超全面的JavaWeb笔记day06<Schema&SAX&dom4j>
1、Schema的简介和快速入门(了解)
2、Schema文档的开发流程(了解)
3、Schema文档的名称空间(了解)
4、SAX解析原理分析(*********)
5、SAX解析xml获得整个文档(会写)
6、SAX解析xml获得某个节点(会写)
(***************dom4j是重点************)
7、dom4j简介(*********)
==========================================================
8、dom4j查找元素(*********)
9、dom4j添加元素(在特定位置添加)(*********)
在末尾添加 使用 addElement setText
在特定位置添加
- 获取所有子标签 使用 elements()方法
- 使用list里面add(位置,添加的元素)方法
10、dom4j修改元素、删除节点和获得属性(*********)
删除使用remove方法,但是删除通过父节点删除
attributeValue方法
11、dom4j对XPath的支持(****这个很重要******)
selectNodes: 多个节点
selectSingleNode:一个节点
//id //p1[@id='aaa']
12、学生管理系统的代码实现(*********)
1、schema约束
dtd语法: <!ELEMENT 元素名称 约束>
** schema符合xml的语法,xml语句
** 一个xml中可以有多个schema,多个schema使用名称空间区分(类似于java包名)
** dtd里面有PCDATA类型,但是在schema里面可以支持更多的数据类型
*** 比如 年龄 只能是整数,在schema可以直接定义一个整数类型
*** schema语法更加复杂,schema目前不能替代dtd
2、schema的快速入门
* 创建一个schema文件 后缀名是 .xsd
** 根节点 <schema>
** 在schema文件里面
** 属性 xmlns="http://www.w3.org/2001/XMLSchema"
- 表示当前xml文件是一个约束文件
** targetNamespace="http://www.itcast.cn/20151111"
- 使用schema约束文件,直接通过这个地址引入约束文件
** elementFormDefault="qualified"
步骤
(1)看xml中有多少个元素
<element>
(2)看简单元素和复杂元素
* 如果复杂元素
<complexType>
<sequence>
子元素
</sequence>
</complexType>
(3)简单元素,写在复杂元素的
<element name="person">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
1.xsd
- <?xml version="1.0" encoding="UTF-8"?>
- <schema xmlns="http://www.w3.org/2001/XMLSchema"
- targetNamespace="http://www.itcast.cn/20151111"
- elementFormDefault="qualified">
- <element name="person">
- <complexType>
- <sequence>
- <!-- <all> -->
- <!-- <choice> -->
- <element name="name" type="string" maxOccurs="unbounded"></element>
- <element name="age" type="int"></element>
- <!-- </choice> -->
- <!-- </all> -->
- </sequence>
- <attribute name="id1" type="int" use="required"></attribute>
- </complexType>
- </element>
- </schema>
(4)在被约束文件里面引入约束文件
person.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xmlns="http://www.itcast.cn/20151111"
- xsi:schemaLocation="http://www.itcast.cn/20151111 1.xsd" id1="123">
- <name>zhangsan</name>
- <name>zhangsan</name>
- <name>zhangsan</name>
- <age>20</age>
- </person>
<person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itcast.cn/20151111"
xsi:schemaLocation="http://www.itcast.cn/20151111 1.xsd">
** xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
-- 表示xml是一个被约束文件
** xmlns="http://www.itcast.cn/20151111"
-- 是约束文档里面 targetNamespace
** xsi:schemaLocation="http://www.itcast.cn/20151111 1.xsd">
-- targetNamespace 空格 约束文档的地址路径
* <sequence>:表示元素的出现的顺序
<all>: 元素只能出现一次
<choice>:元素只能出现其中的一个
maxOccurs="unbounded": 表示元素的出现的次数
<any></any>:表示任意元素
* 可以约束属性
* 写在复杂元素里面
***写在 </complexType>之前
--
<attribute name="id1" type="int" use="required"></attribute>
- name: 属性名称
- type:属性类型 int stirng
- use:属性是否必须出现 required
* 复杂的schema约束
company.xsd
- <?xml version="1.0" encoding="UTF-8"?>
- <schema xmlns="http://www.w3.org/2001/XMLSchema"
- targetNamespace="http://www.example.org/company"
- elementFormDefault="qualified">
- <element name="company">
- <complexType>
- <sequence>
- <element name="employee">
- <complexType>
- <sequence>
- <!-- 引用任何一个元素 -->
- <any></any>
- <!-- 员工名称 -->
- <element name="name"></element>
- </sequence>
- <!-- 为employee元素添加属性 -->
- <attribute name="age" type="int"></attribute>
- </complexType>
- </element>
- </sequence>
- </complexType>
- </element>
- </schema>
* 引入多个schema文件,可以给每个起一个别名
company.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <!-- 数据文件 引用多个Schema -->
