Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.编写年度最高气温统计
如上图说所示:有一个temp的文件,里面存放的是每年的数据,该数据全部是文本内容,大小2M左右,我已将他放在百度云(链接:https://pan.baidu.com/s/1CEcHAXlII2kKxbn1dmTPKA 密码:jgp0),当你下载后,看到该文件的第15列到19列存放的是年份,而第87列到92列存放的是温度,注意999是无效值,需要排除! 最终测试实验结果如下:

其实这个跟我上次写的wordCount如出一辙,只需要稍微改动一下,就可以轻松实现这个统计结果,具体代码如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.mapreduce.maxtemp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* 我们定义的map端类为MaxTempMapper,它需要继承“org.apache.hadoop.mapreduce.Mapper.Mapper”,
* 该Mapper有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出
* key和value的数据类型。
*/
public class MaxTempMapper extends Mapper<LongWritable,Text,Text,IntWritable> { /**
*
* @param key : 表示输入的key变量。
* @param value : 表示输入的value
* @param context : 表示map端的上下文,它是负责将map端数据传给reduce。
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到一行数据
String line = value.toString();
//得到年份
String year = line.substring(15, 19);
//得到气温
int temp = Integer.parseInt(line.substring(87, 92));
//判断temp不能为9999
if (temp != 9999){
//通过上线文将yaer和temp发给reduce端
context.write(new Text(year),new IntWritable(temp));
}
}
}
MaxTempMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.mapreduce.maxtemp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /**
* 我们定义的reduce端类为MaxTempReducer,它需要继承“org.apache.hadoop.mapreduce.Reducer.Reducer”,
* 该Reducer有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出
* key和value的数据类型。
*/
public class MaxTempReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
/**
*
* @param key : 表示输入的key变量。这里的key实际上就是mapper端传过来的year。
* @param values : 表示输入的value,这个变量是可迭代的,因此传递的是多个值。这个value实际上就是传过来的temp。
* @param context : 表示reduce端的上下文,它是负责将reduce端数据传给调用者(调用者可以传递的数据输出到文件,也可以输出到下一个MapReduce程序。
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//给max变量定义一个最小的int初始值方便用于比较
int max = Integer.MIN_VALUE;
//由于输入端只有一个key,因此value的所有值都属于这个key的,我们需要做的是对value进行遍历并将所有数据进行相加操作,最终的结果就得到了同一个key的出现的次数。
for (IntWritable value : values){
//获取到value的get方法获取到value的值。然后和max进行比较,将较大的值重新赋值给max
max = Math.max(max,value.get());
}
//我们将key原封不动的返回,并将key的values的所有int类型的参数进行折叠,最终返回单词书以及该单词总共出现的次数。
context.write(key,new IntWritable(max));
}
}
MaxTempReducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.mapreduce.maxtemp; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException; public class MaxTempApp { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。
conf.set("fs.defaultFS","file:///");
//创建一个任务对象job,别忘记把conf穿进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("WordCount");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(MaxTempApp.class);
//指定map的类名,这里指定咱们自定义的map程序即可
job.setMapperClass(MaxTempMapper.class);
//指定reduce的类名,这里指定咱们自定义的reduce程序即可
job.setReducerClass(MaxTempReducer.class);
//设置输出key的数据类型
job.setOutputKeyClass(Text.class);
