何接口,意思是你的接口的返回值必须是HRESULT,所使用的参数的类型也应该是与C++的VARIANT结构兼容。
2. 通过创建Stub / proxy DLL
这个DLL的源代由MIDL产生。你必须在服务器和客户机上都注册这个DLL(这是标准的marshal 方式)使用吃方法时,最好把stub / proxy代码编译作为一个独立的组件。
3. 自定义marshaling
自定义marshal要求在你的组件中必须实现IMarshal接口。当COM需要marchal时,他首先通过QueryInterface看你是否支 持IMarshal接口,如果你实现了该接口,也就是说,由你控制了你的COM的所有参数和返回值的打包、解包的方法模式。
代理和存根dll的建立
使用工具MIDL,对一个IDL文件,MIDL会分析自动产生相应的代理/存根 DLL的相关文件。
怎么使用代理和存根
COM组件对外输出接口有两种模式:TLB库((TypeLibrary)模式和代理/存根(Proxy/stud)模式。如果COM组件是通过TLB库模式输出的时候,将会生成一个.tlb文件,这种方法客户端调用也方便(直接导入即可),同时支持跨语言开发和调用,所以是VC默认的COM接口输出模式。但是该模式将不支持部分IDL语言定义的接口属性,例如:size_is,length_is,[]ref等相关属性。关于tlb的说明请参考http://msdn.microsoft.com/en-us/library/aa366757(v=vs.85).aspx文档。代理/存根(Proxy/stud)模式相对就比较麻烦,并且不能支持跨语言开发和调用,但是可以很好的支持IDL语言定义的各种属性。下面我们主要说明一下代理/存根(Proxy/stud)模式的生产和组件调用。关于IDL接口的定义和说明请参考http://msdn.microsoft.com/en-us/library/aa367091(v=VS.85).aspx文档。
代理/存根(Proxy/stud)模式下COM组件或者服务的生成:由于VC编译器默认生成的是tlb库模式,所以首先需要通过/notlb编译选项告诉编译器我们不需要tlb库输出,同时需要在资源文件(.rc)中将导入tlb库的命令取消(TYPELIB "Interface.tlb")。如果为services服务,在执行前面步骤操作后需要编写一个.mk文件。该文件主要用来将idl接口文件生产的.h, _i.c, _p.c,dlldata.c编译生产代理/存根(Proxy/stud)需要的dll文件, 并通过nmake-f DataExchangeServer.mk 命令编译和生产dll文件,最后通过regsvr32命令将dll注册为服务。
10)COM使用线程
单线程单元(STA)、多线程单元(MTA)
单线程单元:只允许一个线程访问组件,但是在一个进程中允许有多个单线程单元。
多线程单元:多个线程可以同时访问组件。
11)错误处理
在旧COM技术中,错误是通过方法返回HRESULT值来定义的。HRESULT的值是S_OK,表示方法成功。
新COM组件就实现接口ISupportErrorInfo,该接口不但提供了错误信息,还提供了帮助文件的链接、错误源,在方法返回时还会返回一个错误信息对象。
四、VC调用COM的方式
原文出处:http://topic.csdn.net/t/20040417/16/2977524.html,此篇转载稍有修改。
准备及条件:
COM服务器为进程内服务器,DLL名为simpCOM.dll,该组件只有一个接口IFoo,该接口只有一个方法HRESULT SayHello(void)
在SDK中调用
=====================================
1、最简单最常用的一种,用#import导入类型库,利用VC提供的智能指针包装类
演示代码:
#import "D:/Temp/vc/simpCOM/Debug/simpCOM.dll" no_namespace
CoInitialize(NULL);
IFooPtr spFoo = NULL;
spFoo.CreateInstance(__uuidof(Foo));
spFoo->SayHello();
spFoo.Release();/*晕死了,本来智能指针就是为了让用户不用关心这个的,可是我发现如果不手工调用一下的话,程序退出后会发生内存访问错误,我是在console中做试验的,哪位大侠知道怎么回事请一定指教*/
CoUninitialize();
/*lynn注:确实是IXXXPtr智能指针所引起的问题,正确的方式有:
1).限制智能指针作用域:
CoInitialize(NULL);
{
IFooPtr spFoo = NULL; //这样写也没问题,IFooPtr应该重载了赋值操作,但是IFooPtr是个类,不要把它当成真的原始指针了
spFoo.CreateInstance(__uuidof(Foo));
spFoo->SayHello();