- <company xmlns = "http://www.example.org/company"
- xmlns:dept="http://www.example.org/department"
- xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://www.example.org/company company.xsd http://www.example.org/department department.xsd" >
- <employee age="30">
- <!-- 部门名称 -->
- <!--想要引入部门的约束文件里面的name,使用部门的别名 detp:元素名称-->
- <dept:name>100</dept:name>
- <!-- 员工名称 -->
- <name>王晓晓</name>
- </employee>
- </company>
department.xsd
- <?xml version="1.0" encoding="UTF-8"?>
- <schema xmlns="http://www.w3.org/2001/XMLSchema"
- targetNamespace="http://www.example.org/department"
- elementFormDefault="qualified">
- <!-- 部门名称 -->
- <element name="name" type="int"></element>
- </schema>
3、sax解析的原理(********)
* 解析xml有两种技术 dom 和sax
* dom方式:根据xml的层级结构在内存中分配一个树形结构
** 把xml中标签,属性,文本封装成对象
* sax方式:事件驱动,边读边解析
* 在javax.xml.parsers包里面
** SAXParser
此类的实例可以从 SAXParserFactory.newSAXParser() 方法获得
- parse(File f, DefaultHandler dh)
* 两个参数
** 第一个参数:xml的路径
** 事件处理器
** SAXParserFactory
实例 newInstance() 方法得到
* 画图分析一下sax执行过程
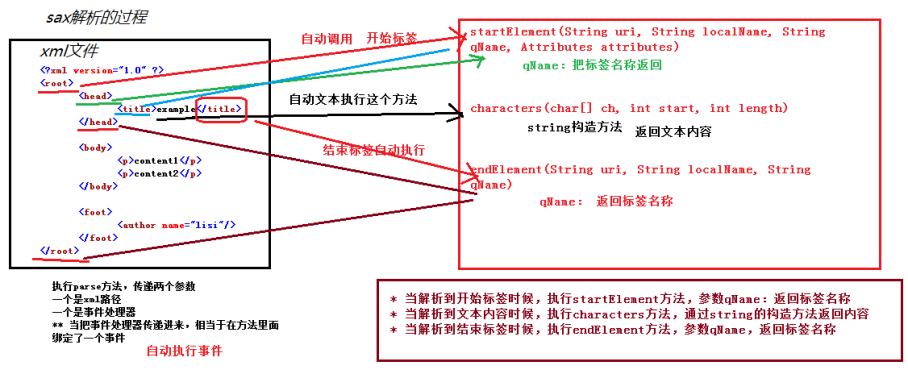
* 当解析到开始标签时候,自动执行startElement方法
* 当解析到文本时候,自动执行characters方法
* 当解析到结束标签时候,自动执行endElement方法
4、使用jaxp的sax方式解析xml(**会写**)
* sax方式不能实现增删改操作,只能做查询操作
** 打印出整个文档
p1.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <person>
- <p1 id1="aaaa">
- <name>zhangsan</name>
- <age>300</age>
- <sex>nv</sex>
- </p1>
- <p1>
- <name>lisi</name>
- <age>30</age>
- </p1>
- </person>
TestSax.java
- package com.li.jaxpsax;
- import javax.xml.parsers.ParserConfigurationException;
- import javax.xml.parsers.SAXParser;
- import javax.xml.parsers.SAXParserFactory;
- import org.xml.sax.Attributes;
- import org.xml.sax.SAXException;
- import org.xml.sax.helpers.DefaultHandler;
- public class TestSax {
- public static void main(String[] args) throws Exception {
- /*
- * 1、创建解析器工厂
- * 2、创建解析器
- * 3、执行parse方法
- *
- * 4、自己创建一个类,继承DefaultHandler
- * 5、重写类里面的三个方法
- * */
- //创建解析器工厂
- SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
- //创建解析器
- SAXParser saxParser = saxParserFactory.newSAXParser();
- //执行parse方法
- saxParser.parse("src/p1.xml", new MyDefault2());
- }
- }
- class MyDefault1 extends DefaultHandler {
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- System.out.print("<"+qName+">");
- }
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- System.out.print(new String(ch,start,length));
- }
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- System.out.print("</"+qName+">");
- }
- }
*** 执行parse方法,第一个参数xml路径,第二个参数是 事件处理器
*** 创建一个类,继承事件处理器的类,
***重写里面的三个方法
** 获取到所有的name元素的值
** 定义一个成员变量 flag= false
** 判断开始方法是否是name元素,如果是name元素,把flag值设置成true
** 如果flag值是true,在characters方法里面打印内容
** 当执行到结束方法时候,把flag值设置成false
* 获取第一个name元素的值
** 定义一个成员变量 idx=1
** 在结束方法时候,idx+1 idx++
** 想要打印出第一个name元素的值,
- 在characters方法里面判断,
-- 判断flag=true 并且 idx==1,在打印内容
- //实现获取所有(第一个)的name元素的值
- class MyDefault2 extends DefaultHandler {
- boolean flag = false;
- int idx = 1;
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- //判断qName是否是name元素
- if("name".equals(qName)) {
- flag = true;
- }
- }
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- //当flag值是true时候,表示解析到name元素
- //索引是1 实现获取第一个的name元素的值
- if(flag == true && idx == 1) {
- System.out.println(new String(ch,start,length));
- }
- }
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- //把flag设置成false,表示name元素结束
- if("name".equals(qName)) {
- flag = false;
- idx++;
- }
- }
- }
5、使用dom4j解析xml
* dom4j,是一个组织,针对xml解析,提供解析器 dom4j
* dom4j不是javase的一部分,想要使用第一步需要怎么做?
