Scala_数据结构
数据结构
容器(Collection)
Scala提供了一套丰富的容器(collection)库,包括列表 (List)、数组(Array)、集合(Set)、映射(Map)等
根据容器中元素的组织方式和操作方式,可以区分为有序 和无序、可变和不可变等不同的容器类别
Scala用了三个包来组织容器类,分别是scala.collection 、 scala.collection.mutable和scala.collection.immutable
下图显示了scala.collection包中所有的容器类。这些都是 高级抽象类或特质。例如,所有容器类的基本特质(trait)是 Traverable特质,它为所有的容器类定义了公用的foreach 方法,用于对容器元素进行遍历操作
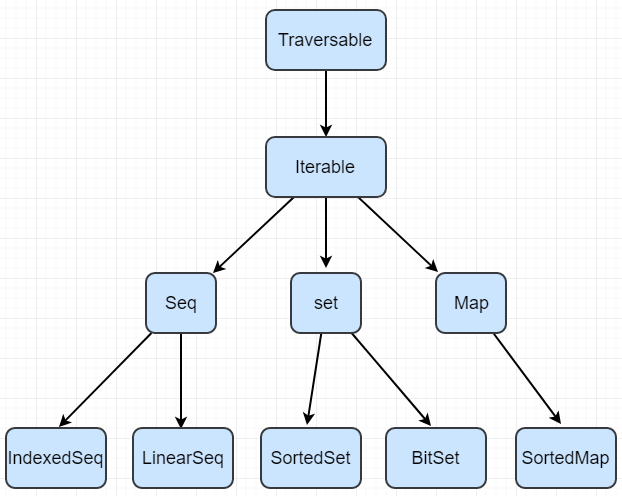
下面的图表显示了scala.collection.immutable中的所有容器类
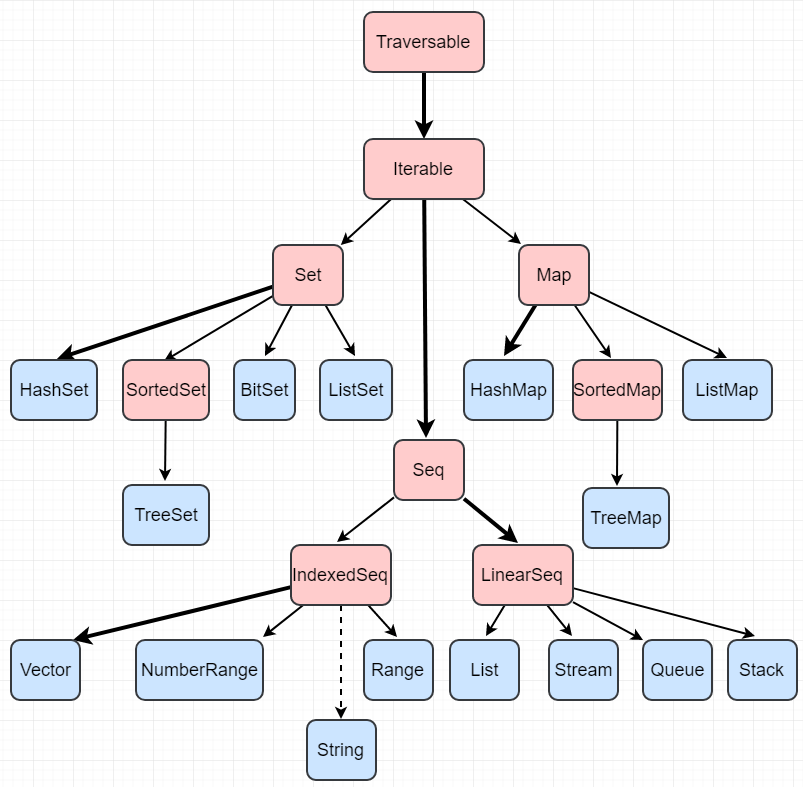
下面的图表显示scala.collection.mutable中的所有容器类
列表(List)
列表是一种共享相同类型的不可变的对象序列。既然是一个 不可变的集合, Scala的List定义在scala.collection.immutable包中
不同于Java的java.util.List,scala的List一旦被定义,其值就 不能改变,因此声明List时必须初始化
scala> var strList = List("BigData","Hadoop","Spark")
strList: List[String] = List(BigData, Hadoop, Spark)
列表有头部和尾部的概念,可以分别使用head和tail方法来获取
head返回的是列表第一个元素的值
scala> strList.head
res8: String = BigData
tail返回的是除第一个元素外的其它值构成的新列表,这体现出 列表具有递归的链表结构
scala> strList.tail
res9: List[String] = List(Hadoop, Spark)
scala> strList.tail.tail
res10: List[String] = List(Spark)
scala> strList.tail.tail.tail
res12: List[String] = List()
构造列表常用的方法是通过在已有列表前端增加元素, 使用的操作符为::,例如:
scala> val strList = List("BigData","Hadoop","Spark")
strList: List[String] = List(BigData, Hadoop, Spark)
scala> val otherList = "Apache"::strList
otherList: List[String] = List(Apache, BigData, Hadoop, Spark)
scala> strList
res13: List[String] = List(BigData, Hadoop, Spark)
Scala还定义了一个空列表对象Nil,借助Nil,可以将 多个元素用操作符::串起来初始化一个列表
scala> val intList = 1::2::3::Nil
intList: List[Int] = List(1, 2, 3)
scala> val intList = List(1,2,3)
intList: List[Int] = List(1, 2, 3)
集合(Set)
集合(set)是不重复元素的容器(collection)。列表中的元素 是按照插入的先后顺序来组织的,但是,“集合”中的元素并 不会记录元素的插入顺序,而是以“哈希”方法对元素的值 进行组织,所以,它允许你快速地找到某个元素
集合包括可变集和不可变集,分别位于 scala.collection.mutable包和scala.collection.immutable 包,缺省情况下创建的是不可变集
scala> var mySet = Set("Hadoop","Spark")
mySet: scala.collection.immutable.Set[String] = Set(Hadoop, Spark)
scala> mySet += "Scala"
scala> mySet
res15: scala.collection.immutable.Set[String] = Set(Hadoop, Spark, Scala)
scala> val mySet = Set("Hadoop","Spark")
mySet: scala.collection.immutable.Set[String] = Set(Hadoop, Spark)
scala> mySet += "Scala"
<console>:9: error: value += is not a member of scala.collection.immutable.Set[String]
mySet += "Scala"
^
如果要声明一个可变集,则需要提前引入scala.collection.mutable.Set