// spFoo.Release();
}
CoUninitialize();
2).跟原句差不多:
CoInitialize(NULL);
IFooPtr spFoo = NULL;
spFoo.CreateInstance(__uuidof(Foo));
spFoo->SayHello();
// spFoo.Release();
spFoo = NULL; // 网上找的,所以可以肯定IFooPtr定义了赋值操作
CoUninitialize();
*/
2、引入midl.exe产生的*.h,*_i.c文件,利用CoCreateInstance函数来调用
演示代码:
/*在工程中加入*_i.c文件,例如本例的simpCOM_i.c,该文件定义了类和接口的guid值,如果不引入的话,会发生连接错误。*/
#include "D:/Temp/vc/simpCOM/simpCOM.h"
CoInitialize(NULL);
IFoo* pFoo = NULL;
HRESULT hr = CoCreateInstance(CLSID_Foo, NULL, CLSCTX_ALL, IID_IFoo, (void**)&pFoo);
if (SUCCEEDED(hr) && (pFoo != NULL))
{
pFoo->SayHello();
pFoo->Release();
}
CoUninitialize();
/*
lynn注: 二适合有COM组件源码的情况,比如自己编写的COM组件,在VS项目里的“生成的文件”里的那两个文件
*/
3、不用CoCreateInstance,直接用CoGetClassObejct得到类厂对象接口,然后用该接口的方法CreateInstance来生成实例。
演示代码:
/*前期准备如二方法所述*/
IClassFactory* pcf = NULL;
HRESULT hr = CoGetClassObject(CLSID_Foo, CLSCTX_ALL, NULL, IID_IClassFactory, (void**)&pcf);
if (SUCCEEDED(hr) && (pcf != NULL))
{
IFoo* pFoo = NULL;
hr = pcf->CreateInstance(NULL, IID_IFoo, (void**)&pFoo);
if (SUCCEEDED(hr) && (pFoo != NULL))
{
pFoo->SayHello();
pFoo->Release();
}
pcf->Release();
}
4、不用CoCreateInstance or CoGetClassObject,直接从dll中得到DllGetClassObject,接着生成类对象及类实例(本方法适合于你想用某个组件,却不想在注册表中注册该组件)
演示代码:
/*前期准备工作如二方法所述,事实上只要得到CLSID和IID的定义及接口的定义就行*/
typedef HRESULT (__stdcall * pfnGCO) (REFCLSID, REFIID, void**);
pfnGCO fnGCO = NULL;
HINSTANCE hdllInst = LoadLibrary("D://Temp//vc//simpCOM//Debug//simpCOM.dll");
fnGCO = (pfnGCO)GetProcAddress(hdllInst, "DllGetClassObject");
if (fnGCO != 0)
{
IClassFactory* pcf = NULL;
HRESULT hr=(fnGCO)(CLSID_Foo, IID_IClassFactory, (void**)&pcf);
if (SUCCEEDED(hr) && (pcf != NULL))
{
IFoo* pFoo = NULL;
hr = pcf->CreateInstance(NULL, IID_IFoo, (void**)&pFoo);
if (SUCCEEDED(hr) && (pFoo != NULL))
{
pFoo->SayHello();
pFoo->Release();
}
pcf->Release();
}
}
FreeLibrary(hdllInst);
在MFC中调用
=====================================
在MFC中除了上面的几种方法外,还有一种更方便的方法,就是通过ClassWizard利用类型库生成包装类,不过有个前提就是com组件的接口必须是派生自IDispatch
具体方法:
1、按Ctrl+W调出类向导,按Add Class按钮弹出新菜单,选From a type libarary,然后定位到simpCOM.dll,接下来会出来该simpCOM中的所有接口,选择你想生成的接口包装类后,向导会自动生成相应的.cpp和.h文件.
这样你就可以在你的MFC工程中像使用普通类那样使用COM组件了.