*** 导入dom4j提供jar包
-- 创建一个文件夹 lib
-- 复制jar包到lib下面,
-- 右键点击jar包,build path -- add to build path
-- 看到jar包,变成奶瓶样子,表示导入成功
* 得到document
SAXReader reader = new SAXReader();
Document document = reader.read(url);
* document的父接口是Node
* 如果在document里面找不到想要的方法,到Node里面去找
* document里面的方法 getRootElement() :获取根节点 返回的是Element
* Element也是一个接口,父接口是Node
- Element和Node里面方法
** getParent():获取父节点
** addElement:添加标签
* element(qname)
** 表示获取标签下面的第一个子标签
** qname:标签的名称
* elements(qname)
** 获取标签下面是这个名称的所有子标签(一层)
** qname:标签名称
* elements()
** 获取标签下面的所有一层子标签
6、使用dom4j查询xml
* 解析是从上到下解析
* 查询所有name元素里面的值
/*
1、创建解析器
2、得到document
3、得到根节点 getRootElement() 返回Element
4、得到所有的p1标签
* elements("p1") 返回list集合
* 遍历list得到每一个p1
5、得到name
* 在p1下面执行 element("name")方法 返回Element
6、得到name里面的值
* getText方法得到值
*/
- //查询xml中所有name元素的值
- public static void selectName() throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- * 3、得到根节点
- *
- * 4、得到p1
- * 5、得到p1下面的name
- * 6、得到name里面的值
- * */
- //创建解析器
- SAXReader saxReader = new SAXReader();
- //得到document
- Document document = saxReader.read("src/p1.xml");
- //得到根节点
- Element root = document.getRootElement();
- //得到p1
- List<Element> list = root.elements("p1");
- //遍历list
- for (Element element : list) {
- //element是每一个p1元素
- //得到p1下面的name元素
- Element name1 = element.element("name");
- //得到name里面的值
- String s = name1.getText();
- System.out.println(s);
- }
- }
* 查询第一个name元素的值
/*
* 1、创建解析器
* 2、得到document
* 3、得到根节点
* 4、得到第一个p1元素
** element("p1")方法 返回Element
* 5、得到p1下面的name元素
** element("name")方法 返回Element
* 6、得到name元素里面的值
** getText方法
* */
- //获取到一个name元素里面的值
- public static void selectSin() throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- * 3、得到根节点
- *
- * 4、得到第一个p1元素
- * 5、得到p1下面的name元素
- * 6、得到name元素里面的值
- * */
- //创建解析器
- SAXReader saxReader = new SAXReader();
- //得到document
- Document document = saxReader.read("src/p1.xml");
- //得到根节点
- Element root = document.getRootElement();
- //得到第一个p1
- Element p1 = root.element("p1");
- //得到p1下面的name元素
- Element name1 = p1.element("name");
- //得到name的值
- String s1 = name1.getText();
- System.out.println(s1);
- }
* 获取第二个name元素的值
/*
* 1、创建解析器
* 2、得到document
* 3、得到根节点
* 4、得到所有的p1
** 返回 list集合
* 5、遍历得到第二个p1
** 使用list下标得到 get方法,集合的下标从 0 开始,想要得到第二个值,下标写 1
* 6、得到第二个p1下面的name
** element("name")方法 返回Element
* 7、得到name的值
** getText方法
* */
- //获取第二个name元素里面的值
- public static void selectSecond() throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- * 3、得到根节点
- *
- * 4、得到所有的p1
- * 5、遍历得到第二个p1
- * 6、得到第二个p1下面的name
- * 7、得到name的值
- * */
- //创建解析器
- SAXReader saxReader = new SAXReader();
- //得到document
- Document document = saxReader.read("src/p1.xml");
- //得到根节点
- Element root = document.getRootElement();
- //得到所有的p1
- List<Element> list = root.elements("p1");
- //得到第二个p1 list集合下标从0开始
- Element p2 = list.get(1);
- //得到p1下面的name
- Element name2 = p2.element("name");
- //得到name里面的值
- String s2 = name2.getText();
- System.out.println(s2);
- }
7、使用dom4j实现添加操作
Dom4jUtils.java
- package com.li.utils;
- import java.io.FileOutputStream;
- import org.dom4j.Document;
- import org.dom4j.DocumentException;
- import org.dom4j.io.OutputFormat;