scala> import scala.collection.mutable.Set
import scala.collection.mutable.Set
scala> val mySet = Set("Hadoop","Spark")
mySet: scala.collection.mutable.Set[String] = Set(Hadoop, Spark)
scala> mySet += "Scala"
res0: mySet.type = Set(Scala, Hadoop, Spark)
scala> mySet
res1: scala.collection.mutable.Set[String] = Set(Scala, Hadoop, Spark)
映射(Map)
映射(Map)是一系列键值对的容器。在一个映射中,键是 唯一的,但值不一定是唯一的。可以根据键来对值进行快 速的检索
和集合一样,Scala 采用了类继承机制提供了可变的和不 可变的两种版本的映射,分别定义在包 scala.collection.mutable 和scala.collection.immutable 里。 默认情况下,Scala中使用不可变的映射。如果想使用可 变映射,必须明确地导入scala.collection.mutable.Map
scala> val university = Map("XMU" -> "Xiamen University","THU" -> "Tsinghua University")
university: scala.collection.immutable.Map[String,String] = Map(XMU -> Xiamen University, THU -> Tsinghua University)
scala> university("XMU")
res3: String = Xiamen University
对于这种访问方式,如果给定的键不存在,则会抛出异常, 为此,访问前可以先调用contains方法确定键是否存在
scala> val u = if (university.contains("XMU")) university("XMU") else 0
u: Any = Xiamen University
不可变映射,是无法更新映射中的元素的,也无法增加新的 元素。如果要更新映射的元素,就需要定义一个可变的映射,也可以使用+=操作来添加新的元素
scala> import scala.collection.mutable.Map
import scala.collection.mutable.Map
scala> val university2 = Map("XMU" -> "Xiamen University","THU" -> "Tsinghua University")
university2: scala.collection.mutable.Map[String,String] = Map(XMU -> Xiamen University, THU -> Tsinghua University)
scala> university2("XMU") = "xiamen university"//更新已有元素
scala> university2("FZU") = "Fuzhou university"//添加新元素
scala> university2
res6: scala.collection.mutable.Map[String,String] = Map(XMU -> xiamen university, THU -> Tsinghua University, FZU -> Fuzhou university)
scala> university2 += ("TIU" -> "Tianjin University")//添加新元素
res7: university2.type = Map(TIU -> Tianjin University, XMU -> xiamen university, THU -> Tsinghua University, FZU -> Fuzhou university)
循环遍历映射
格式
for ((k , v) <- 映射) 语句块
scala> for ((k,v) <- university2) printf("Code is : %s and name is : %s\n" , k , v)
Code is : TIU and name is : Tianjin University
Code is : XMU and name is : xiamen university
Code is : THU and name is : Tsinghua University
Code is : FZU and name is : Fuzhou university
或者,也可以只遍历映射中的k或者v
scala> for (k <- university2.keys) println(k)
TIU
XMU
THU
FZU
scala> for (v <- university2.values) println(v)
Tianjin University
xiamen university
Tsinghua University
Fuzhou university