演示代码:
CoInitialize(NULL);
IFoo foo;
if (foo.CreateDispatch("simpCOM.Foo") != 0)
{
foo.SayHello();
foo.ReleaseDispatch();
}
CoUninitialize();
五、COM使用的注意细节
1.ConvertStringToBSTR 也是需要释放内存空间的
Example
// ConvertStringToBSTR.cpp
#include <comutil.h>
#include <stdio.h>
#pragma comment(lib, "comsupp.lib")
#pragma comment(lib, "kernel32.lib")
int main()
{
char* lpszText = "Test";
printf("char * text: %s/n", lpszText);
BSTR bstrText = _com_util::ConvertStringToBSTR(lpszText);
wprintf(L"BSTR text: %s/n", bstrText);
SysFreeString(bstrText);
}
或者:
char* pTemp;
CString csTemp;
pTemp =_com_util::ConvertBSTRToString(bsVal);
csTemp = pTemp;
delete pTemp;
pTemp = NULL;
2.对于throw()的函数,为了统一处理com错误,可以这样
inline void TESTHR(HRESULT x) {if FAILED(x) _com_issue_error(x);};
...
try
{
TESTHR(pConnection.CreateInstance(__uuidof(Connection))); //智能指针的CreateInstance是不抛异常的(根据HRESULTE判断调用是否成功),这里加了个宏就使异常处理统一了
pConnection->Open(strCnn, "", "", adConnectUnspecified);
pConnection->Open(strCnn, "", "", adConnectUnspecified);
}
catch(_com_error &e)
{
CString t;
t.Format("%s", e.ErrorMessage());
AfxMessageBox(t);
}
3、在stdafx.h文件导入dll能够让编译器在运行时连接dll的类型库,#import它能够自动产生一个对GUIDs的定义,同时自动生成对clsado对象的封装。同时能够列举它在类中所能找到的类型, VC++会在编译的时候自动生成两个文件:
一个头文件(.tlh),它包含了列举的类型和对类型库中对象的定义;
一个实现文件(.tli)对类型库对象模型中的方法产生封装。
Namespace(名字空间)用来定义一个名字空间,使用unsing就可以将当前的类型上下文转换名字空间所定地,让我们可以访问服务组件的方法。
如果我们修改了服务组件程序,建议删除这两个文件后重新完整编译工程,以便让编译器重新列举类的属性以及函数。
4、COM接口类型
COM接口定义时可分为直接继承IUnkown接口(vtable结构)、直接声明为dispinterface和由IDispatch继承三种形式,一般来说分别称之为纯接口、分发接口和双接口
纯接口只有C/C++语言可以声明,理所当然是.h头文件的形式,也只有C/C++语言可以感知,但是通常并不使用C/C++直接书写.h头文件,而是使用midl命令对idl文件(接口定义文件)生成C/C++同时兼容的.h头文件。
VB和脚本语言只能识别分发接口的结构,这些语言的运行时库或虚拟机可以生成和识别.tlb文件,而.tlb文件也可以通过使用midl命令编译idl文件生成。
可以看出.h头文件和.tlb类型库文件实际上是起到相同的作用,即定义和感知接口的二进制结构,只不过一个是使用文本形式,一个是使用字节码形式。
需要说明的是C/C++语言是可以感知分发接口的结构的,因为它的编译器可以解析.tlb类型库文件,方法是:#import"xxx.tlb" no_namespace,这就是说VB和脚本语言实现的COM组件可以被C/C++语言环境使用,而C/C++语言定义的接口(.h头文件中定义)不能被VB和脚本语言感知,为了解决这个问题双接口应运而生,双接口的结构实际上就是纯接口+分发接口。在使用C/C++语言开发COM组件时,使用双接口定义就可以被VB和脚本语言使用了,当然双接口的接口函数的参数必须服从和分发接口情况下一样的限制,即必须是OLE变量兼容类型(Variant兼容类型)。
5、COM线程模型