- import org.dom4j.io.SAXReader;
- import org.dom4j.io.XMLWriter;
- public class Dom4jUtils {
- public static final String PATH = "src/p1.xml";
- //返回document
- public static Document getDocument(String path) {
- try {
- //创建解析器
- SAXReader reader = new SAXReader();
- //得到document
- Document document = reader.read(path);
- return document;
- } catch (Exception e) {
- e.printStackTrace();
- }
- return null;
- }
- //回写xml的方法
- public static void xmlWriters(String path,Document document) {
- try {
- OutputFormat format = OutputFormat.createPrettyPrint();
- XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(path), format);
- xmlWriter.write(document);
- xmlWriter.close();
- }catch(Exception e) {
- e.printStackTrace();
- }
- }
- }
* 在第一个p1标签末尾添加一个元素 <sex>nv</sex>
* 步骤
/*
* 1、创建解析器
* 2、得到document
* 3、得到根节点
* 4、获取到第一个p1
* 使用element方法
* 5、在p1下面添加元素
* 在p1上面直接使用 addElement("标签名称")方法 返回一个Element
* 6、在添加完成之后的元素下面添加文本
*在sex上直接使用 setText("文本内容")方法
* 7、回写xml
* 格式化 OutputFormat,使用 createPrettyPrint方法,表示一个漂亮的格式
* 使用类XMLWriter 直接new 这个类 ,传递两个参数
*** 第一个参数是xml文件路径 new FileOutputStream("路径")
*** 第二个参数是格式化类的值
* */
- //在第一个p1标签末尾添加一个元素 <sex>nv</sex>
- public static void addSex() throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- * 3、得到根节点
- *
- * 4、获取到第一个p1
- * 5、在p1下面添加元素
- * 6、在添加完成之后的元素下面添加文本
- *
- * 7、回写xml
- * */
- //创建解析器
- // SAXReader reader = new SAXReader();
- //得到document
- // Document document = reader.read("src/p1.xml");
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //得到根节点
- Element root = document.getRootElement();
- //得到第一个p1元素
- Element p1 = root.element("p1");
- //在p1下面直接添加元素
- Element sex1 = p1.addElement("sex");
- //在sex下面添加文本
- sex1.setText("nv");
- //回写xml
- // OutputFormat format = OutputFormat.createPrettyPrint(); //可以有缩进的效果
- //// OutputFormat format = OutputFormat.createCompactFormat(); //压缩
- // XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/p1.xml"), format);
- // xmlWriter.write(document);
- // xmlWriter.close();
- Dom4jUtils.xmlWriters(Dom4jUtils.PATH, document);
- }
8、使用dom4j实现在特定位置添加元素
* 在第一个p1下面的age标签之前添加 <school>ecit.edu.cn</schlool>
* 步骤
/*
* 1、创建解析器
* 2、得到document
* 3、得到根节点
* 4、获取到第一个p1
* 5、获取p1下面的所有的元素
** elements()方法 返回 list集合
** 使用list里面的方法,在特定位置添加元素
** 首先创建元素 在元素下面创建文本
- 使用DocumentHelper类方法createElement创建标签
- 把文本添加到标签下面 使用 setText("文本内容")方法
*** list集合里面的 add(int index, E element)
- 第一个参数是 位置 下标,从0开始
- 第二个参数是 要添加的元素
* 6、回写xml
* */
- //在第一个p1下面的age标签之前添加 <school>ecit.edu.cn</schlool>
- public static void addAgeBefore() throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- * 3、得到根节点
- * 4、获取到第一个p1
- *
- * 5、获取p1下面的所有的元素
- * ** elements()方法 返回 list集合
- * ** 使用list里面的方法,在特定位置添加元素
- * ** 创建元素 在元素下面创建文本
- * *** add(int index, E element)
- * - 第一个参数是 位置 下标,从0开始
- * - 第二个参数是 要添加的元素
- * 6、回写xml
- * */
- //创建解析器
- // SAXReader saxReader = new SAXReader();
- //得到document
- // Document document = saxReader.read("src/p1.xml");
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //得到根节点
- Element root = document.getRootElement();
- //获取到第一个p1
- Element p1 = root.element("p1");
- //获取p1下面的所有元素
- List<Element> list = p1.elements();