迭代器(Iterator)
在Scala中,迭代器(Iterator)不是一个集合,但是,提供了 访问集合的一种方法
迭代器包含两个基本操作:next和hasNext。next可以返回迭 代器的下一个元素,hasNext用于检测是否还有下一个元素
scala> val iter = Iterator("Hadoop","Spark","Scala")
iter: Iterator[String] = non-empty iterator
scala> while(iter.hasNext){
| println(iter.next())
| }
Hadoop
Spark
Scala
scala> val iter = Iterator("Hadoop","Spark","Scala")
iter: Iterator[String] = non-empty iterator
scala> for (elem <- iter){
| println(elem)
| }
Hadoop
Spark
Scala
Iterable有两个方法返回迭代器:grouped和sliding。然而,这些迭代器返回的不是单 个元素,而是原容器(collection)元素的全部子序列。这些最大的子序列作为参数传 给这些方法。
grouped方法返回元素的增量分块,
sliding方法生成一个滑动元素的窗口。 两者之间的差异通过REPL的作用能够清楚看出。
scala> val list = List(1,2,3,4,5)
list: List[Int] = List(1, 2, 3, 4, 5)
scala> val iter = list grouped 3
iter: Iterator[List[Int]] = non-empty iterator
scala> iter.next()
res16: List[Int] = List(1, 2, 3)
scala> iter.next()
res17: List[Int] = List(4, 5)
scala> val sli = list sliding 3
sli: Iterator[List[Int]] = non-empty iterator
scala> sli.next()
res18: List[Int] = List(1, 2, 3)
scala> sli.next()
res19: List[Int] = List(2, 3, 4)
scala> sli.next()
res20: List[Int] = List(3, 4, 5)
数组(Array)
数组是一种可变的、可索引的、元素具有相同类型的数据集合,它是各种高 级语言中最常用的数据结构。Scala提供了参数化类型的通用数组类Array[T], 其中T可以是任意的Scala类型,可以通过显式指定类型或者通过隐式推断来实例化一个数组。
scala> val arr = new Array[Int](3)
arr: Array[Int] = Array(0, 0, 0)
scala> arr(0) = 12
scala> arr
res24: Array[Int] = Array(12, 0, 0)
scala> arr(1) = 45
scala> arr(2) = 33
scala> arr
res27: Array[Int] = Array(12, 45, 33)
scala> val intArr = Array(12,45,23)
intArr: Array[Int] = Array(12, 45, 23)
scala> val strArr = new Array[String](3)
strArr: Array[String] = Array(null, null, null)
scala> strArr(0) = "BigData"
scala> strArr(1) = "Hive"
scala> strArr(1) = "HBase"
scala> strArr(2) = "Hive"
scala> for (i <- 0 to 2) println(strArr(i))
BigData
HBase
Hive
scala> val strArr = Array("Hadoop","Hive","Hbase")
strArr: Array[String] = Array(Hadoop, Hive, Hbase)
Array提供了函数ofDim来定义二维和三维数组,用法如下:
scala> val myMatrix = Array.ofDim[Int](3,4) //类型实际就是Array[Array[Int]]
myMatrix: Array[Array[Int]] = Array(Array(0, 0, 0, 0), Array(0, 0, 0, 0), Array(0, 0, 0, 0))
scala> val myCube = Array.ofDim[String](3,2,4) //类型实际是Array[Array[Array[String]]]
myCube: Array[Array[Array[String]]] = Array(Array(Array(null, null, null, null), Array(null, null, null, null)), Array(Array(null, null, null, null), Array(null, null, null, null)), Array(Array(null, null, null, null), Array(null, null, null, null)))
