GROUP BY和 HAVING 及 统计函数 执行顺序等
【我理解:
where是对最外层结果进行条件筛选,
而having是对分组时分组中的数据进行 组内条件筛选,注意:只能进行筛选,不能进行统计或计算,所有统计或计算都要放在最外层的select 后面,无论是否有分组】
转:
mysql必知必会——GROUP BY和HAVING
GROUP BY语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
select子句中的列名必须为分组列或列函数,列函数对于group by子句定义的每个组返回一个结果。
某个员工信息表结构和数据如下:
id name dept salary edlevel hiredate
1 张三 开发部 2000 3 2009-10-11
2 李四 开发部 2500 3 2009-10-01
3 王五 设计部 2600 5 2010-10-02
4 王六 设计部 2300 4 2010-10-03
5 马七 设计部 2100 4 2010-10-06
6 赵八 销售部 3000 5 2010-10-05
7 钱九 销售部 3100 7 2010-10-07
8 孙十 销售部 3500 7 2010-10-06
我想列出每个部门最高薪水的结果,sql语句如下:
- select dept , max(salary) AS MAXIMUM
- FROM STAFF
- GROUP BY DEPT
查询结果如下:
dept MAXIMUM
开发部 4500
设计部 2600
销售部 3500
解释一下这个结果:
1、 满足“SELECT子句中的列名必须为分组列或列函数”,因为SELECT有group by中包含的列dept;
2、“列函数对于group by子句定义的每个组各返回一个结果”,根据部门分组,对每个部门返回一个结果,就是每个部门的最高薪水。
将where子句与group by子句一起使用
分组查询可以在形成组和计算列函数之前具有消除非限定行的标准where子句。必须在group by子句之前指定where子句
例如,查询公司2010年入职的各个部门每个级别里的最高薪水
- SELECT dept,edlevel,MAX(salary) AS MAXIMUM
- FROM STAFF
- WHERE hiredate > '2010-01-01'
- GROUP BY dept,edlevel
查询结果如下:
dept edlevel MAXIMUM
设计部 4 2300
设计部 5 2600
销售部 5 3000
销售部 7 3500
在SELECT语句中指定的每个列名也在GROUP BY子句中提到,未在这两个地方提到的列名将产生错误。GROUP BY子句对dept和edlevel的每个唯一组合各返回一行。
GROUP BY子句之后使用Having子句
可应用限定条件进行分组,以便系统仅对满足条件的组返回结果。因此,在GROUP BY子句后面包含了一个HAVING子句。HAVING类似于WHERE(唯一的差别是WHERE过滤行,HAVING过滤组)AVING支持所有WHERE操作符。
例如,查找雇员数超过2个的部门的最高和最低薪水:
- SELECT dept ,MAX(salary) AS MAXIMUM ,MIN(salary) AS MINIMUM
- FROM STAFF
- GROUP BY dept
- HAVING COUNT(*) > 2
- ORDER BY dept
查询结果如下:
dept MAXIMUM MINIMUM
设计部 2600 2100
销售部 3500 3000
例如,查找雇员平均工资大于3000的部门的最高薪水和最低薪水:
- SELECT dept,MAX(salary) AS MAXIMUM,MIN(salary) AS MINIMUM
- FROM STAFF
- GROUP BY dept
- HAVING AVG(salary) > 3000
- ORDER BY dept
查询结果如下:
dept MAXIMUM MINIMUM
销售部 3500 3000
--------------------------------------------------------- 另一篇博客:
MySQL使用笔记(八)统计函数和分组数据记录查询
By francis_hao Dec 17,2016
统计函数数据记录查询
统计函数
|
统计函数 |
描述 |
|
count() |
count(*):统计表中记录条数(包括NULL值字段) count(field): 统计表中记录条数(不包括NULL值字段) |
|
avg() |
计算字段值的平均值 |
|
sum() |
计算字段值总和 |
|
max() |
查询字段值最大值 |
|
min() |
查询字段值最小值 |
mysql> select function(field) [new_name] from table_name where 条件;

可以为最终的字段取一个名字,当然也可以使用默认的。
分组数据记录查询
分组的意义是将某个字段相同的数据记录放在一起。
分组实现统计功能
首先要介绍一个函数group_concat(),该函数可实现显示每个分组中的指定字段值。
mysql> select group_concat(field) from table_name [where 条件] group by field;
下例显示了在以row1分组的时候,每个组中row2的值。
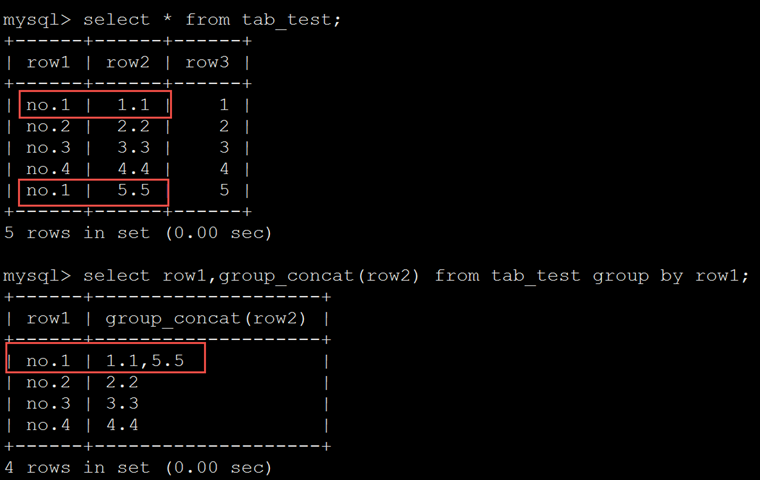
having子句限定分组查询
类似一种显示的控制,过滤出满足条件的数据记录。
下例为显示以row1字段分组的组中,row2的字段数据记录大于一个的记录。