- //创建元素 使用
- Element school = DocumentHelper.createElement("school");
- //在school下面创建文本
- school.setText("ecit");
- //在特定位置添加
- list.add(1, school);
- //回写xml
- /*OutputFormat format = OutputFormat.createPrettyPrint();
- XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/p1.xml"), format);
- xmlWriter.write(document);
- xmlWriter.close();*/
- Dom4jUtils.xmlWriters(Dom4jUtils.PATH, document);
- }
** 可以对得到document的操作和 回写xml的操作,封装成方法
** 也可以把传递的文件路径,封装成一个常量
*** 好处:可以提高开发速度,可以提交代码可维护性
- 比如想要修改文件路径(名称),这个时候只需要修改常量的值就可以了,其他代码不需要做任何改变
9、使用dom4j实现修改节点的操作
* 修改第一个p1下面的age元素的值 <age>30</age>
* 步骤
/*
* 1、得到document
* 2、得到根节点,然后再得到第一个p1元素
* 3、得到第一个p1下面的age
element("")方法
* 4、修改值是 30
** 使用setText("文本内容")方法
* 5、回写xml
* */
- //修改第一个p1下面的age元素的值 <age>30</age>
- public static void modifyAge() throws Exception {
- /*
- * 1、得到document
- * 2、得到根节点,然后再得到第一个p1元素
- * 3、得到第一个p1下面的age
- * 4、修改值是 30
- *
- * 5、回写xml
- *
- * */
- //得到document
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //得到第一个根节点
- Element root = document.getRootElement();
- //得到第一个p1
- Element p1 = root.element("p1");
- //得到p1下面的age
- Element age = p1.element("age");
- //修改age的值
- age.setText("30");
- //回写xml
- Dom4jUtils.xmlWriters(Dom4jUtils.PATH, document);
- }
10、使用dom4j实现删除节点的操作
* 删除第一个p1下面的<school>ecit</school>元素
* 步骤
/*
* 1、得到document
* 2、得到根节点
* 3、得到第一个p1标签
* 4、得到第一个p1下面的school元素
* 5、删除(使用p1删除school)
* 得到school的父节点
- 第一种直接得到p1
- 使用方法 getParent方法得到
* 删除操作
- 在p1上面执行remove方法删除节点
* 6、回写xml
* */
- //删除第一个p1下面的<school>ecit</school>元素
- public static void delSch() throws Exception {
- /*
- * 1、得到document
- * 2、得到根节点
- * 3、得到第一个p1标签
- * 4、得到第一个p1下面的school元素
- * 5、删除(使用p1删除school)
- *
- * 6、回写xml
- * */
- //得到document ctrl shift o 快速导包
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //得到根节点
- Element root = document.getRootElement();
- //得到第一个p1元素
- Element p1 = root.element("p1");
- //得到p1下面的school标签
- Element sch = p1.element("school");
- //删除school元素
- //通过父节点删除
- //获取父节点的方法
- //sch.getParent(); //获取到school的父节点p1
- p1.remove(sch);
- //回写xml
- Dom4jUtils.xmlWriters(Dom4jUtils.PATH, document);
- }
11、使用dom4j获取属性的操作
* 获取第一个p1里面的属性id1的值
* 步骤
/*
* 1、得到document
* 2、得到根节点
* 3、得到第一个p1元素
* 4、得到p1里面的属性值
- p1.attributeValue("id1");
- 在p1上面执行这个方法,里面的参数是属性名称
* */
- //获取第一个p1里面的属性id1的值
- public static void getValues() throws Exception {
- /*
- * 1、得到document
- * 2、得到根节点
- * 3、得到第一个p1元素
- * 4、得到p1里面的属性值
- * */
- //得到document
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //得到根节点
- Element root = document.getRootElement();
- //得到第一个p1元素
- Element p1 = root.element("p1");
- //得到p1里面的属性值
- String value = p1.attributeValue("id1");
- System.out.println(value);
- }
12、使用dom4j支持xpath的操作
* 可以直接获取到某个元素
查看XPath.chm得知:
* 第一种形式
/AAA/DDD/BBB: 表示一层一层的,AAA下面 DDD下面的BBB
* 第二种形式
//BBB: 表示和这个名称相同,表示只要名称是BBB,都得到
* 第三种形式
/*: 所有元素
* 第四种形式
** BBB[1]: 表示第一个BBB元素
×× BBB[last()]:表示最后一个BBB元素
* 第五种形式
** //BBB[@id]: 表示只要BBB元素上面有id属性,都得到
* 第六种形式
** //BBB[@id='b1'] 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
13、使用dom4j支持xpath具体操作
** 默认的情况下,dom4j不支持xpath
** 如果想要在dom4j里面是有xpath
* 第一步需要,引入支持xpath的jar包,使用 jaxen-1.1-beta-6.jar