COM提供的线程模型共有三种:Single-ThreadedApartment(STA 单线程套间)、MultithreadedApartment(MTA 多线程套间)和NeutralApartment/Thread Neutral Apartment/Neutral Threaded Apartment(NA/TNA/NTA中立线程套间,由COM+提供)。虽然它们的名字都含有套间这个词,这只是COM运行时期库(注意,不是COM规范,以下简称COM)使用套间技术来实现前面的三种线程模型,应注意套间和线程模型不是同一个概念。COM提供的套间共有三种,分别一一对应。而线程模型的存在就是线程规则的不同导致的,而所谓的线程规则就只有两个:代码是线程安全的或不安全的,即代码访问公共数据时会或不会发生访问冲突。由于线程模型只是个模型,概念上的,因此可以违背它,不过就不能获得COM提供的自动同步调用及兼容等好处了。
STA 一个对象只能由一个线程访问(通过对象的接口指针调用其方法),其他线程不得访问这个对象,因此对于这个对象的所有调用都是同步了的,对象的状态(也就是对象的成员变量的值)肯定是正确变化的,不会出现线程访问冲突而导致对象状态错误。其他线程要访问这个对象,必须等待,直到那个唯一的线程空闲时才能调用对象。注意:这只是要求、希望、协议,实际是否做到是由COM决定的。如上所说,这个模型很像Windows提供的窗口消息运行机制,因此这个线程模型非常适合于拥有界面的组件,像ActiveX控件、OLE文档服务器等,都应该使用STA的套间。
MTA 一个对象可以被多个线程访问,即这个对象的代码在自己的方法中实现了线程保护,保证可以正确改变自己的状态。这对于作为业务逻辑组件或干后台服务的组件非常适合。因为作为一个分布式的服务器,同一时间可能有几千条服务请求到达,如果排队进行调用,那么将是不能想像的。注意:这也只是一个要求、希望、协议而已。
NA 一个对象可以被任何线程访问,与MTA不同的是任何线程,而且当跨套间访问时(后面说明),它的调用费用(耗费的CPU时间及资源)要少得多。这准确的说都已经不能算是线程模型了,它是结合套间的具体实现而提出的要求,它和MTA不同的是COM的实现方式而已。
STA套件的初始化方式(两种方式等效):
1,CoInitialize(nil);
2,CoInitializeEx(nil,COINIT_APARTMENTTHREADED);
MTA套间的初始化方式:
1,CoInitializeEx(nil,COINIT_MULTITHREADED);
编写可以工作的COM客户端
要编写可以工作的COM客户端,需要遵循三条规则。牢记这些规则,你就可以在编写COM客户端时避免严重的错误。
规则1:客户线程必须调用CoInitialize[Ex]
线程做任何与COM相关的操作之前,必须调用CoInitialize或者CoInitializeEx初始化COM。如果客户程序有20个线程,其中10个使用COM,则这10个线程都应该调用CoInitialize或者CoInitializeEx。调用线程将在这两个API中被分配给一个套间。对于没有分配给套间的线程,COM是无法施行并发规则的。此外还要记住,成功调用了CoInitialize或者CoInitializeEx的线程应该在终止前调用CoUninitialize。否则,由CoInitialize[Ex]分配的资源将直到进程终止才释放。
这条规则看起来很简单,只是一个函数调用而已。但是你会惊奇地发现,这条规则经常被违背。违背这条规则的错误一般在调用CoCreateInstance或者其他COM API时展现。但是有时候问题直到很晚才出现,而且客户端的错误似乎与没有初始化COM没有明显的关系。
具有讽刺意味的是,有时候开发者不调用CoInitialize[Ex]的原因是,微软告诉他们不需要调用。MSDN中有篇文章说COM客户端有时候可以避免调用这个函数。但文章随后说这可能会导致拒绝访问。我近期收到一个开发者的电话,说客户线程调用Release的时候会死锁或者发生拒绝访问异常。原因是?有些线程没有调用CoInitialize[Ex]就发起方法调用了,结果调用Release的时候发生问题了。幸运地是,解决问题只需要简单地加几个CoInitialize[Ex]调用。
记住:调用CoInitialize[Ex]总是没有坏处的。对于调用COM API或者以任何方式使用COM对象的线程,调用CoInitialize[Ex]应该说是必须的。
规则2:STA线程需要消息循环
如果不理解单线程套间机制,这条规则看起来不那么明显。客户调用基于STA的对象时,调用将被传递到STA中运行的线程。COM通过向STA的隐藏窗口投递消息来完成这种传递。那么,如果STA中的线程不接收和分发消息将发生什么?调用将在RPC通道中消失,永远也不返回。它将永远凋谢在STA的消息队列中(It will languish in the STA's messagequeue forever)。