附注
【这个顺序和我们通常想的不一样,要注意】
以最后的一个例子为例,分析一下SQL语句的执行顺序。

1、从表tab_test中将以row1分组的数据记录传递给2
2、从1中收到的数据记录选取需要的记录,并传递给3
3、显示满足自己的条件的从2传过来的数据记录

本文由 刘英皓 创作,采用 知识共享 署名-非商业性使用-相同方式共享 3.0 中国大陆 许可协议进行许可。欢迎转载,请注明出处:
转载自:http://www.cnblogs.com/yinghao1991/
参考
[1] 王飞飞 崔洋 贺亚茹《MySQL数据库应用从入门到精通(第二版)》北京:中国铁道出版社,2014年9月
GROUP BY和 HAVING 及 统计函数 执行顺序等的更多相关文章
- 查询语句中select from where group by having order by的执行顺序
查询语句中select from where group by having order by的执行顺序 1.查询中用到的关键词主要包含六个,并且他们的顺序依次为 select--from--w ...
- 查询语句中 select from where group by having order by 的执行顺序
查询中用到的关键词主要包含六个,并且他们的顺序依次为 select--from--where--group by--having--order by 其中 select 和 from 是必须的,其他关 ...
- MySQL select from join on where group by having order by limit 执行顺序
书写顺序:select [查询列表] from [表] [连接类型] join [表2] on [连接条件] where [筛选条件] group by [分组列表] having [分组后的筛选条件 ...
- group by和distinct语句的执行顺序
同一条语句之中,如果同时有group by和distinct语句,是先group by后distinct,还是先distinct后group by呢? 先说结论:先group by后distinct. ...
- HIVE点滴:group by和distinct语句的执行顺序
同一条语句之中,如果同时有group by和distinct语句,是先group by后distinct,还是先distinct后group by呢? 先说结论:先group by后distinct. ...
- SQL 中的语法顺序与执行顺序
FROM : HOME SQL 是一种声明式语言 SQL 语言是为计算机声明了一个你想从原始数据中获得什么样的结果的一个范例,而不是告诉计算机如何能够得到结果. SQL 语言声明的是结果集的属性,计算 ...
- mysql 中sql的执行顺序
文章转自 https://www.cnblogs.com/annsshadow/p/5037667.html https://www.cnblogs.com/yyjie/p/7788428.html ...
- sql 语句的先后执行顺序
例:查询语句中select from where group by having order by的执行顺序 一般以为会按照逻辑思维执行,为: 查询中用到的关键词主要包含六个,并且他们的顺序依次为 ...
- SQL查询中关键词的执行顺序
写在前面:最近的工作主要是写SQL脚本,在编写过程中对SQL的执行和解析过程特别混乱不清,造成了想优化却无从下手.为此专门在网上找博文学习,并做了如下总结. 1.查询中常用到的关键词有: SELECT ...
随机推荐
- 20155333 《网络对抗》Exp4 恶意代码分析
20155333 <网络对抗>Exp4 恶意代码分析 基础问题回答 1.如果在工作中怀疑一台主机上有恶意代码,但只是猜想,所有想监控下系统一天天的到底在干些什么.请设计下你想监控的操作有哪 ...
- Luogu P1726 上白泽慧音
这显然是一道求强连通分量(SCC)的题目. 只要你正常,都知道应该写Tarjan. 然后(假装会写Tarjan),其实我当然不会.但是求SCC还有另一个算法.复杂度和Tarjan一样,只不过常数大了点 ...
- Android 实现 WheelView
wheel view 目录(?)[-] Android WheelView效果图 网上的开源代码 实现思路 扩展Gallery 如何使用 我们都知道,在iOS里面有一种控件------滚筒控件(Whe ...
- 读取配置文件的URL,使用httpClient发送Post和Get请求,实现查询快递物流和智能机器人对话
1.主要jar包: httpclient-4.3.5.jar httpcore-4.3.2.jar 2.目录结构如图所示: 3.url.properties文件如下: geturl=http:// ...
- 由Windows开发平台向Linux平台转移的一些想法
从毕业到现在已经快20年了,一直在从事Windows平台上的开发工作.刚毕业那会大约是97,98年左右,工作的平台除了Windows平台还有Dos平台,因为在学校学习时,也是从Dos开始的.因此对于从 ...
- python 游戏(记忆拼图Memory_Puzzle)
1. 游戏功能和流程图 实现功能:翻开两个一样的牌子就显示,全部翻开游戏结束,设置5种图形,7种颜色,游戏开始提示随机8个牌子 游戏流程图 2. 游戏配置 配置游戏目录 配置游戏(game_conf. ...
- RN热更新
说白了集成RN业务,就是集成RN离线包,解析并渲染.所以,RN热更新的根本原理就是更换js bundle文件和资源文件,并重新加载,新的内容就完美的展示出来了. 目前市场上出现的3种热更新模式如下:仅 ...
- PAT甲题题解-1124. Raffle for Weibo Followers-模拟,水题
水题一个,贴个代码吧. #include <iostream> #include <cstdio> #include <algorithm> #include &l ...
- 《Linux内核分析》第四周学习笔记
<Linux内核分析>第四周学习笔记 扒开系统调用的三层皮(上) 郭垚 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.c ...
- Leetcode题库——39.组合总和
@author: ZZQ @software: PyCharm @file: combinationSum.py @time: 2018/11/14 18:23 要求:给定一个无重复元素的数组 can ...