** 需要把jar包导入到项目中
** 在dom4j里面提供了两个方法,用来支持xpath
*** selectNodes("xpath表达式")
- 获取多个节点
*** selectSingleNode("xpath表达式")
- 获取一个节点
** 使用xpath实现:查询xml中所有name元素的值
** 所有name元素的xpath表示: //name
** 使用selectNodes("//name");
** 代码和步骤
- //查询xml中所有name元素的值
- public static void test1() throws Exception {
- /*
- * 1、得到document
- * 2、直接使用selectNodes("//name")方法得到所有的name元素
- * */
- //得到document
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //使用selectNodes("//name")方法得到所有的name元素
- List<Node> list = document.selectNodes("//name");
- //遍历list集合
- for (Node node : list) {
- //node是每一个name元素
- //得到name元素里面的值
- String s = node.getText();
- System.out.println(s);
- }
- }
** 使用xpath实现:获取第一个p1下面的name的值
* //p1[@id1='aaaa']/name
* 使用到 selectSingleNode("//p1[@id1='aaaa']/name")
* 步骤和代码
- //使用xpath实现:获取第一个p1下面的name的值
- public static void test2() throws Exception {
- /*
- * 1、得到document
- * 2、直接使用selectSingleNode方法实现
- * - xpath : //p1[@id1='aaaa']/name
- * */
- //得到document
- Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
- //直接使用selectSingleNode方法实现
- Node name1 = document.selectSingleNode("//p1[@id1='aaaa']/name"); //name的元素
- //得到name里面的值
- String s1 = name1.getText();
- System.out.println(s1);
- }
14、实现简单的学生管理系统
** 使用xml当做数据,存储学生信息
** 创建一个xml文件,写一些学生信息
student.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <sudent>
- <stu>
- <id>100</id>
- <name>zhangsan</name>
- <age>20</age>
- </stu>
- <stu>
- <id>101</id>
- <name>lisi</name>
- <age>30</age>
- </stu>
- </sudent>
** 增加操作
/*
* 1、创建解析器
* 2、得到document
* 3、获取到根节点
* 4、在根节点上面创建stu标签
* 5、在stu标签上面依次添加id name age
** addElement方法添加
* 6、在id name age上面依次添加值
** setText方法
* 7、回写xml
* */
Student.java
- package com.li.vo;
- public class Student {
- private String id;
- private String name;
- private String age;
- public String getId() {
- return id;
- }
- public void setId(String id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getAge() {
- return age;
- }
- public void setAge(String age) {
- this.age = age;
- }
- @Override
- public String toString() {
- return "Student [id=" + id + ", name=" + name + ", age=" + age + "]";
- }
- }
StuService.java
- import java.util.List;
- import org.dom4j.Document;
- import org.dom4j.DocumentException;
- import org.dom4j.Element;
- import org.dom4j.Node;
- import org.dom4j.io.OutputFormat;
- import org.dom4j.io.SAXReader;
- import org.dom4j.io.XMLWriter;
- import cn.itcast.vo.Student;
- public class StuService {
- //增加
- public static void addStu(Student student) throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- * 3、获取到根节点
- * 4、在根节点上面创建stu标签
- * 5、在stu标签上面依次添加id name age
- * 6、在id name age上面依次添加值
- *
- * 7、回写xml
- * */
- //创建解析器
- SAXReader saxReader = new SAXReader();
- //得到document
- Document document = saxReader.read("src/student.xml");
- //得到根节点
- Element root = document.getRootElement();
- //在根节点上面添加stu
- Element stu = root.addElement("stu");
- //在stu标签上面依次添加id name age标签
- Element id1 = stu.addElement("id");
- Element name1 = stu.addElement("name");
- Element age1 = stu.addElement("age");
- //在id name age上面依次添加值
- id1.setText(student.getId());
- name1.setText(student.getName());