开发者问我为什么方法调用不返回的时候,我首先问他们“你调用的对象是在STA中吗?如果是,驱动STA的线程是否有消息循环?”。多半的回答是“我不知道”。如果你不知道,你就是在玩火。调用CoInitialize,或者使用参数COINIT_APARTMENTTHREADED调用CoInitializeEx,或者调用MFC的AfxOleInit的时候,线程被分配到一个STA中。如果随后在这个STA中创建对象,而STA线程又没有消息泵,那么对象不能接收来自其他套间的客户的方法调用。消息泵可以这样简单:
MSG msg;
while (GetMessage(&msg, 0, 0, 0))
{
DispatchMessage (&msg)
}
如果缺少这些简单的语句,把线程放入STA时要当心。一个常见的情况是MFC应用程序启动工作线程(MFC工作线程的定义是,缺少消息泵的线程),而线程调用AfxOleInit将自身放入到STA中。如果STA不容纳任何对象,或者虽然容纳对象但是却没有来自其他套间的客户,你不会遇到问题。但是如果STA容纳导出接口指针到其他套间的对象,则对这些接口指针的调用将永远不会返回。
规则3:不要在套间之间传递原始未列集的接口指针
设想编写一个有两个线程的COM客户端。两个线程都调用CoInitialize进入一个STA,然后其中一个线程——线程A,使用CoCreateInstance创建一个COM对象。线程A想要与线程B共享从CoCreateInstance返回的接口指针。所以线程A将接口指针赋值给一个全局变量,然后通知线程B指针已经准备好了。线程B从全局变量读取接口指针并且对对象发起调用。这个过程有什么错误吗?
这个过程会引发事故。问题是线程A向其他套间中的线程传递了原始未列集的接口指针。线程B应该只通过列集到线程B所属套间的接口指针与对象通信。
这里“列集(Marshaling)”的意思是给COM在线程B所属套间中创建新代理的机会,让线程B可以安全地进行调用。在套间之间传递原始接口指针的后果可以从与时间极其相关(也很难重现)的数据损坏到完全死锁。
如果线程A列集接口指针,则可以安全地与线程B共享接口指针。COM客户端有两种基本的方法将接口指针列集到其他套间:
使用COM API函数CoMarshalInterThreadInterfaceInStream和CoGetInterfaceAndReleaseStream。
线程A调用CoMarshalInterThreadInterfaceInStream列集接口指针,线程B调用CoGetInterfaceAndReleaseStream进行散集。通过函数CoGetInterfaceAndReleaseStream,COM在调用者套间中创建新的代理。如果接口指针不需要进行列集(比如说,两个线程共享同一个套间时),CoGetInterfaceAndReleaseStream会智能地不创建代理。
使用在Windows NT4.0 Service Pack 3中首次引入的全局接口表(Global Interface Table,GIT)。
GIT是每个进程一个的表格,让各个线程可以安全地共享接口指针。如果线程A想要与同一个进程中的其他线程共享接口指针,可以使用IGlobalInterfaceTable::RegisterInterfaceInGlobal来将接口指针放到GIT中。然后想要使用接口的线程可以调用IGlobalInterfaceTable::GetInterfaceFromGlobal来获取接口指针。神奇之处在于线程从GIT获取接口指针的时候,COM会将接口指针列集到获取线程所属的套间中。
有没有不列集需要与其他线程共享的接口指针也OK的情况?有。如果两个线程属于同一个套间,则可以共享原始未列集的接口指针,而这只可能在两个线程都属于MTA时发生。如果不确定是否需要,请进行列集。调用CoMarshalInterThreadInterfaceInStream和CoGetInterfaceAndReleaseStream或者使用GIT总是无害的,因为COM只在必要的时候才进行列集。
编写可以工作的COM服务器
编写COM服务器时也应该遵守一些规则。
规则1:保护ThreadingModel=Apartment的对象的共享数据
标记对象的ThreadingModel=Apartment就可以不考虑线程安全问题?这是关于COM编程的一个最常见的错误想法。注册进程内对象的ThreadingModel=Apartment暗示COM,对象(以及从DLL创建的其他对象)会以线程安全的方式访问共享数据。这意味着已经使用临界区或者其他线程同步原语来保证在任何时刻只有一个线程可以接触到共享数据。对象之间数据共享通常有三种方式:
DLL中声明全局变量
C++类中的静态成员变量
静态局部变量
为什么线程同步对于ThreadingModel=Apartment的对象是很重要的?考虑从同一个DLL创建两个对象A和B的情况。假定两个对象都读写在DLL中声明的一个全局变量。因为标记为ThreadingModel=Apartment,对象可能分别在不同的STA中创建和运行,因此,也是在不同的线程中运行。但是两个对象访问的全局变量是共享的,只在进程内实例化一次。如果来自A和B的调用几乎同时发生,而且A写入那个变量,B读取那个变量(或者相反),那么变量可能被破坏,除非串行化线程的操作。如果不提供同步机制,那么多数时候会遇到问题。最终两个线程可能在共享数据上发生冲突,后果无法预知。
存在不需要同步机制就可以安全地访问共享数据的情况吗?存在。下列条件下可以不需要同步机制:
没有为对象注册ThreadingModel值(也称作ThreadingModel=None或者ThreadingModel=Single)时,所有对象在相同STA(主STA)和相同线程中运行,因此不会在共享数据上发生冲突。
虽然标记为ThreadingModel=Apartment,但是确信对象将在相同的STA中运行(比如说,所有对象都由同一个STA线程创建)。
确信对象不会被并发地调用时。
对于除此之外的情况,要确保ThreadingModel=Apartment的对象以线程安全的方式访问共享数据,只有这样才是正确完成了任务。
规则2:标记为ThreadingModel=Free或者ThreadingModel=Both的对象应该是线程安全的。
标记对象是ThreadingModel=Free或者ThreadingModel=Both时,对象将被或者可能被放入到MTA中。记住:COM不会串行化对基于MTA的对象的调用。因此,毫无疑问地(beyond the shadow of a doubt),除非确信对象的客户不会进行并发调用,对象应该是完全线程安全的。这意味着除了要同步由多个实例共享的数据之外,还必须同步对非静态成员变量的访问。编写线程安全的代码不容易,但是如果准备使用MTA,就必须这么做。
规则3:避免在标记为ThreadingModel=Free或者ThreadingModel=Both的对象里使用线程局部存储(TLS)
一些Windows程序员使用线程局部存储临时保存数据。设想在实现一个COM方法时,需要缓存一些关于当前调用的信息,以备下次调用时使用。这时你可能很想使用TLS。在STA中,这样做没问题。但是如果对象在MTA中,就应该像躲避瘟疫那样避免使用TLS。
为什么?因为进入MTA的调用被传递给RPC线程。每次调用可能被传递给不同的RPC线程,即使调用都是来自于同一个线程中的同一个调用者。一个线程不能访问另一个线程的线程局部存储。所以如果调用1到达线程A,对象将数据保存在TLS中;然后调用2到达线程B,对象试图取出在调用1中存入TLS的数据时,会找不到数据。这个道理很简单。
对于基于MTA的对象,在方法调用之间使用TLS缓存数据时要注意,这种方法只在所有的方法调用来自于对象所在的MTA中的同一个线程时才可以正确工作。
参考资料:
《COM技术内幕》
COM 组件设计与应用
http://www.vckbase.com/document/viewdoc/?id=1483
vc中调用Com组件方法
http://www.cppblog.com/woaidongmao/archive/2011/01/10/138250.html
理解COM套间:
http://www.cnblogs.com/Quincy/archive/2011/03/03/1969510.html
[转] COM编程总结的更多相关文章
- 从直播编程到直播教育:LiveEdu.tv开启多元化的在线学习直播时代
2015年9月,一个叫Livecoding.tv的网站在互联网上引起了编程界的注意.缘于Pingwest品玩的一位编辑在上网时无意中发现了这个网站,并写了一篇文章<一个比直播睡觉更奇怪的网站:直 ...
- JavaScript之父Brendan Eich,Clojure 创建者Rich Hickey,Python创建者Van Rossum等编程大牛对程序员的职业建议
软件开发是现时很火的职业.据美国劳动局发布的一项统计数据显示,从2014年至2024年,美国就业市场对开发人员的需求量将增长17%,而这个增长率比起所有职业的平均需求量高出了7%.很多人年轻人会选择编 ...
- 读书笔记:JavaScript DOM 编程艺术(第二版)
读完还是能学到很多的基础知识,这里记录下,方便回顾与及时查阅. 内容也有自己的一些补充. JavaScript DOM 编程艺术(第二版) 1.JavaScript简史 JavaScript由Nets ...