//设置输出value的数据类型
job.setOutputValueClass(IntWritable.class);
//设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\temp"));
//初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。我的目的是调用该对象的delete方法,删除已经存在的文件夹
FileSystem fs = FileSystem.get(conf);
//通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录
Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
//设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径
FileOutputFormat.setOutputPath(job,outPath);
//等待任务执行结束,将里面的值设置为true。
job.waitForCompletion(true);
}
}
MaxTempApp.java 文件内容
关于MapReduce处理的大致流程,我画了一个草图,如下:
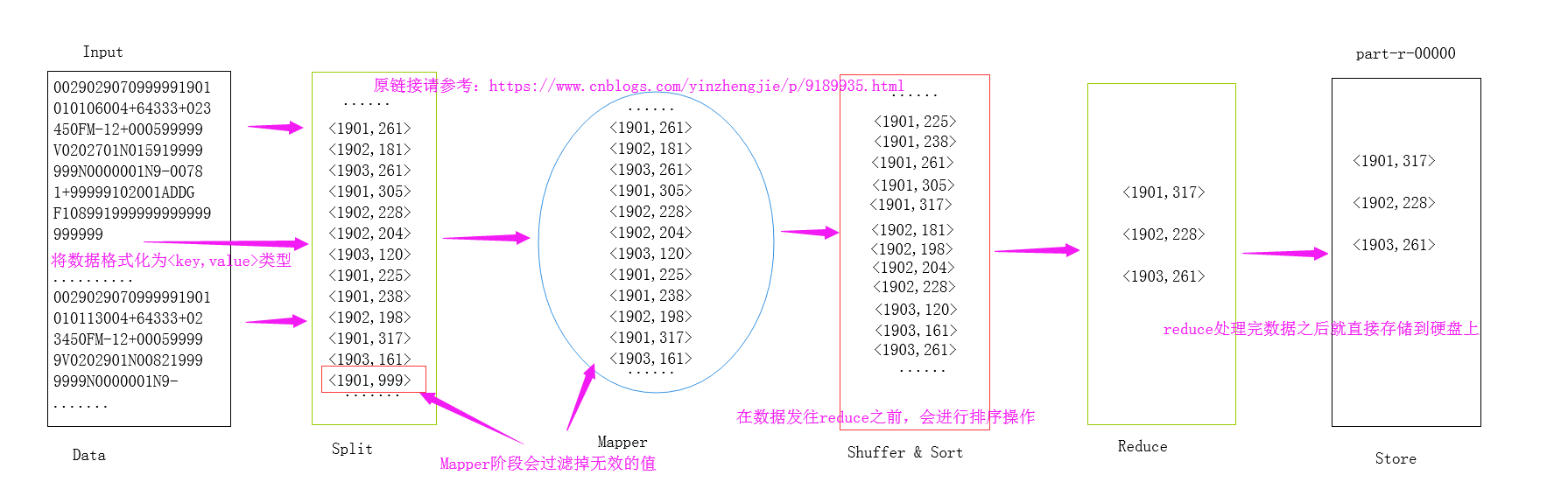
上述代码实现过程很简单,用到了一个Map程序和一个Reduce程序,那么问题来了,不用Reduce程序也能实现相同的效果吗?只用一个Map程序就把这个这个事情搞定可以吗?答案是肯定的,我们只需用Combiner就可以帮我们实现,那什么是Combiner呢?Combiner就相当于Map端的Reduce,用于减少网络间分发,属于预聚合阶段。Combiner适用场景:不适用于平均值,适用于最大值,最小值等等。接下来我们一起来研究研究它。
二.Combiner
1>.Combiner适用场景
简单来说:Combiner相当于Map端的Reduce,用于减少网络间分发,属于预聚合阶段,不适用于平均值,适用于最大值,最小值等等。具体用法我都不啰嗦了,一切尽在注释中!
2>.只有一个Map的情况
在上面的截图中我已经简单的分析了MapReduce的大致关系,其实实际生成环境中一个Map和一个Reduce的情况并不能代表所有,而是很多情况都是多个Map和多个Reduce,为了方便说明,我这里就简单的画一个Map和一个Reduce的情况,如果想要了解单个Reduce或者多个Reduce以及没有Re
3>.实现代码
MaxTempMapper.java 文件内容如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.mapreduce.maxtemp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* 我们定义的map端类为MaxTempMapper,它需要继承“org.apache.hadoop.mapreduce.Mapper.Mapper”,
* 该Mapper有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出
* key和value的数据类型。
*/
public class MaxTempMapper extends Mapper<LongWritable,Text,Text,IntWritable> { /**
*
* @param key : 表示输入的key变量。
* @param value : 表示输入的value
* @param context : 表示map端的上下文,它是负责将map端数据传给reduce。
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到一行数据
String line = value.toString();
//得到年份
String year = line.substring(15, 19);
//得到气温
int temp = Integer.parseInt(line.substring(87, 92));
//判断temp不能为9999
if (temp != 9999){
//通过上线文将yaer和temp发给reduce端
context.write(new Text(year),new IntWritable(temp));
}
}
}
MaxTempReducer.java文件内容如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.mapreduce.maxtemp; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /**
* 我们定义的reduce端类为MaxTempReducer,它需要继承“org.apache.hadoop.mapreduce.Reducer.Reducer”,
* 该Reducer有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出
* key和value的数据类型。
*/
public class MaxTempReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
/**
*
* @param key : 表示输入的key变量。这里的key实际上就是mapper端传过来的year。
* @param values : 表示输入的value,这个变量是可迭代的,因此传递的是多个值。这个value实际上就是传过来的temp。
* @param context : 表示reduce端的上下文,它是负责将reduce端数据传给调用者(调用者可以传递的数据输出到文件,也可以输出到下一个MapReduce程序。
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//给max变量定义一个最小的int初始值方便用于比较
int max = Integer.MIN_VALUE;
//由于输入端只有一个key,因此value的所有值都属于这个key的,我们需要做的是对value进行遍历并将所有数据进行相加操作,最终的结果就得到了同一个key的出现的次数。