- age1.setText(student.getAge());
- //回写xml
- OutputFormat format = OutputFormat.createPrettyPrint();
- XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/student.xml"), format);
- xmlWriter.write(document);
- xmlWriter.close();
- }
- }
TestStu.java
- //测试添加方法
- public static void testAdd() throws Exception {
- //设置值
- Student stu = new Student();
- stu.setId("103");
- stu.setName("wangwu");
- stu.setAge("40");
- StuService.addStu(stu);
- }
** 删除操作(根据id删除)
/*
* 1、创建解析器
* 2、得到document
* 3、获取到所有的id
* 使用xpath //id 返回 list集合
* 4、遍历list集合
* 5、判断集合里面的id和传递的id是否相同
* 6、如果相同,把id所在的stu删除
* */
StuService.java
- //删除 根据学生的id删除
- public static void delStu(String id) throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- *
- * 3、获取到所有的id
- * 使用xpath //id 返回 list集合
- * 4、遍历list集合
- * 5、判断集合里面的id和传递的id是否相同
- * 6、如果相同,把id所在的stu删除
- *
- * */
- //创建解析器
- SAXReader saxReader = new SAXReader();
- //得到document
- Document document = saxReader.read("src/student.xml");
- //获取所有的id xpath: //id
- List<Node> list = document.selectNodes("//id");
- //遍历list集合
- for (Node node : list) { //node是每一个id的元素
- //得到id的值
- String idv = node.getText();
- //判断idv和传递的id是否相同
- if(idv.equals(id)) { //id相同
- //得到stu节点
- Element stu = node.getParent();
- //获取stu的父节点
- Element student = stu.getParent();
- //删除stu
- student.remove(stu);
- }
- }
- //回写xml
- OutputFormat format = OutputFormat.createPrettyPrint();
- XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/student.xml"), format);
- xmlWriter.write(document);
- xmlWriter.close();
- }
TestStu.java
- //测试删除方法
- public static void testDel() throws Exception {
- StuService.delStu("103");
- }
** 查询操作(根据id查询)
/*
* 1、创建解析器
* 2、得到document
* 3、获取到所有的id
* 4、返回的是list集合,遍历list集合
* 5、得到每一个id的节点
* 6、id节点的值
* 7、判断id的值和传递的id值是否相同
* 8、如果相同,先获取到id的父节点stu
* 9、通过stu获取到name age值
** 把这些值封装到一个对象里面 返回对象
* */
StuService.java
- //查询 根据id查询学生信息
- public static Student getStu(String id) throws Exception {
- /*
- * 1、创建解析器
- * 2、得到document
- *
- * 3、获取到所有的id
- * 4、返回的是list集合,遍历list集合
- * 5、得到每一个id的节点
- * 6、id节点的值
- * 7、判断id的值和传递的id值是否相同
- * 8、如果相同,先获取到id的父节点stu
- * 9、通过stu获取到name age值
- *
- * */
- //创建解析器
- SAXReader saxReader = new SAXReader();
- //得到document
- Document document = saxReader.read("src/student.xml");
- //获取所有的id
- List<Node> list = document.selectNodes("//id");
- //创建student对象
- Student student = new Student();
- //遍历list
- for (Node node : list) { //node是每一个id节点
- //得到id节点的值
- String idv = node.getText();
- //判断id是否相同
- if(idv.equals(id)) {
- //得到id的父节点 stu
- Element stu = node.getParent();
- //通过stu获取name和age
- String namev = stu.element("name").getText();
- String agev = stu.element("age").getText();
- student.setId(idv);
- student.setName(namev);
- student.setAge(agev);
- }
- }
- return student;
- }
TestStu.java
- //测试查询方法
- public static void testSelect() throws Exception {
- Student stu = StuService.getStu("100");
- System.out.println(stu.toString());
- }
超全面的JavaWeb笔记day06<Schema&SAX&dom4j>的更多相关文章
- 超全面的JavaWeb笔记day03<JS对象&函数>
1.js的String对象(****) 2.js的Array对象 (****) 3.js的Date对象 (****) 获取当前的月 0-11,想要得到准确的月 +1 获取星期时候,星期日是 0 4.j ...