- [ 高并发]Java高并发编程系列第二篇--线程同步
高并发,听起来高大上的一个词汇,在身处于互联网潮的社会大趋势下,高并发赋予了更多的传奇色彩.首先,我们可以看到很多招聘中,会提到有高并发项目者优先.高并发,意味着,你的前雇主,有很大的业务层面的需求, ...
- C#异步编程(一)
异步编程简介 前言 本人学习.Net两年有余,是第一次写博客,虽然写的很认真,当毕竟是第一次,肯定会有很多不足之处, 希望大家照顾照顾新人,有错误之处可以指出来,我会虚心接受的. 何谓异步 与同步相对 ...
- UE4新手之编程指南
虚幻引擎4为程序员提供了两套工具集,可共同使用来加速开发的工作流程. 新的游戏类.Slate和Canvas用户接口元素以及编辑器功能可以使用C++语言来编写,并且在使用Visual Studio 或 ...
- C#与C++的发展历程第三 - C#5.0异步编程巅峰
系列文章目录 1. C#与C++的发展历程第一 - 由C#3.0起 2. C#与C++的发展历程第二 - C#4.0再接再厉 3. C#与C++的发展历程第三 - C#5.0异步编程的巅峰 C#5.0 ...
- 猫哥网络编程系列:HTTP PEM 万能调试法
注:本文内容较长且细节较多,建议先收藏再阅读,原文将在 Github 上维护与更新. 在 HTTP 接口开发与调试过程中,我们经常遇到以下类似的问题: 为什么本地环境接口可以调用成功,但放到手机上就跑 ...
- 关于如何提高Web服务端并发效率的异步编程技术
最近我研究技术的一个重点是java的多线程开发,在我早期学习java的时候,很多书上把java的多线程开发标榜为简单易用,这个简单易用是以C语言作为参照的,不过我也没有使用过C语言开发过多线程,我只知 ...
- 异步编程 In .NET
概述 在之前写的一篇关于async和await的前世今生的文章之后,大家似乎在async和await提高网站处理能力方面还有一些疑问,博客园本身也做了不少的尝试.今天我们再来回答一下这个问题,同时我们 ...
随机推荐
- JVM Inline
http://www.ssw.uni-linz.ac.at/Research/Papers/Wimmer08PhD/Wimmer08PhD.pdf http://www.azulsystems.com ...
- ny225 小明求素数积
小明求素数积时间限制:1000 ms | 内存限制:65535 KB 难度:1描述 小明最近遇到了一个素数题,是给你一个正整数N(2=<N<=1000)让你求出2~N的所有素数乘积的后 ...
- 将socket通信变成并发的方式
一 利用multiprocessing模块,开启多进程,实现socket通信并发 1. 开启子进程的两种方式 import time import random from multiprocessin ...
- HttpClient 教程 (一)
转自:http://www.cnblogs.com/loveyakamoz/archive/2011/07/21/2112804.html HttpClient 教程 (一) 前言 超文本传输协议 ...
- JSON数据乱码问题
http://ifeve.com/json-code-problem/ ***************************** 背景 程序员一提到编码应该都不陌生,像gbk.utf-8.ascii ...
- python 字典格式嵌套,相同项做叠加
all_dict = {} for tg_id in ['com.qq_a','com.qq_b','com.qq_c','com.qq_c']: tmp_dict = all_dict.get(tg ...
- 获取Django中model字段名 字段的verbose_name
obj._meta.fields 为关键 obj为model类 推荐使用函数 from django.apps import apps def getmodelfield(appname,modeln ...
- xcode常见报错调试
转载来自于:http://www.cnblogs.com/g-ios/p/4625912.html(广_ios博客园) BMKGeoCodeSearch 反向地理编码一直失败 Location 申请的 ...
- [转]C#读取Word指定页的内容
/// <summary> /// Word按页读取内容 /// </summary> /// <param name="page">页数< ...
- C语言 · 用宏求球的体积
算法提高 7-1用宏求球的体积 时间限制:1.0s 内存限制:256.0MB 问题描述 使用宏实现计算球体体积的功能.用户输入半径,系统输出体积.不能使用函数,pi=3.141592 ...