for (IntWritable value : values){
//获取到value的get方法获取到value的值。然后和max进行比较,将较大的值重新赋值给max
max = Math.max(max,value.get());
}
//我们将key原封不动的返回,并将key的values的所有int类型的参数进行折叠,最终返回单词书以及该单词总共出现的次数。
context.write(key,new IntWritable(max));
}
}
MaxTempApp.java文件内容如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.mapreduce.maxtemp; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException; public class MaxTempApp { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。
conf.set("fs.defaultFS","file:///");
//创建一个任务对象job,别忘记把conf穿进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("WordCount");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(MaxTempApp.class);
//指定map的类名,这里指定咱们自定义的map程序即可
job.setMapperClass(MaxTempMapper.class);
//指定Combiner的类名,这里指定咱们自定义的reduce程序即可,注意,咱们这里没有设置Reduce程序,只是用了Map和Combiner。
job.setCombinerClass(MaxTempReducer.class);
//设置输出key的数据类型
job.setOutputKeyClass(Text.class);
//设置输出value的数据类型
job.setOutputValueClass(IntWritable.class);
//设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\temp"));
//初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。我的目的是调用该对象的delete方法,删除已经存在的文件夹
FileSystem fs = FileSystem.get(conf);
//通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录
Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
//设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径
FileOutputFormat.setOutputPath(job,outPath);
//等待任务执行结束,将里面的值设置为true。
job.waitForCompletion(true);
}
}
Hadoop基础-MapReduce的Combiner用法案例的更多相关文章
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
随机推荐
- 项目 - RM 部署上centos7 之后出现的一些问题和解决方法
系统版本: [root@localhost logs]# cat /etc/redhat-release CentOS Linux release (Core) 获取方法来自:https://www. ...
- JavaScript快速入门-实战(例子)
1.模拟bootstrap中的模态框 效果图:(点我后,弹出对话框,最下面的内容可以看到,但是有一定的透明度.) 思路分析: 整体分为三层,最底层(点我),中间透明层(实现透明效果),最顶层(最新内容 ...
- Flask学习-Flask app接受第一个HTTP请求
一.__call__() 在Flask app启动后,一旦uwsgi收到来自web server的请求,就会调用后端app,其实此时就是调用app的__call__(environ,start_res ...
- effective c++ 笔记 (5-8)
//---------------------------15/03/26---------------------------- //#5 了解c++默默编写并调用哪些函数 { /* c++会 ...
- Js_图片轮播
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- A - 摆仙果
题目描述 Adrian, Bruno与Goran三人参加了仙界的宴会,宴会开始之前先准备了一些仙果供三人品尝,但是仙果的摆放有顺序要求,如果把仙果摆错了位置,仙果就会消失而无法品尝到. 由于三人是第一 ...
- 20135316Linux内核学习笔记第五周
20135316王剑桥<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.给MenuOS增加time和t ...
- 实训四(cocos2dx sharesdk集成-1)
随着项目的进行,好像陷入的技术优先的迷局,对那些可以实现的功能,代码的编写上越来越漫不经心,反而对没有掌握的技术求之若渴,不免显得有些好高骛远.在没有掌握之前,思考.学习.交流也是一种快乐与享受. 言 ...
- Leetcode——37.解数独 [##]
@author: ZZQ @software: PyCharm @file: leetcode37_solveSudoku.py @time: 2018/11/20 16:41 思路:递归回溯 首先, ...
- LeetCode 638 Shopping Offers
题目链接: LeetCode 638 Shopping Offers 题解 dynamic programing 需要用到进制转换来表示状态,或者可以直接用一个vector来保存状态. 代码 1.未优 ...