Hdfs&MapReduce测试
Hdfs&MapReduce测试
测试 上传文件到hdfs
随意打开一个文件夹传一个文件试试(把javafx-src.zip传到hdfs的/根目录下):hadoop fs -put javafx-src.zip hdfs://node01:9000/
用客户端(windows主机)浏览器打开 http://node01:50070 能看到这文件(当然,先要在windows配置下hosts,加一行node01 192.168.216.100)

测试 运行一个MapReduce程序
cd hadoop-3.0.0/share/hadoop/mapreduce 有个example程序jar包
hadoop jar hadoop-mapreduce-examples-3.0.0.jar pi 5 5 运行其中一个pi程序,参数是map的任务数量和每个map的取样数
运行失败,log如下
Current usage: 38.3 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.
解决方案:https://blog.csdn.net/paicMis/article/details/73477019 按照这个的方法三,到mapred-site.xml中设置map和reduce任务的内存配置
我设置的参数如下:
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2048M</value>
</property>
再次运行成功。
Hdfs的实现思想粗略
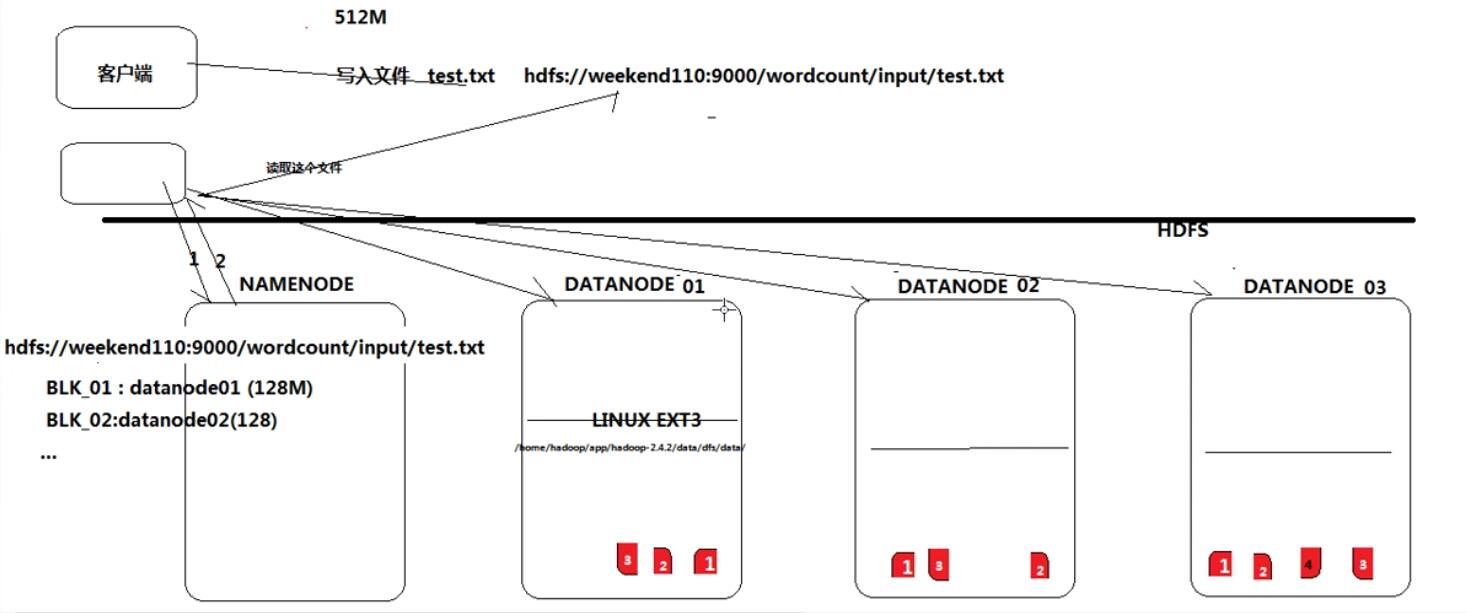
- hdfs是通过分布式集群来存储文件,但为客户端提供了一个便捷的访问方式(一个虚拟的目录结构)
- 文件存储到hdfs集群中去的时候是被切分成block的(由客户端负责切分)
- 文件的block存放在若干台datanode节点上(由hdfs负责拷贝和互传,拷贝出来的第一个副本会优先放在另一个机架上)
- hdfs文件系统中的文件与真实的block之间的映射关系,用namenode管理
- 每一个block在集群中会存储多个副本,可以提高数据的可靠性和访问的吞吐量,提高并发能力
Hdfs的shell操作
基本跟linux上的shell操作类似。hadoop fs(file system)-xx
最常用的shell指令:
hadoop fs -ls
hadoop fs -cat
hadoop fs -put
hadoop fs -get
试试看查看文件
[thousfeet@node01 mapreduce]$ hadoop fs -ls /
Found 5 items
-rw-r--r-- 1 thousfeet supergroup 5202881 2018-03-23 11:30 /javafx-src.zip
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 15:30 /output
drwx------ - thousfeet supergroup 0 2018-03-23 11:42 /tmp
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 11:42 /user
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 12:08 /wordcount
第二列的 1 表示这个文件在hdfs中的副本数,文件夹是元数据是个虚拟的东西,所以没有副本
Hdfs&MapReduce测试的更多相关文章
- 4 weekend110的hdfs&mapreduce测试 + hdfs的实现机制初始 + hdfs的shell操作 + 无密登陆配置
Hdfs是根/目录,windows是每一个盘符, 1 从Linux里传一个到,hdfs里去 2 从hdfs里下一个到,linux里去 想从hdfs里,下载到linux, 涨知识,记住,hdfs是建 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- HDFS部署测试记录(2019/05)
目录 HDFS部署测试记录 0.HDFS基础知识 1.基本组成结构与文件访问过程 2.NameNode启动时如何维护元数据 3.HDFS文件上传流程 1.系统环境 1.安装大致记录: 2.磁盘分区 3 ...