可以使用多级圆括号来访问多维数组的元素,例如myMatrix(0)(1)返回第 一行第二列的元素
采用Array类型定义的数组属于定长数组,其数组长度 在初始化后就不能改变。如果要定义变长数组,需要使用ArrayBuffer参数类型,其位于包 scala.collection.mutable中。举例如下:
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val aMutableArr = ArrayBuffer(10,20,30)
aMutableArr: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 20, 30)
scala> aMutableArr += 40
res37: aMutableArr.type = ArrayBuffer(10, 20, 30, 40)
scala> aMutableArr.insert(2, 60,40)
scala> aMutableArr
res39: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 20, 60, 40, 30, 40)
scala> aMutableArr -= 40
res40: aMutableArr.type = ArrayBuffer(10, 20, 60, 30, 40)
scala> var temp=aMutableArr.remove(2)
temp: Int = 60
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val aMutableArr = ArrayBuffer(10,20,30)
aMutableArr: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 20, 30)
scala> aMutableArr ++= Array(4,5,6) //追加数组
res11: aMutableArr.type = ArrayBuffer(10, 20, 30, 4, 5, 6
scala> var temp=aMutableArr.remove(2,2) //从第二个元素删除,删除2个元素
temp: Unit = ()
scala> aMutableArr
res12: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 20, 5, 6)
元组(Tuple)
元组是不同类型的值的聚集。元组和列表不同,列表中各 个元素必须是相同类型,而元组可以包含不同类型的元素
scala> val tuple = ("bigdata" , 2015 , 45.0 , 33f)
tuple: (String, Int, Double, Float) = (bigdata,2015,45.0,33.0)
scala> println(tuple._1)
bigdata
scala> println(tuple._2)
2015
scala> println(tuple._4)
33.0
scala> val t,(a,b,c,d) = ("bigdata" , 2015 , 45.0 , 33f)
t: (String, Int, Double, Float) = (bigdata,2015,45.0,33.0)
a: String = bigdata
b: Int = 2015
c: Double = 45.0
d: Float = 33.0
scala> a
res0: String = bigdata
Scala_数据结构的更多相关文章
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- 一起学 Java(三) 集合框架、数据结构、泛型
一.Java 集合框架 集合框架是一个用来代表和操纵集合的统一架构.所有的集合框架都包含如下内容: 接口:是代表集合的抽象数据类型.接口允许集合独立操纵其代表的细节.在面向对象的语言,接口通常形成一个 ...
- 深入浅出Redis-redis底层数据结构(上)
1.概述 相信使用过Redis 的各位同学都很清楚,Redis 是一个基于键值对(key-value)的分布式存储系统,与Memcached类似,却优于Memcached的一个高性能的key-valu ...
- 算法与数据结构(十五) 归并排序(Swift 3.0版)
上篇博客我们主要聊了堆排序的相关内容,本篇博客,我们就来聊一下归并排序的相关内容.归并排序主要用了分治法的思想,在归并排序中,将我们需要排序的数组进行拆分,将其拆分的足够小.当拆分的数组中只有一个元素 ...
- 算法与数据结构(十三) 冒泡排序、插入排序、希尔排序、选择排序(Swift3.0版)
本篇博客中的代码实现依然采用Swift3.0来实现.在前几篇博客连续的介绍了关于查找的相关内容, 大约包括线性数据结构的顺序查找.折半查找.插值查找.Fibonacci查找,还包括数结构的二叉排序树以 ...
