视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
1.Bag-of-words模型简介
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。 也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。举个例子就好理解:
例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “likes”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序。
Bag-of-words模型应用于图像表示:
为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
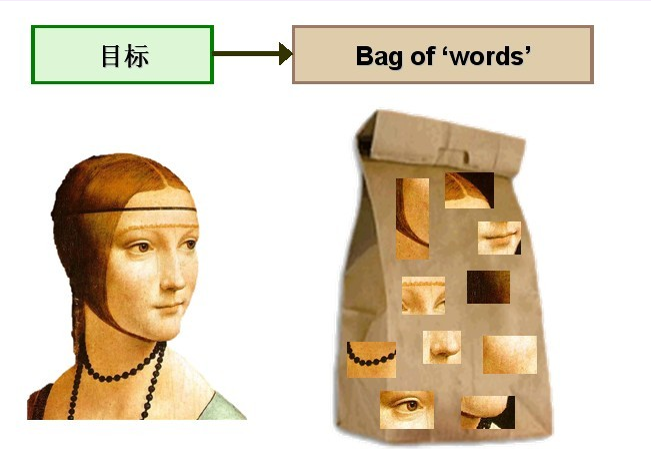
视觉词典的生成流程:

由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:(1)特征检测,(2)特征表示,(3)单词本的生成。 下图是从图像中提取出相互独立的视觉词汇:

通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛, 嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
构建BOW码本步骤:
利用K-Means算法构造单词表。用K-means对第二步中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
假定我们将K设为4,那么单词表的构造过程如下图所示:
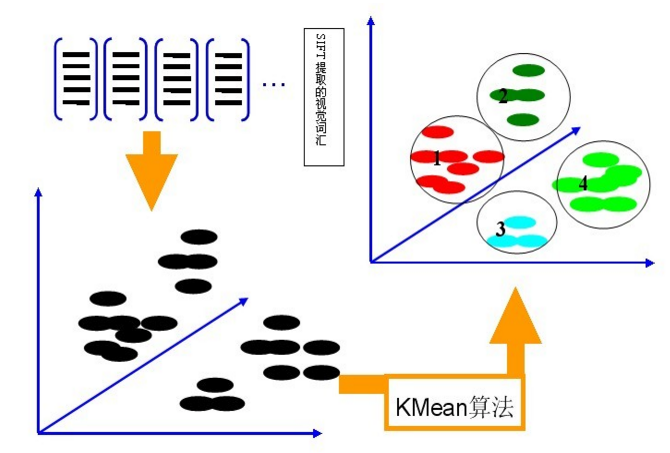
第三步:
利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。请看下图:
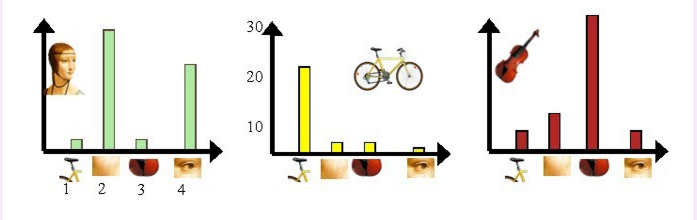
我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示:
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
总结一下步骤:
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)的更多相关文章
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(2)
聚类概念: 聚类:简单地说就是把相似的东西分到一组.同 Classification (分类)不同,分类应属于监督学习.而在聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到 ...
- 第六篇 视觉slam中的优化问题梳理及雅克比推导
优化问题定义以及求解 通用定义 解决问题的开始一定是定义清楚问题.这里引用g2o的定义. \[ \begin{aligned} \mathbf{F}(\mathbf{x})&=\sum_{k\ ...
- 词袋和 TF-IDF 模型
做文本分类等问题的时,需要从大量语料中提取特征,并将这些文本特征变换为数值特征.常用的有词袋模型和TF-IDF 模型 1.词袋模型 词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的 ...
- 视觉slam十四讲开源库安装教程
目录 前言 1.Eigen线性代数库的安装 2.Sophus李代数库的安装 3.OpenCV计算机视觉库的安装 4.PCL点云库的安装 5.Ceres非线性优化库的安装 6.G2O图优化库的安装 7. ...
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- 视觉SLAM关键方法总结
点"计算机视觉life"关注,置顶更快接收消息! 最近在做基于激光信息的机器人行人跟踪发现如果单独利用激光信息很难完成机器人对行人的识别.跟踪等功能,因此考虑与视觉融合的方法,这样 ...
- (转) SLAM系统的研究点介绍 与 Kinect视觉SLAM技术介绍
首页 视界智尚 算法技术 每日技术 来打我呀 注册 SLAM系统的研究点介绍 本文主要谈谈SLAM中的各个研究点,为研究生们(应该是博客的多数读者吧)作一个提纲挈领的摘要.然后,我 ...
- NLP从词袋到Word2Vec的文本表示
在NLP(自然语言处理)领域,文本表示是第一步,也是很重要的一步,通俗来说就是把人类的语言符号转化为机器能够进行计算的数字,因为普通的文本语言机器是看不懂的,必须通过转化来表征对应文本.早期是基于规则 ...
随机推荐
- Linux下adb的配置
进入当前用户主目录 yongdaimi@ubuntu:~$ cd ~ 打开.bashrc文件 yongdaimi@ubuntu:~$ vi .bashrc 在文件末尾添加下列代码 export ADB ...
- 每日英语:China's Retirement Age Sets Experts at Odds
The politically explosive issue of the official retirement age has drawn academics from two of China ...
- nyoj 504 课程设计
课程设计 时间限制:3000 ms | 内存限制:65535 KB 难度:2 描述 新学期伊始,Gangster 老师又在为如何给学生分配课程设计题目而犯愁,Gangster老师老共有 N 名学生 ...
- Django——model基础
ORM 映射关系: 表名 <-------> 类名 字段 <-------> 属性 表记录 <------->类实例对象 创建表(建立模型) 实例:我们来假定下 ...
- gulp——myself配置
var gulp = require('gulp'), uglify = require('gulp-uglify'), concat = require('gulp-concat'); var pu ...
- HttpClient 教程 (五)
第五章 HTTP客户端服务 5.1 HttpClient门面 HttpClient接口代表了最重要的HTTP请求执行的契约.它没有在请求执行处理上强加限制或特殊细节,而在连接管理,状态管理,认证和处理 ...
- BAT-使用BAT方法清理Delphi临时文件
@echo offdel /S *.~*del /S *.dcudel /S *.dskdel /S *.hppdel /S *.ddpdel /S *.mpsdel /S *.mptdel /S * ...
- JDBC的介绍2
一.基础知识 1. 数据持久化 持久化(persistence):对象在内存中创建后,不能永久存在.把对象永久的保存起来就是持久化的过程.而持久化的实现过程大多通过各种关系数据库来完成. 持久化的主要 ...
- ubuntu 14.04 安装中文输入法
记录Ubuntu 14.04 里面安装中文输入法的过程 先安装如下包 sudo apt-get install ibus sudo apt-get install ibus ibus-clutter ...
- DRAM 各项基本参数记录
记录一下DRAM的各项基本参数 tCL CAS Latency CAS 潜伏期, 列地址寻找/读写命令执行完毕,准备要读出来,需要一个延时缓一缓 tRAS: RAS Active Timeing 行有 ...