- Alluxio+HDFS+MapReduce集成及测试
目录 1.在 HDFS 上配置 Alluxio 1.1.节点角色 1.2.软件版本 1.3.准备工作 1.3.1.设置 SSH 免密登录 1.3.2.安装 JDK 1.3.3.安装 Hadoop 1. ...
- 【Hadoop测试程序】编写MapReduce测试Hadoop环境
我们使用之前搭建好的Hadoop环境,可参见: <[Hadoop环境搭建]Centos6.8搭建hadoop伪分布模式>http://www.cnblogs.com/ssslinppp/p ...
- YARN集群的mapreduce测试(六)
两张表链接操作(分布式缓存): ----------------------------------假设:其中一张A表,只有20条数据记录(比如group表)另外一张非常大,上亿的记录数量(比如use ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- YARN集群的mapreduce测试(四)
将手机用户使用流量的数据进行分组,排序: 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryN ...
随机推荐
- jQuery中hover与mouseover和mouseout的区别分析
本文实例分析了jQuery中hover与mouseover和mouseout的区别.分享给大家供大家参考,具体如下: 以前一直以为在jquery中其实mouseover和mouseout两个事件等于h ...
- 吴恩达《深度学习》第四门课(3)目标检测(Object detection)
3.1目标定位 (1)案例1:在构建自动驾驶时,需要定位出照片中的行人.汽车.摩托车和背景,即四个类别.可以设置这样的输出,首先第一个元素pc=1表示有要定位的物体,那么用另外四个输出元素表示定位框的 ...
- 第8章 scrapy进阶开发(2)
8-4 selenium集成到scrapy中 其实也没什么好说的直接上代码 这是在middlewares.py中定义的一个class: from selenium.common.exceptions ...
- VS中特殊的注释——TODO/UNDONE/HACK的使用
在代码的后面添加形如下面注释: //TODO: (未实现)…… //UNDONE:(没有做完)…… //HACK:(修改)…… 等到再次打开VS的时候,找到 :视图>任务列表 即可显示所有带有T ...
- C#三大特性之 封装、继承、多态
一.封装: 封装是实现面向对象程序设计的第一步,封装就是将数据或函数等集合在一个个的单元中(我们称之为类).被封装的对象通常被称为抽象数据类型. 封装的意义: 封装的意义在于保护或者防止代码(数据) ...
- mongodb在w10安装及配置
官网网站下载mongodb 第一步:安装 默认安装一直next,直到choose setup type,系统盘空间足够大,安装在c盘就好 第二步:配置及使用 1.创建目录mongodb,及三个文件夹d ...
- 一、spark单机安装
如果要全面的使用spark,你可能要安装如JDK,scala,hadoop等好些东西.可有时候我们只是为了简单地安装和测试来感受一下spark的使用,并不需要那么全面.对于这样的需要,我们其实只要安装 ...
- 【SSH网上商城项目实战12】添加和更新商品功能的实现
转自: https://blog.csdn.net/eson_15/article/details/51366370 添加商品部分原理和添加商品类别是一样的,不过要比商品类别复杂,因为商品的属性有很多 ...
- BZOJ4602: [Sdoi2016]齿轮(并查集 启发式合并)
题意 题目链接 Sol 和cc的一道题很像啊 对于初始的\(N\)个点,每加一条限制实际上就是合并了两个联通块. 那么我们预处理出\(val[i]\)表示的是\(i\)节点所在的联通块根节点转了\(1 ...
- Python 关于bytes类方法对数字转换的误区, Json的重要性
本文起源于一次犯错, 在发觉bytes()里面可以填数字, 转出来的也是bytes类型, 就心急把里面的东西decode出来. 结果为空.搞来搞去以为是命令不熟练事实上错在逻辑. a1 = bytes ...