- 超全面的JavaWeb笔记day05<xml&dtd&jaxp>
0.表单提交方式(*****) button提交 超链接提交 事件 1.xml简介和应用(了解) 2.xml文档声明和乱码解决(*****) 文档声明 必须放在第一行第一列 设置xml编码和保存编码一 ...
- 超全面的JavaWeb笔记day20<监听器&国际化>
JavaWeb监听器 三大组件: l Servlet l Listener l Filter Listener:监听器 1. 初次相见:AWT 2. 二次相见:SAX 监听器: l 它是一个接口,内容 ...
- 超全面的JavaWeb笔记day15<mysql数据库>
1.数据库的概述 2.SQL 3.DDL 4.DML 5.DCL 6.DQL MySQL 数据库 1 数据库概念(了解) 1.1 什么是数据库 数据库就是用来存储和管理数据的仓库! 数据库存储数据的优 ...
- 超全面的JavaWeb笔记day13<JSTL&自定义标签>
1.JSTL标签库(重点) core out set remove url if choose when otherwise forEach fmt formatDate formatNumber 2 ...
- 超全面的JavaWeb笔记day12<Jsp&JavaBean&El表达式>
1.JSP三大指令 page include taglib 2.9个内置对象 out page pageContext request response session application exc ...
- 超全面的JavaWeb笔记day11<JSP&Session&Cookie&HttpSession>
1.JSP 2.回话跟踪技术 3.Cookie 4.HttpSession JSP入门 1 JSP概述 1.1 什么是JSP JSP(Java Server Pages)是JavaWeb服务器端的动态 ...
- 超全面的JavaWeb笔记day10<Response&Request&路径&编码>
1.Response 2.Request 3.路径 4.编码 请求响应流程图 response 1.response概述 response是Servlet.service方法的一个参数,类型为java ...
- 超全面的JavaWeb笔记day04<dom树等>
1.案例:在末尾添加节点(*****) 创建标签 createElement方法 创建文本 createTextNode方法 把文本添加到标签下面 appendChild方法 2.元素对象(了解) 如 ...
随机推荐
- js 学习的地址;
1.https://github.com/windiest/Front-end-tutorial 2.http://www.w3school.com.cn/tags/html_ref_eve ...
- LeetCode: Sort Colors 解题报告
Sort ColorsGiven an array with n objects colored red, white or blue, sort them so that objects of th ...
- jq 跳转方式汇总
按钮式: <INPUT name="pclog" type="button" value="GO" onClick="loc ...
- UML笔记1
UML包括 事物 结构:类,接口等等 行为:交互,状态改变等 分组:包,子系统等 注释 关系 依赖,关联(聚合,组合),泛化,实现 图 用例图,交互图(顺序图,协作图),类图,活动图,状态图等 扩展机 ...
- mysql 开启慢查询记录
Linux查看mysql 安装路径 一.查看文件安装路径 由于软件安装的地方不止一个地方,所有先说查看文件安装的所有路径(地址). 这里以mysql为例.比如说我安装了mysql,但是不知道文件都安装 ...
- [转]SQL Server 2012 的 T-SQL 新功能 – 新的数据分析函数(LEAD、LAG)
当您需要在 SQL Server 中利用 T-SQL 比较结果集的每一列跟前一列或后一列的差异时,在过去可能需要利用 CURSOR 搭配临时表变量,或是透过递归 CTE 来达到这个效果,如今 SQL ...
- 问题-XE10.2开发Datasnap时提示"provider not exported datasetprovider1"
问题现象: 在用最新版本的XE10.2开发一个代有图片的数据操作时,出现“provider not exported datasetprovider1”. 问题原因: 提示这个信息,代表未找到data ...
- 一款基于jquery和css3的响应式二级导航菜单
今天给大家分享一款基于jquery和css3的响应式二级导航菜单,这款导航是传统的基于顶部,鼠标经过的时候显示二级导航,还采用了当前流行的响应式设计.效果图如下: 在线预览 源码下载 实现的代码. ...
- 激活JetBrains的IDE(PhpStorm、WebStorm、IntelliJ IDEA)
JetBrains 授权服务器(License Server URL): http://idea.imsxm.com/ 转自: http://www.imsxm.com/jetbrains-licen ...
- size_t ssize_t socklen_t
size_t 解释一:为了增强程序的可移植性,便有了size_t,它是为了方便系统之间的移植而定义的,不同的系统上,定义size_t可能不一样. 在32位系统上 定义为 unsigned int 也就 ...