- 算法与数据结构(九) 查找表的顺序查找、折半查找、插值查找以及Fibonacci查找
今天这篇博客就聊聊几种常见的查找算法,当然本篇博客只是涉及了部分查找算法,接下来的几篇博客中都将会介绍关于查找的相关内容.本篇博客主要介绍查找表的顺序查找.折半查找.插值查找以及Fibonacci查找 ...
- 算法与数据结构(八) AOV网的关键路径
上篇博客我们介绍了AOV网的拓扑序列,请参考<数据结构(七) AOV网的拓扑排序(Swift面向对象版)>.拓扑序列中包括项目的每个结点,沿着拓扑序列将项目进行下去是肯定可以将项目完成的, ...
- 算法与数据结构(七) AOV网的拓扑排序
今天博客的内容依然与图有关,今天博客的主题是关于拓扑排序的.拓扑排序是基于AOV网的,关于AOV网的概念,我想引用下方这句话来介绍: AOV网:在现代化管理中,人们常用有向图来描述和分析一项工程的计划 ...
- 掌握javascript中的最基础数据结构-----数组
这是一篇<数据结构与算法javascript描述>的读书笔记.主要梳理了关于数组的知识.部分内容及源码来自原作. 书中第一章介绍了如何配置javascript运行环境:javascript ...
随机推荐
- 基于spring boot的统一异常处理
一.springboot的默认异常处理 Spring Boot提供了一个默认的映射:/error,当处理中抛出异常之后,会转到该请求中处理,并且该请求有一个全局的错误页面用来展示异常内容. 例如这里我 ...
- Mac下安装社区版MongoDB
MongoDB下载地址:https://www.mongodb.com/download-center?_ga=2.98072543.1777419256.1515472368-391344272.1 ...
- 显示实现接口的好处c#比java好的地方
所谓Go语言式的接口,就是不用显示声明类型T实现了接口I,只要类型T的公开方法完全满足接口I的要求,就可以把类型T的对象用在需要接口I的地方.这种做法的学名叫做Structural Typing,有人 ...
- 全面了解HTTP请求方法说明
超文本传输协议(HTTP, HyperText Transfer Protocol)是一种无状态的协议,它位于OSI七层模型的传输层.HTTP客户端会根据需要构建合适的HTTP请求方法,而HTTP服务 ...
- g2o相关问题cs.h,以及no matching function for call to ‘g2o::OptimizationAlgorithmLevenberg::OptimizationAlgorithmLevenberg(Block*&)
1.对于cs.h找不到的情况 1)编译的时候一定要把csparse在EXTERNAL文件中,编译进去. 2)修改CMakeLists.txt文件中的include_directories中的${CPA ...
- [IBM][CLI Driver][DB2/NT] SQL1101N 不能以指定的授权标识和密码访问节点 "" 上的远程数据库 "LBZM"。 SQLSTATE=08004
[IBM][CLI Driver][DB2/NT] SQL1101N 不能以指定的授权标识和密码访问节点 "" 上的远程数据库 "LBZM". SQLST ...
- 关于传统项目打成war包的的分析
技术在不断的革新,以前的项目没有jar管理工具时,都是手动将依赖的jar拷贝到项目之下,然后Build Path,之后Maven出现了,出现了jar包中央仓库,所有的jar包资源集中在这里,免去频繁去 ...
- Windows 8风格应用-触控输入
参考:演练:创建您的第一个触控应用程序 http://msdn.microsoft.com/zh-cn/library/ee649090(v=vs.110).aspx win8支持多点触摸技术,而我们 ...
- 【C#】解析C#中JSON.NET的使用
目录结构: contents structure [-] JSON.NET简介 Serializing and Deserializing JSON Json Convert Json Seriali ...
- 27 isinstance与issubclass、反射、内置方法
isinstance与issubclass issubclass:判断子类是否属于父类,是则返回True,否则返回False isinstance:判断对象是否属于类,是则返回True,否则返回Fal ...